ML-Agents案例之金字塔
本案例源自ML-Agents官方的示例,Github地址:https://github.com/Unity-Technologies/ml-agents,本文是详细的配套讲解。
本文基于我前面发的两篇文章,需要对ML-Agents有一定的了解,详情请见:Unity强化学习之ML-Agents的使用、ML-Agents命令及配置大全。
我前面的相关文章有:
ML-Agents案例之Crawler
ML-Agents案例之推箱子游戏
ML-Agents案例之跳墙游戏
ML-Agents案例之食物收集者
ML-Agents案例之双人足球
Unity人工智能之不断自我进化的五人足球赛
ML-Agents案例之地牢逃脱

环境说明
本案例的环境要比以往大了很多倍,智能体要在这个相当大的环境中去寻找一个绿色的方块,而方块位于一个金字塔的顶端,想要触碰这个方块必须要推倒金字塔,而金字塔和方块不是一开始就有的,必须要触碰按钮才会出现在随机地点,按钮会刷新在随机的位置。因此智能体想要完成任务,必须要经过寻找按钮–>触碰按钮–>寻找金字塔–>推倒金字塔–>触碰绿色方块,这几个步骤,步骤的复杂和环境的庞大对训练是一个相当大的挑战。
由于奖励太过稀疏,这次的任务如果使用以往的寻常方法是几乎不可能得到一个好的结果的,因此这里我们需要应用到一个好奇心机制,(Curiosity),使得智能体在探索未知事物中得到奖励,才能有效推动训练的进展。
状态输入:
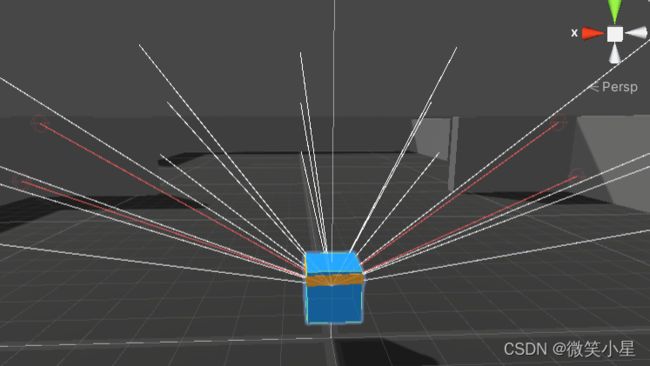
可以看到,智能体采用了射线传感器Ray Perception Sensor 3D,并且使用了三个,以获得上中下的立体视角,上中下三层的每一层都有七条射线,总共有21条射线,每一条射线检测的标签有墙壁、目标金字塔的石头、普通金字塔的石头、目标方块、闭合的开关、断开的开关。参数见下图。关于该传感器的详细说明见ML-Agents案例之推箱子游戏。三个传感器在参数上只有细微差别。
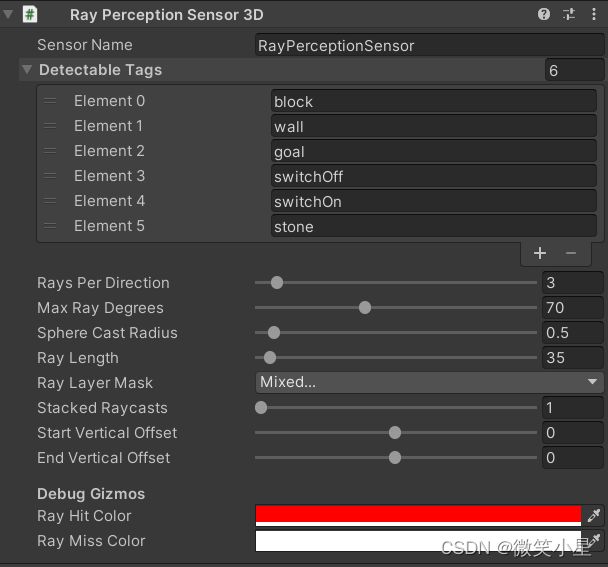


除了射线传感器的输入之外,代码中海油四个输入维度,分别是智能体的速度(三维,Local Space),开关是否闭合。
动作输出:
输出只有一个离散的动作,包含五个值,分别是什么都不做,向前走,向后走,左转,右转。较少的输出会大大降低神经网络复杂度,减少训练时间。缺点是同一时间只能执行一个动作,降低智能体的灵活性,例如不能同时前进和旋转。
代码讲解
智能体代码PyramidAgent.cs:
初始化方法Initialize():
public override void Initialize()
{
// 获取刚体
m_AgentRb = GetComponent();
// 获取控制整个环境的脚本
m_MyArea = area.GetComponent();
// 获取开关的脚本
m_SwitchLogic = areaSwitch.GetComponent();
}
状态输入方法CollectObservations:
public override void CollectObservations(VectorSensor sensor)
{
if (useVectorObs)
{
// 输入开关的状态
sensor.AddObservation(m_SwitchLogic.GetState());
// 输入智能体的速度向量
sensor.AddObservation(transform.InverseTransformDirection(m_AgentRb.velocity));
}
}
动作输出方法OnActionReceived:
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// 给予时间惩罚,鼓励快速结束游戏
AddReward(-1f / MaxStep);
MoveAgent(actionBuffers.DiscreteActions);
}
public void MoveAgent(ActionSegment act)
{
var dirToGo = Vector3.zero;
var rotateDir = Vector3.zero;
// 接收神经网络的输出
var action = act[0];
// 输出处理
switch (action)
{
case 1:
dirToGo = transform.forward * 1f;
break;
case 2:
dirToGo = transform.forward * -1f;
break;
case 3:
rotateDir = transform.up * 1f;
break;
case 4:
rotateDir = transform.up * -1f;
break;
}
// 执行输出
transform.Rotate(rotateDir, Time.deltaTime * 200f);
m_AgentRb.AddForce(dirToGo * 2f, ForceMode.VelocityChange);
}
在一个episode开始时执行方法OnEpisodeBegin():
// 相比以前需要加上这句
using System.Linq;
public override void OnEpisodeBegin()
{
// 取0-9并打乱顺序
var enumerable = Enumerable.Range(0, 9).OrderBy(x => Guid.NewGuid()).Take(9);
var items = enumerable.ToArray();
// 清理区域,销毁场景中所有金字塔(包括真*金字塔)
m_MyArea.CleanPyramidArea();
// 智能体速度归零
m_AgentRb.velocity = Vector3.zero;
// 把自己的位置放到items[0]的区域
m_MyArea.PlaceObject(gameObject, items[0]);
// 随机自己的旋转rotation
transform.rotation = Quaternion.Euler(new Vector3(0f, Random.Range(0, 360)));
// 重置按钮(回到未触发状态,位置随机)
m_SwitchLogic.ResetSwitch(items[1], items[2]);
// 生成六个石头金字塔
m_MyArea.CreateStonePyramid(1, items[3]);
m_MyArea.CreateStonePyramid(1, items[4]);
m_MyArea.CreateStonePyramid(1, items[5]);
m_MyArea.CreateStonePyramid(1, items[6]);
m_MyArea.CreateStonePyramid(1, items[7]);
m_MyArea.CreateStonePyramid(1, items[8]);
}
碰撞检测OnCollisionEnter方法:
void OnCollisionEnter(Collision collision)
{
// 如果碰到目标方块,那么游戏结束,加2分
if (collision.gameObject.CompareTag("goal"))
{
SetReward(2f);
EndEpisode();
}
}
挂在开关下的脚本PyramidSwitch.cs:
// 初始化,获取父物体中的脚本
void Start()
{
m_Area = gameObject.transform.parent.gameObject;
m_AreaComponent = m_Area.GetComponent();
}
重置开关方法:
public void ResetSwitch(int spawnAreaIndex, int pyramidSpawnIndex)
{
// 把开关放置到指定位置
m_AreaComponent.PlaceObject(gameObject, spawnAreaIndex);
// 设定开关状态为断开
m_State = false;
m_PyramidIndex = pyramidSpawnIndex;
tag = "switchOff";
// 旋转归零
transform.rotation = Quaternion.Euler(0f, 0f, 0f);
// 材质变成未触发的状态
myButton.GetComponent().material = offMaterial;
}
碰撞检测:
void OnCollisionEnter(Collision other)
{
// 当碰到未打开的开关,开关变为打开状态,并创造一个金字塔
if (other.gameObject.CompareTag("agent") && m_State == false)
{
myButton.GetComponent().material = onMaterial;
m_State = true;
// 生成真*金字塔
m_AreaComponent.CreatePyramid(1, m_PyramidIndex);
tag = "switchOn";
}
}
整个环境的控制脚本PyramidArea.cs:
参数设置(可以在Unity编辑器中自由更改):
public GameObject pyramid;
public GameObject stonePyramid;
// 生成区域数组
public GameObject[] spawnAreas;
public int numPyra;
public float range;
生成两种金字塔的方法:
public void CreatePyramid(int numObjects, int spawnAreaIndex)
{
CreateObject(numObjects, pyramid, spawnAreaIndex);
}
public void CreateStonePyramid(int numObjects, int spawnAreaIndex)
{
CreateObject(numObjects, stonePyramid, spawnAreaIndex);
}
void CreateObject(int numObjects, GameObject desiredObject, int spawnAreaIndex)
{
for (var i = 0; i < numObjects; i++)
{
// 生成金字塔,并且作为本物体的子物体
var newObject = Instantiate(desiredObject, Vector3.zero,
Quaternion.Euler(0f, 0f, 0f), transform);
// 移动金字塔到指定位置
PlaceObject(newObject, spawnAreaIndex);
}
}
移动金字塔:
public void PlaceObject(GameObject objectToPlace, int spawnAreaIndex)
{
// 生成区域的位置
var spawnTransform = spawnAreas[spawnAreaIndex].transform;
var xRange = spawnTransform.localScale.x / 2.1f;
var zRange = spawnTransform.localScale.z / 2.1f;
// 位置在范围内做一定的随机
objectToPlace.transform.position = new Vector3(Random.Range(-xRange, xRange), 2f, Random.Range(-zRange, zRange))
+ spawnTransform.position;
}
销毁所有的金字塔:
public void CleanPyramidArea()
{
foreach (Transform child in transform)
if (child.CompareTag("pyramid"))
{
Destroy(child.gameObject);
}
}
配置文件
配置1:
behaviors:
Pyramids:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.01
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
curiosity:
gamma: 0.99
strength: 0.02
network_settings:
hidden_units: 256
learning_rate: 0.0003
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 128
summary_freq: 30000
相比于以往的设置,不同的地方在于奖励信号的设置多了一项Curiosity,也就是好奇心奖励信号,这个奖励信号在本项目中是必须的,通过给予奖励鼓励智能体在环境中探索新事物,这样才能使智能体在稀疏奖励的环境下顺利训练,其参数如下:
curiosity:
gamma: 0.99
strength: 0.02
network_settings:
hidden_units: 256
learning_rate: 0.0003
gamma:折扣因子,决定了未来奖励对于现在的状态及动作价值的影响程度。推荐:0.8-0.995。
strength:好奇心模块产生的奖励大小,应该设得足够大使其不被环境的奖励淹没,但也不能设得过大反过来淹没环境的奖励。推荐:0.001-0.1。默认为1。
hidden_units:好奇心网络的隐藏层节点个数。
learning_rate:学习率,用于更新好奇心模块,如果训练不稳定,应当减小。推荐:1e-5 - 1e-3。

对于Curiosity的具体讲解请查看:
李宏毅强化学习课程
强化学习——Intrinsic Curiosity Module
配置2:
behaviors:
Pyramids:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.01
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
rnd:
gamma: 0.99
strength: 0.01
network_settings:
hidden_units: 64
num_layers: 3
learning_rate: 0.0001
keep_checkpoints: 5
max_steps: 3000000
time_horizon: 128
summary_freq: 30000
可以看到,第二种配置不同的地方在于没有使用Curiosity奖励机制,使用了另外一种奖励机制,它叫做Random Network Distillation,中文为随机网络蒸馏,简称RND。
rnd:
gamma: 0.99
strength: 0.01
network_settings:
hidden_units: 64
num_layers: 3
learning_rate: 0.0001
其中参数的配置和Curiosity一致,多出一个可以调节的网络层数num_layers。
它和Curiosity一样,属于智能体自身的内部奖励,鼓励智能体积极探索。
运行效果:在100万个step过后智能体能够达到平均1.5以上的奖励。比Curiosity的训练速度要快很多。

详细信息请查看:
强化学习中的好奇心驱动学习算法:随机网络精馏探索技术
exploration by random network distillation
效果演示
后记
本文探究了在稀疏奖励的环境下,我们怎么让智能体更加有效地学习策略,这里我们采用了鼓励探索的方法,主要增加了基于好奇心(Curiosity)的奖励机制,以及基于随机网络蒸馏(Random Network Distillation)的奖励机制。ML-Agents提供了便利的参数设置,使得我们不用去实现那些复杂的网络结构,仅仅靠几行设置就能完美使用这个功能。我认为这种好奇心奖励机制的发展将是未来通用人工智能实现的重要一步。