一、知识图谱商业应用
一、知识图谱商业应用
01 唯品金融大数据
使用的是OrientDB,Orientdb提供了大量的接口, 其中最常用的就是Gremlin和sql。
Gremlin是Apache TinkerPop 框架下的图遍历语言。Gremlin是一种函数式数据流语言,可以使得用户使用简洁的方式表述复杂的图的遍历或查询,大部分图数据库都支持Gremlin。示例图总共拥有12个节点(Vertex) 11条边(Edge)。1521537893115977.png
唯品金融在使用Orientdb的开发过程中遇到的最大问题,是数据库初始化时的批量写入速度较慢, 由于Vertex和Edge数量在10亿数量级,在没有优化的情况下,单台服务器写入完整数据需要几天。

02 PlantData知识图谱数据智能平台
地址:http://www.hiekn.com/KGIndex/index.html

PlantData是一个用知识图谱技术解决数据关联、数据语义、数据智能的平台。
自主研发的PlantData图谱数据智能平台,致力于推进知识图谱在产业界的落地发展,让数据智能更好的支撑商业智能和人工智能。
多源异构数据,其中非结构化数据有一定比例;
数据中存在一定数量不同类别的实体;
业务上更加关注数据中实体的关联,而不仅仅是数据本身…
03 拍拍贷图数据库技术
目前将用户信息,设备信息及社交关系构建了一个异构网络,并将该异构网络图应用在用户关联分析及反欺诈检测场景。
传统的方式上,我们的数据都是存储在RDMS上,要查询用户的关联关系的时候,都是通过关联多张表来实现。但是这种方式存在很多的问题:
- a. 这些表相应都较大,在做表关联的时候效率非常低下;
- b. 对于关系的层次支持非常有限,出入度很大的结点,产生的中间结果会非常大;
- c. 对于图上的查询不够灵活。
这些都极大地限制了我们分析能力和分析效率。出于以上这些痛点,我们引入了titan图形数据库。每天会通过改写的Titan Bulkload将10亿+结点信息和500亿+左右的关系数据导入Titan后台HBase生成一张包含13类节点和15类边的复杂异构网络。通过该网络,可以方便快速地回答以下类似问题:1) 和用户A关联的用户有哪些;2) 和用户A关联的用户有什么特征;3) 用户A和用户B怎么关联在一起的。
下图是我们将图数据库应用于反欺诈中的示例图:

根据原始的数据图我们可以对用户做以下调查分析,来确定特定的用户是不是欺诈用户或者是不是与欺诈用户有关联:
- 通过特定规则筛选可疑用户
- 查看与可疑用户有特定关联的用户
- 查看与可疑用户有特定关联的所有用户组成的子网的网络特征及用户特征
- 分析特定用户可以通过什么样的关联关系关联在一起
- 最多可分析6层关联关系的数据
通过该方式,我们大大减少了调查过程中的工作量,整体效率提升了25%+。
04 CN-DBpedia
样例数据文件是txt格式,每行一条数据,每条数据是一个(实体名称,属性名称,属性值)的三元组,中间用tab分隔,具体如下所示。
【复旦大学 简称 复旦】
包含900万+的百科实体以及6700万+的三元组关系。其中mention2entity信息110万+,摘要信息400万+,标签信息1980万+,infobox信息4100万+
该数据仅供学术研究使用,商用请联系我们获取授权
http://kw.fudan.edu.cn/cndbpedia/download/
05 OpenKG.CN——开放的中文知识图谱
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。
知识图谱旨在通过建立数据之间的关联链接,将碎片化的数据有机的组织起来, 让数据更加容易被人和机器理解和处理,并为搜索、挖掘、分析等提供便利,为人工智能的实现提供知识库基础。知识图谱涉及的技术领域包括:知识表示、自然语言理解、智能问答、知识抽取、链接数据、图数据库、图挖掘、常识推理等。

06 楚辞
楚辞以语义网为理论基础,致力于建设中文语义知识库,解决歧义问题,把知识嵌入到各类信息中。

知识结构中有:
项目描述(DOAP)词汇集
项目描述(DOAP)词汇集使用了W3C的RDF和网络本体语义进行描述。
Muninn坟墓本体
Muninn坟墓本体的意思是用于处理人类的遗体。
还有比较好玩的:
关于功夫、功法的本体、关于能力、技能的本体、有关五行的基础本体、有关感觉的基础本体、有关症状的本体、有关商业模式画布的本体
联谊的nodes,还有几个方向,不过好像里面没货

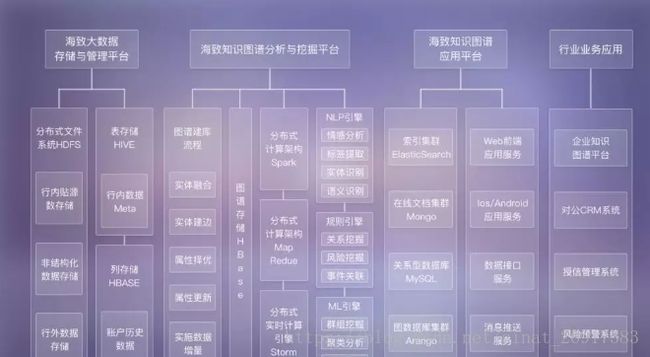
07 海致大数据
http://www.haizhi.com/solution.html
海致大数据核心团队在参与研发了全球第一个中文通用知识图谱平台之后,致力于将这一大数据时代的核心技术向金融产业进行垂直化研发,推出了业界首个金融领域知识图谱平台——海致智能金融知识图谱1.0,其具备强大的自然语言处理能力,包括模板识别、实体识别、情感分析等,也具备领先的关系挖掘算法引擎,是海致大数据多年研发与客户服务的最新成果。
08 腾讯云星图

是一个图数据库和图计算引擎的一体化平台:融合治理异构异质数据;提供关联查询、可视化图分析、图挖掘、机器学习和规则引擎;支持万亿关联关系数据的快速检索、查找和浏览;挖掘隐藏关系并模型化业务经验。作为金融AI风控等泛安全领域知识图谱解决方案,星图增强企业业务,催新商业模式。
- 金融
- 星图智能平台运用大数据、知识图谱、人工智能等技术,并围绕监管科技服务于金融行业,可提升金融机构合规和风控能力,从而帮助实现行业人工智能,为金融环境快速而稳健的发展贡献前沿科技的力量。在对公业务中,星图可深耕大数据,帮助金融合作伙伴存储其商业客户大数据,梳理客户关系以高效挖掘潜在商业价值;在对私业务方面,星图可在预测新客户的潜在风险和检测恶意用户团伙等方面提供精准服务。
- 泛安全
- 星图智能平台从大数据中深度挖掘关联关系,可准实时分析多至万亿级海量关系数据,转化为关系图谱数据,编织线上线下社交的泛安全专属知识图谱。结合专属的图计算引擎、机器学习技术和业务专家经验打造泛安全人工智能:线上可帮助新兴互联网公司梳理用户关系实现精准营销等,线下可有力支撑公安机关展开情报研判分析、犯罪团伙跟踪以及重大事情预警等。
09 网感至察


二、相关科研机构与算法框架
2.1 复旦大学 Knowledge Works
http://kw.fudan.edu.cn/
开源库、开源工具、创业项目(数眼科技)
2.1.1 开源库:FudanDNN 基于深度学习的中文自然语言处理工具。
复旦深度网络中文自然语言处理工具FudanDNN-NLP4.0(在3.0的基础上新增上下文相关问答。分为两种情况:第一种情况处理类似上一句问“今天北京天气如何?”,然后追问“上海呢?”的情况;另一种情况是根据对话主题展开、转换和递进给出合适的回答;多轮对话。处理类似订购机票的场景。不同场景可以根据对话进展自由切换,并且期间可插入其他问答;海量自定义问答对的高效检索。检索匹配时考虑同义词替换,可根据发音相似性纠正可能的错误,并且支持一次提问包括多个问题的情况;可为每一位用户定义各自的上下文信息;图形客户端用于系统演示和调试,支持本地或服务器快速部署;问答过程中检测禁用词功能)
C++所写,专门用于商业环境
github:https://github.com/FudanDNN/FudanDNN
blog:http://homepage.fudan.edu.cn/zhengxq/deeplearning/
2.1.2 CN-DBpedia接口——解释型
提供全套API,并且免费开放使用。如需大规模调用请联系[email protected]索取APIKEY。
- (1) api/cndbpedia/ment2ent
输入实体指称项名称(mention name),返回对应实体(entity)的列表,json格式。
{"status": "ok", "ret": ["红楼梦(中国古典四大名著之一)", "红楼梦(2010年李少红执导的古装情感剧)", "红楼梦(1987年陈晓旭、欧阳奋强主演央视版电视剧)"}
- 1
- 2
- (2) api/cndbpedia/avpair
输入实体名,返回实体全部的三元组知识
{"status": "ok", "ret": [["中文名", "复旦大学"], ["英文名称", "Fudan University"], ["简称", "复旦·FUDAN"], ["创办时间", "1905年09月14日"], ["类别", "公立大学"], ["学校类型", "综合"]}
- 1
- 2
- (3) api/cndbpedia/value
给定实体名和属性名,返回属性值
{"status": "ok", "ret": ["Fudan University"]}
- 1
- 2
2.1.3 Probaseplus API接口
- pbapi/getconcepts
输入一个英文或中文的实体或概念名,返回其概念列表,返回格式为json格式。
查询 航空母舰 的第1-50个概念(第一页)
http://knowledgeworks.cn:20314/probaseplus/pbapi/getconcepts?kw=航空母舰&start=0
返回值:{"numcon": 73, "concept": [["船", 15], ...]}
表示航空母舰在CN-Probase中有73个概念,最具有代表性的概念是 船。
- 1
- 2
- 3
- 4
- 5
点评:该接口专用于多义词
- pbapi/getentities
输入一个英文或中文的概念名,返回其包含的实体列表,返回格式为json格式。
查询 水果 的第1-50个实体(第一页)
http://knowledgeworks.cn:20314/probaseplus/pbapi/getentities?kw=水果&start=0
返回值:{"entity": [["苹果", 2100], ["香蕉", 1321], ...], "nument": 1060}
表示水果在CN-Probase中有1060个实体,如 苹果,香蕉 等。
- 1
- 2
- 3
- 4
- 5
点评:该接口专门用于寻找一个实体词的下属词
2.1.4 CN-Probase接口——概念型
中文概念图谱和概念分类体系
-
api/mention2entity
{“status”: “ok”, “ret”: [“刘德华(中国香港男演员、歌手、词作人)”, “刘福荣(刘德华别名)”, “刘德华(清华大学教授)”}
跟CN-DBpedia中的ment2ent类似,返回实体词解释。
- api/getConcept
输入实体,返回实体对应概念列表,json格式。
http://shuyantech.com/api/cnprobase/concept?q=刘德华
{"status": "ok", "ret": [["人物", 1299103], ["演员", 59658], ["娱乐人物", 25299], ["歌手", 15884], ["电影人", 88], ["填词人", 64]], "count": 6, "pagesize": 50}
- 1
- 2
- 3
count:概念数量;pagesize:每次请求最多返回的概念数量
点评:返回了实体词的属性,跟CN-DBpedia中的avpair,有点类似
- api/getEntity
输入概念,返回概念对应实体列表,json格式。默认返回前50个。
{"status": "ok", "ret": [["乔振宇(中国内地男演员)", 321795144], ["霍建华(中国台湾男演员)", 104187122], ["杨洋(中国内地男演员)", 87598713]}
- 1
- 2
count:实体数量;pagesize:每次请求最多返回的实体数量
2.1.5 Shorttext Parsing API,短文本依存分析接口
输入英文字符串,返回短文本解析的json
目前比较支持英文
2.1.6 Entity Understanding API接口
输入中文文本,输出分词后的文本,以及识别的实体,json格式。
http://shuyantech.com/api/entitylinking/cutsegment?q=打球的李娜和唱歌的李娜不是同一个人
{"cuts": ["打球", "的", "李娜", "和", "唱歌", "的", "李娜", "不是", "同一个", "人"], "entities": [[[3, 5], "李娜(中国女子网球名将)"], [[9, 11], "李娜(流行歌手、佛门女弟子)"]]}
- 1
- 2
- 3
输入一段话,输出话中的实体词 + 实体词的位置信息
2.1.7 数眼科技
爬虫模块(分布式、企业级的爬虫任务)
知识图谱与概念图谱,基于知识工场
中文QA(输入一段话然后返回内容)、[实体链接][4]
未来开放:企业级图数据库解决方案(还没开发完全)
2.1.8 额外
金融新闻Bots,金融类监控,根据关键词筛选,新闻、网站、软文;理财产品问答系统
拼音转汉字服务
2.2 思知(OwnThink)
开放项目:问答机器人、知识库
跟 复旦的Knowledge Works有点相似,估计没那个全面,开源的聊天机器人也弱爆了。。
获取歧义关系(mention -> entity)
https://api.ownthink.com/ambiguous?mention=苹果
{
"message": "success",
"data": [
{
"蔷薇科苹果属果实": [
"苹果(蔷薇科苹果属果实)",
10929205
]
},
{
"韩国2008年康理贯执导电影": [
"苹果(韩国2008年康理贯执导电影)",
7589732
]
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
获取全部知识(entity -> knowledge)
更详细的信息
https://api.ownthink.com/kg?entity=苹果(蔷薇科苹果属果实)
{
“message”: “success”,
“data”: {
“item”: “苹果(2007年李玉执导电影)”,
“desc”: “《苹果》是由李玉执导,范冰冰、佟大为、梁家辉、金燕玲领衔主演的黑色幽默剧情电影。”,
“eav”: [
{
“entity”: “苹果(2007年李玉执导电影)”,
“value”: “苹果”,
“attribute”: “中文名”
关联图谱
https://api.ownthink.com/assmap?entity=苹果
关联图谱暂时不对外直接开放(由于某种原因将于2018年8月开放)
- 1
- 2
- 3
2.3 Zhishi.me
王昊奋,Zhishi.me 通过从开放的百科数据中抽取结构化数据,首次尝试构建中文通用知识图谱。目前,已融合了三大中文百科,百度百科,互动百科以及维基百科中的数据。
2.4 交大的Acenap
官方主页,http://acemap.sjtu.edu.cn/
主要做学术论文、人群的知识图谱
- 公开了多款算法(http://acemap.sjtu.edu.cn/acenap),有不同的软件版本,python/matlab
- 公开了多个可视化的方案与算法,http://acemap.sjtu.edu.cn/acenap/algorithms
- 提到了几个公开的数据源:社交媒体数据源 + 人人网爬取的人物关系数据源
- 社交媒体数据源:
- MovieLens This dataset is collected from the MovieLens dataset
available at https://grouplens.org/datasets/movielens/. In the
original dataset, the edge weights between users and items, namely
the users’ ratings on items are decimal ratings in (0,5]. In our
modified dataset, we map the decimal ratings to interger ratings in
range [1,10]. - AudioSrobbler This dataset is collected from the AudioSrobbler
dataset available at
http://www-etud.iro.umontreal.ca/~bergstrj/audioscrobbler_data.html.
In the original dataset we are provided with users’ play counts for
each music artist they have listened to. In our modified dataset, we
mapped play counts to bounded edge weights between users and items
i.e. users’ ratings as integers in [1,5]. - BookCrossing This dataset is collected from the BookCrossing dataset
available at http://www2.informatik.uni-freiburg.de/~cziegler/BX/. In
the original dataset, we are provided with the users’ implicit and
explicit ratings on books. In our modified dataset, we use integers
in [1,10] to present the explicit user ratings and exculde ratings of
0, which denote implicit ratings.
- MovieLens This dataset is collected from the MovieLens dataset
- 社交媒体数据源:
2.5 清华大学的openKE
由 THUNLP 基于 TensorFlow 工具包开发
该框架有如下特征:
- 拥有配置多种训练环境和经典模型的简易接口;
- 对高性能 GPU 训练进行加速和内存优化;
- 高效轻量级的 C++实现,用于快速部署和多线程加速;
- 现有大规模知识图谱的预训练嵌入,可用于多种相关任务;
- 长期维护以修复 bug,满足新需求。
TransE 、TransH、TransR、TransD、RESCAL、DistMult、HolE、ComplEx等算法的统一接口的高效实现;
面向WikiData和Freebase两大通用KG全量数据的预训练好的知识表示模型下载,不需要大家再费心重复训练
2.6 自然语言处理工具包HanLP
HanLP是由一系列模型与算法组成的NLP工具包,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
有py和java版本的,分别是:
pyhanlp: Python interfaces for HanLP
HanLP: Han Language Processing
从分词、词性标注、命名实体识别、关键词提取、短语提取、文本推荐(语义推荐、拼音推荐、字词推荐)、依存句法分析等功能,很全面。
2.7 scikit-kge: MIT知识图谱embedding工具包
地址:https://github.com/mnick/scikit-kge
此工具包是有麻省理工大学( MIT )开发的python库,可用不同方法训练得到知识图谱的分布式表示结果,包含的知识图谱表示学习方法有:
Holographic Embeddings (HolE)
RESCAL
TransE
TransR
ER-MLP
2.8 RDFox: 牛津大学的知识库推理工具(推荐)
OpenKG搜集和整理知识图谱相关的技术工具,并将组织开展技术评测。
RDFox是一个高度可扩展的内存RDF三元组存储,支持共享内存并行OWL 2 RL推理。 它是用C ++编写的跨平台软件,带有一个Java包装器,允许与任何基于Java的解决方案(包括OWL API)轻松集成。
2.9 中国知网
同时,知网内的NLP结构也非常复杂,参考:http://www.keenage.com/zhiwang/c_zhiwang.html
知网描述了下列各种关系:
(a) 上下位关系 (由概念的主要特征体现,请参看《知网管理工具》)
(b) 同义关系(可通过《同义、反义以及对义组的形成》获得)
(c) 反义关系(可通过《同义、反义以及对义组的形成》获得)
(d) 对义关系(可通过《同义、反义以及对义组的形成》获得)
(e) 部件-整体关系(由在整体前标注 % 体现,如”心”,”CPU”等)
(f) 属性-宿主关系(由在宿主前标注 & 体现,如”颜色”,”速度”等)
(g) 材料-成品关系(由在成品前标注 ? 体现,如”布”,”面粉”等)
(h) 施事/经验者/关系主体-事件关系(由在事件前标注 * 体现,如”医生”,”雇主”等)
(i) 受事/内容/领属物等-事件关系(由在事件前标注 $ 体现,如”患者”,”雇员”等)
(j) 工具-事件关系(由在事件前标注 * 体现,如”手表”,”计算机”等)
(k) 场所-事件关系(由在事件前标注 @ 体现,如”银行”,”医院”等)
(l) 时间-事件关系(由在事件前标注 @ 体现,如”假日”,”孕期”等)
(m) 值-属性关系(直接标注无须借助标识符,如”蓝”,”慢”等)
(n) 实体-值关系(直接标注无须借助标识符,如”矮子”,”傻瓜”等)
(o) 事件-角色关系(由加角色名体现,如”购物”,”盗墓”等)
(p) 相关关系(由在相关概念前标注 # 体现,如”谷物”,”煤田”等)
同时还有API:介绍知网知识库的 API 参数与调用过程,当日调用接口的次数不得超过5000次
词语相似度检测/中文分析/英文分析/词语相关性检测
知网的api是在一个语知的平台:http://yuzhinlp.com/chnParse.html

知网内容期刊查询的时候,也支持知识图谱:



延伸:语知科技的接口非常丰富!
- 有关系抽取接口:判案要素抽取、金融事件抽取、公司以及机构名抽取(在更新)
- 文本语义解析接口、词语相关、句子相关性、篇章相关性;
- 基础接口:词语拼音、词性判定、自动分词、词性标注、英文释义(机器翻译?)
每天有5000次免费调用额度 

语知科技在语义分析方面优势明显,它可以处理的文本可以是超句的段落或篇章,并且系统的分析结果可揭示五种类型的内容:词语之间的句法关系,词语之间的逻辑语义关系,词语之间的深层逻辑语义关系,通过逻辑语义角色转换得到的深层理解,以及各个词语的词性、义项、拼音及其对应的英语译文。
可参考:基于HowNet的NLP技术,语知科技打造新型语言理解技术服务平台
2.10 浙江大学:创新设计产品库
url:http://120.55.82.39:8080/index.html



2.11 中草药知识服务系统
http://zcy.ckcest.cn/tcm/
好厉害,有知识图谱,有KGQA问答系统,还有主题建模,各种专业分词工具。
还有以图搜图功能,尼玛,逆天!!





2.12 中国工程科技知识中心
http://www.ckcest.cn/portal/hotspotdetail18
依据时间,关键词等信息对内容进行展示 
2.13 NLPIR
http://ictclas.nlpir.org/nlpir/
基于词语的多度传播,简单的词关联逻辑。

2.14 开放域中文知识图谱《大词林》

延伸一:一文揭秘!自底向上构建知识图谱全过程
知识图谱的构建技术主要有自顶向下和自底向上两种。其中自顶向下构建是指借助百科类网站等结构化数据源,从高质量数
据中提取本体和模式信息,加入到知识库里。而自底向上构建,则是借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的信息,加入到知识库中。
本篇文章很基础的解释了知识图谱的底层结构,很赞!
