An image is worth 16x16 words:Transformers for image recognition at scale(论文阅读)
被美东时间折磨的一天
今天参加了Journal Club,第一次参加这样的journal分享讨论,收获满满。
这一期分享的paper是:An image is worth 16x16 words:Transformers for image recognition at scale
一、概述
CV------>CNN------>CNN as Backbone Attention as asuxiliary
NLP----->RNN----->Conv Seq2Seq------>Attention(Transformer)
这篇文章:
1、对于cnn的依赖是不必要的
2、pure transformer直接应用于图像patches序列可以很好地实现图像分类任务。
- 在mid-sized的数据上训练,精度比同等规模的ResNet网络低几个百分点;
- 在大规模的数据集上训练,迁移到较小规模的数据集上结果>= state of the art。(特别是,最佳模型在ImageNet上达到88.55%,在ImageNet-ReaL上达到90.72%,在CIFAR-100上达到94.55%,在19个任务的VTAB套件上达到77.63%。)
做法:
将image 分成一个个patch,然后把这些patches的线性嵌入序列输入到Transformer,这些patches在nlp任务中相当于tokens或者是words。
二、模型原理(Vision Transformer----ViT)
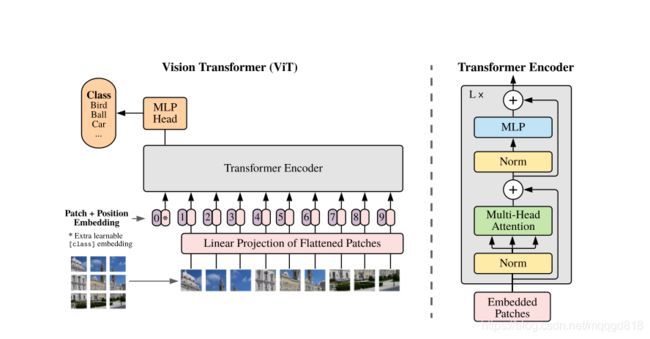
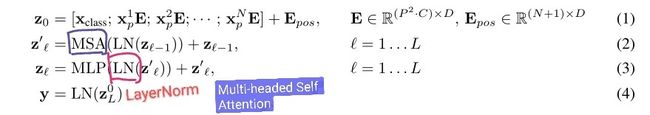
Transformer的输入是一维序列,而图片数据都是二维的。因此使用Patch Embedding的方法将图片以合适的方式输入到模型中。
首先,将原始图片划分为多个patch子图,每个子图相当于一个token。接着,对每个patch进行embedding,通过一个线性变换层将二维的patch嵌入表示为长度为D的一维向量,并添加位置嵌入信息(0,1,2,…),即每个patch在原始图像中的位置信息。(目的是:引入位置信息有利于模型正确评估注意力权重)。图像中0的位置是起一个占位符的作用,类似Bert中的CLS(不太了解Bert…不太懂这个操作)
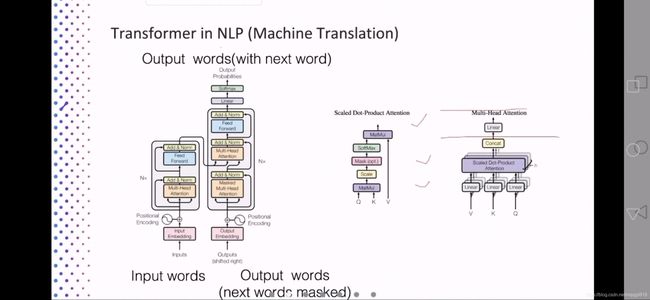
- 引入Transforme在机器翻译任务上的应用,解释Transformer的工作机制。ViT的模型之只是采用了Encoder部分。
- Q、K、V表示同一个句子中不同token组成的矩阵。矩阵中的每一行,是表示一个token的word embedding向量。其中Q和K先做点乘,可以理解为一个句子中的token与其他token之间的一个相似度(attention score),然后这个相似度与V相乘,得到一个加权后的结果[参考]
三、实验
1、Typical model setting
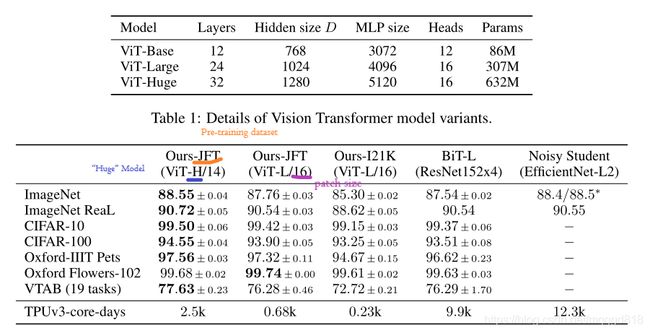
ViT-Base 、ViT-Large、ViT-Huge 是借鉴了Bert那篇论文。Ours-JFT表示本文模型在JFT-300M数据集上进行了与训练。14和16表示pitch size。可以看出规模较小的ViT-L在各个数据集上都超过了ResNet,并且其所需的算力也要少十多倍。
2、Experiment setting
数据集:
ImageNet 1.3M images 1K classes
ImageNet-21k 14M images 21K classes
JFT 300M images 18K classes
ImageNet Real cleaned-up labels
CIFAR-10/100
Oxford Ptes/Flowers
VTAB 19-task Natural-tasks like the above,Pets,CIFAR,etc.
Specialized-medical and satellite imagery
Structured-tasks that require geometric understanding like localization
Baseline Model:
- ResNet(BiT)
ResNet + GroupNorm(replace BN) + Standardized convolutions
- Noisy Student
A large EfficientNet trained using semi-supervised learning on ImageNet and JFT-300M with the labels removed.
3、Training set size & Performance
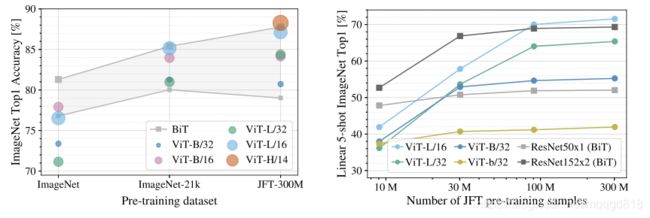
左图可以看出,预训练数据集size越大,最终的性能越好,“Huge ”Model(ViT-H/14)要高于较小的(ViT-L);
右图可以看出ViT本身的性能上限要优于ResNet,随着数据规模的增大,ViT模型要远远高于ResNet。可以看出注意力机制可以几乎代替CNN了。
4、Visualization
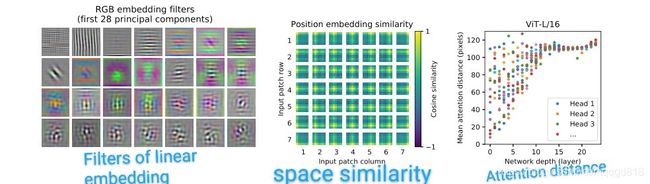
左图是每个patch的低维表示,中间的图是位置嵌入的相似性,可以看到同一行或者列的patch具有相似的embeddings
右图是根据注意力权重计算图像空间中整合信息的平均距离。可以看到Head在低层的注意距离很小,随着网络层数的增加,attention距离也在增加。

可视化的结果可以看到模型关注的是与分类语义相关的图像区域
四、注意力机制在CV中的应用(引言):
*这部分可能对今后的学习有帮助
1、注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持他们的整体结构不变。
注意力架构的相关工作:
- local multi-head dot-product self attention blocks can completely replace convolutions
- such as Sparse Transformers (Child et al., 2019) employ scalable approximations to global self attention in order to be applicable to images.
- An alternative way to scale attentionis to apply it in Blocks of varying sizes(Weissenbornetal.,2019), in the extreme case only along individual axes(Hoet al., 2019; Wang et al., 2020a).
缺点:复杂,计算效率低
2、CNN与self-attention相结合的:
- by augmenting feature maps for image classification
- by further processing the output of a CNN using self-attention
五、总结
- Position embedding的信息可以让每个slot往学习到的特定区域去寻找目标。在生成任务中是否能加入position embedding的信息将文本主题对应到图像的区域?
- 看到主讲人做的ppt,对比自己平时做的PPT,真的没眼看了。。汇报的时候对涉及到的一些背景模型要有一定的了解。
- 下次听报告前,一定要熟读论文,带着问题听报告,提前列好就自己方向相关的问题