[论文阅读:Transformer] 2111 Restormer:Efficient Transformer for High-Resolution Image Restoration
[论文阅读:Transformer] 2111 Restormer:Efficient Transformer for High-Resolution Image Restoration
low-level领域最新Transformer: Restormer
https://paperswithcode.com/paper/restormer-efficient-transformer-for-high 可以看到其已经在low-level领域屠榜了
![[论文阅读:Transformer] 2111 Restormer:Efficient Transformer for High-Resolution Image Restoration_第1张图片](http://img.e-com-net.com/image/info8/7482926f777c40d1ba598b5c6ed05b1c.jpg)
代码:https://github.com/swz30/Restormer
论文:https://arxiv.org/abs/2111.09881
本文提出一种low-level视觉新Transformer模型:Restormer,在多个图像恢复任务上取得了最先进的结果,包括图像去雨、单图像运动去模糊、散焦去模糊(单图像和双像素数据)和图像去噪等,优于SwinIR、IPT等网络
![[论文阅读:Transformer] 2111 Restormer:Efficient Transformer for High-Resolution Image Restoration_第2张图片](http://img.e-com-net.com/image/info8/8d04c948066f458489a0a1cad0199e67.jpg)
摘要:
由于卷积神经网络 (CNN) 在从大规模数据中学习可泛化的图像先验方面表现良好,因此这些模型已广泛应用于图像恢复和相关任务。最近,另一类神经架构 Transformers 在自然语言和高级视觉任务上表现出显著的性能提升。虽然 Transformer 模型减轻了 CNN 的缺点(即有限的感受野和对输入内容的不适应),但其计算复杂度随空间分辨率成二次方增长,因此无法应用于大多数涉及高分辨率图像的图像恢复任务。
在这项工作中,我们通过在构建块(多头注意力和前馈网络)中进行几个关键设计来提出一种高效的 Transformer 模型,以便它可以捕获远程像素交互,同时仍然适用于大图像。我们的模型名为 Restoration Transformer (Restormer)。
Contributions
- 提出了Restormer,一种编码-解码结构的Transformer,用于在高分辨率图像上进行多尺度局部/全局表示学习,而不将它们分解成局部窗口,从而利用遥远的图像上下文。
- 提出了一种使用深度卷积的多头转置注意模块(multi-Dconv head transposed attention, MDTA),它能够聚合局部和非局部像素交互,并且足够有效地处理高分辨率图像。
- 一种新的使用深度卷积的门控前馈网络(Gated-Dconv feed-forward network, GDFN),它执行受控的特征转换,即抑制信息量较少的特征,只允许有用的信息进一步通过网络层次结构
整体框架
- 多尺度层次化设计
- Transformer Block 里面包括 MDTA和GDFN
- (a) multi-Dconv head transposed attention (MDTA) 键值对跨通道交互信息,而不是跨空间交互信息
- (b) Gated-Dconv feed-forward network (GDFN) 控制有用信息进一步传播
![[论文阅读:Transformer] 2111 Restormer:Efficient Transformer for High-Resolution Image Restoration_第3张图片](http://img.e-com-net.com/image/info8/2d590f82e84c4e638572d57b1b179640.jpg)
图2. 高分辨率图像恢复的restormer的结构。多尺度分层设计,结合高效 Transformer Block。
Transformer Block的核心模块有: (a) multi-Dconv head transposed attention (MDTA),跨通道(而不是空间维度)执行(空间丰富的)查询键特征交互; (b) gate - dconv feed-forward network (GDFN),执行受控的特征转换,即允许有用的信息进一步传播。
网络首先经过一个3x3卷积得到特征嵌入F0,接下来 浅层特征F0经过一个4层级对称的编码-解码架构,将特征转换为深层特征Fd, 后接包含Transformer block的Refinement模块(在高分辨率下),后接一个卷积层得到残差图像,最后I‘=I+R
- a multi-scale hierarchical module 多尺度层次化模块 相比单尺度网络SwinIR,这样可以减轻计算需求
- 每个级别的编码器-解码器都包含多个Transformer模块,Transformer模块的数量从上到下(from top to bottom)逐渐增加(精细化设计各层级block数目),编码器层次化地减少空间尺寸(类似按照U-Net架构)
- 上采样和下采样 采用的是pixel-unshuffle和pixel-shuffle
- skip-connection concatenation之后 使用1x1的卷积将通道数减半(除了第一个skip-connection)
(a) multi-Dconv head transposed attention (MDTA)
Transformer中的主要计算开销来自于self-attention,其计算复杂度与输入图片的尺寸的平方成正比,对于尺寸为WxH的输入图像,其计算复杂度为 O ( W 2 H 2 ) O(W^2H^2) O(W2H2),所以在需要输入高分辨率图片的应用中很难应用SA模块。
而MDTA模块如下所示,其拥有线性复杂度, O ( W H ) O(WH) O(WH)。key ingredient是跨通道而不是空间维度应用SA,这儿应该是指 Q K T QK^T QKT矩阵乘法的运算结果维度为 R C × C {\mathbb{R}}^{C{\times}C} RC×C, 即计算跨通道的交叉协方差,以生成一个对全局上下文进行隐式编码的注意图。作为MDTA中的另一个重要组件,我们在计算特征协方差以生成全局注意图之前,引入深度卷积来强调局部上下文。
![[论文阅读:Transformer] 2111 Restormer:Efficient Transformer for High-Resolution Image Restoration_第4张图片](http://img.e-com-net.com/image/info8/d7635a8b49914a7d8af1ef4afc01e89e.jpg)
MDTA与原始transformer Multi-head self-attention的区别:
- 在LN归一化后,使用1x1卷积和3x3深度卷积得到Q/K/V,使用的是bias-free的卷积
- 矩阵计算后得到的 Q K T QK^T QKT维度不是(HW,HW),而是(C,C),再通过softmax得到Transposed-Attention Map
MDTA的整体过程可以描述为:
![[论文阅读:Transformer] 2111 Restormer:Efficient Transformer for High-Resolution Image Restoration_第5张图片](http://img.e-com-net.com/image/info8/8e60d023f68b42dda953d8d158cce7ed.jpg)
其中 α \alpha α是可学习的放缩参数,用于控制点乘后softmax前的 Q ^ \hat{Q} Q^和 K ^ \hat{K} K^的幅值
(b) Gated-Dconv feed-forward network (GDFN)
在前馈网络部分,我们提出了两个基本改进来改进表示学习:(1)门控机制和(2)深度卷积。我们的GDFN架构如下图所示。
![[论文阅读:Transformer] 2111 Restormer:Efficient Transformer for High-Resolution Image Restoration_第6张图片](http://img.e-com-net.com/image/info8/3c7bf4ce2bbb400fb047e58daca3c271.jpg)
门控机制被制定为两个平行路径的线性变换层的元件的乘积,其中一个被GELU非线性[26]激活。与在MDTA中一样,我们还在GDFN中包含深度卷积来编码信息空间上相邻像素的位置,有用的学习局部图像结构,以有效的恢复。给定一个输入张量 X ∈ R H ^ × W ^ × C ^ X∈{\mathbb{R}}^{\hat{H}\times\hat{W}\times\hat{C}} X∈RH^×W^×C^, GDFN表示为:
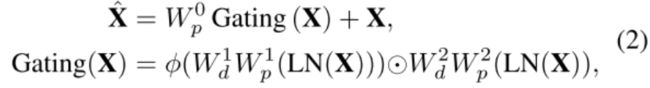
式中 ⊙ \odot ⊙为元素相乘,φ表示GELU非线性激活层,LN为层归一化。
总的来说,GDFN控制着管道中各个层次的信息流,从而允许每个层次关注与其他层次互补的细节。也就是说,与MDTA相比,GDFN提供了一个独特的角色(专注于用上下文信息丰富特性)。由于提出的GDFN比常规FN(ViT)执行更多的操作,我们降低了膨胀比γ,从而具有类似的参数和计算负担。
Progressive Learning 渐进式学习
基于cnn的复原模型通常在固定大小的图像块上进行训练。然而,在小的裁剪patch上训练Transformer模型可能无法编码全局图像统计信息,从而在测试时提供对全分辨率图像的次优性能。
为此,我们进行了渐进式学习,即网络在早期的训练时间内对较小的图像块进行训练,并在后期的训练时间内逐渐对较大的图像块进行训练。通过渐进式学习对混合大小的patch进行训练的模型在测试时表现出增强的性能,图像可以是不同的分辨率(图像恢复中的常见情况)。
渐进学习策略的行为方式类似于课程学习过程,网络从一个更简单的任务开始,然后逐渐转移到学习一个更复杂的任务(其中需要保存精细的图像结构/纹理)。由于在大patch上进行训练需要花费更长的时间,所以我们随着patch大小的增加而减少批大小,以保持每个优化步骤与固定patch训练的时间相似。
实验结果
实现细节
- 我们针对不同的图像恢复任务训练不同的模型。Transformer采用4级编码器-解码器结构。
- 从1级到4级,Transformer blocks的数量为[4,6,6,8],MDTA中的注意头为[1,2,4,8],通道数为[48,96,192,384]。
- Refinement阶段包含4个Transformer块。GDFN中的通道扩展系数为γ=2.66。
- 我们使用AdamW优化器(β1=0.9, β2=0.999,权值衰减1e−4)训练模型,共进行300K次迭代,初始学习速率3e−4通过余弦退火逐渐降低到1e−6。
- 使用渐进式学习(progressing learning),我们开始训练的patch大小为128×128和batch=64。在迭代[92K, 156K, 204K, 240K, 276K]时,patch大小和batch大小对更新为[(1602,40),(1922,32),(2562,16),(3202,8),(3842,8)]。对于数据增强,我们使用水平和垂直翻转。
实际效果
在多个图像恢复任务上取得了最先进的结果,包括图像去雨、单图像运动去模糊、散焦去模糊(单图像和双像素数据)和图像去噪(高斯灰度/彩色去噪和真实图像去噪)。
图像去雨
比较PSNR / SSIM。与最近的最佳方法SPAIR[60]相比,Restormer在所有数据集上平均提高了1.05 dB。
单张图像运动去模糊
评估了在合成数据集(GoPro [55], HIDE[66])和真实数据集(RealBlur-R [64], RealBlur-J[64])上的去模糊效果。
当对所有数据集进行平均时,Restormer比最近的算法MIMO-UNet+[14]获得了0.47 dB的性能提升,比之前的最佳方法MPRNet[92]获得了0.26 dB的性能提升。与MPRNet[92]相比,Restormer的flop减少81%。此外,我们的方法比IPT[13]改进了0.4 dB,同时参数减少了4.4倍,运行速度快了29倍
![[论文阅读:Transformer] 2111 Restormer:Efficient Transformer for High-Resolution Image Restoration_第7张图片](http://img.e-com-net.com/image/info8/29b5f25496ba4cbfba39e944450c92a2.jpg)
散焦去模糊
图像去噪
消融实验
在消融实验中,我们在尺寸为128x128的图像块上训练高斯彩色去噪模型,迭代次数仅为100K。在Urban100[28]上进行测试,并对具有挑战性的噪声水平σ=50进行分析。FLOPS和推断时间在图像大小256x256上计算。表7-10显示了我们的贡献产生了质量性能的改进。
![[论文阅读:Transformer] 2111 Restormer:Efficient Transformer for High-Resolution Image Restoration_第8张图片](http://img.e-com-net.com/image/info8/951ce88b089b46b3adafd8f3c6d35abf.jpg)
![[论文阅读:Transformer] 2111 Restormer:Efficient Transformer for High-Resolution Image Restoration_第9张图片](http://img.e-com-net.com/image/info8/3735b61363334243827f0c65aaaec879.jpg)
改善多头注意力
- 表7c表明,我们的MDTA(multi-Dconv head transposed attention)提供了较基线0.32 dB的良好增益(表7a)。
- 此外,通过深度卷积将局部性引入MDTA,提高了鲁棒性,因为去除它会导致PSNR下降(见表7b)。
前馈网络(FN)的改进
- 从表7d可以看出,FN控制信息流的门控机制比传统FN产生0.12 dB增益[76]。
- 与多头注意力一样,将局部机制(使用深度卷积实现)引入FN也会带来性能优势(见表7e)。
- 我们通过合并门控深度卷积进一步加强FN。我们的GDFN(Gated-Dconv feed-forward network)(表7f)在噪声水平为50时,PSNR增益比标准FN[76]高出0.26 dB。
- 总的来说,我们的Transformer块贡献导致了比基线显著增加0.51 dB。
level-1解码器的设计选择
为了将编码器特性与level-1解码器聚合在一起,我们在拼接操作后不使用1×1卷积(1x1卷积可以将信道减少一半)(level-2/level-3均使用了1x1卷积)。它有助于保存来自编码器的精细纹理细节,如表8所示。这些结果进一步证明了在Refinement阶段添加Transformer块的有效性。
progressive learning的影响
从表9可以看出,在训练时间相近的情况下,渐进式学习的效果优于固定patch训练。
更深还是更广的Transformer?
表10显示,在相似的参数/FLOPs预算下,深窄模型比宽浅模型执行得更准确。然而,由于并行化,更宽的模型运行得更快。在本文中,我们使用深窄Transformer。
总结
我们提出了一种图像恢复Transformer模型,restormer,它可以以很高的计算效率处理高分辨率图像。我们对Transformer块的核心组件引入了关键设计,以改进特征融合和特征转换。
具体来说,我们的multi-Dconv head transposed attention(MDTA)模块通过跨通道而不是空间维度应用自我注意,隐式地建模全局上下文,因此具有线性复杂性而不是二次复杂性。
此外,提出的Gated-Dconv feed-forward network(GDFN)引入了一种门控机制来执行受控特征转换。
为了将cnn的强度合并到Transformer模型中,MDTA和GDFN模块都包括深度卷积,用于编码空间局部上下文。
在16个基准数据集上的广泛实验表明,Restormer实现了许多图像恢复任务的最先进的性能。