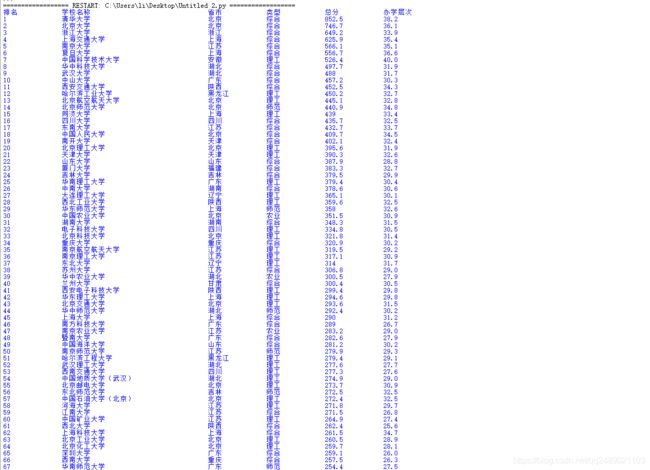
定向爬虫:爬取最好大学网的中国大学排名
定向爬虫:爬取最好大学网的中国大学排名
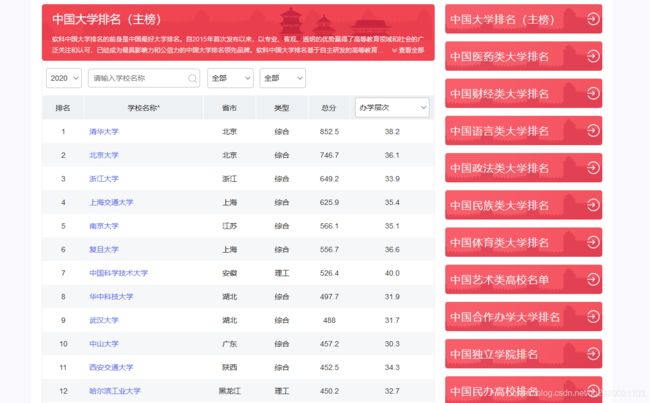
网站在此:最好大学网
f12查看网页源代码
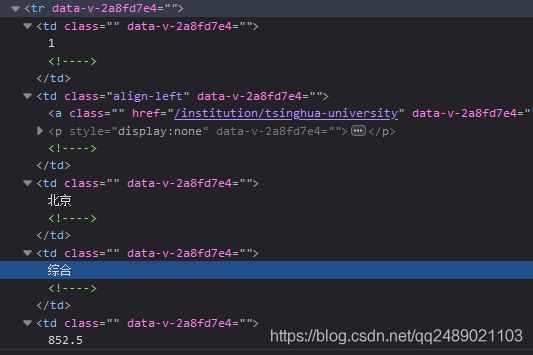
分析得知,所有大学排名都包含在一个tbody标签中,而tbody标签中的tr标签又分别包含了很多tr标签,每一个tr标签代表一所大学,每个tr标签中包含了6个td标签,分别代表大学的排名,名字,省市,类型,总分,办学层次。
如下所示:
 分析:要提取的信息都在html文件中,所以选择用bs4库和requests库就行了,先用get方法获取html页面,然后用bs4遍历解析页面,再将提取出来的字符串存入列表最后输出即可。
分析:要提取的信息都在html文件中,所以选择用bs4库和requests库就行了,先用get方法获取html页面,然后用bs4遍历解析页面,再将提取出来的字符串存入列表最后输出即可。
首先,有三部分的功能:爬取,解析,输出。分别三个函数就行了
#! /usr/bin/env python
#coding=utf-8
import requests
from bs4 import BeautifulSoup
import bs4
def getHtmlText(url):#爬取url
def fillUnivList(ulist,html):#解析html界面
def printUnivList(ulist,num): #输出结果
def main():
gethtmltext函数用来爬取url界面,爬取有可能不成功,所以利用requests库的raise_for_status()方法来判断服务器返回的状态码,如果状态码不是200,则抛出一个异常,用try和except关键字来捕捉异常,这样程序便能够在爬取失败的情况下及时做出反应,降低了程序崩溃的风险。
def getHtmlText(url):#爬取url
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("爬取异常")
return ""
别忘了更改编码方式
获取到了html界面之后,接下来就是利用bs4库中的html解析器对返回的字符串进行解析,然后使用find().children方法查找tbody标签的所有子标签,利用for 循环将find().children返回的列表切片存ulist 列表中。这里需要注意需要加入isinstance判断,以为解析出来的有些东西有可能不是你想要的。
def fillUnivList(ulist,html):#解析html界面
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].text.strip(), tds[1].a.text.strip(), tds[2].text.strip(), tds[3].text.strip(), tds[4].text.strip(), tds[5].text.strip()])
这里开始时得不到想要的字符串,后来发现用strip()去掉空白控制字符就行了。
第三步就非常简单了,格式化输出列表即可
def printUnivList(ulist,num): #输出结果
print("{:^10}\t{:^20}\t\t{:^10}\t{:<10}\t{:<10}\t{:<6}".format("排名", "学校名称", "省市", "类型", "总分" , "办学层次"))
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^20}\t\t{:^10}\t{:<10}\t{:<10}\t{:<6}".format(u[0],u[1],u[2],u[3],u[4],u[5]))
完整代码如下:
#! /usr/bin/env python
#coding=utf-8
import requests
from bs4 import BeautifulSoup
import bs4
def getHtmlText(url):#爬取url
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("爬取异常")
return ""
def fillUnivList(ulist,html):#解析html界面
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].text.strip(), tds[1].a.text.strip(), tds[2].text.strip(), tds[3].text.strip(), tds[4].text.strip(), tds[5].text.strip()])
def printUnivList(ulist,num): #输出结果
print("{:^10}\t{:^20}\t\t{:^10}\t{:<10}\t{:<10}\t{:<6}".format("排名", "学校名称", "省市", "类型", "总分" , "办学层次"))
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^20}\t\t{:^10}\t{:<10}\t{:<10}\t{:<6}".format(u[0],u[1],u[2],u[3],u[4],u[5]))
def main():
uinfo = []
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
html = getHtmlText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,500)
main()
运行截图: