PyTorch搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
目录
- I. 前言
- II. seq2seq
- III. 代码实现
-
- 3.1 数据处理
- 3.2 模型搭建
- 3.3 模型训练/测试
- 3.4 实验结果
- IV. 源码及数据
I. 前言
系列文章:
- 深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)
- PyTorch搭建LSTM实现时间序列预测(负荷预测)
- PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)
- PyTorch搭建双向LSTM实现时间序列预测(负荷预测)
- PyTorch搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- PyTorch搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- PyTorch中实现LSTM多步长时间序列预测的几种方法总结(负荷预测)
II. seq2seq
seq2seq由两部分组成:Encoder和Decoder。seq2seq的输入是一个序列,输出也是一个序列,经常用于时间序列预测。关于seq2seq的具体原理可以参考:DL入门(3):循环神经网络(RNN)。
III. 代码实现
3.1 数据处理
我们根据前24个时刻的负荷以及该时刻的环境变量来预测接下来12个时刻的负荷(步长pred_step_size可调)。
数据处理代码和前面的直接多输出预测一致:
# Multiple outputs data processing.
def nn_seq_mo(B, num):
data = load_data()
train = data[:int(len(data) * 0.7)]
test = data[int(len(data) * 0.7):len(data)]
def process(dataset, batch_size):
load = dataset[dataset.columns[1]]
load = load.tolist()
m, n = np.max(load), np.min(load)
load = (load - n) / (m - n)
dataset = dataset.values.tolist()
seq = []
for i in range(0, len(dataset) - 24 - num, num):
train_seq = []
train_label = []
for j in range(i, i + 24):
x = [load[j]]
for c in range(2, 8):
x.append(dataset[j][c])
train_seq.append(x)
for j in range(i + 24, i + 24 + num):
train_label.append(load[j])
train_seq = torch.FloatTensor(train_seq)
train_label = torch.FloatTensor(train_label).view(-1)
seq.append((train_seq, train_label))
seq = MyDataset(seq)
seq = DataLoader(dataset=seq, batch_size=batch_size, shuffle=False, num_workers=0, drop_last=True)
return seq, [m, n]
Dtr, lis1 = process(train, B)
Dte, lis2 = process(test, B)
return Dtr, Dte, lis1, lis2
3.2 模型搭建
模型搭建分为三个步骤:编码器、解码器以及seq2seq。
首先是Encoder:
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.num_directions = 1
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True, bidirectional=False)
def forward(self, input_seq):
batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
h_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size).to(device)
# print(input_seq.size())
# output(batch_size, seq_len, num_directions * hidden_size)
output, (h, c) = self.lstm(input_seq, (h_0, c_0))
return h, c
一般来讲编码器采用的就是RNN网络,这里采用了LSTM将原始数据进行编码,然后将LSTM的最后的隐状态和单元状态返回。
接着是解码器Decoder:
class Decoder(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 1
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True, bidirectional=False)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq, h, c):
batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
output, _ = self.lstm(input_seq, (h, c))
pred = self.linear(output) # pred()
pred = pred[:, -1, :]
return pred
编码器同样也由LSTM组成,不过解码器的初始的隐状态和单元状态是编码器的输出。
3.3 模型训练/测试
模型训练:
def seq2seq_train(args, Dtr, path):
input_size, hidden_size, num_layers = args.input_size, args.hidden_size, args.num_layers
output_size = args.output_size
batch_size = args.batch_size
model = Seq2Seq(input_size, hidden_size, num_layers, output_size, batch_size=batch_size).to(device)
loss_function = nn.MSELoss().to(device)
if args.optimizer == 'adam':
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr,
weight_decay=args.weight_decay)
else:
optimizer = torch.optim.SGD(model.parameters(), lr=args.lr,
momentum=0.9, weight_decay=args.weight_decay)
scheduler = StepLR(optimizer, step_size=args.step_size, gamma=args.gamma)
# training
loss = 0
for i in tqdm(range(args.epochs)):
cnt = 0
for (seq, label) in Dtr:
cnt += 1
seq = seq.to(device)
label = label.to(device)
y_pred = model(seq)
loss = loss_function(y_pred, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# if cnt % 100 == 0:
# print('epoch', i, ':', cnt - 100, '~', cnt, loss.item())
print('epoch', i, ':', loss.item())
scheduler.step()
# save
state = {'model': model.state_dict(), 'optimizer': optimizer.state_dict()}
torch.save(state, path)
模型测试:
def seq2seq_test(args, Dte, lis, path):
# Dtr, Dte, lis1, lis2 = load_data(args, flag, args.batch_size)
pred = []
y = []
print('loading model...')
input_size, hidden_size, num_layers = args.input_size, args.hidden_size, args.num_layers
output_size = args.output_size
model = Seq2Seq(input_size, hidden_size, num_layers, output_size, batch_size=args.batch_size).to(device)
model.load_state_dict(torch.load(path)['model'])
model.eval()
print('predicting...')
for (seq, target) in tqdm(Dte):
target = list(chain.from_iterable(target.data.tolist()))
y.extend(target)
seq = seq.to(device)
with torch.no_grad():
y_pred = model(seq)
y_pred = list(chain.from_iterable(y_pred.data.tolist()))
pred.extend(y_pred)
y, pred = np.array(y), np.array(pred)
m, n = lis[0], lis[1]
y = (m - n) * y + n
pred = (m - n) * pred + n
print('mape:', get_mape(y, pred))
# plot
plot(y, pred)
多步预测的每一步,都需要用不同的模型来进行预测。在正式预测时,数据的batch_size需要设置为1。
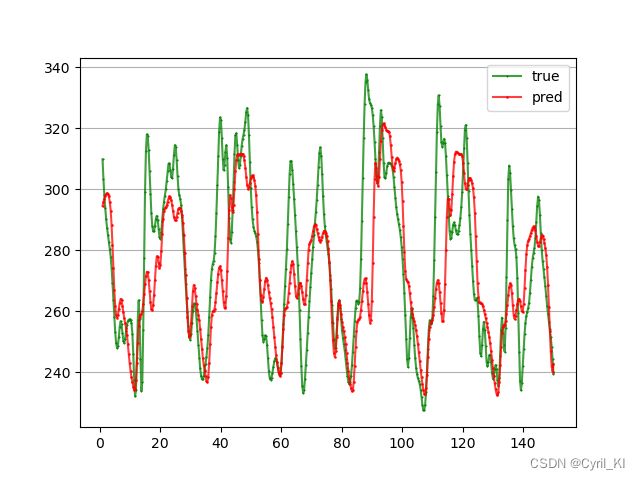
3.4 实验结果
前24个预测未来12个,每个模型训练50轮,MAPE为9.09%,还需要进一步完善。
IV. 源码及数据
源码及数据我放在了GitHub上,下载时请随手给个follow和star,感谢!
LSTM-MultiStep-Forecasting