YoloX | SimOTA标签匹配策略
如有错误,恳请指出。
文章目录
- 1. SimOTA简要介绍
- 2. SimOTA具体实现
- 3. SimOTA实现代码
在之前阅读YoloX的时候已经做过一次笔记,论文主要的重点与更改的地方,亮点介绍了一遍,见:论文阅读笔记 | 目标检测算法——YOLOX
但对于YoloX的核心重点,其正负样本的匹配策略在当时其实只是一知半解,现在重新记录一下YoloX所提出的SimOTA标签匹配策略。
以下内容是建立在参考内容整理之上的总结。
1. SimOTA简要介绍
SimOTA可以理解为是一种匹配策略的方法,可以看成是一个最优传输的问题。举一个通俗易懂的例子就是,有2个分配基地与6个周围城市,现在需要考虑一个最优的配送方式来确保分配东西到这几个城市的运输成本是最低的。而对于目标检测来说,这个最优传输问题也就是一个最优分配问题,如何实现把这些anchor point分配给gt的代价(cost)是最低的。这个代价就是iou损失,分类损失等内容。
在论文中,cost的公式为:
c i j = L i j c l s + λ L i j r e g c_{ij} = L_{ij}^{cls} + \lambda L_{ij}^{reg} cij=Lijcls+λLijreg
也就是说,对于一张特征图上的所有anchor point来说,整个匹配的策略代价是所有特征点与每一个gt box所产生的分类损失与回归损失之和。但是实际代码中的cost计算公式是稍微不一样的:
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_ious_loss
+ 100000.0 * (~is_in_boxes_and_center)
)
- pair_wise_cls_loss就是每个样本与每个GT之间的分类损失 L i j c l s L_{ij}^{cls} Lijcls
- pair_wise_ious_loss是每个样本与每个GT之间的回归损失 L i j r e g L_{ij}^{reg} Lijreg
- is_in_boxes_and_center代表那些落入GT Bbox与fixed center area交集内的样本,即上图中橙色勾对应的样本,然后这里进行了取反
~表示不在GT Bbox与fixed center area交集内的样本(非橙色样本),即上图中黑色勾对应的样本。接着又乘以100000.0,也就是说对于GT Bbox与fixed center area交集外的样本cost加上了一个非常大的数,这样在最小化cost过程中会优先选择GT Bbox与fixed center area交集内的样本。
SimOTA所需要考虑的问题就是,如何筛选出优质的正样本来匹配gt box,从而减少这个匹配过程所产生的代价(cost)
当然,如果是按照我们刚才所想的对整副特征图来筛选,来减少这个匹配代价是没有意义的,因为这样的cost会很大。一个很容易想到的点是类似FCOS方法一样,先进行一个预筛选,gt box的中心区域更有可能筛选出优质的正样本使得边界回归损失与分类损失较小,也就是匹配策略中的cost教小。(关于FCOS详细介绍见:论文阅读笔记 | 目标检测算法——FCOS算法)
那么,进行预筛选之后,cost就会下降很多,从而可以在这个限定区域内进行进一步的筛选,从而获得最后的筛选样本(anchor point)。
SimOTA具体的做法是首先计算每个目标Cost最低的10特征点,然后把这十个特征点对应的预测框与真实框的IOU加起来求得最终的k。这一部分就是对框进行筛选。首先进行初步的框筛选:
- 根据中心点判断:寻找anchor box中心点,落在gt_box矩形范围内的anchors
- 根据目标框来预测:以gt中心点为基准,设置边长为5的正方形,挑选正方形内所有的锚框。
经过初步筛选后则可以精细化筛选:
- 初筛正样本信息提取
- Loss函数计算
- cost成本计算
- SimOTA求解
下面对SimOTA实现的匹配策略进行详细介绍。
2. SimOTA具体实现

详细流程:
-
首先需要对anchor point进行一个预筛选。在SimOTA中,首先会对gt boxs位置范围内的所有anchor point进行框选,其次在gt boxs位置范围内设定一个5x5大小的box,称之为
fixed center area,如下图所示。这些被gt box与fixed center area框选出来的anchor point就是预筛选的目标。
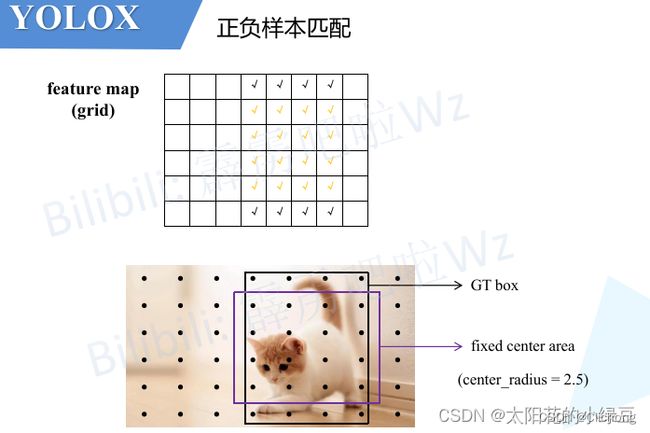
当然,如果那么此时如果有多个gt box,就会有多个gt box区域范围以及fixed center area范围,anchor point的数量也随之成倍的增加。 -
针对这些设计多个gt box所获取的anchor point,现在假设有3个gt box的范围中涵盖了1000个anchor point。那么,现在需要做的就是分别对每一个anchor point计算其相对与每一个gt box的分类损失cls_loss、位置损失iou_loss。从而根据分类损失cls_loss、位置损失iou_loss获取cost矩阵以及iou矩阵(而从上面的公式可以发现,其实iou在计算cost的过程中是获取到了,不需要进行重复计算)。
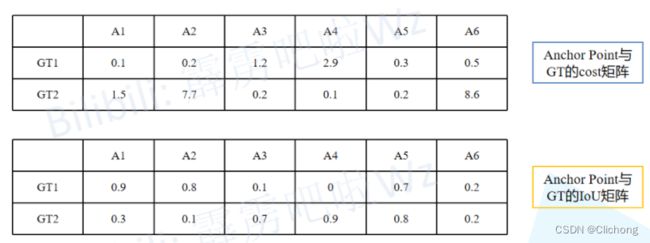
其中这里由于分别计算了每个anchor point与每个gt box的cost,注意到不处于fixed center area区域的anchor point与gt box匹配的代价是极大的,因为第三项会乘上一个100000的权重因子,那么就可以确保匹配的点肯定是在代价较少的fixed center area区域中选择。 -
那么,现在就可以根据所获得的iou矩阵来选择出n_candidate_k个iou最大的候选框,topk_ious(n_candidate_k是取10和Anchor Point数量之间的最小值)。需要需要注意,这里的iou矩阵只是为了确定dynamic_k,也就是动态的选择为每一个gt box赋予多少个正样本。
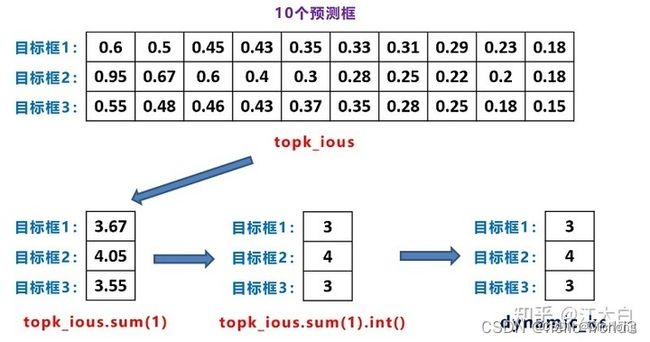
当获取到每个gt box最高的前k个iou数值时,这里会对他们进行一个求和处理。这里获取出来的值是处于[0, n_candidate_k]之间的。如果是浮点数值,则对其进行向下取整处理。所获取的最后数值dynamic_k,就是每个针对每个gt box分配的anchor point数。
其中对iou矩阵进行topk,可以获取与每一个gt box的iou最大的前k的iou值与索引的,只是这里只需要返回最大的数值而不需要要返回索引。代码测试如下:
import torch
import numpy as np
chart = [[0.8, 0.1, 0.7, 0.6],
[0.1, 0.9, 0.3, 0.3],
[0.2, 0.1, 0.6, 0.5]]
chart = np.array(chart)
chart.sum(axis=0)
# 输出:array([1.1, 1.1, 1.6, 1.4])
torch.topk(chart, k=2, dim=1)
# 输出:
torch.return_types.topk(
values=tensor([[0.8000, 0.7000],
[0.9000, 0.3000],
[0.6000, 0.5000]], dtype=torch.float64),
indices=tensor([[0, 2],
[1, 3],
[2, 3]]))
topk_ious, topk_indices = torch.topk(chart, k=2, dim=1)
# topk_ious为:
tensor([[0.8000, 0.7000],
[0.9000, 0.3000],
[0.6000, 0.5000]], dtype=torch.float64)
-
现在对每个gt box进行动态的缺点分配的anchor point数之后,就根据cost矩阵来确定。这里会对每一个gt box来分配cost值最低的dynamic_k个anchor point。对于代码中的公式也可以知道,只有位于当前gt box的
fixed center area内区域的anchor point所对应的cost才会比较低,其余的gt box内的剩余地方因为分配的权重过大,所以cost必定很大,而不再gt box的cost就更大了。
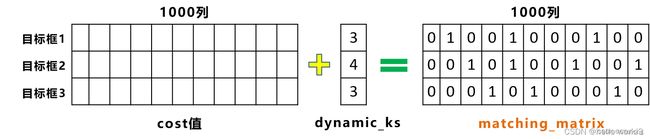
根据cost值的挑选出来的几个最低anchor point,可以再构建一个Anchor Point分配矩阵,记录每个GT对应哪些正样本,对应正样本的位置标1,其他位置标0。如上图所示。 -
对于重复预测框对应不同的gt目标框,即第五列所对应的候选框,被目标检测框1和2,都进行关联。对这两个位置,还要使用cost值进行对比,选择较小的值,再进一步筛选。确保一个gt只分配给一个anchor point。
-
根据以上流程就能找到所有的正样本以及正样本对应的GT了,那么剩下的Anchor Point全部归为负样本。对筛选预测框进行loss计算,要注意的是这里的iou_loss和cls_loss,只针对目标框和筛选出的正样本预测框进行计算,而obj_loss还是针对所有的anchor point(包含所有的正样本与负样本)
L o s s = 1 N p o s ( L c l s + λ L r e g + L o b j ) Loss = \frac{1}{N_{pos}}(L_{cls} + \lambda L_{reg} + L_{obj}) Loss=Npos1(Lcls+λLreg+Lobj)
其中: L c l s L_{cls} Lcls代表分类损失; L r e g L_{reg} Lreg代表定位损失; L o b j L_{obj} Lobj代表obj损失; λ \lambda λ代表定位损失的平衡系数,源码中设置是5.0; N p o s N_{pos} Npos代表被分为正样的Anchor Point数。
3. SimOTA实现代码
详细见参考资料5.
- 1、get_losses函数:
①准备simOTA计算所需的数据。
②遍历每张图片,调用get_assignments进行正负样本分配。
③根据正负样本结果计算loss。
def get_losses(
self, imgs, x_shifts, y_shifts, expanded_strides, labels, outputs, origin_preds, dtype,
):
# 将特征图切分成bbox,obj,cls
bbox_preds = outputs[:, :, :4] # shape:[batch, n_anchors_all, 4]
obj_preds = outputs[:, :, 4].unsqueeze(-1) # shape:[batch, n_anchors_all, 1]
cls_preds = outputs[:, :, 5:] # shape:[batch, n_anchors_all, n_cls]
# calculate targets
mixup = labels.shape[2] > 5
if mixup:
label_cut = labels[..., :5]
else:
label_cut = labels
nlabel = (label_cut.sum(dim=2) > 0).sum(dim=1) # number of objects
total_num_anchors = outputs.shape[1]
x_shifts = torch.cat(x_shifts, 1) # [1, n_anchors_all],相当于每个anchor的中心点相较于输入尺寸的x坐标
y_shifts = torch.cat(y_shifts, 1) # [1, n_anchors_all]
expanded_strides = torch.cat(expanded_strides, 1) # shape:[num_anchors],数值是每个anchor相较于输入尺寸减小的strides
……
# 一张图片一张图片计算
for batch_idx in range(outputs.shape[0]):
num_gt = int(nlabel[batch_idx])
num_gts += num_gt
if num_gt == 0:
…………
else:
# 对gt切分成gt_bboxes,gt_classes
gt_bboxes_per_image = labels[batch_idx, :num_gt, 1:5]
gt_classes = labels[batch_idx, :num_gt, 0]
bboxes_preds_per_image = bbox_preds[batch_idx]
try:
# ---------------------------关键代码-----------------------------------
# ---------------------------------------------------------------------
# label assignment
gt_matched_classes, fg_mask, pred_ious_this_matching, matched_gt_inds, num_fg_img = self.get_assignments( # noqa
batch_idx, num_gt, total_num_anchors, gt_bboxes_per_image, gt_classes,
bboxes_preds_per_image, expanded_strides, x_shifts, y_shifts,
cls_preds, bbox_preds, obj_preds, labels, imgs,
)
# ---------------------------------------------------------------------
# ---------------------------------------------------------------------
except RuntimeError:
…………
torch.cuda.empty_cache()
num_fg += num_fg_img
cls_target = F.one_hot(
gt_matched_classes.to(torch.int64), self.num_classes
) * pred_ious_this_matching.unsqueeze(-1)
obj_target = fg_mask.unsqueeze(-1)
reg_target = gt_bboxes_per_image[matched_gt_inds]
if self.use_l1:
……
……
# loss计算
num_fg = max(num_fg, 1)
loss_iou = (self.iou_loss(bbox_preds.view(-1, 4)[fg_masks], reg_targets)).sum() / num_fg
loss_obj = (self.bcewithlog_loss(obj_preds.view(-1, 1), obj_targets)).sum() / num_fg
loss_cls = (
self.bcewithlog_loss(cls_preds.view(-1, self.num_classes)[fg_masks], cls_targets)
).sum() / num_fg
# loss合并
reg_weight = 5.0
loss = reg_weight * loss_iou + loss_obj + loss_cls + loss_l1
return loss, reg_weight * loss_iou, loss_obj, loss_cls, loss_l1, num_fg / max(num_gts, 1)
- 2、get_assignments函数:
①调用get_in_boxes_info确定候选区域。
②计算anchor与gt的iou。
③在候选区域内计算cost。
④调用dynamic_k_matching分配正负样本
def get_assignments(
self, batch_idx, num_gt, total_num_anchors, gt_bboxes_per_image, gt_classes,
bboxes_preds_per_image, expanded_strides, x_shifts, y_shifts,
cls_preds, bbox_preds, obj_preds, labels, imgs, mode="gpu",
):
……
# ----------确定论文中所说的a fixed center region,即缩小anchor考察范围。--------------------
# -------------------------------------------------------------------------------------
# fg_mask shape:[num_anchors]
# is_in_boxes_and_center shape:[num_gt, num_in_anchors]
fg_mask, is_in_boxes_and_center = self.get_in_boxes_info(
gt_bboxes_per_image, expanded_strides, x_shifts, y_shifts, total_num_anchors, num_gt,
)
# -------------------------------------------------------------------------------------
# -------------------------------------------------------------------------------------
bboxes_preds_per_image = bboxes_preds_per_image[fg_mask]
cls_preds_ = cls_preds[batch_idx][fg_mask]
obj_preds_ = obj_preds[batch_idx][fg_mask]
num_in_boxes_anchor = bboxes_preds_per_image.shape[0]
……
# -------------------------------------计算cost-----------------------------------------
# -------------------------------------------------------------------------------------
# 计算所有的gt和bboxes的iou,iou用于dynamic_k的确定
pair_wise_ious = bboxes_iou(
gt_bboxes_per_image, bboxes_preds_per_image, False
)
gt_cls_per_image = (
F.one_hot(gt_classes.to(torch.int64), self.num_classes).float()
.unsqueeze(1).repeat(1, num_in_boxes_anchor, 1)
)
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)
……
# cost中Lcls和Lreg计算
cls_preds_ = (
cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
* obj_preds_.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
)
pair_wise_cls_loss = F.binary_cross_entropy(
cls_preds_.sqrt_(), gt_cls_per_image, reduction="none"
).sum(-1)
del cls_preds_
cost = (
pair_wise_cls_loss # Lcls
+ 3.0 * pair_wise_ious_loss # λ*Lreg,实际代码中把λ设置为了3
+ 100000.0 * (~is_in_boxes_and_center) # 把不在考虑范围内的anchor置为很大的数值
)
# -------------------------------------------------------------------------------------
# -------------------------------------------------------------------------------------
# -----------------给每个gt分配正样本,同时确定每个gt要分配几个正样本--------------------------
# -------------------------------------------------------------------------------------
(
num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds
) = self.dynamic_k_matching(cost, pair_wise_ious, gt_classes, num_gt, fg_mask)
del pair_wise_cls_loss, cost, pair_wise_ious, pair_wise_ious_loss
# -------------------------------------------------------------------------------------
# -------------------------------------------------------------------------------------
……
return gt_matched_classes, fg_mask, pred_ious_this_matching, matched_gt_inds, num_fg
- 3、get_in_boxes_info函数:
确定候选区域
def get_in_boxes_info(
self, gt_bboxes_per_image, expanded_strides, x_shifts, y_shifts, total_num_anchors, num_gt,
):
expanded_strides_per_image = expanded_strides[0] # shape:[num_anchors]
x_shifts_per_image = x_shifts[0] * expanded_strides_per_image #每个anchor在原图中的偏移量
y_shifts_per_image = y_shifts[0] * expanded_strides_per_image
x_centers_per_image = (
(x_shifts_per_image + 0.5 * expanded_strides_per_image)
.unsqueeze(0)
.repeat(num_gt, 1)
) # [n_anchor] -> [n_gt, n_anchor]
y_centers_per_image = (
(y_shifts_per_image + 0.5 * expanded_strides_per_image)
.unsqueeze(0)
.repeat(num_gt, 1)
)
# ------每个gt的left,right,top,bottom与anchor进行比较,计算anchor中心点是否在gt中,得到is_in_boxes_all(shape:[num_anchors])---------------
# -------------------------------------------------------------------------------------
# 这里计算出了gt的坐标,是相较于原图的
gt_bboxes_per_image_l = (
(gt_bboxes_per_image[:, 0] - 0.5 * gt_bboxes_per_image[:, 2])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
gt_bboxes_per_image_r = (
(gt_bboxes_per_image[:, 0] + 0.5 * gt_bboxes_per_image[:, 2])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
gt_bboxes_per_image_t = (
(gt_bboxes_per_image[:, 1] - 0.5 * gt_bboxes_per_image[:, 3])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
gt_bboxes_per_image_b = (
(gt_bboxes_per_image[:, 1] + 0.5 * gt_bboxes_per_image[:, 3])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
# [num_gt, num_anchors]
# 用每个anchor中心减去gt的坐标
b_l = x_centers_per_image - gt_bboxes_per_image_l
b_r = gt_bboxes_per_image_r - x_centers_per_image
b_t = y_centers_per_image - gt_bboxes_per_image_t
b_b = gt_bboxes_per_image_b - y_centers_per_image
bbox_deltas = torch.stack([b_l, b_t, b_r, b_b], 2)
# 这里求出的是,哪些anchor的中心点是在gt内部的
is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0
is_in_boxes_all = is_in_boxes.sum(dim=0) > 0
# -------------------------------------------------------------------------------------
# -------------------------------------------------------------------------------------
# ---------每个gt的cx与cy向外扩展2.5*expanded_strides距离得到left_b,right_b,top_b,bottom_b,与anchor进行比较,计算anchor中心点是否包含在left_b,right_b,top_b,bottom_b中,得到is_in_centers_all(shape:[num_anchors])-------------
# -------------------------------------------------------------------------------------
# in fixed center
center_radius = 2.5
gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(
1, total_num_anchors
) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(
1, total_num_anchors
) + center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors
) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors
) + center_radius * expanded_strides_per_image.unsqueeze(0)
c_l = x_centers_per_image - gt_bboxes_per_image_l
c_r = gt_bboxes_per_image_r - x_centers_per_image
c_t = y_centers_per_image - gt_bboxes_per_image_t
c_b = gt_bboxes_per_image_b - y_centers_per_image
center_deltas = torch.stack([c_l, c_t, c_r, c_b], 2)
is_in_centers = center_deltas.min(dim=-1).values > 0.0
is_in_centers_all = is_in_centers.sum(dim=0) > 0
# -------------------------------------------------------------------------------------
# -------------------------------------------------------------------------------------
# in boxes and in centers
# shape:[num_anchors]
is_in_boxes_anchor = is_in_boxes_all | is_in_centers_all # 上述两个条件只要满足一个,就成为候选区域。注意!!!这里是“|”求或
# !!!shape:[num_gt, num_in_boxes_anchor],注意:这里是每一个gt与每一个候选区域的关系
# 这里一个anchor可能与多个gt存在候选关系
is_in_boxes_and_center = (
is_in_boxes[:, is_in_boxes_anchor] & is_in_centers[:, is_in_boxes_anchor] # 注意!!!这里是“&”求与
)
return is_in_boxes_anchor, is_in_boxes_and_center
- 4、dynamic_k_matching函数:
①使用iou确定dynamic_k。
②为每个gt取cost排名最小的前dynamic_k个anchor作为正样本,其余为负样本。
def dynamic_k_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):
# Dynamic K
# --------------------dynamic_k确定逻辑---------------------------
# ---------------------------------------------------------------
matching_matrix = torch.zeros_like(cost)
ious_in_boxes_matrix = pair_wise_ious
n_candidate_k = 10
# 取预测值与gt拥有最大iou前10名的iou总和作为dynamic_k
topk_ious, _ = torch.topk(ious_in_boxes_matrix, n_candidate_k, dim=1)
# min=1,即把dynamic_ks限制最小为1,保证一个gt至少有一个正样本
# 刚开始训练时候,由于预测基本不准,导致dynamic_k基本上都是1
dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1)
for gt_idx in range(num_gt):
# 取cost排名最小的前dynamic_k个anchor作为postive
_, pos_idx = torch.topk(
cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False
)
matching_matrix[gt_idx][pos_idx] = 1.0
# ---------------------------------------------------------------
# ---------------------------------------------------------------
del topk_ious, dynamic_ks, pos_idx
anchor_matching_gt = matching_matrix.sum(0)
# 针对一个anchor匹配了2个gt情况进行处理
if (anchor_matching_gt > 1).sum() > 0:
cost_min, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
num_fg = fg_mask_inboxes.sum().item()
fg_mask[fg_mask.clone()] = fg_mask_inboxes
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
gt_matched_classes = gt_classes[matched_gt_inds]
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[fg_mask_inboxes]
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds
参考资料:
1. YOLOX的深入理解
2. 如何评价旷视开源的YOLOX,效果超过YOLOv5?
3. simOTA标签匹配策略详解(专栏试读)
4. YOLOX网络结构详解
5. YOLOX深度解析(二)-simOTA详解