关于概率密度函数和分布函数的理解
理解1:
离散随机变量:随机变量的值可以都列举出来,则该随机变量称为离散型,例如,投掷骰子事件,该事件只出现两种情况:正面和反面,可以使用整数0和1表示,0表示反面,1表示证明,则可以用离散随机变量来表示投掷骰子事件。连续性随机变量就是不能使用数列举出来的情况,例如,
理解2:
概率密度函数=概率函数,只是应用的对象不同,概率函数对应离散随机变量,概率密度函数对应连续随机变量。
在离散随机变量中,概率密度函数被称为概率函数,顾名思义,就是关于概率的函数,例如:![]() ,其中,pi表示投掷骰子的事件的概率值,只有两个取值(0,1)。该表示中变量为x,随机变量X的取值不同,得到不同结果,即给定一个特定的X,得到一个对应的结果,所以该表达式为一个关于变量X的函数,也就是概率函数。
,其中,pi表示投掷骰子的事件的概率值,只有两个取值(0,1)。该表示中变量为x,随机变量X的取值不同,得到不同结果,即给定一个特定的X,得到一个对应的结果,所以该表达式为一个关于变量X的函数,也就是概率函数。
倘若随机变量为连续数值,则称为概率密度函数,为何?首先看概率密度函数数学定义:
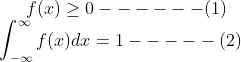
如果f(x)满足公式1和2,则f(x)就是概率密度函数。公式(1)表示概率密度函数的非负性,公式(2)表示各个取值累计和为1。从几何上将,公式(2)是函数f(x)图像下的面积,该面积为1。再看密度,密度第一想到是质量密度,密度=质量/体积,即单位体积下的质量,稍微推广下就是单位***下的***。回到公式(2),一种求积分的方法就是将函数f(x)分割为小的矩形框,也就是将整个面积分为多个小矩形框,通过对矩形框面积叠加得到总面积。好的,假设现在在x轴上等分f(x)N等分,则每个矩形的面积就1/N,结合质量密度定义公式,可以得到其实1/N表示的也是一种密度的概念,某个单位”长度“下的面积,只不过这个长度可以极限小。这也就是定义中为何为密度的一个原因。另外,这里矩形面积其实就是概率的含义,看下面的公式更容易理解:
![]()
公式(3)表示随机变量X在区间a和b之间发生的概率,注意这里是概率,其实就是在概率密度函数下a和b区间上的面积,这里的面积就是概率。
理解3:
分布函数首先也是一个函数,就是给定一个值,映射到另一个值,另外它表示的是分布,分布描述的是数据整体的情况。离散情况下,用概率分布列表来表示,很简单因为离散的情况下,随机变量的所有取值都可以列举出来,所以将所有情况放到一个表中就是概率分布列表,等价于分布函数。两个重点,一个是有变量,一个是有对应的概率,并且所有变量和概率都要取到。
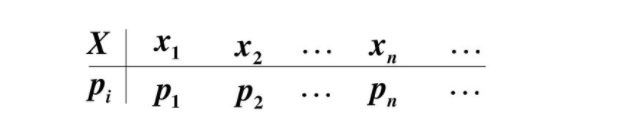
对于连续性随机变量怎么办?将公式(3)推广到积分上限就是连续随机变量分布函数:
![]()
首先公式(4)也是一个关于y的函数, 其次变量y包括了所有变量,y本身是一个变量,它可以是任意数,所以包含了所有变量。
对照离散随机变量分布函数,一有变量y,二是有对应的概率值(即积分值),三所有情况都考虑了,所以公式(4)就是分布函数。另一方面,从公式(4)可以看处分布函数就是概率密度函数的累计和(积分就是累积和哈),不理解,看离散随机变量分布函数定义:
![]()
公式(5)表示F(x)就是一个累积和,累积加和在连续变量的情况下就是积分。
PS:python中使用
概率密度函数使用
python中可以使用科学计算包scipy中的统计模块实现概率密度函数,分布函数的计算,计算前可以对数据进行标准化处理,然后标准正态分布在某个点的概率密度可用scipy.stats.norm.pdf计算。借用别人的代码绘图正态分布:
from scipy import stats
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False#用来正常显示负号
#正态分布概率密度
X = []
Y = []
for a in np.linspace(-5, 5, 100):
y = stats.norm.pdf(a)
X.append(a)
Y.append(y)
plt.plot(X, Y)
plt.xlabel("x")
plt.ylabel("p")
plt.title("正态分布概率密度")
plt.show()
运行后得到:

默认情况,scipy.stats.norm.pdf计算均值为0,方差为1 的正态分布,x轴上某个点对应的p值不是概率,不是概率,不是概率,是概率密度,衡量的是事件在该点处出现的密度(频率),连续随机变量在某个值的概率是0,但是根据公式(3),在x轴上某个区间的面积是概率,表示事件在该区间内出现的概率。
计算某个值在正态分布中的概率,需要知道均值和标准差,p=scipy.stats.norm.pdf(x, loc=均值,scale = 标准差)/标准差=scipy.stats.norm.pdf(x)
分布函数使用
分布函数使用scipy.stats.norm.cdf,同样借用别人的代码看下分布函数的样子:
from scipy import stats
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False#用来正常显示负号
#正态分布概率密度
X = []
Y = []
for a in np.linspace(-5, 5, 100):
y = stats.norm.cdf(a)
X.append(a)
Y.append(y)
plt.plot(X, Y)
plt.xlabel("x")
plt.ylabel("p")
plt.title("正态分布累积概率分布")
plt.show()
结果如图:
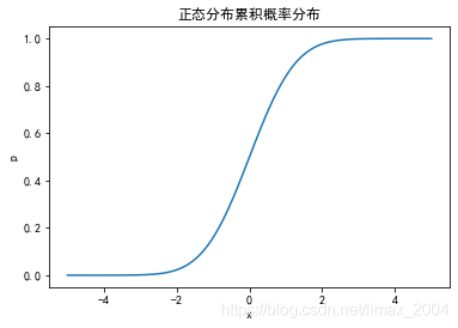
可以看处,分布函数是一个递增函数,肯定是啊,因为它是一个累积和啊,而且最大值为1(所有概率加和为1)。x轴某点对应的值表示事件![]() 发生的概率。
发生的概率。
查表的话,同概率密度函数用法相同:p=scipy.stats.norm.cdf(x, loc=均值,scale = 标准差)。
产生正态分布样本
使用numpy中的np.random.normal()函数:
import numpy as np
#设置随机数种子seed
np.random.seed(456789)
#生成15个均值为10,标准差为2的正态分布样本
r = np.random.normal(loc=10, scale=2, size=15)
print(r)