概率论与数理统计(Probability & Statistics II)
Table of Contents
- 样本与抽样分布(Sample and Sampling Distribution)
-
- 数理统计(Statistics)
- 抽样分布(Sampling distribution)
- 参数估计(Parameter Estimation)
-
- 点估计(Point estimation)
- 估计量的评判标准(Criteria for estimators)
- 区间估计(Interval estimation)
- 假设检验(Hypothesis Testing)
-
- 假设检验的基本思想(The basic idea of hypothesis testing)
- 正态总体下的假设检验(Hypothesis testing in a normal population)
- 置信区间和假设检验的关系(The relationship between confidence intervals and hypothesis testing)
- 非参数检验(Nonparametric tests)
- 假设检验问题中的 p-value 检验法(The p-value test method in hypothesis testing problems)
- 方差分析(Analysis of Variance, ANOVA)
-
- 单因素方差分析(One-factor analysis of variance)
- 双因素方差分析(Two-factor analysis of variance)
- 回归分析(Regression Analysis)
-
- 一元线性回归(Simple Linear Regression)
- 多元线性回归(Multiple Linear Regression)
概率论与数理统计(Probability & Statistics I)
概率论与数理统计(Probability & Statistics II)
样本与抽样分布(Sample and Sampling Distribution)
数理统计(Statistics)
数理统计是以概率论为基础, 关于实验数据的收集、整理、分析与推断的一门科学与艺术。
总体(population):研究对象的全体;
个体(individual):总体中的每一个具体对象称为个体;
总体的容量(capacity):总体中包含的个体数;
有限总体(finite population):容量有限的总体;
无限总体(infinite population):容量无限的总体。通常将容量非常大的有限总体也按无限总体处理。
为了采用数理统计方法进行分析,首先要收集数据,数据收集方法一般有两种。
(1)通过调查、记录收集数据。(2)通过实验收集数据。
实际中人们通常只关注总体的某个(或几个)指标。
- 总体的某个指标 X X X, 对于不同的个体来说有不同的取值, 这些取值构成一个分布, 因此 X X X可以看成一个随机变量。
- 有时候直接将 X X X称为总体. 假设 X X X的分布函数为 F ( x ) F(x) F(x), 也称 X X X服从 F ( x ) F(x) F(x)分布 X ∼ F ( x ) X∼ F(x) X∼F(x)
如何推断总体分布的未知参数(或分布)?
需要从总体中抽取一部分个体, 根据这部分个体的数据,并利用概率论的知识等作出分析推断.被抽取的部分个体叫做总体的一个样本(sample)。
简单随机样本(simple random sample):满足以下两个条件的随机样本 ( X 1 , X 2 , … , X n ) (X_1,X_2,…,X_n) (X1,X2,…,Xn) 称为容量是 n n n的简单随机样本,简称样本。
(1) 代表性:每个 X i X_i Xi与 X X X同分布;
(2) 独立性: ( X 1 , X 2 , … , X n ) (X_1,X_2,…,X_n) (X1,X2,…,Xn)是相互独立的随机变量。
获得简单随机样本的抽样称为简单随机抽样。
- 对于有限总体,采用放回抽样.
- 但当总体容量很大的时候,放回抽样有时候很不方便, 因此在实际中当总体容量比较大时,通常将不放回抽样所得到的样本近似当作简单随机样本来处理.
- 对于无限总体, 一般采取不放回抽样.
对样本 X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn 进行观测后,得到的数值: x 1 , x 2 , … , x n x_1,x_2,…,x_n x1,x2,…,xn 称为样本观测值(observed value)
观测前: X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn 是随机变量
观测后: x 1 , x 2 , … , x n x_1,x_2,…,x_n x1,x2,…,xn 是具体的数据
样本的联合分布:设总体 X ∼ F ( x ) X∼ F(x) X∼F(x),则样本 X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn 的联合分布函数为: F ( x 1 , x 2 , … , x n ) = P { X 1 ⩽ x 1 , … , X n ⩽ x n } = ∏ i = 1 n F ( x i ) F(x_1,x_2,…,x_n)=P\{X_1⩽ x_1,…,X_n⩽ x_n\}=\displaystyle\prod_{i=1}^{n}F(x_i) F(x1,x2,…,xn)=P{ X1⩽x1,…,Xn⩽xn}=i=1∏nF(xi)
若总体 X X X 的密度函数为 f ( x ) f(x) f(x),则样本 X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn 的联合密度函数为: f ( x 1 , x 2 , … , x n ) = ∏ i = 1 n f ( x i ) f(x_1,x_2,…,x_n)=\displaystyle\prod_{i=1}^{n}f(x_i) f(x1,x2,…,xn)=i=1∏nf(xi)
若总体 X X X 的分布律为 P { X = a k } = p k P\{X=a_k\}=p_k P{ X=ak}=pk,则样本 X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn 的联合分布律为: P { X 1 = x 1 , … , X n = x n } = ∏ i = 1 n P { X = x i } P\{X_1=x_1,…,X_n=x_n\}=\displaystyle\prod_{i=1}^{n}P\{X=x_i\} P{ X1=x1,…,Xn=xn}=i=1∏nP{ X=xi}
抽样分布(Sampling distribution)
从样本中提取有用的信息来研究总体的分布及各种特征数——构造统计量.
统计量(statistic):设 X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn 是来自总体 X ∼ F ( x ) X∼ F(x) X∼F(x) 的样本, g ( x 1 , x 2 , … , x n ) g(x_1,x_2,…,x_n) g(x1,x2,…,xn) 是 n n n元实值连续函数,若函数 g ( x 1 , x 2 , … , x n ) g(x_1,x_2,…,x_n) g(x1,x2,…,xn) 不含未知参数, 则称随机变量 g ( X 1 , X 2 , … , X n ) g(X_1,X_2,…,X_n) g(X1,X2,…,Xn) 为统计量。
常用统计量
(1) 样本均值: X ˉ = 1 n ∑ i = 1 n X i \bar X=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i Xˉ=n1i=1∑nXi
(2) 样本方差: S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ˉ ) 2 S^2=\dfrac{1}{n-1}\displaystyle\sum_{i=1}^{n}(X_i-\bar X)^2 S2=n−11i=1∑n(Xi−Xˉ)2
样本标准差: S = S 2 S=\sqrt{S^2} S=S2
(3) 样本 k 阶原点矩: A k = 1 n ∑ i = 1 n X i k A_k=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i^k Ak=n1i=1∑nXik
样本 k 阶中心矩: B k = 1 n ∑ i = 1 n ( X i − X ˉ ) k B_k=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}(X_i-\bar X)^k Bk=n1i=1∑n(Xi−Xˉ)k
(4) 将样本按由小到大的顺序排成 X ( 1 ) ⩽ X ( 2 ) ⩽ … ⩽ X ( n ) X_{(1)}⩽ X_{(2)}⩽ …⩽ X_{(n)} X(1)⩽X(2)⩽…⩽X(n)
顺序统计量(order statistic): X ( 1 ) , X ( 2 ) , … , X ( n ) X_{(1)}, X_{(2)}, …, X_{(n)} X(1),X(2),…,X(n)
样本极小值(minimum): X ( 1 ) = min { X ( 1 ) , X ( 2 ) , … , X ( n ) } X_{(1)}=\min \{X_{(1)}, X_{(2)}, …, X_{(n)}\} X(1)=min{ X(1),X(2),…,X(n)}
样本极大值(maximum): X ( n ) = max { X ( 1 ) , X ( 2 ) , … , X ( n ) } X_{(n)}=\max \{X_{(1)}, X_{(2)}, …, X_{(n)}\} X(n)=max{ X(1),X(2),…,X(n)}
样本极差(range): R n = X ( n ) − X ( 1 ) R_n=X_{(n)}-X_{(1)} Rn=X(n)−X(1)
样本均值与样本方差的数字特征:设 X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn 是来总体 X X X 的样本,且总体的均值与方差存在,记为 E ( X ) = μ , D ( X ) = σ 2 E(X)=μ,D(X)=σ^2 E(X)=μ,D(X)=σ2,则有
(1) E ( X ˉ ) = E ( 1 n ∑ i = 1 n X i ) = 1 n ∑ i = 1 n E ( X i ) = μ E(\bar X)=E(\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i)=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}E(X_i)=μ E(Xˉ)=E(n1i=1∑nXi)=n1i=1∑nE(Xi)=μ
D ( X ˉ ) = D ( 1 n ∑ i = 1 n X i ) = 1 n 2 ∑ i = 1 n D ( X i ) = σ 2 / n D(\bar X)=D(\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i)=\dfrac{1}{n^2}\displaystyle\sum_{i=1}^{n}D(X_i)=σ^2/n D(Xˉ)=D(n1i=1∑nXi)=n21i=1∑nD(Xi)=σ2/n
(2) E ( S 2 ) = σ 2 E(S^2)=σ^2 E(S2)=σ2
(3) 若 X ∼ N ( μ , σ 2 ) X∼ N(μ,σ^2) X∼N(μ,σ2),则 D ( S 2 ) = 2 σ 4 n − 1 D(S^2)=\dfrac{2σ^4}{n-1} D(S2)=n−12σ4
抽样分布(sampling distribution):统计量的分布被称为抽样分布
当总体 X X X服从一般分布(如指数分布、均匀分布等),要得出统计量的分布是很困难的。当总体 X X X服从正态分布时,统计量 X ˉ , S 2 \bar X,S^2 Xˉ,S2是可以计算的,本节主要介绍与标准正态总体相关的抽样分布。
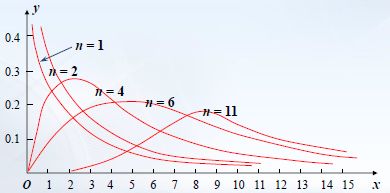
χ 2 χ^2 χ2 分布(chi-square distribution):设 X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn 相互独立,且都服从标准正态分布 N ( 0 , 1 ) N(0, 1) N(0,1) ,则称随机变量 χ 2 = ∑ i = 1 n X i 2 χ^2=\displaystyle\sum_{i=1}^{n}X_i^2 χ2=i=1∑nXi2 服从自由度为 n n n 的 χ 2 χ^2 χ2 分布,记为 χ 2 ∼ χ 2 ( n ) χ^2∼ χ^2(n) χ2∼χ2(n),自由度指包含的独立变量的个数。
χ 2 χ^2 χ2 分布的概率密度为: f n ( x ) = { 1 2 Γ ( n / 2 ) ( x 2 ) n / 2 − 1 e − x / 2 , x > 0 0 , x ⩽ 0 f_n(x)=\begin{cases} \dfrac{1}{2Γ(n/2)}(\dfrac{x}{2})^{n/2-1}e^{-x/2},\quad x>0 \\ 0,\quad x⩽0 \end{cases} fn(x)=⎩⎨⎧2Γ(n/2)1(2x)n/2−1e−x/2,x>00,x⩽0 其中 Γ ( x ) = ∫ 0 + ∞ t x − 1 e − t d t Γ(x)=\displaystyle\int_{0}^{+∞}t^{x-1}e^{-t}\mathrm{d}t Γ(x)=∫0+∞tx−1e−tdt
性质:
(1) 设 Y ∼ χ 2 ( n ) Y∼ χ^2(n) Y∼χ2(n),则 E ( Y ) = n , D ( Y ) = 2 n E(Y)=n,D(Y)=2n E(Y)=n,D(Y)=2n
(2) 分布的可加性:设 Y 1 ∼ χ 2 ( n 1 ) , Y 2 ∼ χ 2 ( n 2 ) Y_1∼ χ^2(n_1),Y_2∼ χ^2(n_2) Y1∼χ2(n1),Y2∼χ2(n2),且 Y 1 , Y 2 Y_1,Y_2 Y1,Y2相互独立,则 Y 1 + Y 2 ∼ χ 2 ( n 1 + n 2 ) Y_1+Y_2∼ χ^2(n_1+n_2) Y1+Y2∼χ2(n1+n2)
推广:设 Y 1 , Y 2 , ⋯ , Y m Y_1,Y_2,\cdots,Y_m Y1,Y2,⋯,Ym相互独立,且 Y i ∼ χ 2 ( n i ) Y_i∼ χ^2(n_i) Yi∼χ2(ni),则 ∑ i = 1 m Y i ∼ χ 2 ( ∑ i = 1 m n i ) \displaystyle\sum_{i=1}^{m}Y_i∼ χ^2(\sum_{i=1}^{m}n_i) i=1∑mYi∼χ2(i=1∑mni)
t 分布(t-distribution):设 X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n ) X∼ N(0,1),Y∼ χ^2(n) X∼N(0,1),Y∼χ2(n),且 X与 Y 相互独立,则称随机变量 T = X Y / n T=\dfrac{X}{\sqrt{Y/n}} T=Y/nX服从自由度为 n 的 t 分布,记为 T ∼ t ( n ) T∼ t(n) T∼t(n)
t ( n ) t(n) t(n)分布的概率密度为: f n ( x ) = Γ ( n + 1 2 ) n π Γ ( n 2 ) ( 1 + x 2 n ) − n + 1 2 , x ∈ R f_n(x)=\dfrac{Γ(\frac{n+1}{2})}{\sqrt{nπ}Γ(\frac{n}{2})}(1+\dfrac{x^2}{n})^{-\frac{n+1}{2}},\quad x\in\R fn(x)=nπΓ(2n)Γ(2n+1)(1+nx2)−2n+1,x∈R
特别地, n = 1 n=1 n=1 的 t 分布就是柯西分布 f ( x ) = 1 π ( 1 + x 2 ) , x ∈ R f(x)=\dfrac{1}{π(1+x^2)},x\in\R f(x)=π(1+x2)1,x∈R
lim n → ∞ f n ( x ) = 1 2 π e − x 2 / 2 , x ∈ R \lim\limits_{n\to∞}f_n(x)=\dfrac{1}{\sqrt{2π}}e^{-x^2/2},x\in\R n→∞limfn(x)=2π1e−x2/2,x∈R

F 分布(F-distribution):设 X ∼ χ 2 ( n 1 ) , Y ∼ χ 2 ( n 2 ) X∼ χ^2(n_1),Y∼ χ^2(n_2) X∼χ2(n1),Y∼χ2(n2),且 X与 Y 相互独立,则称随机变量 F = X / n 1 Y / n 2 F=\dfrac{X/n_1}{Y/n_2} F=Y/n2X/n1服从自由度为 ( n 1 , n 2 ) (n_1,n_2) (n1,n2) 的 F 分布,记为 F ∼ F ( n 1 , n 2 ) F∼ F(n_1,n_2) F∼F(n1,n2),其中 n 1 n_1 n1称为第一自由度, n 2 n_2 n2称为第二自由度。
F ( n 1 , n 2 ) F(n_1,n_2) F(n1,n2)分布的概率密度为: f ( x ) = { ( n 1 / n 2 ) n 1 2 B ( n 1 2 , n 2 2 ) x n 1 2 − 1 ( 1 + n 1 n 2 x ) − n 1 + n 2 2 , x > 0 0 , x ⩽ 0 f(x)=\begin{cases} \dfrac{(n_1/n_2)^{\frac{n_1}{2}}}{B(\frac{n_1}{2},\frac{n_2}{2})}x^{\frac{n_1}{2}-1}(1+\frac{n_1}{n_2}x)^{-\frac{n_1+n_2}{2}},x>0 \\ 0,\quad x⩽ 0 \end{cases} f(x)=⎩⎪⎨⎪⎧B(2n1,2n2)(n1/n2)2n1x2n1−1(1+n2n1x)−2n1+n2,x>00,x⩽0其中 B ( a , b ) = ∫ 0 1 x a − 1 ( 1 − x ) b − 1 d x = Γ ( a ) Γ ( b ) Γ ( a + b ) B(a,b)=\displaystyle\int_0^1x^{a-1}(1-x)^{b-1}\mathrm{d}x=\dfrac{Γ(a)Γ(b)}{Γ(a+b)} B(a,b)=∫01xa−1(1−x)b−1dx=Γ(a+b)Γ(a)Γ(b)
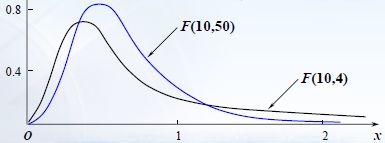
重要性质:若 F ∼ F ( n 1 , n 2 ) F∼ F(n_1,n_2) F∼F(n1,n2),则 1 F ∼ F ( n 2 , n 1 ) \dfrac{1}{F}∼ F(n_2,n_1) F1∼F(n2,n1)
正态总体的抽样分布
设 X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn 是来自正态总体 N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2)的样本,样本均值 X ˉ = 1 n ∑ i = 1 n X i \bar X=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i Xˉ=n1i=1∑nXi,样本方差 S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ˉ ) 2 S^2=\dfrac{1}{n-1}\displaystyle\sum_{i=1}^{n}(X_i-\bar X)^2 S2=n−11i=1∑n(Xi−Xˉ)2,则
(1) X ˉ ∼ N ( μ , σ 2 / n ) \bar X∼ N(μ,σ^2/n) Xˉ∼N(μ,σ2/n)
(2) ( n − 1 ) S 2 σ 2 ∼ χ 2 ( n − 1 ) \dfrac{(n-1)S^2}{σ^2}∼χ^2(n-1) σ2(n−1)S2∼χ2(n−1)
(3) X ˉ \bar X Xˉ与 S 2 S^2 S2相互独立
(4) X ˉ − μ S / n ∼ t ( n − 1 ) \dfrac{\bar X-μ}{S/\sqrt{n}}∼ t(n-1) S/nXˉ−μ∼t(n−1)
设 X 1 , X 2 , … , X n 1 X_1,X_2,…,X_{n_1} X1,X2,…,Xn1和 Y 1 , Y 2 , … , Y n 2 Y_1,Y_2,…,Y_{n_2} Y1,Y2,…,Yn2 分别来自正态总体 N ( μ 1 , σ 1 2 ) N(μ_1,σ_1^2) N(μ1,σ12)和 N ( μ 2 , σ 2 2 ) N(μ_2,σ_2^2) N(μ2,σ22)的样本,均值分别为 X ˉ , Y ˉ \bar X,\bar Y Xˉ,Yˉ,方差分别为 S 1 2 , S 2 2 S_1^2,S_2^2 S12,S22,则
(1) S 1 2 / S 2 2 σ 1 2 / σ 2 2 ∼ F ( n 1 − 1 , n 2 − 1 ) \dfrac{S_1^2/S_2^2}{σ_1^2/σ_2^2}∼ F(n_1-1,n_2-1) σ12/σ22S12/S22∼F(n1−1,n2−1)
(2) ( X ˉ − Y ˉ ) − ( μ 1 − μ 2 ) σ 1 2 n 1 + σ 2 2 n 2 ∼ N ( 0 , 1 ) \dfrac{(\bar X-\bar Y)-(μ_1-μ_2)}{\sqrt{\dfrac{σ_1^2}{n_1}+\dfrac{σ_2^2}{n_2}}}∼ N(0,1) n1σ12+n2σ22(Xˉ−Yˉ)−(μ1−μ2)∼N(0,1)
(3) 当 σ 1 2 = σ 2 2 = σ 2 σ_1^2=σ_2^2=σ^2 σ12=σ22=σ2时
( X ˉ − Y ˉ ) − ( μ 1 − μ 2 ) S w 1 n 1 + 1 n 2 ∼ t ( n 1 + n 2 − 2 ) \dfrac{(\bar X-\bar Y)-(μ_1-μ_2)}{S_w\sqrt{\dfrac{1}{n_1}+\dfrac{1}{n_2}}}∼ t(n_1+n_2-2) Swn11+n21(Xˉ−Yˉ)−(μ1−μ2)∼t(n1+n2−2)
其中 S w 2 = ( n 1 − 1 ) S 1 2 + ( n 2 − 1 ) S 2 2 n 1 + n 2 − 2 , S w = S w 2 S_w^2=\dfrac{(n_1-1)S_1^2+(n_2-1)S_2^2}{n_1+n_2-2},S_w=\sqrt{S_w^2} Sw2=n1+n2−2(n1−1)S12+(n2−1)S22,Sw=Sw2
参数估计(Parameter Estimation)
参数通常是刻画总体某些概率特征的数量。例如正态分布 N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2) 中的参数 μ μ μ 就是该分布的均值,参数 σ2 是该分布的方差。当该参数未知时,从总体中抽取一个样本,用某种方法对该未知参数进行估计,这就是参数估计。
参数估计的形式:先从该总体中抽样得到样本,然后构造样本函数,求出未知参数的估计值或取值范围,这就是点估计和区间估计。
假设总体 X ∼ F ( x ; θ 1 , θ 2 , … , θ m ) X ∼ F(x; θ_1, θ_2,…, θ_m) X∼F(x;θ1,θ2,…,θm),其中分布函数 F F F 的表达式已知,但参数 θ 1 , θ 2 , … , θ m θ_1, θ_2,…, θ_m θ1,θ2,…,θm 未知,若记 θ = ( θ 1 , θ 2 , … , θ m ) θ = (θ_1, θ_2,…, θ_m) θ=(θ1,θ2,…,θm),则总体分布可记为 X ∼ F ( x ; θ ) X∼ F(x; θ) X∼F(x;θ),参数 θ θ θ 的取值范围称为参数空间(parameter space),记为 Θ Θ Θ
点估计(Point estimation)
X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn 是来自总体 X ∼ F ( x ; θ 1 , θ 2 , … , θ m ) X ∼ F(x; θ_1, θ_2,…, θ_m) X∼F(x;θ1,θ2,…,θm)的一个样本, θ 1 , θ 2 , … , θ m θ_1, θ_2,…, θ_m θ1,θ2,…,θm 是未知参数,构造 m 个统计量:
随 机 变 量 { θ ^ 1 ( X 1 , X 2 , … , X n ) θ ^ 2 ( X 1 , X 2 , … , X n ) ⋮ θ ^ m ( X 1 , X 2 , … , X n ) 随机变量\begin{cases} \hat θ_1(X_1,X_2,…,X_n) \\ \hat θ_2(X_1,X_2,…,X_n) \\ \quad\vdots\\ \hat θ_m(X_1,X_2,…,X_n) \end{cases} 随机变量⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧θ^1(X1,X2,…,Xn)θ^2(X1,X2,…,Xn)⋮θ^m(X1,X2,…,Xn)
把样本观测值 x 1 , x 2 , … , x n x_1,x_2,…,x_n x1,x2,…,xn 代入上统计量,就得到 m 个数值:
数 值 { θ ^ 1 ( x 1 , x 2 , … , x n ) θ ^ 2 ( x 1 , x 2 , … , x n ) ⋮ θ ^ m ( x 1 , x 2 , … , x n ) 数值\begin{cases} \hat θ_1(x_1,x_2,…,x_n) \\ \hat θ_2(x_1,x_2,…,x_n) \\ \quad\vdots\\ \hat θ_m(x_1,x_2,…,x_n) \end{cases} 数值⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧θ^1(x1,x2,…,xn)θ^2(x1,x2,…,xn)⋮θ^m(x1,x2,…,xn)
称 θ ^ k ( X 1 , X 2 , … , X n ) \hat θ_k(X_1,X_2,…,X_n) θ^k(X1,X2,…,Xn)为 θ k θ_k θk的估计量(estimate), θ ^ 1 ( x 1 , x 2 , … , x n ) \hat θ_1(x_1,x_2,…,x_n) θ^1(x1,x2,…,xn)为 θ k θ_k θk的估计值(estimator)。
常用的估计方法:矩估计法,极大似然估计法,最小二乘估计法,贝叶斯方法
矩估计法(Moment Estimation)
矩估计思想:以样本矩估计总体矩,以样本矩的函数估计总体矩的函数。
由辛钦大数定律,有 A k = 1 n ∑ i = 1 n X i k → P μ k ( θ 1 , θ 2 , … , θ m ) ( n → ∞ ) A_k=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i^k\xrightarrow{P}μ_k(θ_1, θ_2,…, θ_m)\quad (n\to∞) Ak=n1i=1∑nXikPμk(θ1,θ2,…,θm)(n→∞)
因此当n较大时有 A k ≈ μ k ( θ 1 , θ 2 , … , θ m ) A_k\approx μ_k(θ_1, θ_2,…, θ_m) Ak≈μk(θ1,θ2,…,θm)假设总体的前m阶矩存在,令 A k = μ k ( θ 1 , θ 2 , … , θ m ) , k = 1 , 2 , ⋯ , m A_k=μ_k(θ_1, θ_2,…, θ_m),k=1,2,\cdots,m Ak=μk(θ1,θ2,…,θm),k=1,2,⋯,m得方程组,其解 θ ^ k ( X 1 , X 2 , … , X n ) \hat θ_k(X_1,X_2,…,X_n) θ^k(X1,X2,…,Xn) 称为 θ k θ_k θk的矩估计量。
总体均值和方差的矩估计量表达式不因不同的总体分布而异,设总体 X X X的均值 μ μ μ及方差 σ 2 σ^2 σ2都存在
μ ^ = X ˉ , σ ^ 2 = 1 n ∑ i = 1 n ( X i − X ˉ ) 2 ≜ S ~ 2 \hat μ=\bar X,\hatσ^2=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}(X_i-\bar X)^2 \triangleq \tilde S^2 μ^=Xˉ,σ^2=n1i=1∑n(Xi−Xˉ)2≜S~2
设总体 X ∼ U ( a , b ) ⟹ a ^ = X ˉ − 3 S ~ , b ^ = X ˉ + 3 S ~ X∼ U(a,b)\implies\hat a=\bar X-\sqrt{3}\tilde S,\hat b=\bar X+\sqrt{3}\tilde S X∼U(a,b)⟹a^=Xˉ−3S~,b^=Xˉ+3S~
极大似然估计法(Maximum Likelihood Estimate,MLE)
Fisher的极大似然思想:
假设总体 X X X 是离散型随机变量,其分布律为 P { X = x } = p ( x ; θ ) , θ ∈ Θ P\{X=x\}=p(x;θ),θ\in Θ P{ X=x}=p(x;θ),θ∈Θ,θ未知, X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn为样本,其观察值为 x 1 , x 2 , … , x n x_1,x_2,…,x_n x1,x2,…,xn,则事件 { X 1 = x 1 , X 2 = x 2 , ⋯ , X n = x n } \{X_1=x_1,X_2=x_2,\cdots,X_n=x_n\} { X1=x1,X2=x2,⋯,Xn=xn}发生的概率(联合分布律)为 L ( θ ) = L ( x 1 , x 2 , … , x n ; θ ) = ∏ i = 1 n p ( x i ; θ ) , θ ∈ Θ L(θ)=L(x_1,x_2,…,x_n;θ)=\displaystyle\prod_{i=1}^{n} p(x_i;θ),θ\in Θ L(θ)=L(x1,x2,…,xn;θ)=i=1∏np(xi;θ),θ∈Θ这一概率随θ的取值而改变,我们自然的认为使概率取得最大值的θ值较为合理, L ( θ ) L(θ) L(θ)称为样本的似然函数(likelihood function),方程 L ( θ ^ ) = max θ ∈ Θ L ( θ ) , θ ^ = θ ^ ( x 1 , x 2 , … , x n ) L(\hat θ)=\displaystyle\max_{θ\in Θ} L(θ),\hat θ=\hat θ(x_1,x_2,…,x_n) L(θ^)=θ∈ΘmaxL(θ),θ^=θ^(x1,x2,…,xn)的解 θ ^ \hat θ θ^称为极大似然估计值,统计量 θ ^ = θ ^ ( X 1 , X 2 , … , X n ) \hat θ=\hat θ(X_1,X_2,…,X_n) θ^=θ^(X1,X2,…,Xn)为θ 的极大似然估计量(MLE)
连续型随机变量 X X X的概率密度函数为 f ( x ; θ ) , θ ∈ Θ f(x;θ),θ\in Θ f(x;θ),θ∈Θ,可取得似然函数为 L ( θ ) = L ( x 1 , x 2 , … , x n ; θ ) = ∏ i = 1 n f ( x i ; θ ) , θ ∈ Θ L(θ)=L(x_1,x_2,…,x_n;θ)=\displaystyle\prod_{i=1}^{n} f(x_i;θ),θ\in Θ L(θ)=L(x1,x2,…,xn;θ)=i=1∏nf(xi;θ),θ∈Θ
在许多情况下, p ( x ; θ ) , f ( x ; θ ) p(x;θ),f(x;θ) p(x;θ),f(x;θ)关于θ可微,这时 θ ^ \hat θ θ^常可从方程 d d θ L ( θ ) = 0 \dfrac{\mathrm{d}}{\mathrm{d}θ}L(θ)=0 dθdL(θ)=0解得,又因 L ( θ ) L(θ) L(θ)和 ln L ( θ ) \ln L(θ) lnL(θ)在同一处取得极值,因此 θ ^ \hat θ θ^也可从方程 d d θ ln L ( θ ) = 0 \dfrac{\mathrm{d}}{\mathrm{d}θ}\ln L(θ)=0 dθdlnL(θ)=0求得,这一方程被称作对数似然方程。
极大似然估计法同样适用于分布中含多个参数 θ 1 , θ 2 , … , θ m θ_1, θ_2,…, θ_m θ1,θ2,…,θm的情况,这时似然函数L是这些未知参数的函数,分别令 ∂ ∂ θ i L = 0 , i = 1 , 2 , ⋯ , m \dfrac{∂}{∂θ_i}L=0,i=1,2,\cdots,m ∂θi∂L=0,i=1,2,⋯,m或 ∂ ∂ θ i ln L = 0 , i = 1 , 2 , ⋯ , m \dfrac{∂}{∂θ_i}\ln L=0,i=1,2,\cdots,m ∂θi∂lnL=0,i=1,2,⋯,m解上述由m个方程组成的方程组即可,上式称为对数似然方程组。
设总体 X ∼ N ( μ , σ 2 ) ⟹ μ ^ = X ˉ , σ ^ 2 = 1 n ∑ i = 1 n ( X i − X ˉ ) 2 ≜ S ~ 2 X∼ N(μ,σ^2)\implies\hat μ=\bar X,\hatσ^2=\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}(X_i-\bar X)^2 \triangleq \tilde S^2 X∼N(μ,σ2)⟹μ^=Xˉ,σ^2=n1i=1∑n(Xi−Xˉ)2≜S~2
设总体 X ∼ U ( a , b ) ⟹ a ^ = min { X 1 , X 2 , ⋯ , X n } = X ( 1 ) , b ^ = max { X 1 , X 2 , ⋯ , X n } = X ( n ) X∼ U(a,b)\implies\hat a=\min\{X_1,X_2,\cdots,X_n\}=X_{(1)},\hat b=\max\{X_1,X_2,\cdots,X_n\}=X_{(n)} X∼U(a,b)⟹a^=min{ X1,X2,⋯,Xn}=X(1),b^=max{ X1,X2,⋯,Xn}=X(n)
极大似然估计的不变性:设 θ ^ \hat θ θ^是 θ θ θ的极大似然估计,θ 的函数 u = u ( θ ) u=u(θ) u=u(θ)且有单值反函数 θ = θ ( u ) θ=θ(u) θ=θ(u),则 u ( θ ^ ) u(\hat θ) u(θ^)是 u u u 的极大似然估计。
估计量的评判标准(Criteria for estimators)
对同一个参数,不同方法得到的估计量可能不同。用什么标准来评价一个估计量的好坏?
(1) 无偏性(unbiased):设 X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn为总体 X ∼ F ( x ; θ ) ( θ ∈ Θ ) X∼ F(x;θ) \quad (θ\inΘ) X∼F(x;θ)(θ∈Θ) 的样本,若参数 θ θ θ 的估计量 θ ^ = θ ^ ( X 1 , X 2 , … , X n ) \hat θ=\hat θ(X_1,X_2,…,X_n) θ^=θ^(X1,X2,…,Xn)满足 E ( θ ^ ) = θ E(\hat θ)=θ E(θ^)=θ,则 θ ^ \hat θ θ^是 θ θ θ的一个无偏估计量。
若 E ( θ ^ ) ≠ θ E(\hat θ)\neq θ E(θ^)=θ,则 ∣ E ( θ ^ ) − θ ∣ |E(\hat θ)-θ| ∣E(θ^)−θ∣称为估计量 θ θ θ 的偏差。
若 lim n → ∞ E ( θ ^ ) = θ \lim\limits_{n\to∞}E(\hat θ)= θ n→∞limE(θ^)=θ,则称 θ ^ \hat θ θ^是 θ θ θ的渐近无偏估计量
估计量 θ ^ ( X 1 , X 2 , … , X n ) \hat θ(X_1,X_2,…,X_n) θ^(X1,X2,…,Xn)是随机变量,而估计值会有波动性,无偏性的统计意义是指在大量重复试验下,保证了没有系统误差。
设 X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn是总体 X X X 的样本,总体的k阶矩为 μ k μ_k μk,期望和方差为 μ , σ 2 μ,σ^2 μ,σ2
E ( A k ) = μ k E(A_k)=μ_k E(Ak)=μk,样本 k阶矩都是总体k阶矩的无偏估计
特别的, E ( X ˉ ) = μ , E ( S 2 ) = σ 2 E(\bar X)=μ,E(S^2)=σ^2 E(Xˉ)=μ,E(S2)=σ2
而 E ( S ~ 2 ) = n − 1 n E ( S 2 ) = n − 1 n σ 2 E(\tilde S^2)=\dfrac{n-1}{n}E(S^2)=\dfrac{n-1}{n}σ^2 E(S~2)=nn−1E(S2)=nn−1σ2不是总体方差的无偏估计
lim n → ∞ E ( S ~ 2 ) = σ 2 \lim\limits_{n\to∞}E(\tilde S^2)=σ^2 n→∞limE(S~2)=σ2, S ~ 2 \tilde S^2 S~2是方差的渐进无偏估计。
纠偏方法:若 θ ^ \hat θ θ^是有偏估计, E ( θ ^ ) = a θ + b ( a ≠ 0 , θ ∈ Θ ) E(\hat θ)=aθ+b\quad (a\neq 0,θ\inΘ) E(θ^)=aθ+b(a=0,θ∈Θ),则 θ − b a \dfrac{θ-b}{a} aθ−b是θ 的无偏估计,上面就是用了此方法。
(2) 有效性(effective):设 θ ^ 1 , θ ^ 2 \hat θ_1,\hat θ_2 θ^1,θ^2 都是 θ 的无偏估计量,若有 ∀ θ ∈ Θ , D ( θ ^ 1 ) ⩽ D ( θ ^ 2 ) ∀ θ\inΘ,D(\hat θ_1) ⩽ D(\hat θ_2) ∀θ∈Θ,D(θ^1)⩽D(θ^2),且不等号至少对某一 θ ∈ Θ θ\inΘ θ∈Θ 成立,则 θ ^ 1 \hat θ_1 θ^1比 θ ^ 1 \hat θ_1 θ^1 有效。
均方误差准则:定义 E ( θ ^ − θ ) 2 E(\hat θ-θ)^2 E(θ^−θ)2是估计量 θ ^ \hat θ θ^的均方误差(mean square error;MSE),记作 M s e ( θ ^ ) Mse(\hat θ) Mse(θ^),若 θ ^ \hat θ θ^是θ 的无偏估计量,则 M s e ( θ ^ ) = D ( θ ^ ) Mse(\hat θ)=D(\hat θ) Mse(θ^)=D(θ^)。
设设 θ ^ 1 , θ ^ 2 \hat θ_1,\hat θ_2 θ^1,θ^2 都是 θ的点估计,若有 ∀ θ ∈ Θ , M s e ( θ ^ 1 ) ⩽ M s e ( θ ^ 2 ) ∀ θ\inΘ,Mse(\hat θ_1) ⩽ Mse(\hat θ_2) ∀θ∈Θ,Mse(θ^1)⩽Mse(θ^2),且不等号至少对某一 θ ∈ Θ θ\inΘ θ∈Θ 成立,则在均方误差条件下 θ ^ 1 \hat θ_1 θ^1优于 θ ^ 1 \hat θ_1 θ^1 。
在实际应用中,均方误差准则比无偏性准则更重要
(3) 相合性(consistence):设 θ ^ ( X 1 , X 2 , … , X n ) \hat θ(X_1,X_2,…,X_n) θ^(X1,X2,…,Xn)是参数θ的估计量
若 ∀ θ ∈ Θ , ∀ ϵ > 0 , lim n → ∞ P { ∣ θ ^ − θ ∣ < ϵ } = 1 ∀ θ\inΘ,∀ϵ>0,\lim\limits_{n\to∞}P\{|\hat θ-θ|<ϵ\}=1 ∀θ∈Θ,∀ϵ>0,n→∞limP{ ∣θ^−θ∣<ϵ}=1
即 θ ^ n → P θ ( n → ∞ ) \hat θ_n\xrightarrow{P}θ\quad (n\to∞) θ^nPθ(n→∞),称 θ ^ \hat θ θ^为θ的相合估计量。
相合性的相关结论:
(1) 样本 k 阶矩 A k A_k Ak是总体 k 阶矩 μ k μ_k μk 的相合估计量;-----辛钦大数定律证明
(2) S 2 , S ~ 2 S^2,\tilde S^2 S2,S~2是总体方差的相合估计量。-----切比雪夫不等式证明
(3) 矩估计量一般是相合估计量。
应用
(1) 设 X ∼ N ( μ , σ 2 ) ⟹ M s e ( S 2 ) = D ( S 2 ) = 2 σ 4 n − 1 , M s e ( S ~ 2 ) = 2 n − 1 n 2 σ 4 X∼ N(μ,σ^2)\implies Mse(S^2)=D(S^2)=\dfrac{2σ^4}{n-1},Mse(\tilde S^2)=\dfrac{2n-1}{n^2}σ^4 X∼N(μ,σ2)⟹Mse(S2)=D(S2)=n−12σ4,Mse(S~2)=n22n−1σ4
当 n > 1 n>1 n>1时, M s e ( S 2 ) > M s e ( S ~ 2 ) Mse(S^2)>Mse(\tilde S^2) Mse(S2)>Mse(S~2)因此在均方误差条件下 S ~ 2 \tilde S^2 S~2优于 S 2 S^2 S2
(2) 设 X 1 , X 2 , … , X n X_1,X_2,…,X_n X1,X2,…,Xn是总体指数分布 X ∼ E x p ( θ ) X∼ Exp(θ) X∼Exp(θ)的样本
θ 的矩估计量 X ˉ \bar X Xˉ和极大似然估计量 n Z , Z = min { X 1 , X 2 , … , X n } nZ,Z=\min\{X_1,X_2,…,X_n\} nZ,Z=min{ X1,X2,…,Xn}均是无偏估计;
但 D ( X ˉ ) = θ 2 / n , D ( n Z ) = θ 2 D(\bar X)=θ^2/n,D(nZ)=θ^2 D(Xˉ)=θ2/n,D(nZ)=θ2,当 n > 1 n>1 n>1时, D ( X ˉ ) < D ( n Z ) D(\bar X)
区间估计(Interval estimation)
对于一个未知量,根据具体样本观测值,点估计提供一个明确的数值。还希望根据所给的样本确定一个随机区间, 使其包含参数真值的概率达到指定的要求。
置信区间(Confidence Intervals):设总体 X ∼ F ( x ; θ ) , θ ∈ Θ X∼ F(x;θ),θ\inΘ X∼F(x;θ),θ∈Θ,若对
给定的 α ( 0 < α < 1 ) α(0<α<1) α(0<α<1),由来自 X X X的样本确定的两个统计量 θ ^ L = θ ^ L ( X 1 , X 2 , … , X n ) , θ ^ U = θ ^ U ( X 1 , X 2 , … , X n ) ( θ ^ L < θ ^ U ) \hat θ_L=\hat θ_L(X_1,X_2,…,X_n),\hat θ_U=\hat θ_U(X_1,X_2,…,X_n)(\hatθ_L<\hatθ_U) θ^L=θ^L(X1,X2,…,Xn),θ^U=θ^U(X1,X2,…,Xn)(θ^L<θ^U),对于 ∀ θ ∈ Θ ∀ θ\inΘ ∀θ∈Θ,满足 P { θ ^ L < θ < θ ^ U } ⩾ 1 − α P\{\hatθ_L<θ<\hatθ_U\}⩾ 1-α P{ θ^L<θ<θ^U}⩾1−α则称随机区间 ( θ ^ L , θ ^ U ) (\hatθ_L,\hatθ_U) (θ^L,θ^U)为θ的置信度为 1 − α 1-α 1−α 的置信区间(confidence interval)。 θ ^ L , θ ^ U \hatθ_L,\hatθ_U θ^L,θ^U分别称为置信下限和置信上限, 1 − α 1-α 1−α称为置信度或置信水平(confidence level)。
说明:
(1) 参数θ虽然未知,但是确定的值。置信区间 ( θ ^ L , θ ^ U ) (\hatθ_L,\hatθ_U) (θ^L,θ^U)是随机的,依赖于样本,样本不同,算出的区间也不同。对于有些样本观察值,区间覆盖θ,但对于另一些样本观察值,区间则不能覆盖。反复抽样多次(各次样本容量相同),按伯努利大数定律,在这些区间中,包含真值的比例约为 1 − α 1-α 1−α
(2) 相同的置信水平也可以得到不同的区间估计。称置信区间 ( θ ^ L , θ ^ U ) (\hatθ_L,\hatθ_U) (θ^L,θ^U)的平均长度 E ( θ ^ U − θ ^ L ) E(\hatθ_U-\hatθ_L) E(θ^U−θ^L)为区间的精确度(accuracy)(长度最短,精度最高),精确度的一半为误差限(error limit)。在给定的样本容量下,置信水平和精确度是相互制约的。
(3) Neyman原则:在置信水平达到 1 − α 1-α 1−α的置信区间中,选精确度尽可能高的置信区间。
求解置信区间的一般方法
(1) 构造样本的一个函数 G = G ( X 1 , X 2 , … , X n ; θ ) G=G(X_1,X_2,…,X_n;θ) G=G(X1,X2,…,Xn;θ)它含有待估参数θ,不含其它未知参数,其分布已知,且分布不依赖于待估参数(常由θ的点估计出发考虑),具有这种性质的函数称为枢轴量(pivot)。
(2) 对于给定的置信水平 1 − α 1-α 1−α,求出两个分位点 a , b a,b a,b,使得 P { a < G < b } ⩾ 1 − α P\{a
(3) 由 a < G < b a
分位点(percentile point):设连续型随机变量 X X X的概率密度函数为 f ( x ) f(x) f(x),对给定的 α ( 0 < α < 1 ) α (0<α<1) α(0<α<1),称满足条件 P { X > x α } = ∫ x α ∞ f ( x ) d x = α P\{X>x_α\}=\displaystyle\int_{x_α}^{∞}f(x)\mathrm{d}x=α P{ X>xα}=∫xα∞f(x)dx=α 的点 x α x_α xα为 α 分位点。
标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1)的α 分位点记作 z α , z α = − z 1 − α z_α,z_α=-z_{1-α} zα,zα=−z1−α
χ 2 ( n ) χ^2(n) χ2(n)分布的α 分位点记作 χ α 2 ( n ) χ_α^2(n) χα2(n)
t ( n ) t(n) t(n)分布的α 分位点记作 t α ( n ) , t α ( n ) = − t 1 − α ( n ) t_α(n),t_α(n)=-t_{1-α}(n) tα(n),tα(n)=−t1−α(n)
F ( n 1 , n 2 ) F(n_1,n_2) F(n1,n2)分布的α 分位点记作 F α ( n 1 , n 2 ) F_α(n_1,n_2) Fα(n1,n2)
单侧置信区间(one-sided confidence interval)
如果 P { θ ^ L < θ } ⩾ 1 − α P\{\hatθ_L<θ\}⩾ 1-α P{ θ^L<θ}⩾1−α则称随机变量 θ ^ L \hatθ_L θ^L为θ的置信度为 1 − α 1-α 1−α 的单侧置信下限(one-side confidence lower limit)。
如果 P { θ < θ ^ U } ⩾ 1 − α P\{θ<\hatθ_U\}⩾ 1-α P{ θ<θ^U}⩾1−α则称随机变量 θ ^ U \hatθ_U θ^U为θ的置信度为 1 − α 1-α 1−α 的单侧置信上限(two-side confidence lower limit)。
正态总体参数的区间估计示例
设总体 X ∼ N ( μ , σ 2 ) , X 1 , X 2 , … , X n X∼ N(μ,σ^2),X_1,X_2,…,X_n X∼N(μ,σ2),X1,X2,…,Xn为样本, X ˉ , S 2 \bar X,S^2 Xˉ,S2分别为样本均值和样本方差,置信区间为 1 − α 1-α 1−α
(1) σ 2 σ^2 σ2已知时, X ˉ \bar X Xˉ是 μ 的极大似然估计,取枢轴量 G = X ˉ − μ σ / n ∼ N ( 0 , 1 ) G=\dfrac{\bar X-μ}{σ/\sqrt{n}}∼ N(0,1) G=σ/nXˉ−μ∼N(0,1)
设常数 a , b a,b a,b满足: P { a < G < b } ⩾ 1 − α P\{a
等价于 P { X ˉ − σ n b < μ < X ˉ − σ n a } ⩾ 1 − α P\{\bar X-\dfrac{σ}{\sqrt{n}}b<μ<\bar X-\dfrac{σ}{\sqrt{n}}a\}⩾ 1-α P{ Xˉ−nσb<μ<Xˉ−nσa}⩾1−α
此时区间的长度为 ( b − a ) σ / n (b-a)σ/\sqrt{n} (b−a)σ/n
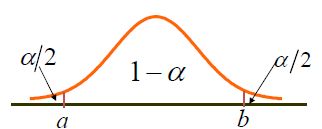
由正态分布的对称性知, a = − b = − z α / 2 a=-b=-z_{α/2} a=−b=−zα/2时,区间的长度达到最短 L = z α / 2 σ / n L=z_{α/2}σ/\sqrt{n} L=zα/2σ/n
n固定,置信水平提高,即 1 − α 1-α 1−α增大,则 z α / 2 z_{α/2} zα/2增大,所以 L L L 变大,精确度降低;反之亦然.
所得 μ 双侧置信区间为 ( X ˉ − σ n z α / 2 , X ˉ + σ n z α / 2 ) (\bar X-\dfrac{σ}{\sqrt{n}}z_{α/2},\bar X+\dfrac{σ}{\sqrt{n}}z_{α/2}) (Xˉ−nσzα/2,Xˉ+nσzα/2)
单侧置信下限为 X ˉ − σ n z α \bar X-\dfrac{σ}{\sqrt{n}}z_{α} Xˉ−nσzα
单侧置信上限为 X ˉ + σ n z α \bar X+\dfrac{σ}{\sqrt{n}}z_{α} Xˉ+nσzα
(2) σ 2 σ^2 σ2已知时,以 S 2 S^2 S2估计 σ 2 σ^2 σ2,的枢轴量 G = X ˉ − μ S / n ∼ t ( n − 1 ) G=\dfrac{\bar X-μ}{S/\sqrt{n}}∼ t(n-1) G=S/nXˉ−μ∼t(n−1)
所得 μ 双侧置信区间为 ( X ˉ − S n t α / 2 ( n − 1 ) , X ˉ + S n t α / 2 ( n − 1 ) ) (\bar X-\dfrac{S}{\sqrt{n}}t_{α/2}(n-1),\bar X+\dfrac{S}{\sqrt{n}}t_{α/2}(n-1)) (Xˉ−nStα/2(n−1),Xˉ+nStα/2(n−1))
单侧置信下限为 X ˉ − σ n t α ( n − 1 ) \bar X-\dfrac{σ}{\sqrt{n}}t_{α}(n-1) Xˉ−nσtα(n−1)
单侧置信上限为 X ˉ + σ n t α ( n − 1 ) \bar X+\dfrac{σ}{\sqrt{n}}t_{α}(n-1) Xˉ+nσtα(n−1)
(3) 其他总体均值的区间估计
当n足够大时(一般 n>30),由中心极限定理知,近似 X ˉ − μ σ / n ∼ N ( 0 , 1 ) \dfrac{\bar X-μ}{σ/\sqrt{n}}∼ N(0,1) σ/nXˉ−μ∼N(0,1)
正态总体的均值、方差的置信区间和单侧置信限(置信水平为 1 − α 1-α 1−α)
一个正态总体
| 待估参数 | 其他参数 | 枢轴量G的分布 | 置信区间 | 单侧置信上/下限 |
|---|---|---|---|---|
| μ μ μ | σ 2 σ^2 σ2已知 | X ˉ − μ σ / n ∼ N ( 0 , 1 ) \dfrac{\bar X-μ}{σ/\sqrt{n}}∼ N(0,1) σ/nXˉ−μ∼N(0,1) | ( X ˉ ± σ n z α / 2 ) (\bar X±\dfrac{σ}{\sqrt{n}}z_{α/2}) (Xˉ±nσzα/2) | X ˉ ± σ n z α / 2 \bar X±\dfrac{σ}{\sqrt{n}}z_{α/2} Xˉ±nσzα/2 |
| μ μ μ | σ 2 σ^2 σ2未知 | X ˉ − μ S / n ∼ t ( n − 1 ) \dfrac{\bar X-μ}{S/\sqrt{n}}∼ t(n-1) S/nXˉ−μ∼t(n−1) | ( X ˉ ± S n t α / 2 ( n − 1 ) ) \left(\bar X± \dfrac{S}{\sqrt{n}}t_{α/2}(n-1)\right) (Xˉ±nStα/2(n−1)) | X ˉ ± σ n t α ( n − 1 ) \bar X±\dfrac{σ}{\sqrt{n}}t_{α}(n-1) Xˉ±nσtα(n−1) |
| σ 2 σ^2 σ2 | μ μ μ未知 | ( n − 1 ) S 2 σ 2 ∼ χ 2 ( n − 1 ) \dfrac{(n-1)S^2}{σ^2}∼χ^2(n-1) σ2(n−1)S2∼χ2(n−1) | ( ( n − 1 ) S 2 χ α / 2 2 ( n − 1 ) , ( n − 1 ) S 2 χ 1 − α / 2 2 ( n − 1 ) ) \left(\dfrac{(n-1)S^2}{χ^2_{α/2}(n-1)},\dfrac{(n-1)S^2}{χ^2_{1-α/2}(n-1)}\right) (χα/22(n−1)(n−1)S2,χ1−α/22(n−1)(n−1)S2) | ( n − 1 ) S 2 χ α / 2 2 ( n − 1 ) \dfrac{(n-1)S^2}{χ^2_{α/2}(n-1)} χα/22(n−1)(n−1)S2 ( n − 1 ) S 2 χ 1 − α / 2 2 ( n − 1 ) \dfrac{(n-1)S^2}{χ^2_{1-α/2}(n-1)} χ1−α/22(n−1)(n−1)S2 |
两个正态总体
| 待估参数 | 其他参数 | 枢轴量G的分布 | 置信区间 | 单侧置信上/下限 |
|---|---|---|---|---|
| μ 1 − μ 2 μ_1-μ_2 μ1−μ2 | σ 1 2 , σ 2 2 σ^2_1,σ^2_2 σ12,σ22 已知 | ( X ˉ − Y ˉ ) − ( μ 1 − μ 2 ) σ 1 2 n 1 + σ 2 2 n 2 ∼ N ( 0 , 1 ) \dfrac{(\bar X-\bar Y)-(μ_1-μ_2)}{\sqrt{\dfrac{σ_1^2}{n_1}+\dfrac{σ_2^2}{n_2}}}∼ N(0,1) n1σ12+n2σ22(Xˉ−Yˉ)−(μ1−μ2)∼N(0,1) | ( ( X ˉ − Y ˉ ) ± z α / 2 σ 1 2 n 1 + σ 2 2 n 2 ) \left((\bar X-\bar Y)± z_{α/2}\sqrt{\dfrac{σ_1^2}{n_1}+\dfrac{σ_2^2}{n_2}}\right) ((Xˉ−Yˉ)±zα/2n1σ12+n2σ22) | ( X ˉ − Y ˉ ) ± z α / 2 σ 1 2 n 1 + σ 2 2 n 2 (\bar X-\bar Y)± z_{α/2}\sqrt{\dfrac{σ_1^2}{n_1}+\dfrac{σ_2^2}{n_2}} (Xˉ−Yˉ)±zα/2n1σ12+n2σ22 |
| μ 1 − μ 2 μ_1-μ_2 μ1−μ2 | σ 1 2 = σ 2 2 = σ 2 σ^2_1=σ^2_2=σ^2 σ12=σ22=σ2 未知 | ( X ˉ − Y ˉ ) − ( μ 1 − μ 2 ) S w 1 n 1 + 1 n 2 ∼ t ( n 1 + n 2 − 2 ) \dfrac{(\bar X-\bar Y)-(μ_1-μ_2)}{S_w\sqrt{\dfrac{1}{n_1}+\dfrac{1}{n_2}}}∼ t(n_1+n_2-2) Swn11+n21(Xˉ−Yˉ)−(μ1−μ2)∼t(n1 |