Opencv图像处理--形态学操作
1 连通性
在图像中,最小的单位是像素,每个像素周围有8个临界像素,常见的邻接关系有3种:4邻接、8邻接和D邻接。分别如下图所示:

- 4邻接:像素p(x,y)的4邻域是:(x+1,y);(x-1,y);(x,y+1);(x,y-1),用N4§表示像素p的4邻域
- D邻接:像素p(x,y)的D邻域是:对角上的点(x+1,y+1);(x+1,y-1);(x-1,y+1);(x-1,y-1),用ND§表示像素p的D邻域
- 8邻接:像素p(x,y)的8邻域是:4邻域的点+D邻域的点,用N8§表示像素p的8邻域
连通性是描述区域和边界的重要概念,两个像素连通的两个必要条件是:
- 两个像素的位置是否相邻
- 两个像素的灰度值是否满足特定的相似性准则(或者是否相等)
根据连通性的定义,有4联通、8联通和m联通三种。
-
4联通:对于具有值V的像素p和q,如果q在集合N4(p)中,则称这两个像素是4连通
-
8联通:对于具有值V的像素p和q,如果q在集合N8(p)中,则称这两个像素是8连通
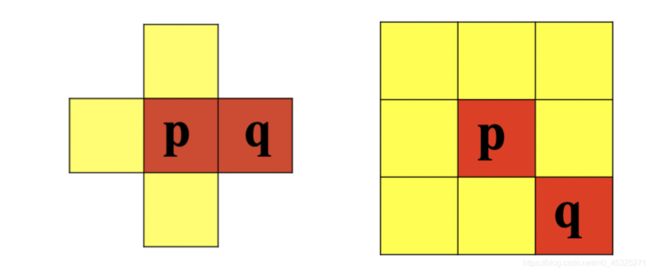
-
对于具有值V的像素p和q,如果:
- q在集合N4(p)中,或
- q在集合ND(p)中,并且N4(p)和N4(q)的集合为空(没有值V的像素)
则称这两个像素是m连通的,即4连通和D连通的混合连通。

2 形态学操作
形态学转换是基于图像形状的一些简单操作。它通常在二进制图像上执行。腐蚀和膨胀是两个基本的形态学运算符。然后它的变体形式如开运算,闭运算,礼帽黑帽等。
2.1 腐蚀和膨胀
腐蚀和膨胀时最基本的形态学操作,腐蚀和膨胀都是针对白色部分(高亮部分)而言的。
膨胀就是使图像中高亮部分扩张,效果图拥有比原图更大的高亮区域;腐蚀是原图中的高亮区域被蚕食,效果图拥有比原图更小的高亮区域。膨胀是求局部最大值的操作,腐蚀是求局部最小值的操作。
-
腐蚀
具体操作是:用一个结构元素扫描图像中的每一个像素,用结构元素中的每一个像素与其覆盖的像素做“与”操作,如果都为1,则该像素为1,否则为0。如下图所示,结构A被结构B腐蚀后:(下图中最上面的方格是错误的!!!)
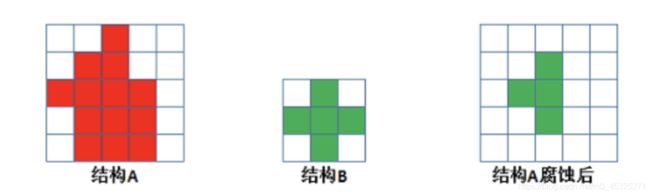
腐蚀的作用是消除物体边界点,使目标缩小,可以消除小于结构元素的噪声点。
API:
cv.erode(img,kernel,iterations)参数:
- img:要处理的图像
- kernel:核结构
- iterations:腐蚀的次数,默认为1
-
膨胀
具体操作是:用一个结构元素扫描图像中的每一个像素,用结构元素中的每一个像素与其覆盖的像素做“与”操作,如果都为0,则该像素为0,否则为1.如下图所示,结构A被结构B腐蚀后:

作用是将与物体接触的所有背景点合并到物体中,使目标增大,可添补目标中的孔洞。
API:
cv.dilate(img,kernel,iterations)参数:
- img:要处理的图像
- kernel:核结构
- iterations:腐蚀的次数,默认为1
-
示例
使用一个5*5的卷积核实现腐蚀和膨胀的运算:
import numpy as np import cv2 as cv import matplotlib.pyplot as plt # 1 读取图像 img = cv.imread("D:\Projects notes\opencv\image\letter.png") # 2 创建核结构 kernel = np.ones((5, 5), np.uint8) # 3 图像腐蚀和膨胀 erosion = cv.erode(img, kernel) # 腐蚀 dilate = cv.dilate(img, kernel) # 膨胀 # 4 图像展示 fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(10, 8), dpi=100) axes[0].imshow(img) axes[0].set_title("原图") axes[1].imshow(erosion) axes[1].set_title("腐蚀后的结构") axes[2].imshow(dilate) axes[2].set_title("膨胀后的图像") plt.show()

2.2 开闭运算
开运算和闭运算是将腐蚀和膨胀按照一定的次序进行处理。但这两者并不是可逆的,即先开后闭并不能得到原来的图像。
-
开运算
开运算使先腐蚀后膨胀,其作用是:分离物体,消除小区域。
特点:下厨早点,去除小的干扰快,而不影响原来的图像。
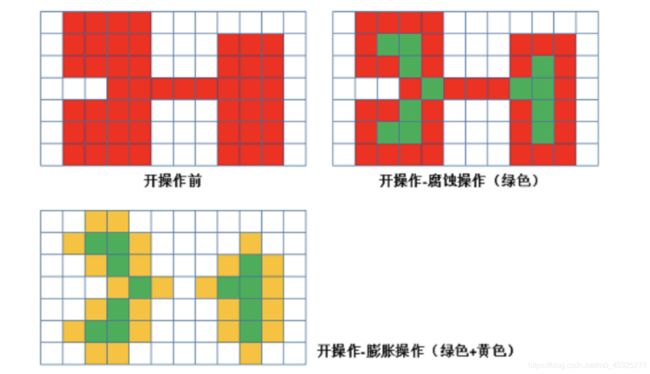
-
闭运算
闭运算与开运算相反,是先膨胀后腐蚀,作用是“消除/闭合”物体里面的孔洞。
特点:可以填充闭合区域

-
API
cv.morphologyEx(img, op, kernel)参数:
- img:要处理的图像
- op:处理方式:若进行开运算,则设为cv.MORPH_OPEN,若进行闭运算,则设为cv.MORPH_CLOSE
- kernel:核结构
-
示例
使用10*10的核结构对卷积进行开闭运算的实现
import numpy as np import cv2 as cv import matplotlib.pyplot as plt # 1 读取图像 img1 = cv.imread("D:\Projects notes\opencv\image\letteropen.png") img2 = cv.imread("D:\Projects notes\opencv\image\letterclose.png") # 2 创建核结构 kernel = np.ones((10, 10), np.uint8) # 3 图像的开闭运算 cvopen = cv.morphologyEx(img1, cv.MORPH_OPEN, kernel) # 开运算 cvclose = cv.morphologyEx(img2, cv.MORPH_CLOSE, kernel) # 闭运算 # 4 图像显示 fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10, 8), dpi=100) plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文 axes[0, 0].imshow(img1) axes[0, 0].set_title("原图") axes[0, 1].imshow(cvopen) axes[0, 1].set_title("开运算结果") axes[1, 0].imshow(img2) axes[1, 0].set_title("原图") axes[1, 1].imshow(cvclose) axes[1, 1].set_tit le("闭运算结果") plt.show()
2.3 礼帽和黑帽
-
礼帽运算
原图像与“开运算”的结果图之差,如下式计算:
d s t = t o p h a t ( s r c , e l e m e n t ) = s r c − o p e n ( s r c , e l e m e n t ) dst = tophat(src, element) = src - open(src, element) dst=tophat(src,element)=src−open(src,element)
因为开运算带来的结果是放大了裂缝或者局部低亮度的区域,因此,从原图中减去开运算后的图,得到的效果图突出了比原图轮廓周围的区域更明亮的区域,且这一操作和选择的核的大小相关。礼帽运算用来分离比临近点亮一些的斑块,当一幅图像具有大幅的背景的时候,而微小物品比较有规律的情况下,可以使用顶帽运算进行背景提取。
-
黑帽运算
为“闭运算”的结果图与原图像之差。数学表达式为:
d s t = b l a c k h a t ( s r c , e l e m e n t ) = c l o s e ( s r c , e l e m e n t ) − s r c dst = blackhat(src, element) = close(src, element) - src dst=blackhat(src,element)=close(src,element)−src
黑帽运算后的效果图突出了比原图轮廓周围的区域更暗的区域,且这一操作核选择的核的大小相关。黑帽运算用来分离比邻近点暗一些的斑块。
-
API
cv.morphologyEx(img, op, kernel)参数:
-
img:要处理的图像
-
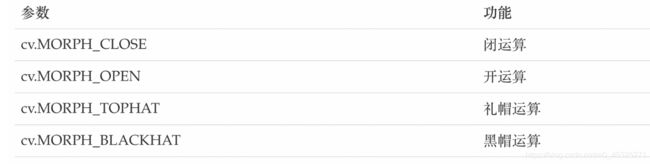
op:处理方式:
-
kernel:核结构
4.示例
import numpy as np import cv2 as cv import matplotlib.pyplot as plt # 1 读取图像 img1 = cv.imread("D:\Projects notes\opencv\image\letteropen.png") img2 = cv.imread("D:\Projects notes\opencv\image\letterclose.png") # 2 创建核结构 kernel = np.ones((10, 10), np.uint8) # 3 图像的礼帽和黑帽运算 cvOpen = cv.morphologyEx(img1, cv.MORPH_TOPHAT, kernel) # 礼帽运算 cvClose = cv.morphologyEx(img2, cv.MORPH_BLACKHAT, kernel) # 黑帽运算 # 4 图像显示 fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10, 8), dpi=100) plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文 axes[0, 0].imshow(img1) axes[0, 0].set_title("原图") axes[0, 1].imshow(cvOpen) axes[0, 1].set_title("礼帽运算结果") axes[1, 0].imshow(img2) axes[1, 0].set_title("原图") axes[1, 1].imshow(cvClose) axes[1, 1].set_title("黑帽运算结果") plt.show() -

3 图像平滑
由于图像采集、处理、传输等过程不可避免的会受到噪声的污染,妨碍人们对图像理解及分析处理。常见的图像噪声有高斯噪声、椒盐噪声等。
1 图像噪声
1.1 椒盐噪声
椒盐噪声也称为脉冲噪声,是图像中经常见到的一种噪声,它是一种随机出现的白点或黑点,可能是亮的区域有黑色像素或是在暗的区域有白色像素(或是两者皆有)。椒盐噪声的成因可能是影像讯号受到突如其来的强烈干扰而产生、类比数位转换器或位元传输错误等。例如失效的感应器导致像素值为最小值,饱和的感应器导致像素值为最大值。

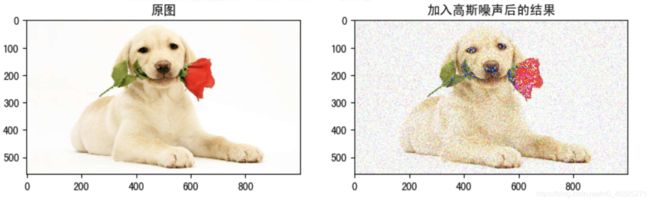
1.2 高斯噪声
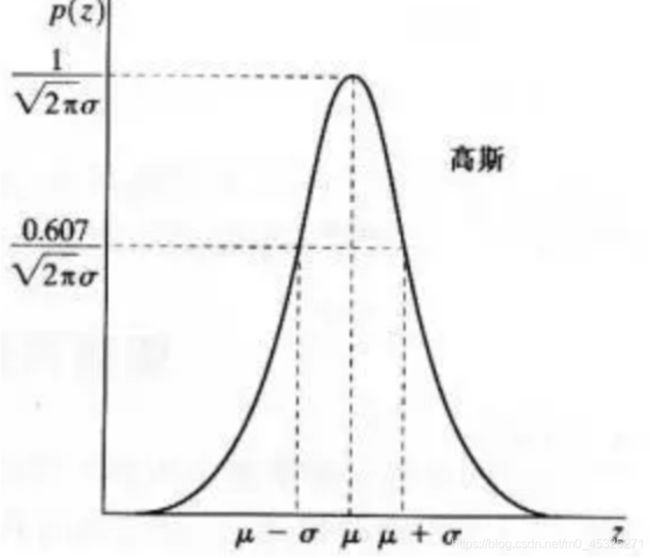
高斯噪声是指噪声密度函数服从高斯分布的一类噪声。由于高斯噪声在空间和频域中数学上的易处理性,这中噪声(也称为正态噪声)模型经常被用于实践中。高斯随机变量z的概率密度函数由下式给出:
p ( z ) = 1 2 π σ e − ( z − μ ) 2 2 σ 2 p(z) = \frac{1}{\sqrt{2\pi}\sigma}e^\frac{-(z-\mu)^2}{2\sigma^2} p(z)=2πσ1e2σ2−(z−μ)2
其中z表示灰度值, μ \mu μ表示z的平均值或期望值, σ \sigma σ表示z的标准差。标准差的平方 σ 2 \sigma^2 σ2称为z的方差。高斯函数的曲线如图所示:
2 图像平滑简介
图像平滑从信号处理的角度看就是去除其中的高频信息,保留低频信息。因此我们可以对图像实施低通滤波。低通滤波可以去除图像中的噪声,对图像进行平滑。
根据滤波器的不同可分为均值滤波、高斯滤波、中值滤波、双边滤波。
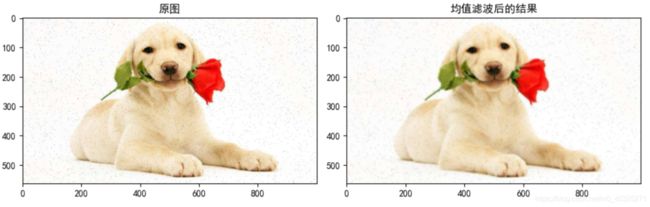
2.1 均值滤波
采用均值滤波模板对图像噪声进行滤波。令 S x y S_{xy} Sxy表示中心在(x,y)点,尺寸为mxn的矩形子图像窗口的坐标组。均值滤波器可表示为:
f ^ ( x , y ) = 1 m n ∑ ( s , t ) ∈ S x y g ( s , t ) \widehat{f}(x,y)=\frac{1}{mn}\sum_{(s,t)\in S_{xy}}{g(s,t)} f (x,y)=mn1(s,t)∈Sxy∑g(s,t)
由一个归一化卷积框完成的。它知识用卷积框覆盖区域所有像素的平均值来代替中心元素。
例如,3x3标准化的平均过滤器如下所示:
K = 1 9 [ 1 1 1 1 1 1 1 1 1 ] (3) K=\frac{1}{9}\left[ \begin{matrix} 1 & 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{matrix} \right] \tag{3} K=91⎣⎡111111111⎦⎤(3)
均值滤波的优点是算法简单,计算速度较快,缺点是在去噪的同时去除了很多细节部分,将图像变得模糊。
API:
cv.blur(src, ksize, anchor, borderType)
参数:
- src:输入图像
- ksize:卷积核的大小
- anchor:默认值(-1,-1),表示核中心
- borderYType:边界类型
示例:
from matplotlib import pyplot as plt
import cv2 as cv
import numpy as np
# 1 图像读取
img = cv.imread("D:\Projects notes\opencv\image\dogsp.jpeg")
# 2 均值滤波
blur = cv.blur(img, (5, 5))
# 3 图像显示
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 8), dpi=100)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文
axes[0].imshow(img[:, :, ::-1])
axes[0].set_title("原图")
axes[1].imshow(blur[:, :, ::-1])
axes[1].set_title("腐蚀后的结构")
plt.show()
2.2 高斯滤波
二维高斯是构建高斯滤波器的基础,其概率分布函数如下所示:
G ( x , y ) = 1 2 π σ 2 e x p { − x 2 + y 2 2 σ 2 } (6) G(x,y) = \frac{1}{2\pi \sigma^2}exp\begin{Bmatrix} -\frac{x^2+y^2}{2\sigma^2} \end{Bmatrix} \tag{6} G(x,y)=2πσ21exp{ −2σ2x2+y2}(6)
G(x, y) 的分布是一个突出的帽子的形状,这里的 σ \sigma σ可以看作两个值,一个是x方向的标准差 σ x \sigma_x σx,另一个是y方向的标准差 σ y \sigma_y σy。

当 σ x \sigma_x σx和 σ y \sigma_y σy取值越大,整个形状趋近于扁平;当 σ x \sigma_x σx和 σ y \sigma_y σy取值越小,整个形状越突起
正态分布是一种钟形曲线,越接近中心,取值越大,越远离中心,取值越小。计算平滑结果时,只需要将”中心点“作为原点,其他点按照其在正态曲线上的位置,分配权重,就可以得到一个加权平均值。
高斯平滑在从图像中去除高斯噪音方面非常有效。
高斯平滑的流程:
- 首先确定权重矩阵
假定中心点的坐标是(0,0),那么距离它最近的8个点的坐标如下:

更远的点以此类推。
为了计算权重矩阵,需要设定 σ \sigma σ的值。假定 σ = 1.5 \sigma=1.5 σ=1.5,则模糊半径为1的权重矩阵如下:
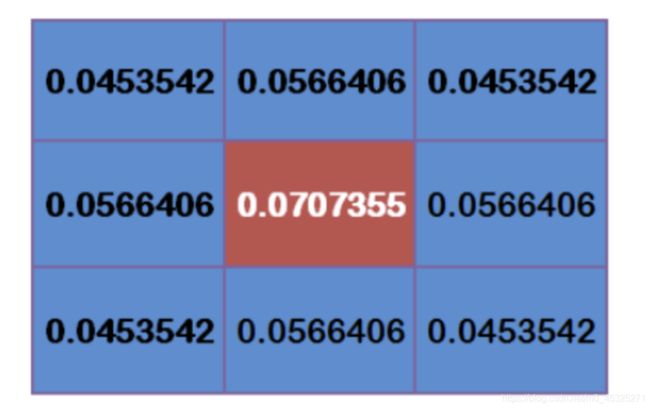
这9个点的权重总和等于0.4787147,如果只计算这9个点的加权平均,还必须让它们的权重之和等于1,因此上面9个值还要分别除以0.4787147,得到最终的权重矩阵。

- 计算高斯模糊
有了权重矩阵,就可以计算高斯模糊的值了。
假设现有9个像素点,灰度值(0-255)如下:

每个点乘以对应的权重值:

得到:
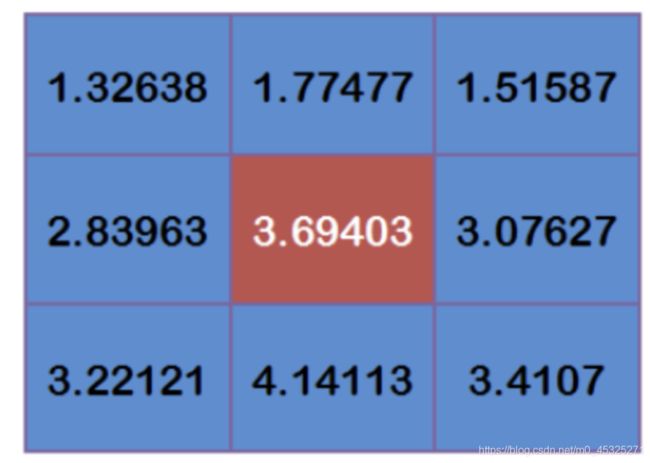
将这9个值加起来,就是中心点的高斯模糊的值。
对所有点重复这个过程,就得到了高斯模糊后的图像。如果原图是彩色图像,可以对RGB三个通道分别做高斯平滑。
API:
cv2.GaussianBlur(src, ksize, sigmaX, sigmaY, borderType)
参数:
- src:输入图像
- ksize:高斯卷积核的大小,注意:卷积核的宽度和高度都应为奇数,且可以不同
- sigmaX:水平方向的标准差
- sigmaY:垂直方向的标准差,默认值为0,表示与sigmaX相同
- borderType:填充边界类型
示例:
from matplotlib import pyplot as plt
import cv2 as cv
import numpy as np
# 1 图像读取
img = cv.imread("D:\Projects notes\opencv\image\dogGauss.jpeg")
# 2 高斯滤波
blur = cv.GaussianBlur(img, (3, 3), 1)
# 3 图像显示
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 8), dpi=100)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文
axes[0].imshow(img[:, :, ::-1])
axes[0].set_title("原图")
axes[1].imshow(blur[:, :, ::-1])
axes[1].set_title("高斯滤波后的结果")
plt.show()

2.3 中值滤波
中值滤波是一种典型的非线性滤波技术,基本思想是用像素点邻域灰度值的中值来代替该像素点的灰度值。
中值滤波对椒盐噪声来说尤其有用,因为它不依赖于邻域内那些与典型值差别很大的值。
API:
cv.medianBlur(src, ksize)
参数:
- src:输入图像
- ksize:卷积核的大小
示例:
from matplotlib import pyplot as plt
import cv2 as cv
import numpy as np
# 1 图像读取
img = cv.imread("D:\Projects notes\opencv\image\dogsp.jpeg")
# 2 高斯滤波
blur = cv.medianBlur(img, 5)
# 3 图像显示
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 8), dpi=100)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文
axes[0].imshow(img[:, :, ::-1])
axes[0].set_title("原图")
axes[1].imshow(blur[:, :, ::-1])
axes[1].set_title("中值滤波后的结果")
plt.show()

3 直方图
3.1 灰度直方图
- 原理
直方图是对数据进行统计的一种方法,并且将统计值组织到一系列实现定义好的bin当中。其中,bin为直方图中经常用到的一个概念,可以译为”直条“或”组距“,其数值是从数据中计算出的特征统计量,这些数据可以是诸如梯度、方向、色彩或任何其他特征。
图像直方图是用以表示数字图像中亮度分布的直方图,标绘了图像中每个亮度值的像素个数。这种直方图中,横坐标的左侧为较暗的区域,而右侧为较亮的区域。因此一张较暗图片的直方图中的数据多集中与左侧和中间部分,而整体明亮、只有少量阴影的图像则相反。

注意:直方图是根据灰度图进行绘制的,而不是彩色图像。
假设有一张图像的信息(灰度值0-255),已知数字的范围包含256个值,于是可以按一定规律将这个范围分割为子区域(也就是bins)。如:
[ 0 , 255 ] = [ 0 , 15 ] ∪ [ 16 , 30 ] ⋯ ∪ [ 240 , 255 ] [0, 255]=[0,15]\cup[16,30]\cdots\cup[240,255] [0,255]=[0,15]∪[16,30]⋯∪[240,255]
然后再统计每一个bin(i)的像素数目。可以得到下图(其中x轴表示bin,y轴表示各个bin中的像素个数):

直方图中的一些术语和细节:
- dims:需要统计的特征数目。在上例中,dims=1,因为仅仅统计了灰度值
- bins:每个特征空间子区段的数目,可译为”直条“或”组距“,在上例中,bins=16
- range:要统计特征的取值范围。在上例中,range=[0,255]
直方图的意义:
- 直方图是图像中像素强度分布的图像表达方式
- 它统计了每一个强度值所具有的像素个数
- 不同的图像的直方图可能是相同的
- 直方图的计算和绘制
使用opencv中的方法统计直方图,并使用matplotlib将其绘制出来
API:
cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]])
参数:
- images:原图像,当传入函数时应该用中括号[]括起来,例如:[img]
- channels:如果输入图像是灰度图,它的值就是[0];如果是彩色图像的话,传入的参数可以是[0],[1],[2]。它们分别对用着通道B,G,R
- mask:掩模图像。要统计整幅图像的直方图就把它设为None。但是如果你想统计图像某一部分的直方图的话,你就需要制作一个掩模图像,并使用它(后面有例子)
- histSize:bin的数目,也应该用中括号括起来,例如:[256]
- ranges:像素值范围,通常为[0, 256]
示例:
如下图,绘制相应的直方图
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
# 1 直接以灰度图的方式读入
img = cv.imread("D:\Projects notes\opencv\image\_20201226153617.jpg", 0)
# 2 统计灰度图
histr = cv.calcHist([img], [0], None, [256], [0, 256])
# 3 绘制直方图
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 8), dpi=100)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文
axes[0].imshow(img, cmap=plt.cm.gray)
axes[0].set_title("原图")
axes[1].plot(histr)
axes[1].set_title("中值滤波后的结果")
plt.show()

- 掩膜的应用
掩膜使用选定的图像、图形或物体,对要处理的图像进行遮挡,来控制图形处理的区域。
在数字图像处理中,我们通常使用二维矩阵数组进行掩膜。掩膜是由0和1组成一个二进制图像,利用该掩膜图像要处理的图像的进行掩膜,其中1值的区域被处理,0值区域被屏蔽,不会处理。
掩膜的主要用途是:
- 提取感兴趣区域:用预先制作的感兴趣区掩膜与待处理图像进行“与”操作,得到感兴趣区图像,感兴趣区内图像值保持不变,而区外图像值都为0.
- 屏蔽作用:用掩膜对图像上某些区域作屏蔽,使其不参加处理或不参加处理参数的计算,或仅对屏蔽区作处理或统计。
- 结构特征提取:用相似性变量或图像匹配方法检测和提取图像中与掩膜相似的结构特征。
- 特殊形状图像制作
掩膜在遥感影像处理中使用较多,当提取道路或者河流,或者房屋时,通过一个掩膜矩阵来对图像进行像素过滤,然后将我们需要的地物或者标志突出显示出来。
使用cv.calcHist()来查找完整图像的直方图。如果要查找图像某些区域的直方图,只需在要查找直方图的区域上创建一个白色的掩膜图像,否则创建黑色,然后将其作为掩膜mask传递即可。
示例:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
# 1 直接以灰度图的方式读入
img = cv.imread("D:\Projects notes\opencv\image\_20201226153617.jpg", 0)
# 2 创建蒙版
mask = np.zeros(img.shape[:2], np.uint8)
mask[400:650, 200:500] = 255
# 3 掩膜
masked_img = cv.bitwise_and(img, img, mask=mask)
# 4 统计掩膜后图像的灰度图
mask_histr = cv.calcHist([img], [0], mask, [256], [1, 256])
# 5 图像展示
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10, 8), dpi=100)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文
axes[0, 0].imshow(img, cmap=plt.cm.gray)
axes[0, 0].set_title("原图")
axes[0, 1].imshow(mask, cmap=plt.cm.gray)
axes[0, 1].set_title("蒙版数据")
axes[1, 0].imshow(masked_img, cmap=plt.cm.gray)
axes[1, 0].set_title("掩膜后数据")
axes[1, 1].plot(mask_histr)
axes[1, 1].grid()
axes[1, 1].set_title("灰度直方图")
plt.show()
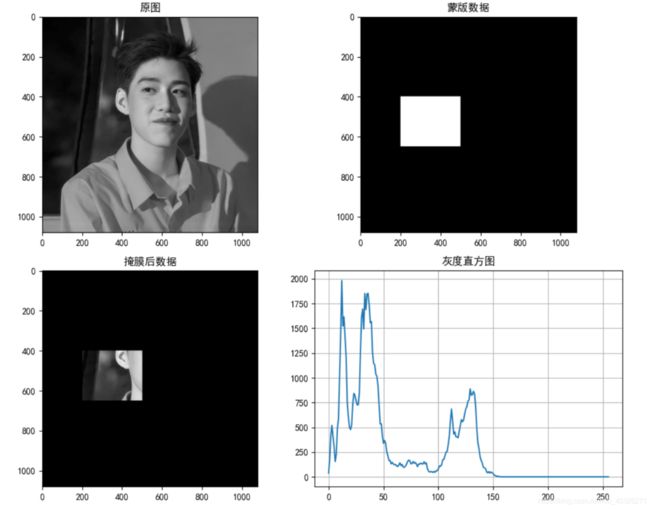
3.2 直方图均衡化
- 原理与应用
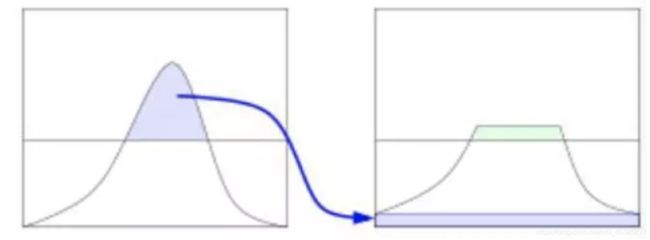
想象一下,如果一幅图像中的大多数像素点的像素值都集中在某一个小的灰度值范围之内会怎样呢?如果一幅图像整体很亮,那所有的像素值的取值个数应该都会很高。所以应该把它的直方图做一个横向拉伸(如下图),就可以扩大图像像素值的分布范围,提高图像的对比度,这就是直方图均衡化要做的事情。

“直方图均衡化”是把原始图像的灰度直方图从比较集中的某个灰度区间变成在更广泛灰度范围内的分布。直方图均衡化就是对图像进行非线性拉伸,重新分配图像像素值,使一定灰度范围内的像素数量大致相同。
这种方法提高图像整体的对比度,特别是有用数据的像素值分布比较接近时,在X光图像中使用广泛,可以提高骨架结构的显示,另外在曝光过度或不足的图像中可以更好的突出细节。
使用opencv进行直方图的统计时,使用的是:
API:
dst = cv.equalizeHist(img)
参数:
- img:灰度图像
返回:
- dst:均衡化后的结果
示例:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
# 1 直接以灰度图的方式读入
img = cv.imread("D:\Projects notes\opencv\image\_20201226153617.jpg", 0)
# 2 均衡化处理
dst = cv.equalizeHist(img)
# 3 结果展示
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 8), dpi=100)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文
axes[0].imshow(img, cmap=plt.cm.gray)
axes[0].set_title("原图")
axes[1].imshow(dst, cmap=plt.cm.gray)
axes[1].set_title("均衡化后结果")
plt.show()

3.3 自适应的直方图均衡化
上述的直方图均衡,我们考虑的是图像的全局对比度。如下图所示,对比下两幅图中雕像的画面,由于太亮丢失了很多信息。

为了解决这个问题,需要使用自适应的直方图均衡化。此时,整幅图像会被分为很多小块,这些小块被称为“tiles”(在opencv中tiles的大小默认是8*8),然后再对每一个小块分别及逆行直方图均衡化。所以再每一个区域中,直方图会集中在某一个小的区域中)。如果由噪声的话,噪声会被放大。为了避免这种情况的出现要使用对比度限制。对于每个小块来说,如果直方图中的bin超过对比度的上限的话,就把其中的像素点均匀分散到其他bins中,然后在进行直方图均衡化。
最后,为了去除每一个小块之间的边界,再使用双线性插值,对每一小块进行拼接。
API:
cv.createCLAHE(clipLimit, tileGridSize)
参数:
- clipLimit:对比度限制,默认是40
- tileGridSize:分块的大小,默认是8*8
示例:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
# 1 直接以灰度图的方式读入
img = cv.imread("D:\Projects notes\opencv\image\_20201226153617.jpg", 0)
# 2 创建一个自适应均衡化的对象,并应用于图像
clahe = cv.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
cl1 = clahe.apply(img)
# 3 图像显示
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 8), dpi=100)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文
axes[0].imshow(img, cmap=plt.cm.gray)
axes[0].set_title("原图")
axes[1].imshow(cl1, cmap=plt.cm.gray)
axes[1].set_title("自适应均衡化后结果")
plt.show()

总结:
- 灰度直方图:
- 直方图是图像中像素强度分布的图像表达式。
- 它统计了每一个强度值所具有的像素个数
- 不同的图像的直方图可能是相同的
cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]])
- 掩膜
创建蒙版,透过mask进行传递,可获取感兴趣区域的直方图
- 直方图均衡化:增强图像对比度的一种方法
cv.equalizeHist():输入是灰度图像,输出是直方图均衡图像
- 自适应直方图均衡
将整幅图像分成很多小块,然后对每一个小块分别进行直方图均衡化,最后进行拼接
clahe = cv.createCLAHE(clipLimit, tileGridsize)