运维面试前准备
描述一下DNS的解析过程:
- 假设在浏览器中输入www.baidu.com ,操作系统回先检查自己本地的hosts中是否有网址映射关系,如果有就进行本地域名解析。,
- 如果hosts文件中不会存在映射关系,则查找本地的DNS解释器缓存,是否有这个网址的映射关系,如果有进直接进行域名解析。
- 如果hosts与本地的DNS解释器缓存都没有映射关系,首先会找到TCP/IP参数中设置的首选DNS服务器,服务器接收到查询后,如果查询的域名,包含在本地配置的区域资源中,则返回解析结果给客户机,完成域名解析,如果要查询的域名,不由本地DNS 服务器区域解析,但该服务器已经缓存了此网址的映射关系,则调用这个ip地址映射进行地址解析。
- 如果DNS服务器本地区域文件和缓存解析都失败,则根据本地的DNS服务器的设置(是否设置转发器)进行查询,如果未用转发模式,本地DNS就把请求发至13台根DNS,根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址(http://qq.com)给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找http://qq.com域服务器,重复上面的动作,进行查询,直至找到www . qq .com主机。
- 如果用的是转发模式,此DNS服务器就会把请求转发至上一级DNS服务器,由上一级服务器进行解析,上一级服务器如果不能解析,或找根DNS或把转请求转至上上级,以此循环。不管是本地DNS服务器用是是转发,还是根提示,最后都是把结果返回给本地DNS服务器,由此DNS服务器再返回给客户机。
简单来说就是先进行浏览器缓存,系统缓存,路由器缓存,DNS缓存(运营商),根域名缓存,顶级域名服务器,主域名服务器
DHCP的作用是:
就是会动态的分配给ip地址以及其他的网络参数,这避免了手动分配带来的地址冲突等情况的发生。
说一下OSI有哪七层?
第一层:物理层,第二层:数据链路层,第三层:网络层,第四层:传输层,第五层:会话层,第六层:表示层,第七层:应用层。
说一下nfs,ftp,samba三者的区别:
**NFS:**是SUN公司指定的一种用于分布式访问的文件系统,它的本质是文件系统,主要用于unix操作系统上使用的,基于TCP/IP协议层,可以将远程的计算机磁盘挂载到本地,像本地磁盘一样操作。
FTP: ftp 的目的是在internet 上共享文件而发明的一种协议,基于TCP/IP。世界上绝大多系统都会有支持FTP工具的存在,通用性比较强。
**Samba:**是unix系统下实现windows文件共享的协议-CIFS,由于Wing共享的基于NetBios协议,是基于Etherbet的广播协议,在没有透明网桥的情况下()是不能够跨网段使用的,它主要用于linx和windows系统进行文件和打印机共享,也可以通过samba套件中的程序挂载到本地使用。
说一下防火墙的工作原理:
防火墙最初是针对internet网络不安全因素所采取的一种保护措施,
怎么实现防火墙对指定ip对指定服务可以访问?
Mysql相关
说一下数据库的主从复制原理:
主从复制原理就是master 开启bin-log二进制日志,从库通过change master 得到主库的相关同步信息,然后连接主库进行验证,主库的IO线程根据从库slave线程的请求,从master.info 开始记录的位置点向下开始取信息,同时把取到的位置点和最新的位置与binlog信息一同发给从库IO线程,从库将相关的sql语句存放到relay-log里面,最终从库的sql线程将relay-log里面的sql语句应用到从库上,至此整个同步过程完成,之后则将无限重复上述的过程。
完整的步骤如下:
- 主库开启binlog功能,并进行全备,将全备文件推送到从库服务器上
- Show master status;记录下当前的位置信息,以及二进制文件名
- 登陆到从库恢复全备文件
- 执行change master to 语句
- 执行start slave and show slave status\G
- 查看io和sql状态是否为yes。
数据库索引的优点和缺点
1、索引的概念
索引就是为了提高数据的检索速度。数据库的索引类似于书籍的索引。
在书籍中,索引允许用户不必翻阅完整个书就能迅速地找到所需要的信息。在数据库中,索引也允许数据库程序迅速地找到表中的数据,而不必扫描整个数据库.
2、索引的优点
1.创建唯一性索引,保证数据库表中每一行数据的唯一性
2.大大加快数据的检索速度,这也是创建索引的最主要的原因
3.减少磁盘IO(向字典一样可以直接定位)
3、索引的缺点
1.创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
2.索引需要占用额外的物理空间
3.当对表中的数据进行增加、删除和修改的时候,
索引也要动态的维护,降低了数据的维护速度
4、索引的分类
1.普通索引和唯一性索引
普通索引:CREATE INDEX mycolumn_index(索引名) ON mytable (表名)
唯一性索引:保证在索引列中的全部数据是唯一的
CREATE unique INDEX mycolumn_index ON mytable (myclumn)
2. 单个索引和复合索引
单个索引:对单个字段建立索引
复合索引:又叫组合索引,在索引建立语句中同时包含多个字段名,
最多16个字段
CREATE INDEX name_index ON userInfo(firstname,lastname)
3.顺序索引,散列索引,位图索引
数据库事务的特性,详细介绍一下ACID?
原子性(Atomicity) 一致性(Consistency) 隔离性(Isolation) 持久性(Durability)
数据库事物特性
1, 什么是数据库事务?
数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
意思就是一连串的数据库操作,即一串增删查改的集合。
2, 数据库事务做了什么?
它把数据库从一个一致的状态转换到另一个一致的状态,比如数据库操作前是一个点,数据库操作后是一个点,
我们只管这两个点的状态,而两点之间的连线上的状态我们不管因为他们可能对我们想要的结果产生影响。
3, 第一个特性 原子性(Atomicity)
假如我们有个方法中对一个属性进行了N次的更新,但是执行到一半的时候有一个语句有问题出现了异常,这样就可能使得我们上面所说的操作后的点与我们预先的点不同,这不是我们想要的,所以原子性要求你这个方法要么全部执行成功,要么你就别执行。
4, 第二个特性 一致性(Consistency)
原子性中规定方法中的操作都执行或者都不执行,但并没有说要所有操作一起执行(一起更新那就乱套了,要哪个结果?),所以操作的执行也是有先后顺序的,那我们要是在执行一半时查询了数据库,那我们会得到中间的更新的属性?答案是不会的,一致性规定事务提交前后只存在两个状态,提交前的状态和提交后的状态,绝对不会出现中间的状态。
5, 第三个特性 隔离性(Isolation)
事务的隔离性基于原子性和一致性,每一个事务可以并发执行,但是他们互不干扰,但是也有可能不同的事务会操作同一个资源,这个时候为了保持隔离性会用到锁方案。
6, 第四个特性 持久性(Durability)
当一个事务提交了之后那这个数据库状态就发生了改变,哪怕是提交后刚写入一半数据到数据库中,数据库宕机(死机)了,那当你下次重启的时候数据库也会根据提交日志进行回滚,最终将全部的数据写入。
讲述一下你对LVS的理解:
LVS 目前已经被集成到linux内核模块中了,也就是linux服务器,该项目在linux内核中实现了基于IP的数据请求负载均衡的调度方案,终端互联网用户从外部访问公司的外部负载均衡器,终端用户的web请求会发送到LVS调度器,调度器会根据自己预设的算法决定将请求发送给后端的 某台WEB服务器,比如轮询的话会将外部请求平均发送给后端的所有服务器。终端用户访问LVS 调度器虽然会被转发到后端的真实服务器,但如果真实服务器连接的是相同的存储,提供的服务也是相同的服务,最终用户不管是访问哪台真实服务器,得到的服务内容都是一样的,整个集群对用户来说的是透明的,最后根据LVS工作模式的不同,真实服务器会选择不同的方式将用户需要的数据发送到终端用户,LVS工作模式分为NAT模式,TUN模式以及DR模式。
DR模式和NAT模式的区别:
NAT模式要求:
- LVS服务器需要有不同的网段
- 服务器的网关必须是LVS的IP地址。
优点:1.安全,2.可以实现不同网段的数据请求
缺点:因为在VS/NAT中请求和响应报文都需要通过负载调度器,伸缩能力有限,当服务器节点数目升到20时,调度器本身,有可能会成为系统的新瓶颈。
DR模式 - 客户端将访问vip报文发送给LVS服务器;
- LVS服务器将请求报文的mac地址改为后端真是服务器的mac地址;
优点:1.LVS服务器知识修改了mac地址,所以非常快速,并且LVS 不会成为瓶颈。
缺点:1.要求较高,LVS服务器必须和后端真实服务器处于同一VLAN下;
2.后端真实服务器直接影响客户端,对于后端真实服务器来说,并不安全。
什么是LAMP架构?
LAMP架构是Linux Apache Mysql PHP 的缩写,即把Apache Mysql PHP 安装在linux系统上,组成一个环境来运行PHP网站,这里的Apache是httpd服务,这些可以安装到一个机器上,但是httpd 和PHP安装在一台机器上(php作为httpd的一个模块存在的,他们两者必须要在一起,才能实现效果)。
Apache主要实现如下功能:
第一:处理http的请求、构建响应报文等自身服务
第二:配置让apache 支持PHP程序的响应(通过php模块或者fpm)
第三:配置Apache具体处理php程序的方法,如通过反向代理将php程序交给fcgi处理
Mysql主要实现如下功能:
第一:提供PhP程序对数据的存储
第二:提供php程序对数据的读取(通常情况下从性能)
php主要实现如下功能:
第一:提供apache的访问接口,即CGI或者Fast CGI(fpm)
第二:提供php程序的解释器
第三:提供mysql数据库的连接函数的基本函数。
python
一句话解释一下什么样的语言能够用装饰器?
函数可以作为参数传递的语言可以使用装饰器。
python内建的数据类型有哪些?
整型–int,布尔型–bool,字符串–str,列表–list,元组–tuple,字典–dict。
装饰器: 给函数增加新功能,不修改被装饰对象的源代码和调用方法
生成器: 生成器其实是一种特殊的迭代器,它不需要__iter__() 和__next__() 方法,只需要一个yiled 关键字
迭代器: 任何实现了__iter__() 和__next__() 方法的对象都是迭代器,iter() 返回迭代器自身, next() 返回容器中的下一个值
简述面向对象中__new__和__init__区别?
简述Django的生命周期?
第一步:浏览器发起请求
- 第二步:WSGI创建socket服务端,接收请求(Httprequest)
- 第三步:中间件处理请求
- 第四步:url路由,根据当前请求的URL找到视图函数
- 第五步:view视图,进行业务处理(ORM处理数据,从数据库取到数据返回给view视图;view视图将数据渲染到template模板;将数据返回)
- 第六步:中间件处理响应
- 第七步:WSGI返回响应(HttpResponse)
- 第八步:浏览器渲染
python中的深拷贝和浅拷贝区别?
time datetime、random、os、sys
深拷贝和浅拷贝最根本的区别在于是否真正获取一个对象的复制实体,而不是引用。
假设B复制了A,修改A的时候,看B是否发生变化:
如果B跟着也变了,说明是浅拷贝,拿人手短!(修改堆内存中的同一个值)
如果B没有改变,说明是深拷贝,自食其力!(修改堆内存中的不同的值)
核心: 如果列表的元素包含可变数据类型, 一定要使用深拷贝。
zabbix监控
zabbix 是怎么实施监控的?
一个监控系统运行的流程是:
agent 需要安装到被监控的主机上,它负责定期收集各项数据,并发送到Zabbix server 端,zabbix server 将数据存储到数据库中,zabbix web根据数据在前端进行展示和绘图,这里agent收集数据分为主动和被动两种模式:
主动:agent 请求server获取主动的监控项列表,并主动将监控项内需要检测的数据提交给server/proxy
被动:server向agent请求获取监控项的数据,agent返回数据。
zabbix自定义发现怎么设置?
- 首先需要在模块中创建一个自动发现规则,这里需要一个名称个一个键值
- 过滤器中间要添加你需要用到的值。
- 然后创建一个监控项原型,也是一个名称个一个键值
- 然后需要去写一个这样的键值的收集
自动发现实际上就是需要首先去获得需要监控得值,然后将这个值做为一个新的参数传递到另外一个收集数据得item中。
zabbix怎么实现微信电话短信报警得?
我当时做zabbix监控的时候使用的是睿象云实现的
- 首先需要注册睿象云,创建监控工具
- 在zabbix server端安装CA探针
- 在睿象云添加策略,选择以什么样的方式进行通知,以及通知人等信息
- 做测试的话可以down掉某台主机,然后等待告警,然后认领解决问题。
使用zabbix 监控过那些服务?
进程cpu查看负载和使用率
单机内存查看
单机磁盘查看
单机查看网络
nginx mysql
Shell
grep 的使用:
grep是全面搜索正则表达式并把行打印出来,它是一种强大的文本搜索工具,与正则表达式结合使用。
如何在脚本中使用参数?
第一个参数:$1,第二个参数$2
[root@Suns ~]# sh show.sh file.txt /mnt
[root@Suns ~]# cat show.sh
#!/bin/bash
cp $1 $2
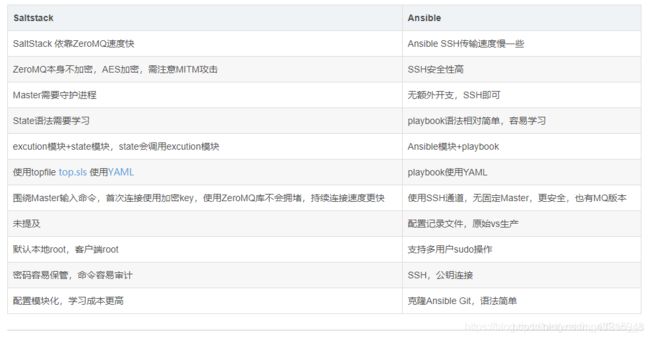
ansible 与 saltstack 自动化运维工具
熟悉主流的高可用架构(nginx、Haproxy、LVS)
nginx和apache的区别??
1、二者最核心的区别在于apache是同步多进程模型,一个连接对应一个进程;nginx是异步的,多个连接(万级别)可以对应一个进程 。nginx处理静态文件好,耗费内存少.但无疑apache仍然是目前的主流,有很多丰富的特性.所以还需要搭配着来.当然如果能确定nginx就适合需求,那么使用nginx会是更经济的方式。
2、nginx的负载能力比apache高很多。最新的服务器也改用nginx了。而且nginx改完配置能-t测试一下配置有没 有问题。
3、apache重启的时候发现配置出错了,会很崩溃,改的时候都会非常小心翼翼现在看有好多集群站,前端nginx抗并发,后端apache集群, 配合的也不错。
4、nginx处理动态请求是鸡肋,一般动态请求要apache去做,nginx只适合静态和反向。
5、从经验来看,nginx是很不错的前端服务器,负载性能很好,nginx,用webbench模拟10000个静态文件请求毫不吃力。 apache对php等语言的支持很好,此外apache有强大的支持网络,发展时间相对nginx更久,bug少但是apache有先天不支持多核心处理负载鸡肋的缺点,建议使用nginx做前端,后端用apache。大型网站建议用nginx自代的集群功能。
6、大部分情况下nginx都优于APACHE,比如说静态文件处理、PHP-CGI的支持、反向代理功能、前端 Cache、维持连接等等。在Apache+PHP(prefork)模式下,如果PHP处理慢或者前端压力很大的情况下,很容易出现Apache进程数 飙升,从而拒绝服务的现象。
7、Apache在处理动态有优势,Nginx并发性比较好,CPU内存占用低,如果rewrite频繁,那还是Apache吧!
8、一般来说,需要性能的web 服务,用nginx 。如果不需要性能只求稳定,那就apache 吧。
Nginx、HAProxy、LVS三者的优缺点**
nginx 的优点:
- 工作在网络7层之上,可针对http应用做一些分流的策略,如针对域名、目录结构,它的正规规则比HAproxy 更为强大和灵活,所以目前为止广泛流行。
- nginx 对网络稳定性的依赖小,理论上能ping 通就能够进行负载均衡
- nginx安装与配置比较简单,测试也比较方便,基本能把错误日志打印出来
- 可以承担高负载压力且稳定,硬件条件不差的情况也能支撑几万的并发量,负载度比LVS小。
- nginx 可以通过端口检测到服务器内部的故障,如根据服务器处理网也返回的状态码、超时等,并会把返回的错误请求重新提交到另一个节点。
- 不仅仅是优秀的负载均衡器/反向代理软件,同时也是强大的WEB应用服务器,LNMP也是近些年非常流行的web架构,在高可用环境中稳定性也很好。
nginx 的缺点: - 适应范围较小,仅能支持http、https、Ema协议
- 对后端服务器的健康检查,只支持通过端口检测,不支持url检测,比如用户正在上传一个文件,而处理该上传的节点刚好在上传过程中出现故障,nginx会上传切到另外一台服务器进行重新处理,而LVS就直接断掉了,如果是上传一个很大的文件或者很重要的文件或者重要的文件的话,用户可能会因此而不满。
LVS的优点:
- 抗负载能力强,是工作在网络4层之上仅做分发之用,没有流量的产生,这个特点也决定了它在负载均衡软件中性能最强的,对内存和cpu资源消耗比较低。
- 配置性比较低,这是一个优点也是一个缺点,因为没有太多可以配置的能洗,所以并不需要太对的接触,大大的减少了人为配置出错的概率。
- 工作稳定,因为本身抗负载能力很强,自身有完整的双机热备方案,如LVS+Keepalived,不过我们在项目实施中用的最多的还是LVS/DR+keepalived.
- 无流量,LVS只分发请求,而流量并不从它本身出去,这点保证了均衡器IO性能不会收到大流量的影响
- 应用范围广,因为LVS工作在4层,所以它几乎可以对所有应用做负载均衡,包括HTTP、数据库等
LVS缺点:
1、软件本身不支持正则表达式处理,不能做动静分离;而现在许多网站在这方面都有较强的需求,这个是Nginx/HAProxy+Keepalived的优势所在。
2、如果是网站应用比较庞大的话,LVS/DR+Keepalived实施起来就比较复杂了,特别后面有Windows Server的机器的话,如果实施及配置还有维护过程就比较复杂了,相对而言,Nginx/HAProxy+Keepalived就简单多了。
HAProxy优点:
- HAproxy 是支持虚拟主机的,可以工作在4.7层(支持多网段)
- Haproy 的优点可以补充nginx的一些缺点,比如支持session的保持,cookie的引导,同时支持通过获取指定的url来检测后端服务器的状态
- Haproxy跟lvs类似,本身就是一种负载均衡的软件,单纯从效率上将会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的。
- HAProxy支持TCP协议的负载均衡转发,可以对MySQL读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,大家可以用LVS+Keepalived对MySQL主从做负载均衡。
- HAProxy负载均衡策略非常多,HAProxy的负载均衡算法现在具体有如下8种
轮询,最小连接数 根据请求源IP进行哈希 权重 uri
/etc/passwd里的内容 :每段代表的意思
用户名 密码 用户id 用户组id 用户说明 用户家目录 用户的默认脚本
**shell写过什么脚本 实现什么功能 **
*iostat
用于输出cpu和磁盘的I/O相关的统计信息。
[root@Suns ~]# iostat
Linux 3.10.0-957.21.3.el7.x86_64 (Suns) 03/31/2021 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.35 0.00 0.35 0.00 0.00 99.29
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.37 0.37 4.03 369195 4030672
第一行:系统版本、主机名 当前时间
avg-cpu 总体的cpu使用情况统计信息,对于多核cpu,这里指得是cpu得平均值
Device 各磁盘设备的IO统计信息。
也可以指定采样时间间隔与采样次数
vmstat
可以展现给定时间间隔的服务器的状态,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,io读写情况。
[root@Suns ~]# vmstat 2 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 305824 179676 1106552 0 0 0 2 2 5 0 0 99 0 0
表示每两秒采集一次服务器状态,1表示只采集1次
进程 内存 swap IO system cpu
linux系统相关
crontab 中 * * * * * 代表什么意思
前面五个*号代表五个数字,数字的取值范围和含义如下:
分钟 (0-59)
小時 (0-23)
日期 (1-31)
月份 (1-12)
星期 (0-6)//0代表星期天
top
第一行:当前时间、系统启动时间、当前系统登录用户数目、平均负载(1分钟,10分钟,15分钟)。
第二行:进程总数、运行进程数、休眠进程数、终止进程数、僵死进程数。
第三行:%us用户空间占用cpu百分比;
%sy内核空间占用cpu百分比;
%ni用户进程空间内改变过优先级的进程占用cpu百分比;
%id空闲cpu百分比,反映一个系统cpu的闲忙程度。越大越空闲;
%wa等待输入输出(I/O)的cpu百分比;
%hi指的是cpu处理硬件中断的时间;
%si值的是cpu处理软件中断的时间;
%st用于有虚拟cpu的情况,用来指示被虚拟机偷掉的cpu时间。
第四行:total总的物理内存;used使用物理内存大小;free空闲物理内存;buffers用于内核缓存的内存大小
第五行:交换分区
buffers于cached区别:
buffers指的是块设备的读写缓冲区,cached指的是文件系统本身的页面缓存。他们都是Linux系统底层的机制,为了加速对磁盘的访问。
top - 14:34:13 up 11 days, 14:01, 2 users, load average: 0.01, 0.02, 0.05
Tasks: 80 total, 1 running, 79 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.2 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1776404 total, 305400 free, 184680 used, 1286324 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1388744 avail Mem
netstat
这个命令用来查看当前建立的网络连接
Netstat 是一款命令行工具,可用于列出系统上所有的网络套接字连接情况,包括 tcp, udp 以及 unix 套接字,另外它还能列出处于监听状态(即等待接入请求)的套接字。如果你想确认系统上的 Web 服务有没有起来,你可以查看80端口有没有打开。以上功能使 netstat 成为网管和系统管理员的必备利器。
buffer(缓冲)是为了提高内存和硬盘(或其他I/O设备)之间的数据交换的速度而设计的。
cache(缓存)从CPU角度考虑,是为了提高cpu和内存之间的数据交换速度而设计的 从内存读取与磁盘读取角度考虑,cache可以理解为操作系统为了更高的读取效率,更多的使用内存来缓存可能被再次访问的数据。
描述Linux系统从开机到登陆界面的启动过程
⑴开机BIOS自检,加载硬盘。
⑵读取MBR,MBR引导。
⑶grub引导菜单(Boot Loader)。
⑷加载内核kernel。
⑸启动init进程,依据inittab文件设定运行级别
⑹init进程,执行rc.sysinit文件。
⑺启动内核模块,执行不同级别的脚本程序。
⑻执行/etc/rc.d/rc.local
⑼启动mingetty,进入系统登陆界面。
进程和线程的区别
1、进程是资源分配的最小单位,线程是程序执行的最小单位(资源调度的最小单位)
2、进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。
而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
Docker
在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容器的创建和维护。使得 Docker 技术比虚拟机技术更为轻便、快捷。
Docker 和传统虚拟化方式的不同之处。传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
DDoS攻击
就是分布式拒绝服务攻击,指借助于客户/服务器技术,将多个计算机联合起来作为攻击平台,对一个或多个目标发动DDoS攻击,可使目标服务器进入瘫痪状态。
防御:
1、尽可能对系统加载最新补丁,并采取有效的合规性配置,降低漏洞利用风险;
2、采取合适的安全域划分,配置防火墙、入侵检测和防范系统,减缓攻击。
3、采用分布式组网、负载均衡、提升系统容量等可靠性措施,增强总体服务能力。
RAID
可以充分发 挥出多块硬盘的优势,可以提升硬盘速度,增大容量,提供容错功能够确保数据安全性,易于管理的优点,在任何一块硬盘出现问题的情况下都可以继续工作,不会 受到损坏硬盘的影响。
以下为RAID 1的特点:
最少需要2块磁盘
提供数据块冗余
性能好
RAID 5特点:
最少3块磁盘
数据条带形式分布
以奇偶校验作冗余
适合多读少写的情景,是性能与数据冗余最佳的折中方案
RAID 10(又叫RAID 1+0)特点:
最少需要4块磁盘
先按RAID 0分成两组,再分别对两组按RAID 1方式镜像
兼顾冗余(提供镜像存储)和性能(数据条带形分布)
在实际应用中较为常用
运维
是指大型组织已经建立好的网络软硬件的维护,就是要保证业务的上线与运作的正常,在他运转的过程中,对他进行维护,他集合了网络、系统、数据库、开发、安全、监控于一身的技术运维又包括很多种。
计算机网络相关的知识
计算机网络相关面试知识
closedwait第二次挥手服务端发送ACK确认请求时的状态
timewait第四次挥手时客户端的状态
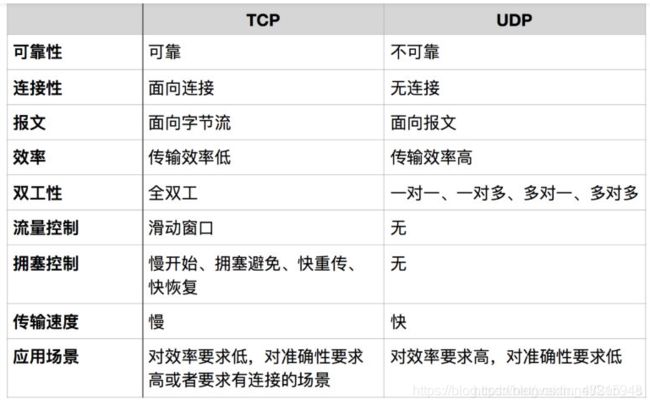
tcp和udp之间的区别?
TCP和UDP的区别
1、TCP与UDP区别总结:
1、 TCP面向连接 (如打电话要先拨号建立连接); UDP是无连接 的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付,Tcp通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。如丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制。
3、UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信。
4.每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP对系统资源要求较多,UDP对系统资源要求较少。
ping 用到的是ICMP协议
- ping 127.0.0.1
127.0.0.1是本地循环地址,如果本地址无法Ping通,则表明本地机TCP/IP协议不能正常工作。 - Ping本机的IP地址
用IPConfig查看本机IP,然后Ping该IP,通则表明网络适配器(网卡或MODEM)工作正常,不通则是网络适配器出现故障。 - Ping同网段计算机的IP
Ping一台同网段计算机的IP,不通则表明网络线路出现故障;若网络中还包含有路由器,则应先Ping路由器在本网段端口的IP,不通则此段线路有问题;通则再PING路由器在目标计算机所在网段的端口IP,不通则是路由出现故障;通则再Ping目的机IP地址。 - ping 网址
若要检测一个带DNS服务的网络,在上一步Ping通了目标计算机的IP地址后,仍无法连接到该机,则可PING该机的网络名,比如 Ping sina.com.cn,正常情况下会出现该网址所指向的IP,这表明本机的DNS设置正确而且DNS服务器工作正常,反之就可能是其中之一出 现了故障;同样也可通过Ping计算机名检测WINS解析的故障(WINS是将计算机名解析到IP地址的服务)。
HTTP协议的认识
HTTP协议就是客户端和服务端之间数据传输的格式规范,格式简称为“超文本传输协议”。
基于TCP/IP
(1)HTTP是一个属于应用层的面向对象的协议
(2)HTTP协议工作于客户端-服务端架构上。
MTV 模式
M 代表模型(Model): 负责业务对象和数据库的关系映射( ORM )。
T 代表模板 (Template):负责如何把页面展示给用户( html )。
V 代表视图(View): 负责业务逻辑,并在适当时候调用Model和Template。
简述TCP三次握手的过程?
答:在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接。第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认。第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态。第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。完成三次握手,客户端与服务器开始传送数据简版:首先A向B发SYN(同步请求),然后B回复SYN+ACK(同步请求应答),最后A回复ACK确认,这样TCP的一次连接(三次握手)的过程就建立了。
为什么连接的时候是三次握手,关闭的时候却是四次握手?
这是因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。
但是关闭连接时,当Client端发送FIN报文仅仅表示它不再发送数据了但是还能接收数据,Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
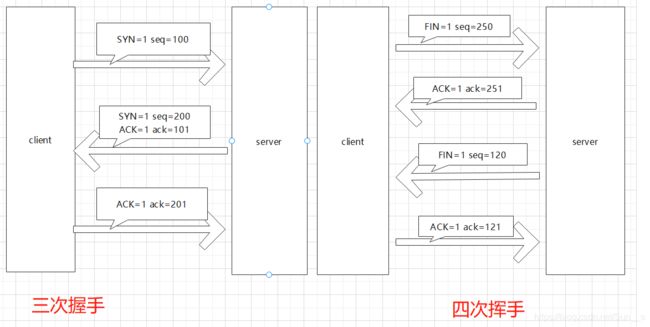
我自己的理解,tcp/ip协议是传输层面向连接的安全可靠的传输协议,三次握手的话就是为了能够建立一个安全可靠的连接,第一次握手是由客户端发起的,客户端向服务端发送一个报文,在报文里面SYN位 置1,当服务端收到报文之后就知道客户端要向我发起一个新的连接,也是服务端就向客户端发送一个确认消息报文,ACK置1,以上两次握手之后对于客户端而言,知道了自己发送和接收的能力,但是服务端只知道了自己的接收能力,却不知道自己的发送能力,进而进行第三次握手,就是客户端回复一个ACK置1的消息给服务端。到这里三次握手结束,不管客户端还是服务端都彼此知道了自己的接收和发送能力是完好的。这个连接就可以被安全建立了。
四次挥手的话就是,客户端首先发送一个FIN报文置1,当服务端收到报文之后,我就知道客户端想要断开连接,但是此时服务端不一定准备好了,此时服务端可能还有未发送完的消息,所以此时对于服务端而言,只能进行消息确认,就是说我已经知道你要和我断开连接了,我这里还没有准备好,你需要等我一下,于是发送完消息确认报文之后,然后待会会继续发送一个断开连接的报文,FIN位置1,之后客户端发送给服务端一个确认报文,ACK置1。四次之后服务端和客户端都做好断开的准备,于是就断开连接了。
三次握手,四次挥手中间都有那些状态?
**CLOSED:**起始点,不在连接状态。可以主动打开连接,或者等待对端的连接。
–>收到“被动打开”报文,进入LISTEN状态。
–>收到“主动打开”报文,进入SYN_SENT状态。
–>收到任何报文段,发送RST报文段。
–>收到其它任何报文段,发出差错报文。
**LISTEN:**被动打开,TCP正在等待对端的连接请求。
–>收到“发送数据”报文,发送SYN报文段,进入SYN_SENT状态。
–>收到任何SYN报文段,发送SYN+ACK报文段,进入SYN_RECEIVED状态。
–>收到任何其它报文段或者报文,发送差错报文。
**SYN_SENT:**主动打开,发送完一个连接请求后等待回复。
–>超时,进入CLOSED状态。
–>收到SYN报文段,发送SYN+ACK报文段,进入SYN_RECEIVED状态。
–>收到SYN+ACK报文段,发送ACK报文段,进入ESTABLISHED状态。
–>收到任何其它报文段或者报文,发送差错报文。
**SYN_RECEIVED:**被动打开,接受连接请求以后进行确认同时也向对端发送连接请求发送,等待对方的回复。
–>超时,发送RST报文段,进入CLOSED状态。
–>收到ACK报文段,进入ESTABLISHED状态。
–>收到"关闭"报文,发送FIN报文段,进入FIN_WAIT_1状态。
–>收到RST报文段,进入LISTEN状态。
–>收到任何其它报文段或者报文,发送差错报文。
**ESTABLISHED:**三次握手完毕,TCP连接建立完成,可以传输数据。
–>收到FIN报文段,进入CLOSED_WAIT状态。
–>收到“关闭”报文,发送FIN报文段,进入FIN_WAIT_1状态。
–>收到RST或SYN报文段,发出差错报文。
–>收到数据或ACK报文段,调用输入模块。
–>收到“发送”报文,调用输出模块。
**FIN_WAIT_1:**四次挥手开始,主动关闭,发送断开连接请求,等待对端确认。
–>收到FIN报文段,发送ACK报文段,进入CLOSING状态(同时关闭)。
–>收到FIN+ACK报文段,发送ACK报文段,进入FIN_WAIT状态(?)。
–>收到ACK报文段,进入FIN_WAIT_2状态。
–>收到任何其它报文段或者报文,发送差错报文。
**FIN_WAIT_2:**接收对方确认,但未接受对方的断开连接请求。
–>收到FIN报文段,发送ACK报文段,进入TIME_WAIT状态。
**CLOSING:**主动关闭的一方本希望收到对方的ACK却收到了对方的断开连接请求。
–>收到ACK报文段,进入TIME_WAIT状态。
–>收到任何其它报文段或者报文,发送差错报文。
**TIME_WAIT:**对方确认后发起断开连接请求,需要等待2MSL保证正常关闭。
–>超时,进入CLOSED状态。
–>收到任何其它报文段或者报文,发送差错报文。
**CLOSE_WAIT:**被动关闭,确认对端的连接终止请求,但是未向对端发送连接终止请求(可能数据没传完)。
–>收到"关闭"报文,发送FIN报文段,进入LAST_ACK状态。
–>收到任何其它报文段或者报文,发送差错报文。
**LAST_ACK:**数据传完,向对端发起断开连接请求后等待确认。
–>收到ACK报文段,进入CLOSED状态。
–>收到任何其它报文段或者报文,发送差错报文。
**CLOSED:**终点,不在连接状态。可以主动打开连接,或者等待对端的连接。