本篇文章,是近期阅读《信息通信技术与政策》2021年第6期的一些有关隐私计算的文章时,记录的笔记,记录在此。
隐私计算发展综述(闫树)
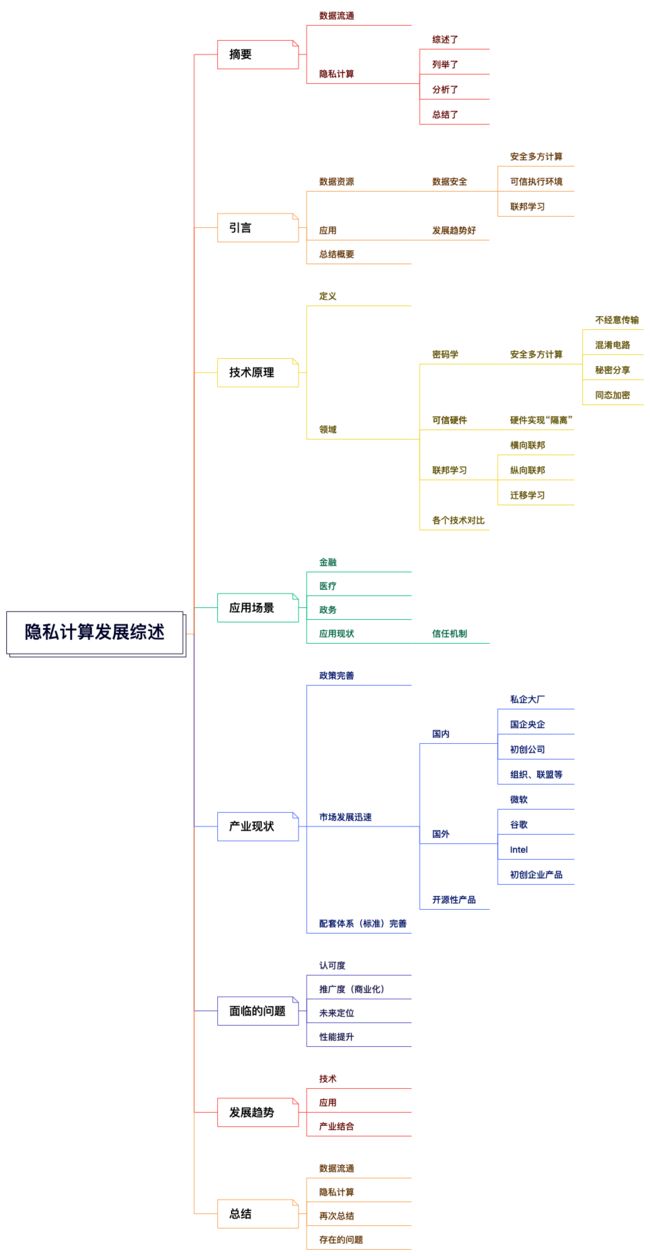
不经意传输(OT)
不经意传输,也称茫然传输,提出了一种在数 据传输与交互过程中保护隐私的思路。 在不经意传输 协议中,数据发送方同时发送多个消息,而接收方仅获 取其中之一。 发送方无法判断接收方获取了具体哪个消息,接收方也对其他消息的内容一无所知。
混淆电路(GC)
混淆电路,是一种将计算任务转化为布尔电路并对真值表进行加密打乱等混淆操作以保护输入隐 私的思路。 利用计算机编程将目标函数转化为布尔电 路后,对每一个门输出的真值进行加密,参与方之间在 互相不掌握对方私有数据的情况下共同完成计算。 混淆电路是姚期智院士针对百万富翁问题提出的解决方 案,因此又称姚氏电路。
秘密分享(SS)
秘密分享,也称秘密分割或秘密共享,给出了 一种分而治之的秘密信息管理方案。 秘密分享的原理 是将秘密拆分成多个分片(Share),每个分片交由不同 的参与方管理。 只有超过一定门限数量的若干个参与 方共同协作才能还原秘密信息,仅通过单一分片无法 破解秘密。
同态加密 (HE)
同态加密,是一类实现在基础的加密操作之 上直接完成密文数据间运算的加密算法。 数据经过同 态加密后进行计算得到的结果与用同一方法在明文计 算下得到的结果保持一致,即先计算后解密等价于先 解密后计算。
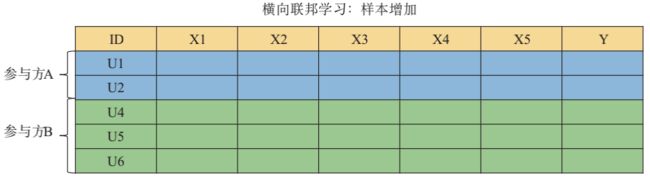
横向联邦学习
数据矩阵(也可以是表格,例如,Excel表格)的横向的一行表示一条训练样本,纵向的一列表示一个数据特征(或者标签)。通常用表格查看数据(例如,病例数据),用一行表示一条训练样本比较好,因为可能有很多条数据。参考
适用于参与者的数据特征重叠较多,而样本ID重叠较少的情况,例如,两家不同地区的银行的客户数据。“横向”二字来源于数据的“横向划分(horizontal partitioning, a.k.a. sharding)”。如图所示例,联合多个参与者的具有相同特征的多行样本进行联邦学习,即各个参与者的训练数据是横向划分的,称为横向联邦学习。
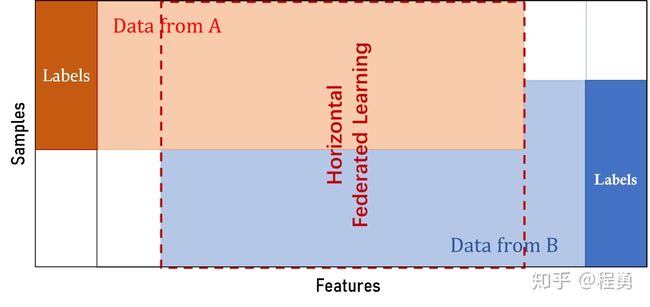
横向联邦学习也称为特征对齐的联邦学习(Feature-Aligned Federated Learning),即横向联邦学习的参与者的数据特征是对齐的。
下图给出了一个横向划分表格的示例,横向联邦使训练样本的总数量增加。
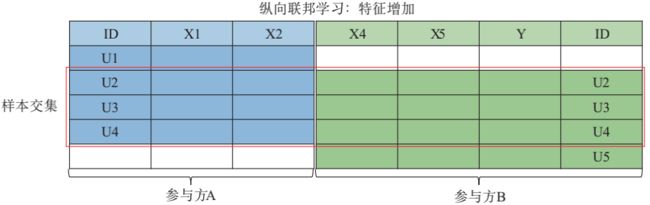
纵向联邦学习
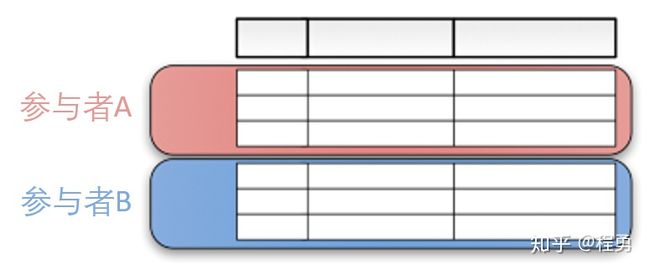
适用于参与者训练样本ID重叠较多,而数据特征重叠较少的情况,例如,同一地区的银行和电商的共同的客户数据。“纵向”二字来源于数据的“纵向划分(vertical partitioning)”。如图所示例,联合多个参与者的共同样本的不同数据特征进行联邦学习,即各个参与者的训练数据是纵向划分的,称为纵向联邦学习。纵向联邦学习需要先做样本对齐,即找出参与者拥有的共同的样本,也就叫“数据库撞库(entity resolution, a.k.a. entity alignment)”。只有联合多个参与者的共同样本的不同特征进行纵向联邦学习,才有意义。纵向联邦使训练样本的特征维度增多。
样本对齐,就是数据求交

纵向联邦学习也称为样本对齐的联邦学习(Sample-Aligned Federated Learning),即纵向联邦学习的参与者的训练样本是对齐的。
下图给出了一个纵向划分表格的示例。
迁移学习
联邦迁移学习则适用于数据集间样本和特征重合均较少的场景。 在这样的场景中,不再对数据进行切分,而是利用迁移学习来弥补数据或标签的不足。 以不同地区、不同行业机构之间进行联合建模为例,用户群体和特征维度的交集都很小,联邦迁移学习即用来针对性解决单边数据规模小、标签样本少的问题。
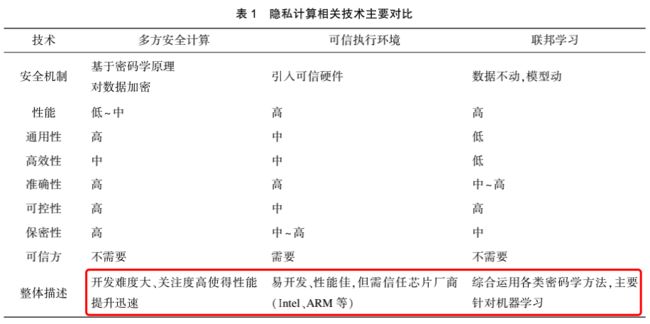
关键技术对比
隐私计算开源产品

开源库
1、 Concrete:是AI 公司 Zama 开源的基于全同态加密的软件库,支持TFHE方案的一个自定义变体,基于的是GSW方案。
2、 Private Join and Compute:谷歌开源的新型多方安全计算开源库,结合了隐私求交和同态加密两种基本的加密技术,实现对求交信息计算。
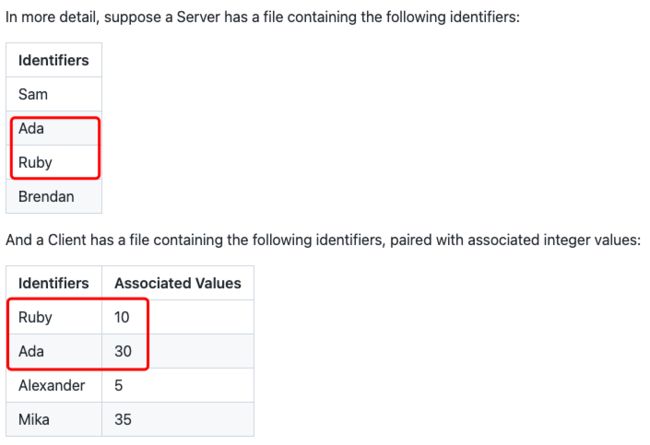
能求出交集对应label的和!
隐私计算关键技术与创新(符芳诚)
PSI
PSI,就是隐私信息求交,它要求参与方在互相不公开本地集合的前提下,共同计算得出多个参 与方的集合的交集,且不能向任何参与方泄露交集以外的信息。
在纵向联邦学习场景中, PSI 也被称为样本对齐( Sample Alignment) 或者数据库撞库,即各参与方需要首先求出各自的训练样本ID 集合之间的交集,基于计算得到的训练样本 ID 交集进行后续的纵向联邦模型训练。
多方PSI
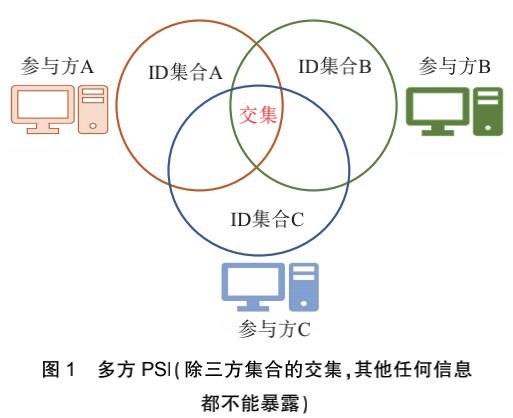
计算多方时,计算复杂度会变大,一般还是两两求交,代替多方求交。
(1)最早的PSI,是基于DH,基于盲签名的和基于OT的,但进行两两求交时,会泄露那些属于两方交集但不属于多方交集的数据。
(2)然后提出真正的多方的PSI,主要思想是将样本 ID 集合编码 成特殊的数据结构,即不经意多项式,其中每一个样本 ID 均为不经意多项式的根【进行编码】;然后利用半同态加密算法对 多项式参数进行保护,使多个参与方可以在密文空间下进行多项式求值,同时又无法读取多项式参数的明 文。 然而,大整数多项式系数展开和求值的计算复杂 度均为 O(n3 )。(APSI中的Partition)
(3)优化方法:分块。具体来说利用哈希分桶技 术将 ID 集合均匀映射到若干 ID 分桶中,这里要求各 参与方使用相同的哈希函数,以便确保相同的样本 ID 被映射到相同的分桶中。 这样一来,只需要进行“桶内 计算、桶间合并”即可得到完整的多方 ID 集合的交集。 将单个桶内样本数量视为一个常数,算法的计算复杂 度可以优化到 O(n)。(APSI中的cuckoo hash)
Unbalanced-PSI
即一个参与方 A 的样本量 远远小于另一参与方 B,这里称拥有样本量少的 A 为 弱势方,称拥有样本量多的 B 为强势方。 此 时,PSI 的计算结果可能非常接近弱势方的真实样本 ID 集合,存在一定的数据泄露风险。
解决办法:
混淆。在 PSI 流程中,提 出从强势方的 ID 集合中随机抽取部分密文 ID 数据混 入最终交集中。
双方都有输出。
(1)最终计算得到的 PSI 交集由真实交集和混淆 集合组成,其中混淆集合全部来自强势方的样本 ID。
(2)弱势方可以获得 PSI 交集,同时可以通过对比 本地 ID 集合和 ID 交集得到真实的样本 ID 交集,但是 无法获取混淆交集部分的样本 ID(由密文保护),保护 了强势方的数据安全。
(3)强势方可以获得 PSI 交集,但是无法判断哪些 样本属于真实 ID 交集。
(4)在实际场景中,当弱势方和强势方数据量之 比在 1:100 时,只需要取真实交集与强势方集合数据 量之比为 1: 10, 即可将弱势方数据的安全性 提 升 10 倍。
斜向联邦学习
在斜向联邦学习场景里,参与方 A 和参与方 B 各拥有 一部分特征,且两个参与方分别拥有一部分由两方 PSI 获得的交集中的样本的标签信息,具体参见图。

两方斜向联邦学习适用的场景是联邦学习的两个 参与方 A 和 B 的训练数据有重叠的数据样本,两方拥 有的数据特征却不同,两方数据特征空间形成互补,类似于纵向联邦学习场景。 与纵向联邦学习不同的是, 在两方斜向联邦学习里,参与方 A 和参与方 B 各拥有 一部分 PSI 交集里的样本对应的标签信息,甚至参与 方 A 和参与方 B 可能同时拥有一部分样本的标签信 息。
PowerFL平台
腾讯 Angel PowerFL(简称 PowerFL) 安全联合计算平台是通用型隐私计算平台。PowerFL 平台提供多种隐私保 护机制,包括半同态加密、秘密分享、差分隐私、TEE 等。
其他
1、Angel 机器学习平台
腾讯AI开源项目Angel,地址
2、 Spark
Apache Spark是一个开源集群运算框架,允许用户将资料加载至集群存储器,并多次对其进行查询,非常适合用于机器学习算法。
3、 Pulsar
Pulsar 是一个用于服务器到服务器的消息系统,具有多租户、高性能等优势。用于集群。