听趣拍云产品经理剖析视频基础知识
https://mbd.baidu.com/newspage/data/landingsuper?context={"nid"%3A"news_3310310027998234129"}&n_type=1&p_from=3
【深度分解】听趣拍云产品经理剖析视频基础知识(1)
陈墨
百家号17-03-1714:08
花潍趣拍云产品经理
深度分解视频基础知识“视频技术发展到现在已经有100多年的历史,虽然比照相技术历史时间短,但在过去很长一段时间之内都是最重要的媒体。由于互联网在新世纪的崛起,使得传统的媒体技术有了更好的发展平台,应运而生了新的多媒体技术。而多媒体技术不仅涵盖了传统媒体的表达,又增加了交互互动功能,成为了目前最主要的信息工具。在多媒体技术中,最先获得发展的是图片信息技术,由于信息来源更加广泛,生成速度高生产效率高,加上应用门槛较低,因此一度是互联网上最有吸引力的内容。然而随着技术的不断进步,视频技术的制作加工门槛逐渐降低,信息资源的不断增长,同时由于视频信息内容更加丰富完整的先天优势,在近年来已经逐渐成为主流。那么接下来我就对视频信息技术做一个详细的介绍。今天我们首先讲的是模拟时代和数字化时代的视频技术。”
模拟时代的视频技术最早的视频技术来源于电影,电影技术则来源于照相技术。由于现代互联网视频信息技术原理则来源于电视技术,所以这里只做电视技术的介绍。世界上第一台电视诞生于1925年,是由英国人约翰贝德发明。同时也是世界上第一套电视拍摄、信号发射和接收系统。而电视技术的原理大概可以理解为信号采集、信号传输、图像还原三个阶段。摄像信号的采集,通过感光器件获取到光线的强度(早期的电视是黑白的,所以只取亮度信号)。然后每隔30~40毫秒,将所采集到光线的强度信息发送到接收端。而对于信号的还原,也是同步的每隔30~40毫秒,将信号扫描到荧光屏上进行展示。那么对于信号的还原,由于荧光屏电视采用的是射线枪将射线打到荧光图层,来激发荧光显示,那么射线枪绘制整幅图像就需要一段时间。射线枪从屏幕顶端开始一行一行的发出射线,一直到屏幕底端。然后继续从顶部开始一行一行的发射,来显示下一幅图像。但是射线枪扫描速度没有那么快,所以每次图像显示,要么只扫单数行,要么只扫双数行。然后两幅图像叠加,就是完整的一帧画面。所以电视在早期都是隔行扫描。
那么信号是怎么产生的呢?跟相机感光原理一样,感光器件是对光敏感的设备,对于进光的强弱可以产生不同的电压。然后再将这些信号转换成不同的电流发射到接收端。电视机的扫描枪以不同的电流强度发射到荧光屏上时,荧光粉接收到的射线越强,就会越亮,越弱就会越暗。这样就产生了黑白信号。那么帧和场的概念是什么?前面说到,由于摄像采集信号属于连续拍摄图像,比如每隔40毫秒截取一张图像,也就是说每秒会产生25副图像。而每个图像就是一帧画面,所以每秒25副图像就可以描述为帧率为25FPS(frames per second)。而由于过去电视荧光屏扫描是隔行扫描,每两次扫描才产生一副图像,而每次扫描就叫做1场。也就是说每2场扫描生成1帧画面。所以帧率25FPS时,隔行扫描就是50场每秒。模拟时代在全世界电视信号标准并不是统一的,电视场的标准有很多,叫做电视信号制式标准。黑白电视的时期制式标准非常多,有A、B、C、D、E、G、H、I、K、K1、L、M、N等,共计13种(我国采用的是D和K制)。到了彩色电视时代,制式简化成了三种:NTSC、PAL、SECAM,其中NTSC又分为NTSC4.43和NTSC3.58。我国彩色电视采用的是PAL制式中的D制调幅模式,所以也叫PAL-D制式。有兴趣的可以百度百科“电视制式”来详细了解。另外你可能会发现,场的频率其实是和交流电的频率一致的。比如我国的电网交流电的频率是50Hz,而电视制式PAL-D是50场每秒,也是50Hz。这之间是否有关联呢?可以告诉你的是,的确有关联,不过建议大家自己去研究。彩色信号又是怎么产生的呢?其实有了基础的黑白摄像技术之后,人们就一直想实现彩色摄像。早在1861年,英国物理学家麦克斯韦就论证了所有彩色都可以使用红、蓝、绿三种基色来叠加生成。但是感光器件只是对光线敏感,但是对颜色却无法识别。为了实现对颜色的识别,人们用分光镜加滤光片的方式,将光线分解成为三种基色的纯色模式。然后分别对三个基色的纯色亮度进行采集,然后再把信号叠加实现了对彩色信号的采集能力。

色彩信号是如何表达的?因为原来黑白电视的时候,基本上只需要一路信号就可以还原图像(同步信号后面讲)。但是有了彩色之后,一路信号能否表达一副完整的彩色图像,以及如何表达呢?彩色电视出现之后,为了兼容早期的黑白电视信号(也就是黑白电视机可以接收彩色信号,但是只显示黑白),科学家引入了YUV色彩表示法。YUV信号有多种叫法,可以称作色差信号(Y,R-Y,B-Y),也可以称作分量信号(YCbCr,或者Component、YPbPr)。它是由一个亮度信号Y (Luminance或Luma),和两个色度信号U和V组成(Chrominance或Chroma)。黑白电视只使用亮度信号Y,彩色电视可以额外使用两个色度信号,来实现彩色效果。但是YUV信号是怎么来的呢?首先,是因为考虑到黑白电视兼容,所以基础信号仍然采用亮度信号。而颜色表达本身是通过RGB三基色的叠加来实现的,为了能够将YUV信号可以还原成三基色RGB色彩值,数学家利用了色差算法,即选取一路Cr信号和一路Cb信号。Cr信号是指RGB的红色信号部分与RGB亮度值之间的差异,Cb信号是指RGB的蓝色信号与RGB亮度值之间的差异。所以YUV信号有时候也表达为Y,R-Y和B-Y,所以也叫色差信号。为什么YUV色彩会延续至今?如果大家平时经常拿手机拍摄视频,你可以把拍摄的视频文件传输到电脑上,然后用MediaInfo软件打开,你会发现很多关于视频的参数信息。而这些参数信息里面,你一定会发现手机拍摄的视频色彩也是使用YUV信号模式。为什么不用RGB来表达?现在早都没有黑白电视了啊?其实不必考虑兼容性的原因,因为你无论是什么信号模式拍摄的视频,只要是数字化的信息文件形式,都可以与播放设备的信号模式无关。因为播放设备在播放视频文件时需要解码,再进行渲染。这时候不管什么信号模式还是色彩空间,都能转化成设备兼容的方式。至于为什么YUV信号模式一直会持续至今,最主要的原因不是因为兼容性考虑,而是YUV信号有个巨大的优势,就是节省带宽。这在数字媒体领域是很重要的。人眼的视觉特点是,人眼对于亮度信号最为敏感,对色度信号敏感度要弱一些。所以可以适当减少色度信号的容量,也不会被人眼观察到差异。就好比音频里面的MP3压缩格式,是将耳朵不敏感的频率信号容量降低或去除掉,以大大降低文件的大小,但是人耳却基本听不到差异。至于YUV信号是如何做到降低信息容量的,可以看下面的引文:YUV主要的采样格式有YCbCr 4:2:0、YCbCr 4:2:2、YCbCr 4:1:1和 YCbCr 4:4:4。其中YCbCr 4:1:1 比较常用,其含义为:每个点保存一个 8bit 的亮度值(也就是Y值),每 2x2 个点保存一个 Cr 和Cb 值,图像在肉眼中的感觉不会起太大的变化。所以, 原来用 RGB(R,G,B 都是 8bit unsigned) 模型, 1个点需要 8x3=24 bits(如下图第一个图),(全采样后,YUV仍各占8bit)。按4:1:1采样后,而现在平均仅需要 8+(8/4)+(8/4)=12bits(4个点,8*4(Y)+8(U)+8(V)=48bits), 平均每个点占12bits。这样就把图像的数据压缩了一半。以上内容引自百度百科“YUV”条目。限于篇幅原因,对于YUV的各种采样模式不再祥加描述,大家可以参考百度百科中的详细解释。
数字化时代的视频技术视频技术发展到了数字化时代,其实原理上并没有太多变化。这也就是为什么前面要提到模拟时代视频技术的知识的原因。但是数字化的视频技术,虽然基础原理没有改变,但是各方面的性能和功能有了很大的提升。这些就重点讲一下数字化之后的视频技术有了哪些突破:
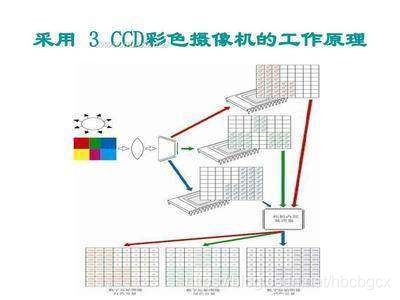
彩色摄像的演进前面讲到,实现彩色摄像其实是把光线分解成为三个基色分别取亮度值,但是这种结构比较复杂,成本也高。因为实现彩色摄像需要有一个分光用的棱镜,然后采集光线必须要用到三片感光器件(CCD或CMOS)。这种结构带来第二个不好的地方就是结构会比较庞大,不利于小型化微型化。后来呢,德国人拜耳发明了一种滤镜,是一种马赛克滤镜。将含三基色的马赛克滤镜覆盖在感光器件上面,这样就可以实现用一片感光器件来采集三种颜色,同时也取消了分光棱镜这种结构。这样下来,不仅成本降低了,结构也简化了。
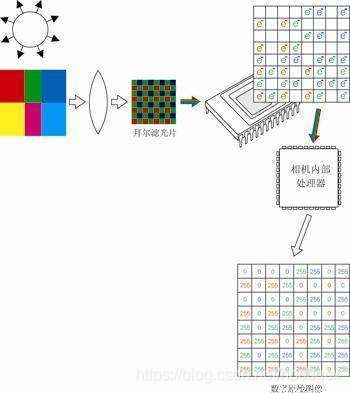
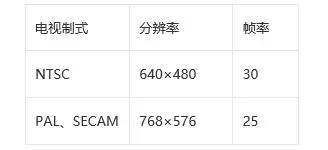
有了这种技术之后,摄像设备就可以越做越小,现在集成在手机上的摄像头整体厚度只有2~3毫米,尺寸只有1~3毫米。当然在专业领域,高端的摄像机仍然采用分光棱镜加3CCD的技术,原因不是他们不愿意改,而是3CCD的色彩丰度更好。而且专业摄像机CCD技术也从IT型发展到了FIT型,感兴趣的同学可以查看一下SONY公司关于FIT型CCD专业摄像机的介绍来了解。总而言之,就是民用领域和专业领域发展方向不一样,所以路线也不同。场概念消失在模拟电视时代,受限于显像管技术原因,采用的是隔行扫描技术来还原图像显示。但是现在都是平板电视了(液晶电视、等离子电视、激光电视),电视的成像方式不再是一条线一条线的扫描,而是一次性全画面呈现。所以现在的视频拍摄一般都没有场的概念,当然为了向前兼容,在视频文件信息中,你会看到扫描模式的参数。利用手机拍摄的视频文件,其扫描模式的参数都是Progressive,就是逐行扫描的意思。采样率和采样精度大家都知道模拟和数字的最大差别就是信息存储和传递方式,一个是模拟量一个是数字量化的。那么数字化对于连续过程的量化就必须用到采样过程,也可以理解为片段化。例如音频数字化,就是把音频在每个很小的时间间隔上获取音频的信息然后进行数字量化,最后把所有连续采样的数字量化数据组合,来形成最终的信息。视频也是这样,按照一定的时间间隔,把获取到的图像进行数字量化,然后连续的数字量化的集合就是一段完整的视频文件。但是视频的采样率并非是大家理解的那样,每秒钟产生25帧的图像,采样率就是25Hz。实际上,ITU(International Telecommunications Union,国际电信联盟)在CCIR 601标准中,对于视频的采样标准有了明确的界定:一、采样频率:为了保证信号的同步,采样频率必须是电视信号行频的倍数。CCIR为NTSC、PAL和SECAM制式制定的共同的电视图像采样标准:f s=13.5MHz这个采样频率正好是PAL、SECAM制行频的864倍,NTSC制行频的858倍,可以保证采样时采样时钟与行同步信号同步。对于4:2:2的采样格式,亮度信号用fs频率采样,两个色差信号分别用f s/2=6.75MHz的频率采样。由此可推出色度分量的最小采样率是3.375MHz。二、分辨率:根据采样频率,可算出对于PAL和SECAM制式,每一扫描行采样864个样本点;对于NTSC制则是858个样本点。由于电视信号中每一行都包括一定的同步信号和回扫信号,故有效的图像信号样本点并没有那么多,CCIR 601规定对所有的制式,其每一行的有效样本点数为720点。由于不同的制式其每帧的有效行数不同(PAL和SECAM制为576行,NTSC制为484行),CCIR 定义720×484为高清晰度电视HDTV(High Definition TV)的基本标准。实际计算机显示数字视频时,通常采用下表的参数:
三、数据量:CCIR 601规定,每个样本点都按8位数字化,也即有256个等级。但实际上亮度信号占220级,色度信号占225级,其它位作同步、编码等控制用。如果按f s 的采样率、4:2:2的格式采样,则数字视频的数据量为:
13.5(MHz)×8(bit)+2×6.75(MHz)×8(bit) = 27Mbyte / s同样可以算出,如果按4:4:4的方式采样,数字视频的数据量为每秒40兆字节!按每秒27兆字节的数据率计算,一段10秒钟的数字视频要占用270兆字节的存储空间。按此数据率,一张680兆字节容量的光盘只能记录约25秒的数字视频数据信息,而且即使当前高倍速的光驱,其数据传输率也远远达不到每秒27兆字节的传输要求,视频数据将无法实时回放。这种未压缩的数字视频数据量对于当前的计算机和网络来说无论是存储或传输都是不现实的,因此,在多媒体中应用数字视频的关键问题是数字视频的压缩技术。由上述引文可知,YUV的采样率和采样精度,是数字视频从模拟向数字化过渡中兼容性的解决方案。延续了模拟视频以行为单位扫描的机制(模拟视频没有分辨率概念,只有行的概念)。由于这套标准是面向数字电视广播系统制定的统一标准,一般只在广播电视领域中才会看到,而在其他的数字化视频体系中基本没有体现。比如你在视频文件信息中找不到关于采样率的参数。视频分辨率视频分辨率也是数字化视频时代的主要特征,由于模拟视频采用线扫描机制,也就是按行显示图像,而每一行的视频线中并没有进行数字量化,所以模拟视频都是以多少行来界定的。比如PAL制式采用576行,NTSC制式采用480行。到了数字化时代,为了量化视频的具体信息,就必须对每行的信息进行采样并量化,就形成了分辨率的概念。如果采用PAL制式的视频,每行量化的图像点为768个,那么分辨率就是768×576。也就是说把PAL制的视频图像可以分解为768×576个像素点组成。虽然简单的看视频分辨率的概念挺简单的,但实际上并没有那么简单。原因就是数字化视频的应用领域非常的多,从最早的广播电视应用,到监控安防,到互联网应用,后来又到了高清数字电视,以及移动互联网等等。而因为涉及的行业很多,每个行业都会制定自己的标准,所以就形成了对视频图像分辨率的定义有了很多标准。我们就拿最常见的广播电视、监控安防为例:大家在计算机领域也都有接触过分辨率的概念,比如VGA(640×480)、SVGA(800×600)、XGA(1024×768)、SXGA(1280×1024)、SXGA+(1400×1050)、UXGA(1600×1200)、WXGA(1280×800)、WXGA+(1280×854/1440×900)、WSXGA(1600×1024)、WSXGA+(1680×1050)、WUXGA(1920×1200)等等。现在最高的标准是WQUXGA(3840×2400)。这个标准最早是由IBM制定的模拟信号的电脑显示标准,后来被各厂家继续沿用和升级。再后来被VESA标准化组织统一制定。但是为什么分辨率就不能是简单的数字,非要在前面弄一堆字母呢?这一堆字母绝对能把一大群人搞晕掉。原因在于制定一个输出的分辨率,并不是简单的设置有多少个像素点,而是还要考虑到实现这个像素点成像的方法。包括色阶多少、带宽多大、扫描方式怎样,如果深入的讲还有电路形式、增益控制、时序方式、寻址方式等等。如果没有详细制定这些图像是如何生成的,那么各个厂家之间的产品可能很难兼容,也就不会见到今天如此发达的计算机市场了。同样的道理,制定标准化的分辨率和实现方式,有助于行业的统一和兼容。监控安防领域有什么分辨率标准呢?下面请看:

这里解释一下,CIF是 Common Intermediate Format 的缩写,即通用影像传输视频会议(video conference)中常使用的影像传输格式,是ITU H.261协议中的一部分。大家可能发现了,每个分辨率的色度取样个数和行数都是对应分辨率的一半。没错,因为这个标准因为考虑到摄像头的性能和传输的性能影响,采取的是间隔像素采样和隔行扫描机制,而间隔像素采样通过插值进行补齐。
不过这些参数貌似现在很难见到了,为什么呢?很简单,因为监控安防现在都是高清化了,都是D2、D3这种级别的,对应分辨率是720P和1080P这一类。那么在广播电视领域,对于分辨率的定义又是怎样呢?前面已经提到了关于PAL制和NTSC制式的视频分辨率标准,另外还有一个SECAM制式,SECAM的分辨率为720×576。那么你会发现SECAM制式和PAL制的行数是一样的,只有每行的分辨率不同。这是由于SECAM调制载波方式不同造成的。在标清电视时代,对于分辨率方面理解与现在其实有所不同。比如SECAM制式每帧图像是625行,但是分辨率是720×576,也就是只有576行。是因为视频信号传输过程中分帧正程和帧逆程,而帧逆程就是回扫,反向回去。在视频信号正常显示时,需要消除行帧逆程扫描对画面的干扰,所以就变成了576行。到了高清时代,数字电视推出了HDTV标准,它对于显示分辨率的定义为1280×720逐行扫描,也就是俗称的720P;1920×1080隔行扫描,也就是俗称的1080i;1920×1080逐行扫描,也就是所谓的1080P。当然高清数字电视已经逐渐普及了,目前正在面向4K高清过渡,也就是所谓的UHDTV(Ultra High Definition Television,超高清数字电视)。UHDTV草案定义了两个分辨率标准,及4K(3840×2160)和8K(7680×4320),支持50Hz、60Hz、和59.94Hz三种帧率,只采用逐行扫描。UHDTV采用正交采样,像素纵横比(PAR)为1:1,显示纵横比(DAR)为16:9。关于像素纵横比和显示纵横比的概念,相对比较简单,这里就不做解释了。关于信号同步信号同步是在广播电视领域中非常重要的技术,因为它如果出现问题,你的电视画面一定是没法看的,比如下面这种情况:

产生这种画面的原因,在于信号没有同步。导致行扫描时,没有在指定的位置。要想图像内容在正确的位置显示,就必须提供同步信号来进行约束。而不管是模拟电视时代,还是在数字电视时代,不管是电视机还是显示器都需要信号同步。同步信号一般有两种,分别为场同步(VSYNC)和行同步(HSYNC)。不论是什么类型的信号接口,都包含有一个或两个同步信号。
VGA信号线的引脚定义

另外一种形式的VGA接口,也叫RGBHV接口
DVI接口引脚定义

专业设备中的专用视频同步接口
虽然有很多设备如电视机的复合信号输入(Composite)、HDMI输入,显示器的DisplayPort输入,专业设备的SDI和HD SDI输入,都没有专门的视频场同步和行同步信号接口,但并不是说这些信号不需要同步。而是这些信号接口把场同步和行同步信号已经调制到了信号中。也就是说我们平时见到的视频信号接口中,并非只有纯粹的视频信息,还包含了很多的信息,比如同步信号、时钟信号(TC,TimeCode)、CEC控制信号、HDCP版权保护信息、SerialClock设备与分辨率识别信息等。未完待续
【深度分解】听趣拍云产品经理剖析视频基础知识(2)
陈墨
百家号17-03-2014:30
花潍趣拍云产品经理
深度分解视频基础知识
“随着技术的不断进步,视频技术的制作加工门槛逐渐降低,信息资源的不断增长,同时由于视频信息内容更加丰富完整的先天优势,在近年来已经逐渐成为主流。在基础知识(1)里面已经讲了模拟时代和数字化时代的视频技术。接下来将对视频编码与压缩、画面压缩、运动压缩、互联网视频应用的到来做一个详细的介绍。”
视频编码与压缩视频编码与压缩,是数字化视频非常重要的技术,以至于它直接影响到视频在各个领域的应用。如果没有视频编码技术的不断提高,我们今天也不可能在方方面面享受到视频的便利性。
首先,视频编码是一项非常复杂的工程,远超过对音频和图像压缩的难度。其次,视频编码是一个多级压缩的过程,而非单一压缩方案。当然如果不是有着这么复杂的一项工程,视频文件远比我们想象的要大的多。我们来举一个例子:
按照CCIR 601的视频信号采集标准,一个标准PAL制式电视信号转换成数字信号,按照常见的非专业级采样标准4:2:0(你想支持更高的也不行啊,民用级的设备做不到更高的采样率),则每秒钟产生的视频内容所生成的数字文件为21MB。那么1分钟的视频文件有多大呢?1260MB那么大。
那么,如果按照RGB色彩表达方式,720×576分辨率,每个采样点3个基色,每个基色是8bit数据,每秒25帧画面。经过简单的计算,我们很容易得出结果是720×576×3×8×25=237.3Mbit=29.67MByte。那么1分钟的视频就是1780MB。我想从没有用户见到过1分钟的视频会生成这么大的文件吧。这还仅仅是标清,如果是高清1080P的话,那就是69.5TB!
从上面的例子可以看出,即便是不压缩视频,采用YUV颜色来存储信息,比起使用RGB颜色来存储信息,容量还是要小一些的。所以也可以说YUV颜色方式算是视频编码的最初一级压缩方法。
这里面需要穿插一个话题,关于色阶。
色阶的意思,就是颜色从无到最大时,中间的过渡梯级有多少。假如说亮度的黑白信号,色阶为2时,那么它就只有两种颜色,全白和全黑。那如果变为256级是(比较常见的色阶标准),结果就是下面这样:

同样的RGB三基色中,每种颜色都有色阶。8bit数据能够存储256个色阶,那么RGB三基色就可以实现1677万种颜色,也就是24位色。
注:计算机颜色体系中有32位色,实际上是24位色之外增加了一个8位的Alpha透明层,所以也叫RGBA。
那能不能使用更高的色阶呢?大于256级色阶好不好?当然好了,不过一般的显示器不支持。但是的确是有高色阶的显示器,目前色阶最高的显示器可以支持10bit颜色信息,也就是1024级色阶。当然价格是不可想象的!

EIZO GX540医学显示器,1024级色阶黑白显示器价格不明,但不会少于10万元

SONY BVM-X300主控监视器,OLED显示10bit彩色可以显示10亿种颜色价格嘛,我记得大概是36万多吧
还有得告诉大家一个不好的消息,一般民用的低端显示器采用的TN型液晶面板,都是6bit的,也就是RGB每种颜色只有64级,一共可以显示颜色只有26万种。当然你可以选择32位色模式,只不过它的1677万种颜色,是通过插值换算出来的,并不是真正的1677万种颜色。真正支持1677万种颜色的显示器,其实也不是很便宜的。
画面压缩如果每一帧的视频画面,按照RGB颜色保存的话,文件会非常大。例如PAL制视频画面所产生的文件有1.2MB。
如果将每帧的视频画面压缩,那么可能大大减小视频的文件大小。而我们所知的最常见图像压缩算法就是jpeg。JPEG 是Joint Photographic Experts Group(联合图像专家小组)的缩写,是第一个国际图像压缩标准。
首先JPEG压缩是对图像的YUV色彩分量进行分别编码,所用的编码主要算法是DCT(DCT for Discrete Cosine Transform,离散余弦变换)。它是与傅里叶变换相关的一种变换,它类似于离散傅里叶变换(DFT for Discrete Fourier Transform),但是只使用实数。DCT是一种非常高压缩率低失真的压缩算法,可以将图像压缩至1/5到1/10大小,而且画质基本没有太大变化。
那么利用JPEG压缩算法,原本每帧图像大小为1.2MB,现在就变成了180KB左右,减小了很多。而每秒钟的视频大小就变成了4.4MB,1分钟的视频就是263MB。顿时小了很多。使用这种算法的视频编码方式叫做Motion JPEG,也叫MJPEG。注意,视频压缩里面也有个比较知名的方法叫做MPEG,但不等同于MJPEG,两者截然不同。
运动压缩虽然通过JPEG算法,可以将视频变小了好几倍,但是还是比较大。对于传输来说和存储来说,门槛还是太高了,只能适合像广播电视行业这种专业机构使用。
那么还有什么办法可以把视频文件压缩的更小呢?那就是帧间压缩方法。
说到帧间压缩,那必须提到一个组织,MPEG(Moving Picture Experts Group,动态图像专家组)是ISO(International Standardization Organization,国际标准化组织)与IEC(International Electrotechnical Commission,国际电工委员会)于1988年成立的专门针对运动图像和语音压缩制定国际标准的组织。
现在知道了吧,MPEG其实是一个组织的名字。当然这个组织有很多有代表性的压缩算法,都是以MPEG-X命名的。所以大家也就习惯的把MPEG称作压缩方法。
首先,运动压缩采用的是帧间压缩法。而什么是帧间压缩法呢?
由于视频是由很多帧的画面集合组成,而鉴于运动的特性,在很短的间隔时间内运动幅度很小。另外就是运动的画面中,存在很多并没有运动的画面信息。甚至有时候拍摄的画面有很多帧图像之间几乎没有变化。这样重复的记录这些没有变化的图像信息,简直是太浪费了。
帧间压缩,就是尽可能的剔除那些相邻画面中没有变化的内容信息。举个例子,比如画面是一个人骑自行车,背景不变,而骑自行车的人从画面一端跑到另外一端。那么这个时候,就可以把没有遮盖到的背景部分,只保存一份就行了。剩下的只是记录人骑自行车的整个动态画面就OK。
当时原理上比较简单,实现起来就比较困难了。帧间压缩的时候首先要用到关键帧和非关键帧的概念。关键帧就是指你要保存画面上所有数据的那一帧图像,并且以这个图像作为参考。关键帧后面每一帧都会比照关键帧和此前一帧的画面,记录画面改变的地方,去掉重复的信息。
早期的压缩算法就是采取这种策略,比如MPEG-1。它的应用产品大家可能更熟悉——VCD。
这里顺便提一下MP3,MP3的全名叫做MPEG-1 layer3。也就是说MP3压缩格式是MPEG-1压缩标准里面的一个子集。跟MP4是完全不同的概念。
VCD虽然在一张光盘里(650MB容量)可以放得下差不多一部电影的长度,已经是压缩率很惊人了。当然这也是牺牲画面为前提的:
VCD的分辨率很低,只有352×288(对应PAL制),比标准的电视画面的清晰度小很多。
VCD在运动不太明显的情况下画质还可以接受,如果是运动很快的画面中,就会出现很多惨不忍睹的马赛克。
有了VCD产品,国人们是皆大欢喜。这里可以顺带讲一下,VCD机是中国人发明的,那家公司叫万燕。但是呢,VCD技术是飞利浦、SONY、松下、JVC等公司联合制定的标准,而生产VCD芯片的公司是美国的C-CUBE公司。怎么说呢,技术虽然是老外们发明的,不过他们并不看重这项技术,所以就没形成产品。反倒是国人把它发扬光大了。
与此同时,欧美国家其实对VCD是不太感冒的。因为他们还在VHS时代(感兴趣的同学可以搜索一下VHS,以及SONY的betacam与JVC的VHS制式标准大战),而且VCD第一不便宜,第二画质也不高,第三还不能录像只能播放。其实有了VCD产品之后,对世界还是很震惊的。大家都觉得把一部电影放在一张小小的碟片里面真的很方便。但是VCD画质真的不好,有没有什么新的技术可以做到更小的容量更高的清晰度呢?那就是后来推出的MPEG-2。
MPEG-2这个标准是最早风靡全球的压缩技术,标准制定的时间是1994年(VCD标准是1993年)。虽然已经过去20多年了,却仍然是当今最重要的视频压缩格式之一。除了还有大量的DVD产品以外,更重要的是目前广播电视领域的数字电视DVB-T标准,仍然使用的是MPEG-2压缩标准(在中国)。
MPEG-2相对于MPEG-1有什么提升呢?
- 画面有了很大的提升,且更加灵活了。MPEG-1几乎所有的应用都集中在VCD上,分辨率很小,且不能改变。MPEG-2可以适合中等清晰度(D1标准、PAL制或者NTSC等制式电视标准)到高清晰度视频内容的展示。也就是说即便是720P、1080P等这样的高分辨率视频,MPEG-2仍然适用。
2.增加了GOP模式,使用IBP帧结构。原来的帧间压缩方式,在大动态场景下马赛克很严重。到了MPEG-2之后就有了很大的提升,因为使用了参考帧B帧,使用了向前预测帧方式,而且压缩率是可变的。总的来说,就是大动态时候不会有马赛克了。
- 增加了很多额外的信息,功能更加强大。比如支持更强的交互与命令控制(大家有没有想起来VCD 2.0时候画面有菜单可以选,DVD比这个强大),支持传输流形式(TS,TransportStream,就是可以用于直播,也不怕文件损坏就全完),多音轨而且多声道。
但是MPEG-2也有不足的,主要就是它是面向工业化视频信息生产发行领域的,也就是说只适合电视台、DVD发行商、卫星通信等领域,不适合民用。因为码流真的很大,比MPEG-1要大。虽然一张光盘就可以装的下一整部电影,那是因为光盘的容量从650MB提升到了4.3GB,甚至7.2GB。
互联网视频应用的到来早期的宽带速度只有1~2Mbps(56K modem和ISDN时代根本就没视频什么事),想要在线播放DVD影片是不可能的(至少5~10Mbps),VCD也不行而且技术上不支持。MPEG组织的科学家就开始研究能够适合在网络上播放的视频压缩方法,也就是后面推出的MPEG-4压缩格式。
MPEG-4很明显的特征就是适合在网络上播放,灵活度更高,功能更加强大:
压缩比更高更灵活。MPEG-1压缩比为20~30倍,MPEG-2压缩比为10~20倍,MPEG-4压缩比从几十到一百多倍不等;
对于画面内容可以使用不同的压缩比率,可以对非重要对象使用高压缩比,对重要对象使用低压缩比。这样可以在保证主要画质情况下压缩比更高;
不同对象可以使用不同编码算法,进一步提升压缩效率;
音视频搭配更灵活;
交互性更强,尤其适合互联网这种模式。
MPEG-4后来产生了很多衍生压缩算法,比较著名的就是Xvid和Dvix了。其实MPEG-4的知名度不如Xvid和Dvix,因为在那个时期,MPEG-4为了适应互联网较低的带宽速度,大部分应用都是一些低分辨率低码流的视频。而Xvid和Dvix虽然源自MPEG-4体系,但是面向视频文件存档进行了优化,可以比DVD小3~4倍的大小,存储与DVD画质非常接近的视频内容。受到了用户的极大喜爱,以至于在那个时期已经成为盗版影片的必选格式。

RealMedia——曾经的王者曾经互联网视频最大的赢家是Real Network,也是它最早实现了基于互联网的流媒体视频(在线观看)。想当年还在56K Modem窄带时期,Real Network公司就已经提供了视频在线观看功能。笔者曾经在那个还在PSTN上进行拨号的时代,体验过通过realplayer观看NBA的直播。如果以现在的标准来衡量那个时期的产品,那就是延时巨大(经常要loading几分钟)、画质惨不忍睹(分辨率超低,马赛克严重)、经常性的卡顿。
但是随着宽带的逐渐普及,RealMedia的巨大优势得以施展。在那个时期,RealMedia是当之无愧的王者。

首先,RealMedia压缩标准并非是MPEG-4衍生的版本,而是一个私有的压缩标准。这个标准由Real Network公司创立,且独有。RealMedia拥有极大的压缩比,远超MPEG家族。比如说一部标准DVD格式的电影,大约4.3GB容量,如果采用Dvix压缩的话,大概能压缩到700MB,而使用RM格式压缩,连700MB的一半都不到。即便是到了后期的RMVB压缩格式,也基本不会超500MB。
第二,Real Network公司在当时提供了世界上最完善的流媒体系统方案,只不过是收费的。那个时候的竞争对手只有微软的Windows Media Encoder,免费但是功能不完善。而RealMedia Encoder提供了VOD模式和LIVE模式完整的流媒体解决方案,虽然比较贵(印象中大概1万多美金)。

对于商业化应用的企业而言,要想做直播和点播业务,自然RealMedia Encoder服务会更加靠谱。虽然是收费的,但是系统稳定、可靠性强、又有服务支持(Windows Media Encoder只能在MSDN社区寻求帮助,没有技术支持)。所以说那个时期Real公司已经处于垄断地位了。
不过在那个时期,Real公司面临最大的问题是盗版。因为RealMedia的播放器虽然是免费的,但是编码器、解码器、流媒体服务器等等都是收费的。随着real格式日渐盛行,盗版就变得非常猖獗。当然Real公司没有微软那么财大气粗,所以自然要到处封杀。这只能说是在21世纪初期的互联网现状,如果要是放到现在,像Real这种公司风投还不挤破大门?公司的估值少说也得几百亿美金吧。
可惜的是,由于封闭而且收费,加上到处封杀,给了竞争对手很多机会。然后就有了Flash流媒体的崛起。
RealMedia能强大到什么程度呢?在21世纪初一直到2010年之前的差不多十年间,real格式一度成为了互联网视频格式的几乎唯一选择。那时候几乎所有盗版的电影和视频文件,全都是基于RM和RMVB格式的。21世纪以前呢?那是avi的天下,科科。
RealMedia的视频压缩主要分为两个阶段,第一阶段就是RM格式,第二阶段是RMVB。由于RM格式虽然压缩率出奇的高,但带来的问题就是画质很差,马赛克严重。随着宽带逐渐普及,人们对画质的要求逐渐提高,加上竞争对手的压力(Dvix和Xvid),RM升级到了RMVB。多出来“VB”这两个字幕,其实指的就是“Variable Bitrate”动态码率或者叫可变码率。关于码率的解释我们在文章最后来做。

RM升级到RMVB之后,一直被诟病的画质问题得到了提升,同时也可以支持较高的清晰度(最大到720P)。但是RMVB推出的时间已经晚于竞争对手,加上商业化的原因,以及更新速度越来越慢。最终消失在互联网的视野中。
Flash Video的崛起不同于RealMedia的全行业流行,Flash Video(以下简称FLV)主要应用在流媒体领域,提供VOD点播和LIVE直播服务。与Dvix和Xvid一起成为了第二阶段的黄金组合。
FLV的压缩编码也不是源自MPEG-4,而是另外一个强大的标准H.26x体系,最早出现在1997年的MacWorld Expo大会上。说来很有意思,FLV天生就和苹果是一对,到最后却被苹果抛弃。
首先,FLV并非是一种压缩编码格式,而是封包格式(比如AVI、MKV、MP4、MOV这些文件,都是一种封包格式。关于封包格式的问题,由于涉及技术过深,在这里暂不作详解。感兴趣的用户可以自己了解掌握,@我也行哦)。FLV采用的视频压缩编码其实有蛮多的,开始是Sorenson Video和Sorenson Video Pro,以及Sonrenson Spark;后来加入了Sorenson MPEG 1/2/4,再后来就是目前最流行的H.264。
其实早期Sonrenson的很多压缩编码格式源自QuickTime压缩编码,也是基于H.263的压缩编码应用。所以我们就不单独介绍这种编码的特点了。
至于FLV在市场上的表现,其实大部分人都可能比较了解。毕竟国内的视频大站,比如优酷土豆、酷6、PPS、PPTV等,早期全都是用的FLV;国外的大站如youtube也是最早的FLV用户。只是随着苹果公司倡导的全面去flash化运动,所有视频大站不得不开始往HTML5转型。
Windows Media VideoWMV一直是一种不温不火的压缩编码格式,出道很早,但应用很少。早在RealMedia时期,微软就已经推出了WMV压缩格式。并可以配合Windows Media Encoder实现流媒体应用,也可以单独编码以文件形式存储。可以说路数跟Real公司一样,只不过是免费的。

其实Windows Media Encoder(以下简称WME)一直都没有什么起色,属于那种历史悠久但无人知晓的品种。早期在跟RealMedia竞争中处于下风,但至少有不少用户知道。后来有了FLV之后,基本就看不到WME的身影了。
至于WMV的压缩格式,最开始也是一种私有格式。只不过到了WMV 9.0的时候,微软向SMPTE学会提交的标准化方案,并入到了VC-1标准体系中。也就是其他家也可以共享这种编码技术。
在早期的WMV标准里面,比如WMV 7.0,是基于MPEG-4 part2实现的编码算法。最早期的版本没有资料,但是可以看得出,WMV主流的版本主要是基于MPEG-4编码的。
H.26x家族除了知名度很高的MPEG组织(隶属于ISO国际标准化组织下面的部门),还有一个在视频编码压缩领域有突出贡献的组织,那就是VCEG(Video Coding Experts Group,视频编码专家组)。VCEG属于另外一个非常厉害的组织ITU(国际电信联盟)下属的部门,可能大部分人都不知道这个名字,但你一定知道他们提供的标准——H.264。
VCEG组织主要编撰的是H.26x标准体系,主要有H.261,H.263,H.264。
H.261主要是面向视频会议领域的,也主要应用在监控安防领域。前面曾讲到的,都是低分辨率低码流视频。
H.263 算是H.261的加强版本,主要是支持更高的分辨率(16CIF),采用了更高级的运动补偿算法。后期又升级到了H.263+和H.263++,使得算法性能和分辨率等都有了明显的提升。
除了知名度很高的H.264以外,还有一个H.262标准,只不过应用非常少,就不讲了。
H.264、MPEG-4 part10 AVC

目前大家最熟悉的压缩编码格式莫过于H.264了,其实它还有另外一个名称MPEG-4 part10 AVC。
原因是这个标准不是一家制定的,而是两家世界上最权威的编码专家组织一同来完成的。那就是ITU下面的VCEG组织和ISO下面的MPEG组织。大家有兴趣的话,可以搜索一下ITU,就知道它在世界标准体系里面的重要性了。目前全世界的通信网络标准,比如2G的GSM、3G的WCDMA、TD-SCDMA、CDMA2000,以及4G的FDD-LTE和TDD-LTE都是ITU来发布的。
H.264/MPEG-4 AVC是融合了两家权威组织的知识结晶,是目前世界上最优秀的编码算法。它的特点非常多,我只列举一下大家能感知到的一些特点。更多的内容大家可以自行查阅资料。
编码压缩率较高,也很灵活。同等画质下,压缩率为MPEG-2的2倍,MPEG-4的1.5~2倍。而且可以用很高的码率(MPEG-2接近)和很低的码率(MPEG-2的1/8),来实现更快的传输需要和更高的画质需要。
动态效果更出色,基本上彻底消除了马赛克现象。比如像《变形金刚》电影里面的大动态场景,你仍然可以非常清晰的看清画面。
压缩效率更高,比如静态画面可以实现超高的压缩比。这是因为H.264/MPEG-4 AVC最大程度的去除冗余数据,使得编码效率提升。
错误修复能力,可以在网络QOS较差的环境下更高效率的传输。
适合各种行业应用,不管是视频会议、安防监控这类的高压缩使用,还是互联网流媒体的动态网络环境使用,以及广播电视这类高画质标准使用。所以你看到的结果就是,几乎所有行业都在使用这个标准(国内的有线电视仍然是MPEG-2,主要是由于有线电视的带宽很高且目前还比较充裕,加上技术升级成本很高)。比如小到CIF尺寸的视频,大到4K标准的电影文件,你会发现他们基本都是基于H.264/MPEG-4 AVC压缩的。
行业应用广泛还得益于H.264/MPEG-4 AVC这种编码格式的产品线健全。
大家可能都知道的一个道理,当压缩率越高的时候(同等画质下),编码就越复杂,计算量越高。对H.264的编码和解码,其计算量比过去的MPEG-2、MPEG-4等都高了很多。所以也就会出现较早期的电脑在软解码(CPU解码)H.264视频的时候,容易出现卡顿。就是因为对计算性能要求较高。
但是好在有大量的专用编码解码芯片,以及专门对H.264编解码优化过的GPU(手机GPU和电脑显卡GPU),使得流畅性和速度得到了保障。所以你会发现某些高画质的视频,可能在电脑上播放会很卡,但是在一些机顶盒上播放会非常流畅。
H.265

其实在H.264还没流行起来,H.265标准就已经建立了。主要特点是压缩效率进一步提升,对UHDTV的支持,更好的信噪比等等。
目前已经有一部分手机、监控安防设备、视频会议设备开始使用H.265编码格式。预计以后会更多,并且逐渐普及。
QuickTime家族

说起QuickTime,大家一定会想起苹果公司。没错,quicktime就是苹果公司推出的一整套编码、解码、播放和流媒体解决方案。quicktime的压缩格式早期是私有的,由于早期MAC系列电脑(那时候没有iphone)普及率很低,所以使用quicktime这种格式的非常少,包括他们的流媒体应用。
只是到了后期,随着iphone的大量用户,quicktime才被大家所知。但这个时候苹果早就将quicktime标准加入到了MPEG-4标准体系中,以及后来H.264出现。结果大家都清楚了,苹果目前也在用H.264压缩标准。
压缩编码全集其实除了上面讲到的主流非主流的视频压缩编码格式以外,还有很多大家不了解的。因为应用非常少,且现在几乎都是被H.264统一了市场,所以就不做介绍了。下面的表格是目前所有的视频压缩编码标准集合:

关于码流的详解简单的说码流就是视频每秒大概产生多大的视频文件,一般以bps(bit per second每秒产生比特数)为单位。其中b代表bit(比特),跟B容易混淆。其实B代表Byte,意为“字节”。1Byte字节=8bit比特。一般存储文件时,通常用B表示;传输文件时,为了表达速度时一般用b表示。
码流常用于视频传输时标记视频属性的,这是因为流媒体,尤其是直播体系中,文件的大小没有太多意义。因为观众可能是随时进来观看的,那么一直等到他观看结束后,才能获取到视频文件的大小。还有一点就是TS流文件不需要从开始读取,它本身就没有文件头尾的概念,可以从任何一个片段开始读取。所以这时候文件大小的意义也不大。
那么为了准确评估视频,需要用到码流这个参数。因为码流代表你每秒需要传输的数据量,需要与你的网络进行匹配。假如你的网络带宽是2Mbps,这代表理想状态下。那么如果你播放码率为1.5Mbps(约等于1500Kbps)的流媒体视频,就很可能会卡顿。主要原因是网络QOS(Quality of Service,服务质量)的问题,它无法保证数据一直都能以最高速度传输,毕竟网络环境很复杂。
在早期的时候,压缩编码标准都采用的是恒定码流编码形式(CBR模式),即每秒钟产生的视频文件大小是完全一样的。例如MPEG-1的码流就是1.5Mbps,那么60分钟的视频产生的文件就是675MB,正好一张VCD光盘的容量。
等到了MPEG-4时代,由于网络环境的复杂性,如果采用恒定码流的策略,在网络速度突然变差的时候,视频就容易卡顿。另外就是视频画面里面如果有存在大动态场景的时候,原先的码流可能会引起画质变差,需要临时降低一下压缩率。所以根据这两种情况的应用,在流媒体直播编码和视频压缩编码时根据实际情况可以采取不同的码流。所以就产生了可变码流编码形式(VBR模式)。
在进行VBR编码时,为了充分提高压缩编码率,可以采用2次压缩法,也就是2pass。但是2次压缩法会大大降低压缩的速度,虽然视频码流更低画质更好,但编码时间也大大拉长。END
小贴士老司机带你了解一下常见的电影文件信息及特点现在很多电影的文件看起来都比较长,大家不一定能够理解。例如下面的:Children.Of.Man.2006.BDRE.1080p.x264.AC3-SiLUHD.mkv对于这样的文件名称,需要拆分开来看。
l 刚开始肯定是影片或电视剧名称,但有时候后面会有一些后缀来表示版本的特殊性,比如Director’s表示导演剪辑版、Unrated表示未分级版、Limited表示有限放映版本;
l 第二部分是发行年份,比如上面的2006;
l 第三部分是视频来源,比如上面的BDRE,表示是来自于蓝光盘(BD)进行了重编码。同样的表示方法还有HDrip表示从HD-DVD重新压制、HR-HDTV表示从高清电视信号重新压制、还有TVrip等。另外有些标识为CAM表示从电影院用摄像机偷拍的、TS表示虽然在电影用摄像机偷拍,但是音频用的是影院提供的音频输出所以音频没有影院的干扰、TC表示直接从胶片上专制拷贝的(没有数字化处理过,亮度不行,画质很一般);
l 第四部分是当前视频的分辨率,很明显上面的1080P代表就是1920×1080分辨率,逐行扫描;
l 第五部分是当前视频使用的压缩格式,上面的X264表示使用X264编码器压缩的,另外还有些Xvid等等都表示用的编码器。比较特殊的是REMUX代表从高清光盘(BD或HD-DVD)中直接提取视频数据重新封装(没有做重编码)。画质最高,但一般文件也会非常大;
l 第六部分是当前影片音频的压缩编码格式,常见的有DTS、AC3、DD5.1、AAC、LPCM、MP3。当然有些使用了次世代高清音频格式,比如DTSHD,TrueHD;
l 横线之后的表示是压制小组的名称。有没有get新技能!比心!