机器学习决策树算法泰塔尼克号预测
对于数据集观察

其中有11列个维度,需要对其中一些进行数据处理
PassengerId ,乘客的id号,对生存率没影响。
Survived ,应该是标签,1表示存活,0表示死亡。
Pclass ,船舱等级,就是我们坐船有等级之分。这个属性会对生产率有影响。
Name ,名字,这个不影响生存率。应该可以忽略。
Sex , 性别,女士优先,所有这列保留,可能有影响。
Age , 年龄,因为优先保护老幼,可能有影响。
SibSp ,兄弟姐妹,就是有些人和兄弟姐妹一起上船的。这个会有影响,保留
Parch , 父母和小孩。这个也可能因为要救父母小孩耽误上救生船。保留
Ticket , 票的编号。应该没有影响,删除
Fare , 费用。这列保留
Cabin ,舱号。住的舱号没有影响。忽略。
Embarked ,上船的地方。这列可能有影响。我认为登陆地点不同,可能显示人的地位之类的不一样。我们先保留这列。
首先导入所需库
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import LabelEncoder
from sklearn import tree
import matplotlib.pyplot as plt导入数据集并可视化基本信息
data = pd.read_csv(r"C:\Users\google1\PycharmProjects\pythonProject\机器学习作业\train.csv")
data.head()
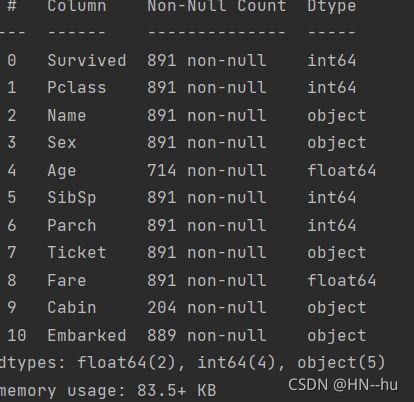
print(data.info())
print(data.shape)#测试集有11个维度,以及891个样本如图
对数据进行预处理,删除对预测效果无关信息,并删除缺失太多的列信息,对行缺失值进行均值填补,行缺失多的进行删除
data.drop(["Cabin","Name","Ticket","PassengerId"],inplace=True,axis=1)
# print(data.info())#现在有8列
data['Age'] = data['Age'].fillna(data['Age'].mean)
data = data.dropna()
print(data.info())#又删除了两个缺失的行
处理后如图

对一些Object类数据进行编码
encoded = LabelEncoder()
encoded.fit(data['Sex'])
data['Sex'] = encoded.transform(data["Sex"])
encoded.fit(data['Embarked'])
data['Embarked'] = encoded.transform(data["Embarked"])
print(data.head()) 效果如下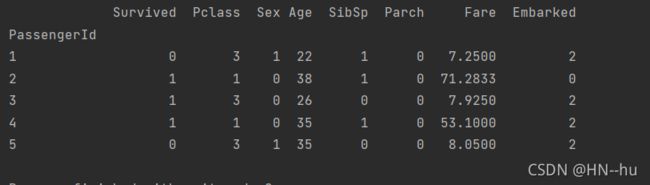
可见将其成功编码
接下来训练模型
#提取标签
X = data.drop(["Survived"],axis=1)
y = data["Survived"]
# print(X.info())
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3)
#调整一下索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
#拟合模型
clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(Xtrain, Ytrain)
# score = cross_val_score(clf,X,y,cv=10).mean()
score_ = clf.score(Xtest, Ytest)
print(score_)测得最后的准确率为0.778

接下来可调参,主要调最大深度max—depth
#影响其性能的一个主要指标是树的最大深度
score__ = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25
,max_depth=i+1
,criterion="entropy" )
clf = clf.fit(Xtrain, Ytrain)
score_te = cross_val_score(clf,X,y,cv=10).mean()
score__.append(score_te)
print(max(score__))
plt.plot(range(1,11),score__,color="blue",label="test")
plt.xticks(range(1,11))
plt.show()
可见当深度是7时效果较好,可以重新返回加入参数最大深度并改为7,此时准确度变为了0.82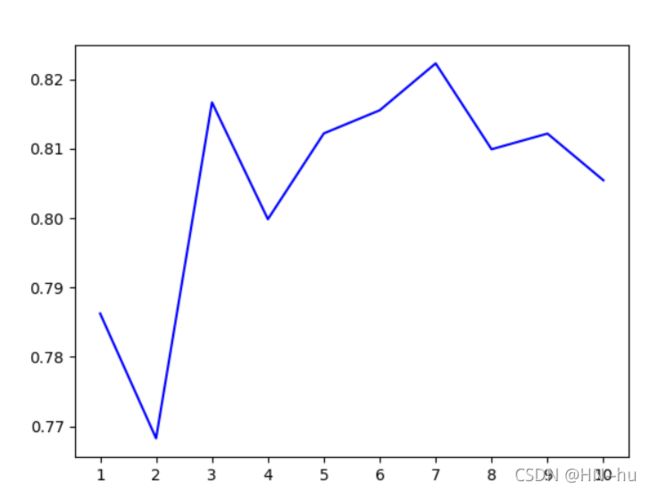
可以画出树的形状,这里需要导入库
#画出决策树,需要导入库
feature_name = ["Pclass","Sex","Age","SibSp","Parch","Fare","Embarked"]
import graphviz
dot_data = tree.export_graphviz(clf,out_file = None,feature_names= feature_name,class_names=["活着","遇难"],filled=True,rounded=True)
graph = graphviz.Source(dot_data)
graph.render(view=True, format="pdf", filename="decisiontree_pdf")一个牛马模样的决策树就诞生了

最后,对给定无标签数据集进行预测,如图 不知存活情况

导入数据集并同样处理
#导入测试集
#导入测试集
data1 = pd.read_csv(r'C:\Users\google1\PycharmProjects\pythonProject\机器学习作业\test.csv')
data1.drop(["Cabin","Name","Ticket","PassengerId"],inplace=True,axis=1)
data1["Age"] = data1["Age"].fillna(data1["Age"].mean())
data1 = data1.dropna()
encoded = LabelEncoder()
encoded.fit(data1['Sex'])
data1['Sex'] = encoded.transform(data1["Sex"]).astype("int64")
encoded.fit(data1['Embarked'])
data1['Embarked'] = encoded.transform(data1["Embarked"]).astype("int64")
predict1 = clf.predict(data1)
print(predict1)结果如图