【统计学习方法】学习笔记-第3章-k近邻法
(知乎:https://zhuanlan.zhihu.com/p/314613894)
- k近邻法(k-nearest neighbor,k-NN)是一种基本分类和回归方法(这里讨论分类),对于新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式预测。k近邻不具有显式的学习过程,是利用训练数据对特征空间进行划分,作为分类模型。k近邻法的三个基本要素——k值选择、距离度量、分类决策规则。
3.1 k近邻算法
【算法3.1(k近邻法)】
- 当k=1时的特殊情况,称为最近邻算法。
3.2 k近邻模型
- k近邻法使用的模型实际上对应于对特征空间的划分,模型由三个基本要素决定——距离度量、k值选择、分类决策规则
- k近邻法中,当训练集、距离度量、k值、分类决策规则确定后,对于任一新的实例,其所属类别唯一确定。
- k近邻模型的距离度量一般使用欧式距离,也可以是更一般的 L p L_p Lp距离或Minkowski距离,设特征空间 X \mathcal{X} X是 n n n维实数向量空间 R n \mathrm{R}^n Rn, x i , x j ∈ X x_i,x_j\in \mathcal{X} xi,xj∈X, x i = ( x i ( 1 ) , x i ( 2 ) , . . . , x i ( n ) ) T , x j = ( x j ( 1 ) , x j ( 2 ) , . . . , x j ( n ) ) T x_i=(x_i^{(1)},x_i^{(2)},...,x_i^{(n)})^T,x_j=(x_j^{(1)},x_j^{(2)},...,x_j^{(n)})^T xi=(xi(1),xi(2),...,xi(n))T,xj=(xj(1),xj(2),...,xj(n))T,则 x i , x j x_i,x_j xi,xj的 L p L_p Lp距离定义为:
L p ( x i , x j ) = ( ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ p ) 1 p , p ≥ 1 L_p(x_i,x_j)=(\sum_{l=1}^{n} |x_i^{(l)}-x_j^{(l)}|^p)^{\frac{1}{p}},p\ge1 Lp(xi,xj)=(l=1∑n∣xi(l)−xj(l)∣p)p1,p≥1
- p=2时,为欧氏距离(Euclidean distance)
L 2 ( x i , x j ) = ( ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ 2 ) 1 2 L_2(x_i,x_j)=(\sum_{l=1}^{n} |x_i^{(l)}-x_j^{(l)}|^2)^{\frac{1}{2}} L2(xi,xj)=(l=1∑n∣xi(l)−xj(l)∣2)21
- p=1时,为曼哈顿距离(Manhattan distance)
L 2 ( x i , x j ) = ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ L_2(x_i,x_j)=\sum_{l=1}^{n} |x_i^{(l)}-x_j^{(l)}| L2(xi,xj)=l=1∑n∣xi(l)−xj(l)∣
- p=∞时,是各个坐标距离的最大值
L ∞ ( x i , x j ) = max l ∣ x i ( l ) − x j ( l ) ∣ L_{\infty}(x_i,x_j)=\max_l|x_i^{(l)}-x_j^{(l)}| L∞(xi,xj)=lmax∣xi(l)−xj(l)∣
-
k值选择对k近邻法的结果有较大影响,较小的k值相当于用小邻域预测,学习的近似误差会减小,估计误差会增大,预测结果对邻近实例点非常敏感,即k值的减小意味着整体模型变复杂,容易过拟合;较大的k值相当于用大邻域预测,会减少估计误差,增大近似误差,整体模型变简单。
-
一般用交叉验证法选择最优k值
-
k近邻法的分类决策规则通常是多数表决规则(majority voting rule),多数表决规则等价于经验风险最小化
- 假定分类的损失函数为0-1损失函数,分类函数为 f : R n → { c 1 , c 2 , . . . , c K } f:\mathrm{R}^n\rightarrow\{c_1,c_2,...,c_K\} f:Rn→{c1,c2,...,cK}
- 误分类概率为 P ( Y ≠ f ( X ) ) = 1 − P ( Y = f ( X ) ) P(Y\ne f(X))=1-P(Y=f(X)) P(Y=f(X))=1−P(Y=f(X))
- 对于实例 x ∈ X x\in \mathcal{X} x∈X,其最近邻k个训练实例构成集合 N k ( x ) N_k(x) Nk(x),若涵盖 N k ( x ) N_k(x) Nk(x)的区域类别是 c j c_j cj,则误分类率为
1 k ∑ x i ∈ N k ( x ) I ( y i ≠ c j ) = 1 − 1 k ∑ x i ∈ N k ( x ) I ( y i = c j ) \frac{1}{k} \sum_{x_i \in N_k(x)} I(y_i \ne c_j)=1-\frac{1}{k} \sum_{x_i \in N_k(x)} I(y_i = c_j) k1xi∈Nk(x)∑I(yi=cj)=1−k1xi∈Nk(x)∑I(yi=cj)
- 使误分类率最小即经验风险最小,要使 ∑ x i ∈ N k ( x ) I ( y i = c j ) \sum_{x_i \in N_k(x)} I(y_i=c_j) ∑xi∈Nk(x)I(yi=cj)最大
3.3 k近邻法的实现:kd树
- kd树(kd tree)是一种对k维空间中实例点进行存储以便进行快速检索的树形结构,是一个二叉树,表示对k维空间的一个划分(partition)。构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列k维超矩形区域,kd树每个结点对应于一个k维超矩形区域。
【算法3.2(构造平衡kd树)】
- kd树是存储k维空间数据的树结构
- 根结点包含k维空间所有实例
- 依次选择坐标轴做空间切分,选择训练实例点在选定轴上的中位数点切分,此时kd树是平衡的,平衡的kd树搜索时效率未必最优
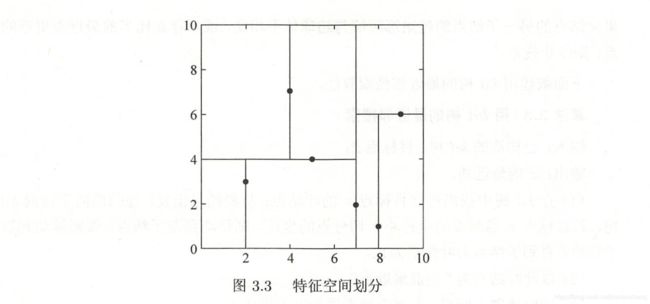
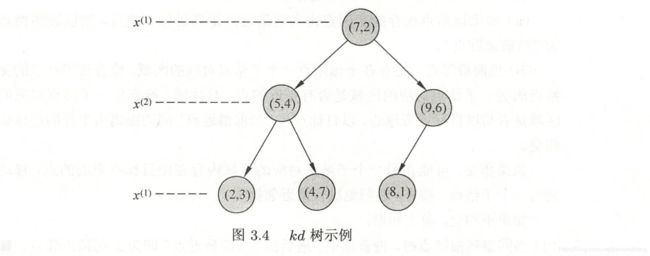
- 例:给定二维空间数据集,构造平衡kd树
T = { ( 2 , 3 ) T , ( 5 , 4 ) T , ( 9 , 6 ) T , ( 4 , 7 ) T , ( 8 , 1 ) T , ( 7 , 2 ) T } T=\{(2,3)^T,(5,4)^T,(9,6)^T,(4,7)^T,(8,1)^T,(7,2)^T\} T={(2,3)T,(5,4)T,(9,6)T,(4,7)T,(8,1)T,(7,2)T}
【算法3.3(用kd树的最近邻搜索)】
-
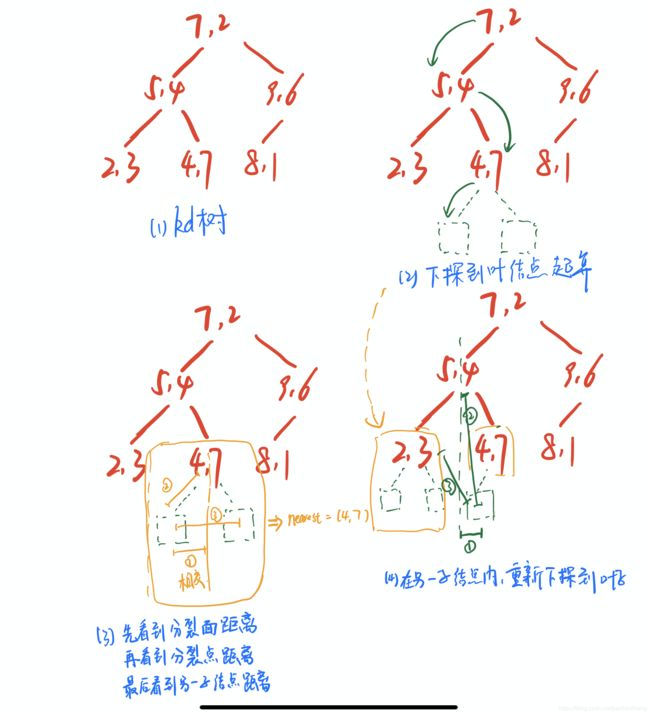
kd树搜索最近邻:①找到该目标点的叶结点;②从叶结点出发,依次回退到父结点;③每次在父结点和另一子结点上找最近邻。③不断查找与目标最邻近的结点,直到确定不可能存在更近结点终止。
-
目标点的最近邻,一定在以目标点为中心并通过当前最近点的超球体内部
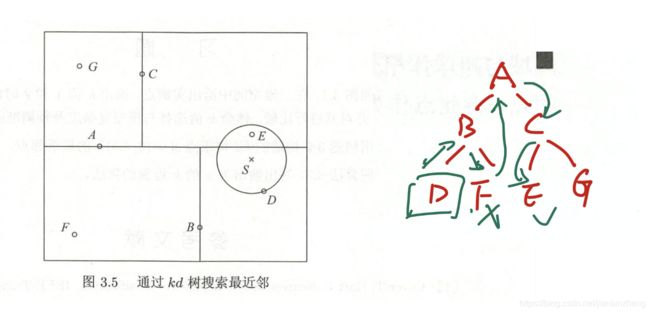
- 如果实例点随机分布,kd树搜索的平均计算复杂度是O(logN),kd树更适用于训练实例树远大于空间维度时的k近邻搜索。
代码复现
数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
# data
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
# data = np.array(df.iloc[:100, [0, 1, -1]])
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
data = np.array(df.iloc[:100, [0, 1, -1]])
X, y = data[:,:-1], data[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lWqcuT0L-1606413627947)(【统计学习方法】学习笔记-第3章-k近邻法.assets/image-20201127015410407.png)]
sklearn
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier()
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
# 0.95
knn遍历方法
class myKNN:
def __init__(self,X_train,y_train,k=3,p=2):
'''
X_train,y_train,训练数据集
k:K值
p:距离度量
'''
self.k=k
self.p=p
self.X_train=X_train
self.y_train=y_train
def predict(self,X):
# 取距离最小的k个点:先取前k个,然后遍历替换
# knn_list存“距离”和“label”
knn_list=[]
for i in range(self.k):
dist=np.linalg.norm(X-self.X_train[i],ord=self.p)
knn_list.append((dist,self.y_train[i]))
for i in range(self.k,len(self.X_train)):
max_index=np.argmax([x[0] for x in knn_list])
dist=np.linalg.norm(X-self.X_train[i],ord=self.p)
if knn_list[max_index][0]>dist:
knn_list[max_index]=(dist,self.y_train[i])
# 聚合k近邻
knn = [k[-1] for k in knn_list]
count_pairs = Counter(knn)
max_label = sorted(count_pairs.items(), key=lambda x: x[1])[-1][0]
return max_label
def score(self, X_test, y_test):
right_count = 0
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right_count += 1
return right_count / len(X_test)
clf = myKNN(X_train, y_train,3)
clf.score(X_test,y_test)
kd-tree
树构建
# 1. 定义树结点=(结点样本,分裂维度,左子树,右子树)
# 2. 顺序寻找分裂维度和分裂点
# 3. 递归分裂
class KdNode(object):
def __init__(self,value,split,left,right):
self.value=value #结点存储的样本,k维向量
self.split=split #分裂维度
self.left=left #左子树
self.right=right #右子树
class KdTree(object):
def __init__(self,data):
k=data.shape[-1] #特征维度
# 在split维切分数据集data_set
def CreateNode(split,data_set):
if len(data_set)==0:
return None
# 确定分裂值,和下一个分裂维度
data_set=sorted(data_set,key=lambda x:x[split])
split_index=len(data_set)//2
split_value=data_set[split_index]
split_next=(split+1)%k
# 递归
return KdNode(
split_value
,split
,CreateNode(split_next,data_set[:split_index])
,CreateNode(split_next,data_set[split_index+1:])
)
self.root = CreateNode(0, data) # 从第0维分量开始构建kd树,返回根节点
# KDTree的前序遍历,用于验证树构建的对不对
def preorder(root):
print(root.value)
if root.left: # 节点不为空
preorder(root.left)
if root.right:
preorder(root.right)
data = np.array([[2,3],[5,4],[9,6],[4,7],[8,1],[7,2]])
kd = KdTree(data)
preorder(kd.root)
#OUTPUT:
#[7 2]
#[5 4]
#[2 3]
#[4 7]
#[9 6]
#[8 1]
树搜索
# 最近邻搜索。对构建好的kd树进行搜索,寻找与目标点最近的样本点:
from math import sqrt
from collections import namedtuple
# 定义一个namedtuple,具名元组,分别存放最近坐标点、最近距离和访问过的节点数
result = namedtuple("Result_tuple",
"nearest_point nearest_dist nodes_visited")
def find_nearest(kd_tree,point):
k=len(point) # 特征维度
def travel(kd_node,target,max_dist):
'''
输入:当前节点、目标点、目前最小距离
输出:最近结点、距离、已访问点数
备注:当前节点=分裂点,输出为当前节点构成的tree中最近的点是哪个
'''
# 如果当前节点为空节点,则返回距离inf
if not kd_node:
return result([0]*k,np.inf,0)
# 每一步这里为判定当前要分到哪个分支
nodes_visited=1
node_split=kd_node.split
node_value=kd_node.value
if target[node_split]<=node_value[node_split]:
nearer_node = kd_node.left # 下一个访问节点为左子树根节点
further_node = kd_node.right # 同时记录下右子树
else:
nearer_node=kd_node.right
further_node=kd_node.left
# 在被分的分支中,最近节点是哪个,距离多少(递归下探到叶子节点)
temp1=travel(nearer_node,target,max_dist)
# 取搜索到的最近点
nearest=temp1.nearest_point
dist=temp1.nearest_dist
nodes_visited+=temp1.nodes_visited
# 若搜索到的最近点比当前最小距离还小,则用该点的距离做超球体半径
if dist<max_dist:
max_dist=dist
# ①计算目标点到当前点截面的距离,即超球体和分割超平面是否相交
dist_split_plane=abs(node_value[node_split]-target[node_split])
# 若不相交,结束返回
if max_dist<dist_split_plane:
return result(nearest,dist,nodes_visited)
# ②计算目标点与当前点(分割点)的距离,如果更近,用这个
dist_split_point = sqrt(sum((p1 - p2)**2 for p1, p2 in zip(node_value, target)))
if dist_split_point < dist: # 如果“更近”
nearest = node_value # 更新最近点
dist = dist_split_point # 更新最近距离
max_dist = dist # 更新超球体半径
# ③检查另一个子结点对应的区域是否有更近的点
temp2 = travel(further_node, target, max_dist)
nodes_visited += temp2.nodes_visited
if temp2.nearest_dist < dist: # 如果另一个子结点内存在更近距离
nearest = temp2.nearest_point # 更新最近点
dist = temp2.nearest_dist # 更新最近距离
return result(nearest, dist, nodes_visited)
return travel(kd_tree.root, point, float("inf")) # 从根节点开始递归ret = find_nearest(kd, [3,4.5])
ret = find_nearest(kd, [3,4.5])
print (ret)
# Result_tuple(nearest_point=array([2, 3]), nearest_dist=1.8027756377319946, nodes_visited=4)