【Transformer 01】AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
机器学习算法在学习过程中对某种类型假设的偏好,称为归纳偏好,简称偏好
Abstract
Transformer框架是自然语言处理的常用结构,但它在计算机视觉上的应用较少。在视觉中,注意力通过和CNN一起使用,或在保持整体结构不变的情况下,替换CNN的某个部分。本文展示了依赖CNN是不必须的,并且在分类任务中,直接对一系列图片块使用transformer是可行的。
当在大量数据上预训练,然后转移到多个大中型或小型图像识别benchmarks(ImageNet, CIFAR-100, VTAB等)。与sota卷积网络相比,Vision Transformer (ViT)获得更出色的结果,但所需训练资源却大大减少。
Introduction
Transformer在NLP中有着大量的应用,通常是在一个大型文本预料上预训练,然后在特定任务数据集上fine-tune。同时,Transformer还体现出了高效和可拓展性,使得我们可以训练参数超过100B的模型。
在CV,CNN依旧占主导地位。受NLP启发,一些工作将self-attention和卷积网络相结合,一些将卷积网络完全替代。后一种模型,虽然理论上有效,但由于使用了专门的attention patterns,尚未拓展到硬件加速平台上。因此,在大规模图片识别中,经典的类ResNet结构仍然是最优的。
受NLP启发,我们将标准的Transformer直接应用到图片上。本文将图片切分为块,并且将这些块的线性嵌入序列作为Transformer的输入。Image Patches被视作tokens (words),以有监督的方式训练。
模型在中型数据集,例如ImageNet上训练,正确率比ResNet低几个点。这个结果是可以被理解的,因为Transformer相较CNNs,缺少一些固有的归纳偏置,例如:平移不变性和空间局部性(translation equivariance and locality,滑动卷积在共享权重,降低参数空间的同时,也引入归纳偏置),因此在不充足数据下训练,会导致模型泛化性不足。
但是,当模型在更大数据集(14M-300M图片)上训练,胜过了inductive bias。当在ImageNet-21k或in-house JFT-300M数据集上预训练时,ViT在多项图片识别benchmarks上取得了很好的结果:ImageNet上取得88.55%,在ImageNet-ReaL上取得90.72%,在CIFAR-100上取得94.55%,在VTAB的19个基础任务上取得77.63%。
Related Work
图片上的简单应用要求每个像素与其他所有像素相关联,这需要像素数量平方的计算复杂度,导致该方法不能简单拓展到真实图片上。因此,前人提出很多近似的方法:(1)仅在局部领域上使用,而不是全局;(2)局部multi-head dot-product self attention模块,可以完全取代卷积;(3)采用scalable approximations实现全局self-attention,或是应用在不同尺寸的块上,甚至仅应用在单独的坐标轴上。这些方法效果不错,但在硬件加速上,需要复杂的工程实现。
还有很多工作致力于CNN和self-attention的结合。例如:(1)用于图像分类的增强特征映射,或是对CNN的输出使用self-attention,例如object detection,video processing,image classification,unsupervised object discovery,或是unified text-vision tasks。
和我们模型相近的是iGPT,在降低图片分辨率和颜色空间后,对图片像素使用Transformers。该模型以无监督方式训练,之后可以fine-tuned以提高分类性能,在ImageNet上准确率达到72%。
本文的工作致力于探索更大规模数据集上的图片识别,而不是标准ImageNet数据集。额外使用的数据集使得模型在标准benchmark上达到sota。
METHOD
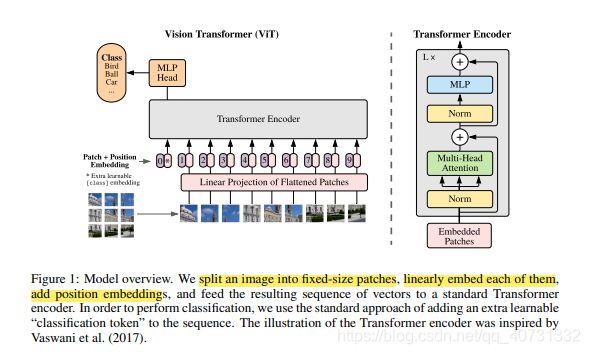
对每一张输入图片(H x W x C),切割为(P, P, C)的小块,并将小块flatten为P * P * C的单维向量,最后得到(N, P*P*C)的序列,其中N = HW / P*P。因为Transformer的输入维度为固定大小D,因此,我们用一个trainable linear projection将patches投影为D维。
和BERT's的[class] token类似,我们预置一个可学习的embeded patches xclass,作为图片的标签输出。在pre-training和fine-tuning过程中,xclass始终作为classification head的输入,其中classification head在预训练时是:a MLP with one hidden layer,在fine-tuning time时:a single linear layer。
位置信息被嵌入patch embeddings中。本文使用标准的可学习1维位置嵌入,因为我们发现,使用2D位置嵌入没有显著的改善。
本文使用了Transformer的encoder部分,它包含了可选的多层self-attention(MSA)和MLP blocks(Eq. 2, 3)。Layernorm(LN)和残差连接被使用。MLP包含带有GELU non-linearity的两层网络。

混合结构:patch除了来自图片,也可以是CNN的feature maps。
Fine-tuning和更高的分辨率:Fine-tuning时,我们移除pre-trained prediction head,然后加上一个由零初始化的 (D x K) 的前馈层。其中K是下游分类任务的类别数。当输入更高分辨率的图片时,我们保持P不变,增加N的数量。ViT可以输入任意多的sequence,上限取决于内存,但是会导致pre-trained position embeddings失去意义,因此,本文根据它的位置,对它进行二维插值。注意,这里的resolution adjustment and patch extraction是图片2D结构唯一的归纳偏置,被我们人为加入到ViT当中。
Experiments
在JFT(18k类别,303M高分辨率图片)和ImageNet-21k(21k类别,14M图片),对模型进行测试,模型后的数字代表输入的patch size。可以看到相较于ResNet152,ViT训练时间更短,同时效果更好。
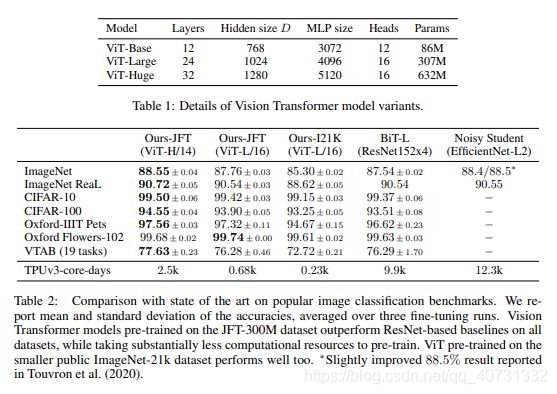
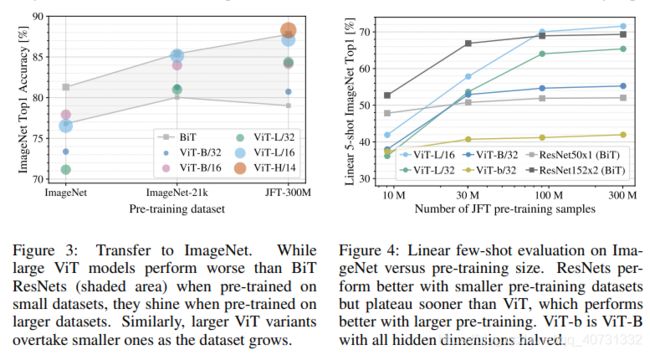
图3探究训练数据量对模型的影响,发现在训练数据较少的情况下(同时进行了正则化优化), 表现不如ResNet,只有在大量数据的情况下,会超过。图4探究计算量和准确率的关系,分别在9M,30M,90M和完整JFT-300M上训练,结果的变化。
实验部分请参考:https://blog.csdn.net/qq_16236875/article/details/108964948