金融风控-贷款违约预测学习笔记(Part4:建模与超参调整)
金融风控-贷款违约预测学习笔记(Part4:建模与超参调整)
- 1. 模型与其相关原理介绍
- 2. 模型对比与性能评估
-
- 2.2 逻辑回归
- 2.3 决策树模型
- 2.4 集成学习方法
- 3. 模型评估方法
-
- 3.1 留出法
- 3.2 交叉验证法
- 3.3 自助法
- 3.4 总结:
- 4. 模型评价标准
- 5. 代码示例
-
- 5.1 模块导入
- 5.2 读取数据
- 5.3 简单建模
- 5.4 模型调参
-
- 5.4.1 贪心调参
- 5.4.2 网格搜索
- 5.4.3 贝叶斯调参
- 5.5 建立最终模型
本节主要内容:模型创建,模型评价和调参策略
资料参考:https://github.com/datawhalechina/team-learning-data-mining/blob/master/FinancialRiskControl/Task4%20%E5%BB%BA%E6%A8%A1%E8%B0%83%E5%8F%82.md
1. 模型与其相关原理介绍
参考资料
-
1 逻辑回归模型
https://blog.csdn.net/han_xiaoyang/article/details/49123419 -
2 决策树模型
https://blog.csdn.net/c406495762/article/details/76262487 -
3 GBDT模型
https://zhuanlan.zhihu.com/p/45145899 -
4 XGBoost模型
https://blog.csdn.net/wuzhongqiang/article/details/104854890 -
5 LightGBM模型
https://blog.csdn.net/wuzhongqiang/article/details/105350579 -
6 Catboost模型
https://mp.weixin.qq.com/s/xloTLr5NJBgBspMQtxPoFA -
7 时间序列模型)
RNN:https://zhuanlan.zhihu.com/p/45289691
LSTM:https://zhuanlan.zhihu.com/p/83496936
-
8 推荐教材:
《机器学习》 https://book.douban.com/subject/26708119/
《统计学习方法》 https://book.douban.com/subject/10590856/
《面向机器学习的特征工程》 https://book.douban.com/subject/26826639/
《信用评分模型技术与应用》https://book.douban.com/subject/1488075/
《数据化风控》https://book.douban.com/subject/30282558/
2. 模型对比与性能评估
2.2 逻辑回归
- 训练速度快,简单易理解,可解释性强
- 需要分箱、归一化、处理异常值和缺失值
虽然可以引入非线性项来解决非线性问题,但是效果不佳
2.3 决策树模型
- 不需要预处理,不需要归一化,不需要处理缺失数据
- 采用贪心算法,容易得到局部最优解。
2.4 集成学习方法
常见的有bagging、boosting、stacking等,都是将已有的分类或回归算法通过一定方式组合起来,形成一个更加强大的分类器,区别在于结合方式不一样。
3. 模型评估方法
3.1 留出法
将数据集划分为训练集和测试集,且划分的时候要尽可能保证数据分布的一致性(这里的数据分布是否指目标特征的分布?)。为保证数据分布的一致性,通常采用分层采样的方式来对数据集进行采样。
3.2 交叉验证法
k折交叉验证法,通常将数据集分为K份,
交叉验证中数据集的划分依然是依据分层采样的方式来进行
3.3 自助法
对数据集进行m次的有放回抽样,得到大小为m的训练集。因为是有放回抽样,所以有的样本没有被重复抽取,有的样本则未被抽取。未被抽取的样本作为测试。
3.4 总结:
- 数据集样本量充足时,可以采用留出法和K折交叉验证法
- 数据集样本量小,且难以有效划分训练/测试集的时候,使用自助法
- 数据集样本量小,且可以有效划分训练/测试集的时候,最好使用留一法
4. 模型评价标准
本次竞赛中,以AUC作为模型评价标准。详见Part1:赛题理解
5. 代码示例
5.1 模块导入
import pandas as pd
import numpy as np
import warnings
import os
import seaborn as sns
import matplotlib.pyplot as plt
c:\users\honk\appdata\local\programs\python\python37\lib\site-packages\statsmodels\tools\_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tm
"""
seaborn 相关设置
"""
# 将matplotlib的图表样式替换成seaborn的图标样式
sns.set()
# 设定绘图风格。可选参数值:darkgrid(默认), whitegrid, dark, white, ticks
sns.set_style('whitegrid')
# 绘图元素比例。可选参数值(线条和字体越来越粗):paper,notebook(默认),talk,poster
sns.set_context('talk')
# 中文字体设置,解决中文字体无法显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
sns.set(font='SimHei')
# 解决负号'-'无法正常显示的问题
plt.rcParams['axes.unicode_minus'] = False
5.2 读取数据
def reduce_mem_usage(df):
# 调整之前的内存占用空间 (返回的单位是byte)
start_mem = df.memory_usage().sum()
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_dtype = df[col].dtype
if col_dtype != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_dtype)[:3] == 'int':
for dtype in [np.int8, np.int16, np.int32, np.int64]:
if c_min > np.iinfo(dtype).min and c_max < np.iinfo(dtype).max:
df[col] = df[col].astype(dtype)
break
else:
for dtype in [np.float16, np.float32, np.float64]:
if c_min > np.finfo(dtype).min and c_max < np.finfo(dtype).max:
df[col] = df[col].astype(dtype)
break
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum()
print('Memory usage after optimization is: {:.2f}MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem)/start_mem))
return df
x_train = pd.read_csv('Dataset/data_for_model.csv')
x_train = reduce_mem_usage(x_train)
y_train = pd.read_csv('Dataset/label_for_model.csv')['isDefault'].astype(np.int8)
Memory usage of dataframe is 377449200.00 MB
Memory usage after optimization is: 92524170.00MB
Decreased by 75.5%
5.3 简单建模
使用Lightgbm进行建模
"""
对训练集数据进行划分,分成训练集和验证集,并进行相应的操作
"""
from sklearn.model_selection import train_test_split
import lightgbm as lgb
# 数据集划分
X_train_split, X_val, y_train_split, y_val = train_test_split(x_train, y_train, test_size=0.2)
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'learning_rate': 0.1,
'metric': 'auc',
'min_child_weight': 1e-3,
'num_leaves': 31,
'max_depth': -1,
'reg_lambda': 0,
'reg_alpha': 0,
'feature_fraction': 1,
'bagging_fraction': 1,
'bagging_freq': 0,
'seed': 2020,
'nthread': 8,
'silent': True,
'verbose': -1
}
"""
使用训练集数据进行模型训练
"""
model = lgb.train(params, train_set=train_matrix, valid_sets=valid_matrix,
num_boost_round=20000, verbose_eval=1000, early_stopping_rounds=200)
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[334] valid_0's auc: 0.729254
对验证集进行预测
from sklearn import metrics
from sklearn.metrics import roc_auc_score
"""
预测并计算roc的相关指标
"""
val_pre_lgb = model.predict(X_val, num_iteration=model.best_iteration)
fpr, tpr, threshold = metrics.roc_curve(y_val, val_pre_lgb)
roc_auc = metrics.auc(fpr, tpr)
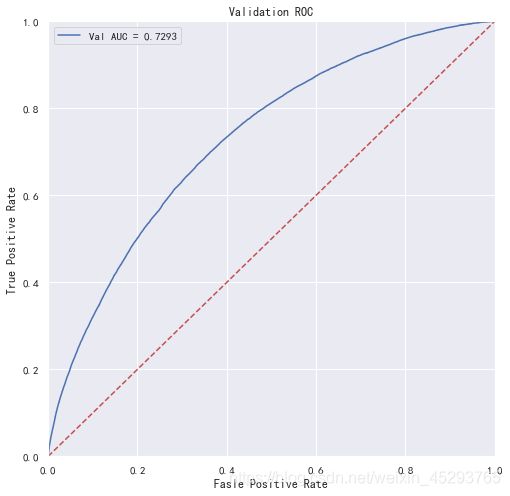
print('未调参前lightgbm单模型在验证集上的AUC:{}'.format(roc_auc))
"画出roc曲线图"
plt.figure(figsize=(8, 8))
plt.title('Validation ROC')
plt.plot(fpr, tpr, 'b', label='Val AUC = %.4f' % roc_auc)
plt.ylim(0, 1)
plt.xlim(0, 1)
plt.legend(loc='best')
# plt.title('ROC')
plt.ylabel('True Positive Rate')
plt.xlabel('Fasle Positive Rate')
"画出对角线"
plt.plot([0, 1], [0, 1], 'r--')
plt.show()
未调参前lightgbm单模型在验证集上的AUC:0.7292540914716458
进一步地,使用5折交叉验证进行模型性能评估
from sklearn.model_selection import KFold
# 5折交叉验证
folds = 5
seed = 2020
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'learning_rate': 0.1,
'metric': 'auc',
'min_child_weight': 1e-3,
'num_leaves': 31,
'max_depth': -1,
'reg_lambda': 0,
'reg_alpha': 0,
'feature_fraction': 1,
'bagging_fraction': 1,
'bagging_freq': 0,
'seed': seed,
'nthread': 8,
'silent': True,
'verbose': -1
}
cv_scores = []
for i,(train_index, valid_index) in enumerate(kf.split(x_train, y_train)):
print('*'*30, str(i+1), '*'*30)
X_train_split, y_train_split, X_val, y_val = (x_train.iloc[train_index],
y_train.iloc[train_index],
x_train.iloc[valid_index],
y_train.iloc[valid_index])
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
model = lgb.train(params, train_set=train_matrix, valid_sets=valid_matrix,
num_boost_round=20000, verbose_eval=1000, early_stopping_rounds=200)
val_pred = model.predict(X_val, num_iteration=model.best_iteration)
cv_scores.append(roc_auc_score(y_val, val_pred))
print(cv_scores)
print('lgb_scotrainre_list: ', cv_scores)
print('lgb_score_mean: ', np.mean(cv_scores))
print('lgb_score_std: ', np.std(cv_scores))
****************************** 1 ******************************
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[391] valid_0's auc: 0.729003
[0.7290028273076175]
****************************** 2 ******************************
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[271] valid_0's auc: 0.730727
[0.7290028273076175, 0.7307267609075013]
****************************** 3 ******************************
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[432] valid_0's auc: 0.731958
[0.7290028273076175, 0.7307267609075013, 0.731958201378707]
****************************** 4 ******************************
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[299] valid_0's auc: 0.727204
[0.7290028273076175, 0.7307267609075013, 0.731958201378707, 0.7272042210402802]
****************************** 5 ******************************
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[287] valid_0's auc: 0.732224
[0.7290028273076175, 0.7307267609075013, 0.731958201378707, 0.7272042210402802, 0.7322240919782057]
lgb_scotrainre_list: [0.7290028273076175, 0.7307267609075013, 0.731958201378707, 0.7272042210402802, 0.7322240919782057]
lgb_score_mean: 0.7302232205224624
lgb_score_std: 0.0018905510067472465
5.4 模型调参
5.4.1 贪心调参
先使用当前对模型影响最大的参数进行调优,达到当前参数下的模型最优化,再使用对模型影响次之的参数进行调优,如此下去,直到所有的参数调整完毕。
这个方法的缺点就是可能会调到局部最优而不是全局最优,但是只需要一步一步的进行参数最优化调试即可,容易理解。
需要注意的是在树模型中参数调整的顺序,也就是各个参数对模型的影响程度,这里列举一下日常调参过程中常用的参数和调参顺序:
①:max_depth(树模型深度)、num_leaves(叶子节点数,树模型复杂度)
②:min_data_in_leaf(一个叶子上最小数据量,可以用来处理过拟合)、min_child_weight(决定最小叶子节点样本权重和。当它的值较大时,可以避免模型学习到局部的特殊样本。但如果这个值过高,会导致欠拟合。)
③:bagging_fraction(不进行重采样的情况下随机选择部分数据)、 feature_fraction(每次迭代中随机选择特征的比例)、bagging_freq(bagging的次数)
④:reg_lambda(权重的L2正则化项)、reg_alpha(权重的L1正则化项)
⑤:min_split_gain(执行切分的最小增益)
objective 可选参数值详见:https://github.com/Microsoft/LightGBM/blob/master/docs/Parameters.rst#objective
from sklearn.model_selection import cross_val_score
best_obj = dict()
objective = ['regression', 'rgression_l1', 'binary', 'cross_entropy', 'cross_entropy_lambda']
for obj in objective:
model = lgb.LGBMRegressor(objective=obj)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_obj[obj] =score
best_leaves = dict()
num_leaves = range(10,80)
for leaves in num_leaves:
model = lgb.LGBMRegressor(objective=min(best_obj.items(), key=lambda x: x[1])[0],
num_leaves=leaves)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_leaves[leaves] = score
best_depth = dict()
max_depth = range(3, 10)
for depth in max_depth:
model = lgb.LGBMRegressor(objective=min(best_obj.items(), key=lambad x: x[1])[0],
num_leaves=min(best_leaves.items(), key=lambad x: x[1])[0],
max_depth=depth)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_depth[depth] = score
5.4.2 网格搜索
相比贪心调参效果更优。但是时间开销大,一旦数据量过大,就很难得出结果。
from sklearn.model_selection import GridSearchCV, StratifiedKFold
def get_best_cv_params(learning_rate=0.1, n_estimators=581,
num_leaves=31, max_depth=-1, bagging_fraction=1.0,
feature_fraction=1.0, bagging_req=0, min_data_in_leaf=20,
min_child_weight=0.001, min_split_gain=0, reg_lambda=0,
reg_alpha=0, param_grid=None):
cv_fold = StratifiedKFold(n_splits=5, random_state=0, shuffle=True)
model_lgb = lgb.LGBMClassifier(learning_rate=learning_rate,
n_estimators=n_estimators,
num_leaves=num_leaves,
max_depth=max_depth,
bagging_fraction=bagging_fraction,
feature_fraction=feature_fraction,
bagging_req=bagging_req,
min_data_in_leaf=min_data_in_leaf,
min_child_weight=min_child_weight,
min_split_gain=min_split_gain,
reg_lambda=reg_lambda,
reg_alpha=reg_alpha,
n_jobs=8
)
grid_searh = GridSearchCV(estimator=model_lgb,
cv=cv_fold,
param_grid=param_grid,
scoring='roc_auc'
)
grid_searh.fit(x_train, y_train)
print('模型当前最优参数为:', grid_searh.best_parmas_)
print('模型当前最优得分为:', grid_searh.best_score_)
"""以下代码未运行,耗时较长,请谨慎运行,且每一步的最优参数需要在下一步进行手动更新,请注意"""
"""
需要注意一下的是,除了获取上面的获取num_boost_round时候用的是原生的lightgbm(因为要用自带的cv)
下面配合GridSearchCV时必须使用sklearn接口的lightgbm。
"""
#设置n_estimators 为581,调整num_leaves和max_depth,这里选择先粗调再细调
lgb_params = {'num_leaves': range(10, 80, 5), 'max_depth': range(3, 10, 2)}
get_best_cv_params(learning_rate=0.1, n_estimators=581, num_leaves=None, max_depth=None,
min_data_in_leaf=20, min_child_weight=0.001, bagging_fraction=1.0,
feature_fraction=1.0, bagging_req=0, min_split_gain=0, reg_lambda=0,
reg_alpha=0, param_grid=lgb_params)
# num_leaves为30,max_depth为7,进一步细调num_leaves和max_depth
lgb_params = {'num_leaves': range(25, 35, 1), 'max_depth': range(5, 9, 1)}
get_best_cv_params(learning_rate=0.1, n_estimators=85, num_leaves=None, max_depth=None,
min_data_in_leaf=20, min_child_weight=0.001, bagging_fraction=1.0,
feature_fraction=1.0, bagging_req=1.0, min_split_gain=0,
reg_lambda=0, reg_lambda=0, reg_alpha=0, param_grid=lgb_params)
# 确定min_data_in_leaf为45,min_child_weight为0.001
# 再进行bagging_fraction、feature_fraction和bagging_freq的调参
lgb_params = {'reg_lambda': [i/10 for i in range(5, 10, 1)],
'reg_alpha': [i/10 for i in range(5, 10, 1)],
'bagging_freq': range(0, 81, 10)}
get_best_cv_params(learning_rate=0.1, n_estimators=85, num_leaves=29, max_depth=7,
min_data_in_leaf=45, min_child_weight=0.001, bagging_fraction=None,
feature_fraction=None, bagging_req=None, min_split_gain=0,
reg_lambda=0, reg_lambda=0, param_grid=lgb_params)
# 确定bagging_fraction为0.4、feature_fraction为0.6、bagging_freq为
# 再进行reg_lambda、reg_alpha的调参
lgb_params = {'reg_lambda': [0, 0.001, 0.01, 0.03, 0.08, 0.3, 0.5],
'reg_alpha': [0, 0.001, 0.01, 0.03, 0.08, 0.3, 0.5]}
get_best_cv_params(learning_rate=0.1, n_estimators=85, num_leaves=29, max_depth=7,
min_data_in_leaf=45, min_child_weight=0.001, bagging_fraction=0.9,
feature_fraction=0.9, bagging_req=40, min_split_gain=0,
reg_lambda=None, reg_lambda=None, param_grid=lgb_params)
# 确定reg_lambda、reg_alpha都为0
# 再进行min_split_gain的调参
lgb_params = {'min_split_gain': [i/10 for i in range(0, 11, 1)]}
get_best_cv_params(learning_rate=0.1, n_estimators=85, num_leaves=29, max_depth=7,
min_data_in_leaf=45, min_child_weight=0.001, bagging_fraction=0.9,
feature_fraction=0.9, bagging_req=40, min_split_gain=0,
reg_lambda=None, reg_lambda=None, param_grid=lgb_params)
"通过网格搜索确定最优参数"
final_parmas = {'boosting_type': 'gbdt',
'learning_rate': 0.01,
'num_leaves': 29,
'max_depth': 7,
'min_data_in_leaf': 45,
'min_child_weight': 0.001,
'bagging_fraction': 0.9,
'feature_fraction': 0.9,
'bagging_freq': 40,
'min_split_gain': 0,
'reg_lambda': 0,
'reg_alpha': 0,
'nthread': 6
}
cv_result = lgb.cv(train_set=lgb_train,
early_stopping_rounds=20,
num_boost_round=5000,
nfold=5,
stratified=True,
params=final_parmas,
metrics='auc',
seed=2020)
print('迭代次数: ', len(cv_result['auc-mean']))
print('交叉验证的AUC为:', max(cv_result['auc-mean']))
5.4.3 贝叶斯调参
贝叶斯调参的主要思想是:给定优化的目标函数(广义的函数,只需指定输入和输出即可,无需知道内部结构以及数学性质),通过不断地添加样本点来更新目标函数的后验分布(高斯过程,直到后验分布基本贴合于真实分布)。简单的说,就是考虑了上一次参数的信息,从而更好的调整当前的参数。
贝叶斯调参的步骤如下:
- 定义优化函数(rf_cv)
- 建立模型
- 定义待优化的参数
- 得到优化结果,并返回要优化的分数指标
# pip install bayesian-optimization
from sklearn.model_selection import cross_val_score
def rf_cv_lgb(num_leaves, max_depth, bagging_fraction, feature_fraction, bagging_freq,
min_data_in_leaf, min_child_weight, min_split_gain, reg_lambda, reg_alpha):
model_lgb = lgb.LGBMClassifier(boosting_type='gbdt', objective='binary', metric='auc',
learning_rate=0.1, n_estimators=5000, num_leaves=int(num_leaves),
max_depth=int(max_depth), bagging_fraction=round(bagging_fraction, 2),
feature_fraction=round(feature_fraction, 2), bagging_freq=int(bagging_freq),
min_data_in_leaf=int(min_data_in_leaf), min_child_weight=min_child_weight,
min_split_gain=min_split_gain, reg_lambda=reg_lambda, reg_alpha=reg_alpha,
n_jobs=8)
val = cross_val_score(model_lgb, X_train_split, y_train_split, cv=5, scoring='roc_auc').mean()
return val
from bayes_opt import BayesianOptimization
"定义需要优化的参数"
bayes_lgb = BayesianOptimization(rf_cv_lgb,
{
'num_leaves': (10, 200),
'max_depth': (3, 20),
'bagging_fraction': (0.5, 1.0),
'feature_fraction': (0.5, 1.0),
'bagging_freq': (0, 100),
'min_data_in_leaf': (10, 100),
'min_child_weight': (0, 10),
'min_split_gain': (0.0, 1.0),
'reg_alpha': (0.0, 10),
'reg_lambda': (0.0, 10)
}
)
"开始优化"
bayes_lgb.maximize(n_iter=10)
| iter | target | baggin... | baggin... | featur... | max_depth | min_ch... | min_da... | min_sp... | num_le... | reg_alpha | reg_la... |
-------------------------------------------------------------------------------------------------------------------------------------------------
| [0m 1 [0m | [0m 0.7253 [0m | [0m 0.5085 [0m | [0m 71.31 [0m | [0m 0.8524 [0m | [0m 8.124 [0m | [0m 2.889 [0m | [0m 26.92 [0m | [0m 0.5716 [0m | [0m 81.84 [0m | [0m 4.136 [0m | [0m 6.484 [0m |
| [0m 2 [0m | [0m 0.6968 [0m | [0m 0.7396 [0m | [0m 64.17 [0m | [0m 0.9414 [0m | [0m 10.52 [0m | [0m 8.3 [0m | [0m 35.48 [0m | [0m 0.02613 [0m | [0m 176.1 [0m | [0m 6.372 [0m | [0m 8.569 [0m |
| [0m 3 [0m | [0m 0.6973 [0m | [0m 0.579 [0m | [0m 19.27 [0m | [0m 0.5447 [0m | [0m 7.248 [0m | [0m 7.272 [0m | [0m 35.98 [0m | [0m 0.09783 [0m | [0m 118.7 [0m | [0m 5.358 [0m | [0m 8.89 [0m |
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
.....
KeyboardInterrupt:
因为调参时间实在是太久了。我就给先停止了。先试试3次调参后的效果怎么样。
'显示优化结果'
bayes_lgb.max
{'target': 0.7253010419224971,
'params': {'bagging_fraction': 0.5085047041852252,
'bagging_freq': 71.30936204845294,
'feature_fraction': 0.8523779866128889,
'max_depth': 8.123528975950922,
'min_child_weight': 2.8885434024723757,
'min_data_in_leaf': 26.916059861564715,
'min_split_gain': 0.5715502339115726,
'num_leaves': 81.83531877577995,
'reg_alpha': 4.135748365864206,
'reg_lambda': 6.484350951024385}}
参数优化完成后,可以根据优化后的参数建立新的模型,降低学习率并寻找最优模型迭代次数
"调整一个较小的学习率,并通过cv函数确定当前最优的迭代次数"
base_params_lgb ={'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'learning_rate': 0.01,
'nthread': 8,
'seed': 2020,
'silent': True,
'verbose': -1
}
for fea in bayes_lgb.max['params']:
if fea in ['num_leaves', 'max_depth', 'min_data_in_leaf', 'bagging_freq']:
base_params_lgb[fea] = int(bayes_lgb.max['params'][fea])
else:
base_params_lgb[fea] = round(bayes_lgb.max['params'][fea], 2)
cv_result_lgb = lgb.cv(train_set=train_matrix,
early_stopping_rounds=1000,
num_boost_round=20000,
nfold=5,
stratified=True,
shuffle=True,
params=base_params_lgb,
metrics='auc',
seed=2020
)
print('迭代次数:', len(cv_result_lgb['auc-mean']))
print('最终模型的AUC为:', max(cv_result_lgb['auc-mean']))
迭代次数: 2290
最终模型的AUC为: 0.7301432469182637
又跑了差不多一个小时。。。
5.5 建立最终模型
模型参数已确定,建立最终模型并对验证集进行验证
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(x_train, y_train)):
print('*'*30, str(i+1), '*'*30)
X_train_split, y_train_split, X_val, y_val = (x_train.iloc[train_index],
y_train.iloc[train_index],
x_train.iloc[valid_index],
y_train.iloc[valid_index])
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
params = base_params_lgb
# params.pop('verbose')
# verbose_eval 每迭代多少次输出一次评估结果
model = lgb.train(params, train_set=train_matrix, valid_sets=valid_matrix,
num_boost_round=2290, verbose_eval=1000, early_stopping_rounds=200)
val_pred = model.predict(X_val, num_iteration=model.best_iteration)
cv_scores.append(roc_auc_score(y_val, val_pred))
print(cv_scores)
print('lgb_scotrainre_list: ', cv_scores)
print('lgb_score_mean: ', np.mean(cv_scores))
print('lgb_score_std: ', np.std(cv_scores))
****************************** 1 ******************************
Training until validation scores don't improve for 200 rounds
[1000] valid_0's auc: 0.728198
[2000] valid_0's auc: 0.730141
Early stopping, best iteration is:
[1995] valid_0's auc: 0.730154
[0.730154013660886]
****************************** 2 ******************************
Training until validation scores don't improve for 200 rounds
[1000] valid_0's auc: 0.730745
Early stopping, best iteration is:
[1775] valid_0's auc: 0.732416
[0.730154013660886, 0.7324162622803124]
****************************** 3 ******************************
Training until validation scores don't improve for 200 rounds
[1000] valid_0's auc: 0.731586
[2000] valid_0's auc: 0.733759
Did not meet early stopping. Best iteration is:
[2210] valid_0's auc: 0.73389
[0.730154013660886, 0.7324162622803124, 0.7338895025847298]
****************************** 4 ******************************
Training until validation scores don't improve for 200 rounds
[1000] valid_0's auc: 0.727136
[2000] valid_0's auc: 0.72886
Early stopping, best iteration is:
[1982] valid_0's auc: 0.728902
[0.730154013660886, 0.7324162622803124, 0.7338895025847298, 0.7289019419414305]
****************************** 5 ******************************
Training until validation scores don't improve for 200 rounds
[1000] valid_0's auc: 0.731454
[2000] valid_0's auc: 0.733089
Did not meet early stopping. Best iteration is:
[2286] valid_0's auc: 0.733251
[0.730154013660886, 0.7324162622803124, 0.7338895025847298, 0.7289019419414305, 0.7332511170149825]
lgb_scotrainre_list: [0.730154013660886, 0.7324162622803124, 0.7338895025847298, 0.7289019419414305, 0.7332511170149825]
lgb_score_mean: 0.7317225674964682
lgb_score_std: 0.0018936511514676447
通过5折交叉验证,可以发现模型迭代到13000次后会停止,那么在建立新模型时,可以直接设置最大迭代次数为13000,并使用验证集进行模型预测。
X_train_split, X_val, y_train_split, y_val = train_test_split(x_train, y_train, test_size=0.2)
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
final_model_lgb = lgb.train(params, train_set=train_matrix, valid_sets=valid_matrix,
num_boost_round=13000, verbose_eval=1000, early_stopping_rounds=200)
Training until validation scores don't improve for 200 rounds
[1000] valid_0's auc: 0.731454
[2000] valid_0's auc: 0.733089
Early stopping, best iteration is:
[2303] valid_0's auc: 0.733253
val_pre_lgb = final_model_lgb.predict(X_val)
fpr, tpr, threshold = metrics.roc_curve(y_val, val_pre_lgb)
roc_auc = metrics.auc(fpr, tpr)
print('调参后lightgbm单mox模型在验证集上的AUC:', roc_auc)
plt.figure(figsize=(8, 8))
plt.title('Validation ROC')
plt.plot(fpr, tpr, 'b', label='Val AUC = %.4f' % roc_auc)
plt.ylim(0, 1)
plt.xlim(0, 1)
plt.legend(loc='best')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.plot([0, 1], [0, 1], 'r-')
plt.show()
调参后lightgbm单mox模型在验证集上的AUC: 0.7332527085057257
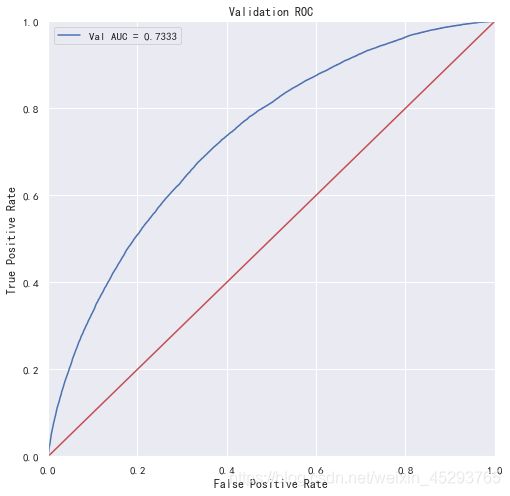
相比较原来未调整的参数,模型的性能有所提升。
"保存模型到本地"
import pickle
pickle.dump(final_model_lgb, open('Dataset/model_lgb_best.pkl', 'wb'))