通过阅读 《learning scrapy》这本书提高自己的爬虫知识水平,记录些觉得比较有意思的地方吧
1 xpath
xpath是查找元素节点的重要工具。入门的话自行百度,下面是几个有意思的例子
- 任意div下面的a "//div//a"
- 任意a的文本 "//a/text()"
- 任意a的href "//a/@href"
- 任意div下的子节点 "//div/*"
- 任意含有href属性的a "//a[@href]"
- 任意含有href属性并且href含有qq的a "//a[contains(@href,"qq")]
- 任意含有href属性并且href以https开头的a "//a[starts-with(@href,"https)]"
- 任意含有href属性并且href不以https开头的a "//a[not(starts-with(@href,"https))]"
- 获得id为firstHeading的h1节点的子节点的span的文案 //h1[@id="firstHeading"]/span/text()
- 获得任意class含有ltr和skin-vector的节点下的任意子孙节点h1的文案 //*[contains(@class,"ltr") and contains(@class,"skin-vector")]//
h1//text() - 获得文案为References 的节点的父节点之后的所有兄弟节点下的a标签 //*[text()="References"]/../following-sibling::div//a
xpath查找小提示:
- 避免用 @class=“xxx”的方式查找,因为ui改版css class 变动的概率很大,而用contains会好很多
- 用 有特定意义的class定位比通用的好用,例如用 “miaosha” 好过 用“green”
3.id通常不会变,而且通常有唯一性,所以能用id定位尽量使用id
2. settings
scrapy 的setting配置是非常重要的一部分,按照功能模块划分一下主要的设置项
2.1 Analysis 分析用
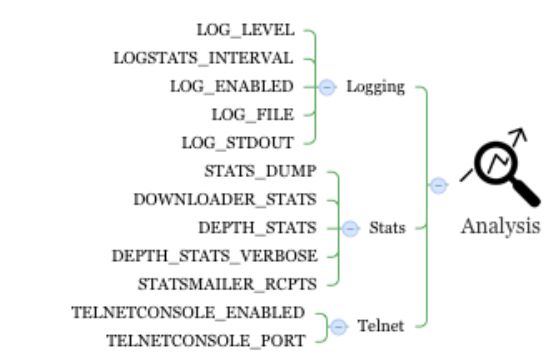
2.1.1 Logging
Scrapy 有不同等级的log: DEBUG (lowest level), INFO,
WARNING, ERROR, CRITICAL (highest level), SILENT(no logging). 可以设置log 文件只接受基本大于等于目标level.通过LOG_LEVEL设置
LOG_STDOUT 是是否所有输出 含print 写入日志文件
其他的可自己去查文档
2.1.2 Stats
STATS_DUMP : 默认为True ,是否在结束时将统计数据写入log文件,关于统计数据后面会写
DOWNLOADER_STATS : 默认 True,是否启用下载统计收集
DEPTH_STATS : 默认True,是否收集爬取深度统计信息
DEPTH_STATS_VERBOSE:默认False,收集爬取深度的完整信息
STATSMAILER_RCPTS : 爬取完成后发生统计信息的通知邮箱列表 如 ['[email protected]']
2.1.3 telnet 是在爬取过程中能够访问爬取状态的方式
scrapy 运行过程中能够通过 telnet 控制 pause continue 和 stop
TELNETCONSOLE_ENABLED 控制是否启用telnet ,默认为True
TELNETCONSOLE_PORT 是端口号,不用设置 程序会自己分配好
shell启动scrapy后输出
[scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023:6023
这样的控制台信息
然后可以通过
telnet localhost 6023
连接
通过
>>> engine.pause()
>>> engine.unpause()
>>> engine.stop()
控制
2.2 Performance性能相关
性能这块后面会细讲,这里只是描述下设置项

CONCURRENT_REQUESTS :并发数
CONCURRENT_REQUESTS_PER_DOMAIN 和CONCURRENT_REQUESTS_PER_IP 顾名思义是控制每个域名和ip的爬取并发数,
如果 CONCURRENT_REQUESTS_PER_IP不为0那么CONCURRENT_REQUESTS_PER_DOMAIN的配置会忽略
DOWNLOAD_TIMEOUT 是request发起后downloader的等待时间,超时取消request,默认180s
DOWNLOAD_DELAY 请求完成到下一次发起的间隔
RANDOMIZE_DOWNLOAD_DELAY Ture 表示对DOWNLOAD_DELAY进行+-%50区间的随机处理
DNSCACHE_ENABLED :默认Ture 使用内存中的dns缓存
2.3 中断和使用缓存
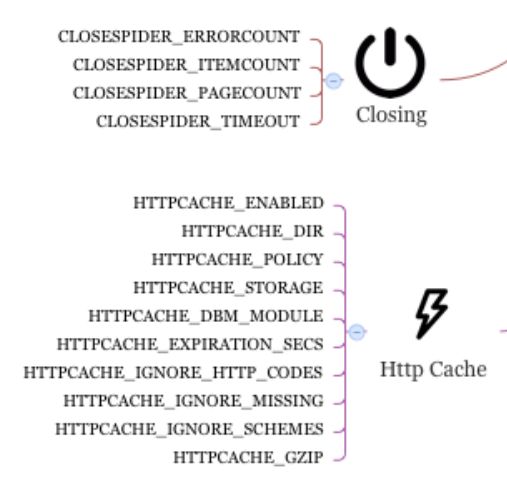
满足设置好的条件后spider可以自己停止爬取如
CLOSESPIDER_ITEMCOUNT:itempipeline处理了超过xx个item后 spider处理完未处理的任务后停止
CLOSESPIDER_TIMEOUT :爬取超时 xx秒后停止,0的话为不会因为超时停止
CLOSESPIDER_PAGECOUNT:处理了xx个response后停止
CLOSESPIDER_ERRORCOUNT:发生错误xx次停止 如http错误 404 500....,默认不会因为错误停止
如果使用了 HttpCacheMiddleware 的话 可以使用缓存设置
HTTPCACHE_ENABLED : 是否使用缓存,默认False
HTTPCACHE_DIR :缓存路径
HTTPCACHE_POLICY :Cache策略的实现类,默认是scrapy.extensions.httpcache.DummyPolicy
HTTPCACHE_STORAGE :缓存的存储方式,默认是 scrapy.extensions.httpcache.FilesystemCacheStorage
HTTPCACHE_DBM_MODULE :数据库模块 默认是anydbm
这一块如果用处大可以独立搞一套
3 Twisted
Scrapy是基于Twisted开发的,了解Scrapy之前学习一下Twisted对于理解也会加强吧
需要记得Twisted是基于事件驱动的网络框架,细节可以自行百度
deferred 是基础单位,可以用来构成事件驱动
简单的用法如下
from twisted.internet import defer
d=defer.Deferred()
print(d.called) #False
d.callback(3)
print(d.called) #True
print(d.result) #3
def addval(v):
print("inputval is"+str(v))
return v+1;
d=defer.Deferred()
d.addCallback(addval)
d.callback(3) # 驱动 addval(3)
print(d.result) #4
通过addCallback的方式可以改变回调事件链
from twisted.internet import defer
a=defer.Deferred()
b=defer.Deferred()
def a_callback(v):
print(v)
return {"value":v}
def b_callback(v):
print(v)
#返回deferred让事件链改变
return b
def c_callback(v):
print("ccallback",end=" ")
print(v)
a.addCallback(a_callback).addCallback(b_callback).addCallback(c_callback)
a.callback(3)
#print 3 然后print {'value': 3}
b.callback(99)
# ccallback 99
DeferredList用来构建事件链,只有参与构建的Deferred 全部有了callback 才会回调callback 事件,
import time
from twisted.internet import defer
from concurrent import futures
def done(v):
print("done with ",end="")
print(v)
deferreds=[defer.Deferred() for x in range(5)]
times=[1,2,2,1]
join=defer.DeferredList(deferreds)
join.addCallback(done)
def timesleep(sleepsecond,x):
print("sleep %s"%(sleepsecond))
time.sleep(sleepsecond)
deferreds[x].callback(x)
print("%s callbak %s"%(sleepsecond,x))
with futures.ThreadPoolExecutor(8) as pool:
for x in range(4):
append=pool.submit(timesleep,times[x],x)
deferreds[4].callback(99)
#全部完成后会打印
#done with [(True, 0), (True, 1), (True, 2), (True, 3), (True, 99)]
#如果使用了 errback ,True会变为False
通过inlineCallbacks 可以进行事件调度,下面的流程就是
d1 callback完,调 next 代码继续走 执行 d2 callback next 然后执行return 调用最外层的callback
from twisted.internet import reactor, defer
def loadRemoteData(callback):
import time
time.sleep(1)
callback(1)
def loadRemoteData2(callback):
import time
time.sleep(1)
callback(2)
@defer.inlineCallbacks
def getRemoteData():
d1 = defer.Deferred()
reactor.callInThread(loadRemoteData, d1.callback)
r1 = yield d1
d2 = defer.Deferred()
reactor.callInThread(loadRemoteData2, d2.callback)
r2 = yield d2
return r1 + r2
def getResult(v):
print("result=", v)
if __name__ == '__main__':
d = getRemoteData()
d.addCallback(getResult)
reactor.callLater(4, reactor.stop);
reactor.run()
4 scrapy 程序框架简述
可以先看下scrapy的工作框架图

我们写的spiders是工作架构的核心,它们用于创建request 、解析response 并且产出items和更多的requests
itemPipeline 是我们用来处理的item的管道
process_item() 可以用来处理item,我们处理完了item 可以return item,让下一个pipeline处理,也可以 raising DropItem exception 以结束这个item的后续处理流程
open_spider() 方法会在初始化spider的回调
close_spider() 方法会在spider结束的时候回调
downloader middlewares 是下载和请求的中间件,默认的下载中间件的源码可以在github上查看 SPIDER_MIDDLEWARES_BASE setting in settings/default_settings.py
4.1 itemPipeline 示例
from datetime import datetime
class TidyUp(object):
def process_item(self, item, spider):
item['date'] = map(datetime.isoformat, item['date'])
return item
然后修改setting.py的内容,满足
TEM_PIPELINES = {'properties.pipelines.tidyup.TidyUp': 100 }
properties.pipelines.tidyup.TidyUp为自定义的pipeline的完整类名