1.前言
对于非常庞大的数据量,经常需要分片分区
在分片分区的模式下:每一个数据(一行记录)只属于一个分区,每个分区是整个数据库的一部分。
分区为了更好的伸缩性。本章就讨论索引是如何利用分区的。在讨论数据的平衡等问题。
2.分区和备份的关系
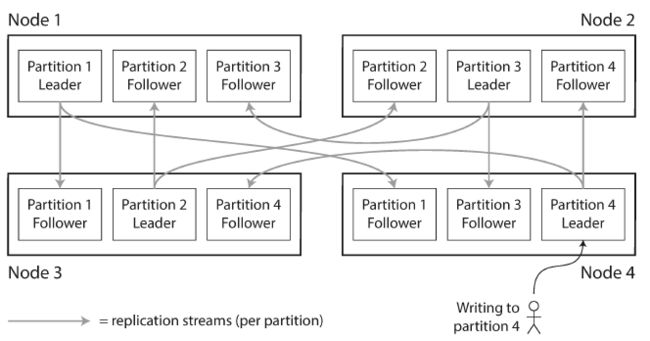
两者经常都是结合起来的,这样每个分区的数据都存有备份,存储在其他的节点上。
一个节点能可以存储多个分区,在单leader模型中,每个节点可以成为某个分区的leader,也可以成为其他分区的follower
如下图所示
3.kv数据的分区
如何进行分区,决定某个记录属于某个节点呢?
目标是让各个分区的数据大小尽可能的均匀。如果分区的规则不公平,可能某些分区会有更多的数据量。称为倾斜.
如果一个分区有不合适的高负载,那么会被称为热点
3.1根据key范围分区
一种方式是根据key的范围来分区,如下图

keys范围分区中,边界的选择不一定需要平均,只要适合自己的数据即可。
可以通过人工选择,也可以根据数据自动选择(后面讲)
每个分区内,保证keys是有序的,利用前面讲过的SSTables和LSM trees完成。
当然,范围分区的缺陷是特定的访问模式会导致热点的出现。
比如按照日期分区,那么每天的写操作只会写到当天对应的分区,成为热点。
3.2根据key的hash值分区
由于倾斜以及热点的问题,很多分不是db选择hash来分区。
这样的话,分区也就根据hash值而不是原来的key来划分了,每个key根据自己的hash值决定落在哪一个分区。如下图

但是,hash分区相对于key分区来说,进行范围查询就很不容易了。
因为原本相邻的两个key,可能hash到完全不同的两个分区。排序结构被破坏了。
因此,一些db的解决办法是:范围查询的语句,让所有分区一起执行,最后再汇总。
3.3负载倾斜以及热点缓解
hash能减缓热点问题但是不能完全避免。极端情况下一个key会受到大量的读写请求。
比如说社交媒体上某个大V有重大消息,粉丝会有大量的读写操作。常见的解决方法如下
如果已知某些key是热点,给这个key加一个随机数(比如rand(100))作为前缀或者后缀。
这样相当于把原有的一个key拆分成100个子key了,写的时候就能随机分布到不同的分区了。
但是读的时候需要额外的工作量,需要读取这100个key的数量,并把他们merge起来.
4.分区以及二级索引
二级索引经常指向的是多行数据而不是一行(比如颜色为红色的车)
由于实现复杂,一个kv存储(如HBase)避免了二级索引。
二级索引的问题是他们不能和分区进行方便的map。
目前二级索引分区主要两种方式:基于文档和基于词语的
4.1 文档分区二级索引
假设有这个场景,卖二手车,每一辆车有一个唯一id。分区按照id来(即key范围分区)
现在二级索引是颜色和制造商
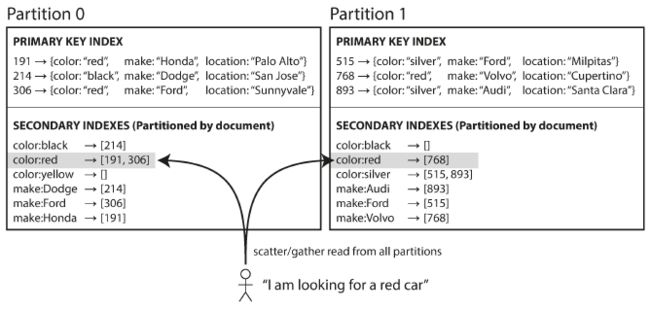
在上图中,每个分区独立,维持自己的二级索引结构,指向在当前分区中的文档。
当对该分区的数据进行改动时,只用更新该分区中的二级索引结构,因此称为local index
读取二级索引的时候,需要读取所有分区的记录,并且结合起来。
比如说找红色的车,那么就要去每个分区找到红色的车,最后结合起来。
这种方式称为scatter/gather(分散/聚集).
优劣如下
优:
写操作时,只用改当前分区的二级索引
劣:
读操作因为要遍历所有分区,存在分散聚集,使得二级索引查询操作代价昂贵
尽管如此,它仍受广泛应用,如ES,SolrCloud等
4.2 词语二级索引分区
相对于每个分区自己维持二级索引结构(local index),可以建立global index,来包含所有分区的数据
当然global index也不能建立在一个节点上,global index也需要分区
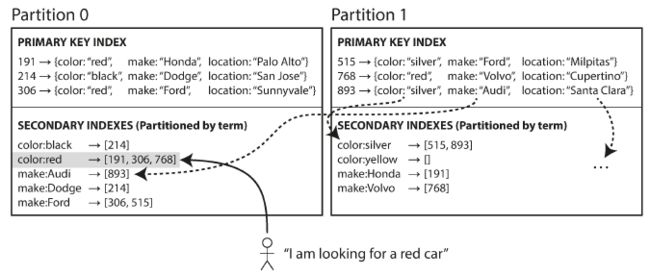
上图中,color以[a,r]开头的在分区0,其他的在分区1.制造商也是类似。
这种被称为term-partitioned,因为查询的term决定了我们要去哪个分区找.
优劣:
优:
读操作更有效率,读一次term就知道数据在哪几个分区,而不用每次读取所有分区
劣:
写操作更复杂,因为可能引起索引改变,导致几个不同分区的数据数据一起变动
实际场景下,这要求分布式事务的执行,但是目前还没有被任何db支持,
因此 global index的更新经常是异步的.
5.分区的Rebalancing
数据库存储的量不断变化,会有下面的场景需求
1.查询量上升,希望加CPU
2.数据量上升,想加磁盘
3.机器宕机,其他机器接管它的职责
上面的变化都要求数据从一个分区移动到另外一个分区,称之为rebalancing,它往往有几个要求
rebalancing要求负载尽可能平衡
rebalancing发生时数据库要能保证读写能够正常进行
rebalancing发生时要尽量减少不必要的数据移动,来减少网络和磁盘IO
5.1 rebalancing策略
先问一个问题,为什么分区不用mod N
如果N变化了,那么数据就得从一个分区移动到另外一个分区了
比如初始10个分区,key为123456
mod 10到6这个区。后来有11个分区了,mod 11到了3这个分区。
这样就移动了不必要的数据
5.1.1 固定的分区数量
有种简单的方法是创建远比节点数量多的分区数量,把多个分区分配各一个几点。
比如10个节点包含1000个分区。
如果有新的节点加入,那么新节点从原有的各个节点挪走一部分的分区,直到balance。
节点间移动的是整个分区。
分区的总数不变
各个分区处理的keys不变
各个节点分配的分区会变
如下图
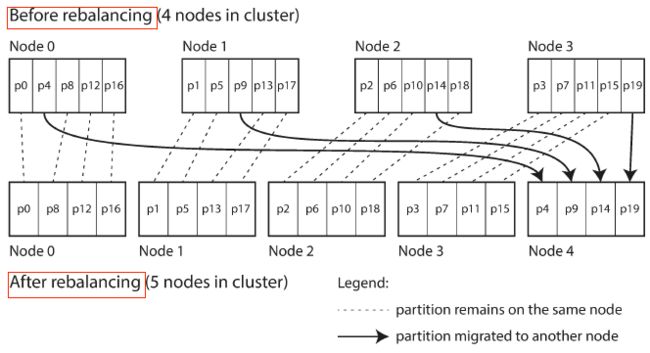
这种方式下,分区数量是固定的。
原则上允许split和merge各个分区
但是固定分区个数会更简单,所以有固定分区个数的算法实现中,不会包含split的过程。
这种实现上,会选择足够大的分区个数,来应对未来的增长,虽然开始的管理会显得麻烦一点。
另外,选择何时的分区的size很难,因为分区数量是固定的但是data size在变化。很难做到刚刚合适。
5.1.2 动态分区
背景
对于利用key range来分区的数据库来说,固定分区数量非常不方便:
如果range的值定的不合理,那么会造成某些分区数据多而某些分区数量少,即数据不均衡。
然而手动重新配置各个range又显得麻烦
因此,对于HBase这样的key range数据库来说,分区是动态创建的。
实现
一个分区分配给一个节点,一个节点可以管理多个分区。
既可以进行split(某个分区数据量过大),也可以进行merge(几个分区数据量过小)
当一个大的分区进行split,会把一半的数据给另一个节点,来完成负载均衡。(书中这里不懂,应该是给另一个分区吧)
优劣
优:
能够适应总体的数据量:
数据小的时候,小数量的分区就足够,开销很小
数据大的时候,每个分区最大的容量根据一个配置的参数来定
劣:
刚启动时只有一个分区,所有读写都会到这个一分区。而其他的节点这时完全闲置。没有达到负载均衡的效果。
解决的一个办法是类似于HBase进行一个预分区(当然有先验知识更好,也就是知道数据分布的情况),也就是说一开始就有多个分区,这样来避免初期的单分区造成的负载不均衡。
场景
适合key range分区,也适合hash range分区
5.1.3 按节点比例进行分区
背景
动态分区中,分区的数量和数据量的大小有关,因为不论split还是merge,每个分区的size都会在一个固定配置的minSize,maxSize区间中
固定分区中,每个分区的size和数据量的size相关
因此,两种场景中,分区的数量其实都和节点的数量没有关系
因此,第三种方法是让分区的数量和节点的数量相关,也就是一个节点有固定数量的分区。
实现
当节点数不变的时候,总共的分区数不变,此时数据量增大,每个分区的数据也增大。
当新节点加入,加多了固定数量的分区数,每个分区会随机把已经存在的分区的部分数据迁移过来(split),这会导致不公平的split.当然有些实现会有些重平衡的策略,这里不展开。
5.2 手动还是自动rebalancing
完全自动和完全手动rebalance是有平滑过度的。
全自动化很方便,但是这样会造成结果不可预估,比如数据在节点之间移动,造成网络阻塞等
还是手动好,虽然慢一点,但是安全稳定
6.请求路由
背景
当split或者merge之后,分区重平衡了,每个节点对应分区的内容变了。
假如现在需要读写key值为”foo“,client到底应该连哪一个ip和port呢。
需要有一个角色在顶层来回答这个问题。
这个也称为服务发现。
方式
有几种方式
1.client随便连node,node能处理就处理,不能就找到可以处理的nodeA,把nodeA的最终结果返回client
2.有一个路由层,专门告诉client去哪里请求。作用类似负载均衡。
3.client自己感知各node负责的分区

上面几种方式都有一个关键问题
做路由决策的组件如何感知路由的变化
要达成一致性是一个很有挑战性的问题,有一些分布式一致性的协议,但是很难被正确的实现。
很多分布式数据系统都依赖一个协同服务类似Zookeeper来跟踪cluster的元数据。
(Zookeeper源码之前都讲过,比较熟悉)
就是client注册watch来感知Zk上一些znode的创建,删除,内容改动的行为
现状
比如HBase,SolrCloud,Kafka都用Zookeeper
Cassanddra和Riak用gossip协议
7.总结
探讨路分区的方式(key range, hash range)
探讨了分区和二级索引的两种方式(文档分区的二级索引,词语分区的二级索引)
探讨了Rebalancing的三个策略(固定分区数量,动态分区,按节点比例的分区)
探讨了请求路由的几种方式以及目前的一些现状
思考
名词
倾斜,热点,local index,global index,scatter/gather
单个key热点的解决
文档二级索引与local index与scatter/gather, 文档二级索引的优劣
refer
了解预分区相关(没有深入)
http://www.cnblogs.com/niurougan/p/3976519.html
http://blog.csdn.net/javajxz008/article/details/51913471