线性代数(MIT)
Chapter 1 Introduction on Vectors
1.1 Vectors and Linear Combinations
1.2 The dot product v ⋅ w v · w v⋅w of two vectors and the length ∣ ∣ v ∣ ∣ = v ⋅ v \mid\mid v \mid\mid = \sqrt{v · v} ∣∣v∣∣=v⋅v
1.3 Matrices A A A, linear equations A x = b Ax = b Ax=b, solutions x = A − 1 b x = A^{-1} b x=A−1b.
Chapter 2 Matrix
- 对 A x = b Ax=b Ax=b,从row picture的角度看,可以看作n条直线交于一点,解为该点的横坐标。从column picture的角度看,可以看作n个列向量的组合,得到b。在n-dimensions的超平面空间中,求交于一点比较困难,向量的组合比较简单。
- if A x = 0 Ax=0 Ax=0,also U x = 0 Ux=0 Ux=0,因为消元改变的是矩阵的列空间,不改变矩阵的行空间,所以解不变。
- 证明 ( A B ) C = A ( B C ) (AB)C=A(BC) (AB)C=A(BC)
Proof
∑ ∑ A i k B k l C l j \sum\sum A_{ik}B_{kl}C_{lj} ∑∑AikBklClj

- 矩阵 S S S可以看作一个无向图/有向图(无向图则对称),对矩阵 S n S^n Sn而言,其中的每一个元素 a i j a_{ij} aij可以看作从 i i i出发经过 n n n步到达 j j j。1.就 S S S举例,比较显然。2.就 S 2 S^2 S2举例, ( S 2 ) i j = s i 1 s 1 j + s i 2 s 2 j + . . . s i k s k j (S^2)_{ij}=s_{i1}s_{1j}+s_{i2}s_{2j}+...s_{ik}s_{kj} (S2)ij=si1s1j+si2s2j+...sikskj,如果 s i 1 = 0 s_{i1}=0 si1=0即 s s s无法到达1,那么这一项就为0。 ( S 2 ) i j (S^2)_{ij} (S2)ij可以看作 i → k → j i\rightarrow k\rightarrow j i→k→j长度为2的路线的个数和。3. ( S n ) i j 可 以 看 作 (S^n)_{ij}可以看作 (Sn)ij可以看作 i → k → j i\rightarrow k\rightarrow j i→k→j长度为n的路线的个数和。
- 什么时候 A B = B A AB=BA AB=BA当 A 、 B A、B A、B为对称矩阵。
2.5 Inverse Matrices
- A − 1 A^{-1} A−1可以看作 A A A空间变换的逆过程
- 左逆和右逆矩阵是同一个矩阵
- x x x是零向量时, A x = 0 , A − 1 Ax=0,A^{-1} Ax=0,A−1存在。 x = A − 1 0 x=A^{-1}0 x=A−10如果 x x x is nonzero vector,不存在一个矩阵变换把零向量变成非零向量。同时,这也意味着,对 A A A中的列向量而言,不存在一个组合使得 A x = 0 , A Ax=0,A Ax=0,A中的列是无关列, det ( A ) ≠ 0 , r a n k ( A ) = n \det(A)\neq0,rank(A)=n det(A)=0,rank(A)=n
2.6 Elimination = Factorization: A = L U A = LU A=LU
-
线性代数的很多思想,关键就是Factorization(因式分解)
-
L L L是 A − U A-U A−U的逆过程
-
When can we predict zeros in L and U?
When a row of A starts with zeros, so does that row of L.
When a column of A starts with zeros, so does that column of U. -
The triangular factorization can be written A = L U A= LU A=LU or A = L D U A= LDU A=LDU.
-
The matrix L L L contains our memory of Gaussian elimination. L L L保存了因式分解的记忆。
-
对 A x = b Ax=b Ax=b Solve L c = b Lc = b Lc=b and then solve U x = c Ux = c Ux=c.
-
时间复杂度: A A A的消元的过程
1.从2-n行每一个entry都减row 1*某个数, c o s t = ( n − 1 ) ∗ n 个 m u l t i p l i c a t i o n s a n d ( n − 1 ) ∗ n 个 s u b t r a c t i o n s . cost=(n-1)*n个 multiplications and (n-1)*n个 subtractions. cost=(n−1)∗n个multiplicationsand(n−1)∗n个subtractions.
2.一次类推,一共需要 c o s t = n 2 + ( n − 1 ) 2 + . . . 1 = 1 / 3 n 3 cost=n^2+(n-1)^2+...1=1/3n^3 cost=n2+(n−1)2+...1=1/3n3, b b b需要变化 n 2 n^2 n2次但是在实际过程中, A A A可能是稀疏矩阵,通过上述3, A = L U A= LU A=LU算的更快
-
Factor : There are ½ ( n 3 − n ) ½ ( n^3 - n) ½(n3−n) multiplications and subtractions on the left side.
-
Solve : There are n 2 n^2 n2 multiplications and subtractions on the right side.
-
For a band matrix, change ½ ( n 3 − n ) ½ ( n^3 - n) ½(n3−n) to n w 2 nw^2 nw2 and change n 2 n^ 2 n2 to 2 w n 2wn 2wn.
2. 7 Transposes and Permutations
- ( A B ) T = B T A T (AB)^T=B^TA^T (AB)T=BTAT,当 B = x B=x B=x时 A x Ax Ax是 A A A的列组合, x T A T x^TA^T xTAT是 A T A^T AT的行组合,这二者是一样的组合
- The transpose puts the rows of A A A into the columns of A T A^T AT. Then ( A T ) i j = A j i (A^T )_{ij} = A_{ji} (AT)ij=Aji
- When S S S is symmetric ( S T = S S^T= S ST=S), its L D U LDU LDU factorization is symmetric: S = L D L T S = LDL^T S=LDLT.
- A permutation matrix P has a 1 in each row and column, and p T = p − 1 p^T = p^{-1} pT=p−1置换矩阵,可以对矩阵进行行变换。此定理可以用在FFT算法中。
- There are n ! n! n! permutation matrices of size n. Half even, half odd.
- If A A A可逆 then a permutation P will reorder its rows for PA= LU.
Chapter 3
3.1 Spaces of vectors
-
DEFINITION:The space R n R^n Rn consists of all column vectors v v v with n n n components.
-
什么是向量空间:空间内任意两个向量相加或相乘后仍在空间内。(重点注意零点需要在空间内)
-
子空间:i. v + w v + w v+w is in the subspace ii: c v cv cv is in the subspace.(一定包含0点 )
-
DEFINITION The column space consists of all linear combinations of the columns . The combinations are all possible vectors A x Ax Ax. They fill the column space C ( A ) C(A) C(A). A x = b , b Ax=b,b Ax=b,b需要出现在 A A A的列空间中才有解
-
the r a n k ( A ) rank(A) rank(A)可以看作线性系统中true size,因为很多行可以通过消元去掉
3.2 The Nullspace of A: Solving A x = 0 Ax=0 Ax=0 and R x = 0 Rx=0 Rx=0
-
零空间(Nullspace):The nullspace N ( A ) N(A) N(A) in R n R^n Rn contains all solutions x to A x = 0 Ax = 0 Ax=0. This includes x = 0 x = 0 x=0.在 R n R^n Rn空间内,所有使得 A x = 0 Ax = 0 Ax=0的 x x x的线性组合,其中当然包括 x = 0 x = 0 x=0
-
秩(rank):A->U(upper matrix)->R,rank为U中pivots(主元的个数),在 A x = 0 Ax=0 Ax=0中,消元并不会影响 x x x的解。mean:只有r个方程起作。如果某一行通过消元后全是0,则意味着可表示为其他行的线性组合,
-
Pivot and free coloums(非主元的叫做自由列):
- free coloums:可以自由分配数值=n-r,free coloums没有主元,可以通过其他列的线性组合得到,因此解的维度为r
- pivot coloums:主变量,主元=r
-
special solutions:给free variables分配特定的值得到的特定的解,通过特解可以构建出整个null space。例如 x = c [ − 2 1 0 0 ] + d [ 2 0 − 2 1 ] x=c\left[ \begin{matrix} -2\\1\\0\\0 \end{matrix} \right]+d\left[ \begin{matrix} 2\\0\\-2\\1 \end{matrix} \right] x=c⎣⎢⎢⎡−2100⎦⎥⎥⎤+d⎣⎢⎢⎡20−21⎦⎥⎥⎤两个向量为特解,此方程可表示为任意的线性组合
-
R(行最简行矩阵):主元所在的行为该列第一个非零行 x = [ 1 2 2 2 0 0 2 4 0 0 0 0 ] → [ 1 2 0 − 2 0 0 1 2 0 0 0 0 ] x=\left[ \begin{matrix} 1&2&2&2\\0&0&2&4\\0&0&0&0 \end{matrix} \right]→\left[ \begin{matrix} 1&2&0&-2\\0&0&1&2\\0&0&0&0 \end{matrix} \right ] x=⎣⎡100200220240⎦⎤→⎣⎡100200010−220⎦⎤经过列变化可得 [ I F ] \left[ \begin{matrix} I&F \end{matrix} \right] [IF](F为free coloums) [ I F ] [ x p i v o t x f r e e ] = 0 → x p i v o t = − F x f r e e \left[ \begin{matrix} I&F \end{matrix} \right][x_{pivot} x_{free}]=0→x_{pivot}=-Fx_{free} [IF][xpivot xfree]=0→xpivot=−Fxfree,令 x f r e e = I x_{free}=I xfree=I得 x p i v o t = − F x_{pivot}=-F xpivot=−F
3.3 Independence, Basis and Dimension
- 解 x x x的维数=x component的个数,4行=4维
- linear independence:线性组合不为0。 The columns are independent when the nullspace N(A) contains only the zero vector.
- span(生成):A set of vectors spans a space if their linear combinations fill the space.
- basis:一组无关向量和生成空间(spaning)
- dimension:the number of vectors basis基向量的个数
- rank(A)是列空间的维数,不是A的维数。
3.4 Dimensions of the Four Subspaces
when A A A is m m mx n n n, r a n k ( A ) = r rank(A)=r rank(A)=r
- 列空间 C ( A ) C(A) C(A)——coloums space in Rᵐ(m维向量) dim of C(A)=r 有r个主列,基向量个数为r
- 零空间 N ( A ) N(A) N(A)——null space in Rⁿ(有n维向量且是 A x = 0 Ax=0 Ax=0的解) n-r个自由变量构成零空间的基础解,因此dim=n-r.所有A基础解的个数=n-r
- 行空间 R ( A ) R(A) R(A)——row space:A中所有行的线性组合=C(Aᵀ)in Rⁿ dim of R(A)=r
- 左零空间 N ( A ᵀ ) N(Aᵀ) N(Aᵀ)——left null space dim=m-r
2个问题:how to produce basis? what’s the dimension?
行变化会改变列空间,不会改变行空间, A x = 0 ⇔ R x = 0 Ax=0 \Leftrightarrow Rx=0 Ax=0⇔Rx=0,因为 A x = 0 ⇔ E − 1 R x = 0 Ax=0 \Leftrightarrow E^{-1}Rx=0 Ax=0⇔E−1Rx=0,如果 R x Rx Rx任何一行不为0,经过行变化后也不为0。又 C ( R ) C(R) C(R)经过一个行变化得到 C ( A ) C(A) C(A),一次改变了行空间
5. 秩1矩阵可表示为 A = u v T A=uv^T A=uvT(每一行可看作唯一一行的组合)
Chapter 4 Orthogonality
4.1正交向量与正交子空间
- Q = [ q 1 , q 2 , . . . , q n ] Q=[q_1,q_2,...,q_n] Q=[q1,q2,...,qn]如果 q i ⋅ q j = 0 , q i ⋅ q i = 1 q_i⋅ q_j=0,q_i⋅ q_i=1 qi⋅qj=0,qi⋅qi=1,则称Q为标准正交矩阵。 Q T Q = I Q^TQ=I QTQ=I
- 当两个空间的任意向量 v , w v,w v,w都有 v ⋅ w = 0 v·w=0 v⋅w=0时,这两个空间正交。注意,2个互相垂直的平面不是正交平面,因为两个平面的交线与自己相乘不为0.
- 矩阵 A A A的行空间和零空间正交,因为 A x = 0 → a i ⋅ x = 0 , A Ax=0 \rightarrow a_i·x=0,A Ax=0→ai⋅x=0,A中的每一行和 x x x的点积都为0。
4.2 Projections
-
当维度为1是, x ^ = a ⊺ b a ⊺ a \hat x=\frac {\mathbf{a}^\intercal b} {\mathbf{a}^\intercal \mathbf{a}} x^=a⊺aa⊺b,投影 p = a a ⊺ a ⊺ a b p=\frac {\mathbf{a}\mathbf{a}^\intercal} {\mathbf{a}^\intercal \mathbf{a}}b p=a⊺aaa⊺b,投影矩阵 P = a a ⊺ a ⊺ a P=\frac {\mathbf{a}\mathbf{a}^\intercal} {\mathbf{a}^\intercal \mathbf{a}} P=a⊺aaa⊺.
-
求解方式,以n为为例
A x = b Ax=b Ax=b无解,假设 A x ^ 最 接 近 b A \hat x最接近b Ax^最接近b,则 A T ( b − A x ^ ) = 0 ⇔ A T A x ^ = A T b , x ^ = ( A T A ) − 1 A T b A^T(b-A \hat x)=0 \Leftrightarrow A^TA\hat x=A^Tb,\hat x=(A^TA)^{-1}A^Tb AT(b−Ax^)=0⇔ATAx^=ATb,x^=(ATA)−1ATb.
p = A x ^ = A ( A T A ) − 1 A T b , P = A ( A T A ) − 1 A T p=A\hat x=A(A^TA)^{-1}A^Tb,P=A(A^TA)^{-1}A^T p=Ax^=A(ATA)−1ATb,P=A(ATA)−1AT -
A A A和 A T A A^TA ATA有相同的nullspace
1.如果 A x = 0 Ax=0 Ax=0,则 A T A x = 0 A^TAx=0 ATAx=0,有相同的x
2.如果 A T A x = 0 A^TAx=0 ATAx=0,则 x T A T A x = 0 ⇔ ∣ ∣ A x ∣ ∣ 2 = 0 , A x = 0 x^TA^TAx=0 \Leftrightarrow ||Ax||^2=0,Ax=0 xTATAx=0⇔∣∣Ax∣∣2=0,Ax=0
4.3 Least Squares Approximations
4.4 Orthonormal Bases and Gram-Schmidt
-
If Q Q Q is also square, then Q Q T = I QQ^T = I QQT=I and Q T = Q − 1 Q^T = Q^{-1} QT=Q−1. Q is an “orthogonal matrix”.
-
标准正交列向量的优势:如果Q是列向量标准正交,那投影到Q的列空间的投影矩阵为 P = Q ( Q T Q − 1 ) Q T = Q Q T P=Q(Q^TQ^{-1})Q^T=QQ^T P=Q(QTQ−1)QT=QQT这种情况会降低很多运算量。如果 Q 为方阵,则 P=I,因为 Q 的列向量张成了整个空间,投影过程不会对向量有任何改变。在很多复杂问题中使用标准正交向量之后都变得简单。用 Q Q Q代替 A A A如果基为标准正交,则方程 A T A x ^ = A T b A^TA \hat x =A^Tb ATAx^=ATb 的解变为 x ^ = Q T b \hat x =Q ^Tb x^=QTb, x ^ i \hat x_i x^i的分量 x ^ i \hat x_i x^i 就等于 q i T b q_i^Tb qiTb。
-
施密特正交化 Gram-Schmidt
Given a,b,c


-
The Factorization A = QR

a只和 q 1 q_1 q1有关,b只和 q 1 , q 2 q_1,q_2 q1,q2有关。。。以此类推,R 在 Q 右侧相当于对 Q 做列操作,即 A 的列向量是 Q 列向量的线性组合,而 Q 为 A 列空间的一组标准正交基,
则 R 的元素实际上是 A 的列向量基于 Q 这组标准正交基的权。。
换句话说 R = Q T A R=Q^TA R=QTA好处是计算快,比如最小二乘法 A T A = ( Q R ) T Q R = R T Q T Q R = R T R , A T A x = A T b A^TA = (QR)^TQR = R^TQ^TQR = R^T R,A^TAx = A^Tb ATA=(QR)TQR=RTQTQR=RTR,ATAx=ATb simplifies to R T R x = R T Q T b R^TRx = R^TQ^T b RTRx=RTQTb. Then finally we reach R x = Q T b Rx = Q^Tb Rx=QTb,上三角矩阵,用回代解特别快。采用矩阵的 QR 分解来帮助求解 Ax=b 的问题,最大的优势是提高了数值的稳定性。
ps:一般不太用斯密特正交化,用分解或者放射旋转更快
Chapter 5 Determinants
它将尽可能多的矩阵信息压缩在这一个数里
- det(AB)=det(A)det(B),互换两行覆盖改变用P*A理解。
-
行列式的三条基本性质
1.det(I)=1。
2.如果交换行列式的两行,则行列式的数值会反号。
3.行列式是“矩阵的行”的线性函数。
4.行列式的几何意义是什么呢?概括说来有两个解释:一个解释是行列式就是行列式中的行或列
向量所构成的超平行多面体的有向面积或有向体积;另一个解释是矩阵 A 的行列式 detA 就是线性
变换 A 下的图形面积或体积的伸缩因子。

Chapter 6 Eigenvalues and Eigenvectors
可以把矩阵的操作变成一个简单的参数 λ \lambda λ
6.1概念
6.1.1Det and trace
λ 1 λ 2 . . . λ n \lambda_1\lambda_2...\lambda_n λ1λ2...λn= d e t ( A ) det(A) det(A),
∑ λ i \sum\lambda_i ∑λi=对角线上的和
Proof
对于 n n n阶方阵 A A A, ∣ A − λ I ∣ = 0 |A-\lambda I|=0 ∣A−λI∣=0求矩阵的特征值。 ∣ A − λ I ∣ |A-\lambda I| ∣A−λI∣最终可表示为:
( λ − λ 1 ) ( λ − λ 2 ) . . . ( λ − λ 3 ) = λ 1 . . . λ n + ( − 1 ) 1 ( λ 1 + . . . + λ n ) λ + . . . + ( − 1 ) n − 1 ( λ 1 + . . . + λ n ) λ n − 1 + ( − 1 ) n λ n (\lambda-\lambda_1)(\lambda-\lambda_2)...(\lambda-\lambda_3)=\lambda_1...\lambda_n+(-1)^1(\lambda_1+...+\lambda_n)\lambda+...+(-1)^{n-1}(\lambda_1+...+\lambda_n)\lambda^{n-1}+(-1)^n\lambda^n (λ−λ1)(λ−λ2)...(λ−λ3)=λ1...λn+(−1)1(λ1+...+λn)λ+...+(−1)n−1(λ1+...+λn)λn−1+(−1)nλn
λ = 0 \lambda=0 λ=0时,有 ∣ A ∣ = λ 1 . . . λ n |A| = \lambda_1...\lambda_n ∣A∣=λ1...λn。因此 λ 1 λ 2 . . . λ n \lambda_1\lambda_2...\lambda_n λ1λ2...λn= d e t ( A ) det(A) det(A)
( − 1 ) n − 1 ( λ 1 + . . . + λ n ) λ n − 1 (-1)^{n-1}(\lambda_1+...+\lambda_n)\lambda^{n-1} (−1)n−1(λ1+...+λn)λn−1中 λ \lambda λ次数为 n − 1 n-1 n−1,则此项一定从 ∣ A − λ I ∣ |A-\lambda I| ∣A−λI∣的对角线乘积中得到。我们从 ( A 11 − λ ) . . . ( A n n − λ ) (A_{11}-\lambda)...(A_{nn}-\lambda) (A11−λ)...(Ann−λ)获取 λ \lambda λ次数为 n − 1 n-1 n−1的项: ( − 1 ) n − 1 ( A 11 + . . . + A n n ) λ n − 1 (-1)^{n-1}(A_{11}+...+A_{nn})\lambda^{n-1} (−1)n−1(A11+...+Ann)λn−1。 ∑ λ i \sum\lambda_i ∑λi= A 11 + . . . + A n n A_{11}+...+A_{nn} A11+...+Ann
6.1.2对角化
如果一个矩阵的特征值都不相同,则该矩阵的特征向量线性无关
Proof:
令
c 1 x 1 + c 2 x 2 = 0 ( 1 ) c_1x_1+c_2x_2=0(1) c1x1+c2x2=0(1)
两边乘 A A A得 c 1 λ 1 x 1 + c 2 λ 2 x 2 = 0 ( 2 ) c_1\lambda_1x_1+c_2\lambda_2x_2=0(2) c1λ1x1+c2λ2x2=0(2)
( 1 ) ∗ λ 1 − ( 2 ) → c 2 x 2 ( λ 1 − λ 2 ) = 0 , λ 1 ≠ λ 2 , c 2 = 0 (1)*\lambda_1-(2)\rightarrow c_2x_2(\lambda_1-\lambda_2)=0,\lambda_1\neq\lambda_2,c_2=0 (1)∗λ1−(2)→c2x2(λ1−λ2)=0,λ1=λ2,c2=0,同理 c 1 = 0 c_1=0 c1=0,因此, x 1 , x 2 x_1,x_2 x1,x2线性无关
A = S Λ S − 1 A=S\varLambda S^{-1} A=SΛS−1, A 100 = S Λ 100 S − 1 A^{100}=S\varLambda ^{100} S^{-1} A100=SΛ100S−1,让 A k A^k Ak运算变得很简单
Similar Matrices: Same Eigenvalues
All the matrices A = BCB-1 are “similar.” They all share the eigenvalues of C.
6.1.3对称矩阵
对称矩阵有如下性质:
(1)特征值都为实数
Proof

(2)如果每个特征值都不同,则特征向量构成的矩阵为正交矩阵
Proof
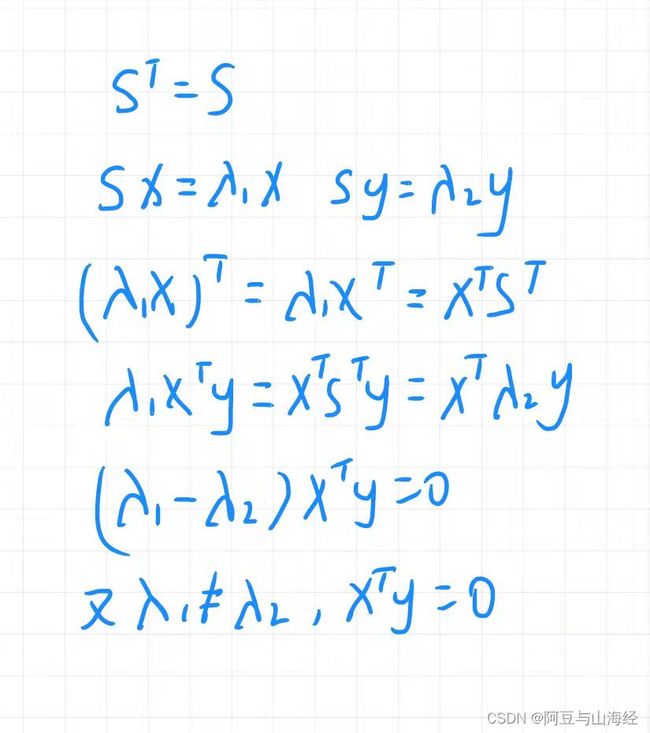
6.2 对角化与矩阵乘幂
对角化矩阵 Diagonalizing a matrix A = S Λ S − 1 A =SΛS^{-1} A=SΛS−1
如果矩阵 A 具有 n 个线性无关的特征向量,将它们作为列向量可以组成一个可逆方阵 S : [ x 1 , x 2 . . x n ] S:[x_1,x_2..x_n] S:[x1,x2..xn]$
A S = [ A x 1 , A x 2 . . . A x n ] = [ λ 1 x 1 , λ 2 x 2 . . . λ n x n ] = S Λ AS=[Ax_1,Ax_2...Ax_n]=[\lambda_1x_1,\lambda_2x_2...\lambda_nx_n]=SΛ AS=[Ax1,Ax2...Axn]=[λ1x1,λ2x2...λnxn]=SΛ
A = S Λ S − 1 A =SΛS^{-1} A=SΛS−1
矩阵乘幂
如果 A x = λ x Ax=\lambda x Ax=λx,则有 A 2 x = λ A x = λ 2 x A^2x=\lambda Ax=\lambda^2x A2x=λAx=λ2x。说明矩阵 A 2 A^2 A2 有着和 A 一样的特征向量,特征值为 λ 2 \lambda^2 λ2。 A k = S Λ k S − 1 A^k=SΛ^k S^{-1} Ak=SΛkS−1。这说明 A k A^k Ak 有着和 A 一样的特征向量,而特征值为 λ k \lambda ^k λk。
如果矩阵 A A A 具有 n 个线性无关的特征向量,如果所有的特征值均满足 ∣ λ ∣ < 1 |\lambda| <1 ∣λ∣<1。则 k → ∞ k→∞ k→∞时, A k → 0 A^k→0 Ak→0。
重特征值 Repeated eigenvalues
如果矩阵 A 没有重特征值,则其一定具有 n 个线性无关的特征向量。
如果矩阵 A 有重特征值,它有可能具有 n 个线性无关的特征向量,也可能没有。比如单位阵的特征值为重特征值 1,但是其具有 n 个线性无关的特征向量。
6.3 微分方程与exp(At)
d u d t = A u {du \over dt}=Au dtdu=Au
方程的通解为 u ( t ) = c 1 e λ 1 t x 1 + c 2 e λ 1 t x 2 . . . u(t)=c_1e^{\lambda_1t}x_1+c_2e^{\lambda_1t}x_2... u(t)=c1eλ1tx1+c2eλ1tx2...
收敛与发散
6.4 Markov Matrices and Fourier Series(特征值的应用)
1.性质:
- 每个元素 ≥ 0 \geq0 ≥0(看成概率相关的概念)
- 每一列相加=1(每一行相加=1,看具体规定)
2.稳态:
- λ = 1 \lambda=1 λ=1是特征值
- 其他 ∣ λ i ∣ < 1 |\lambda_i|<1 ∣λi∣<1
Proof :
μ k = A k μ 0 = c 1 λ 1 k x 1 + c 2 λ 2 k x 2 + . . . c n λ n k x n \mu_k=Α^kμ_0=c_1λ_1^kx_1+c_2λ_2^kx_2+...c_nλ_n^kx_n μk=Akμ0=c1λ1kx1+c2λ2kx2+...cnλnkxn达到稳态,则需要 λ 1 = 1 , 其 他 ∣ λ i ∣ < 1 ⇒ μ k = A k μ 0 = c 1 λ 1 k x 1 = c 1 x 1 λ_1=1,其他|\lambda_i|<1\rArr\mu_k=Α^kμ_0=c_1λ_1^kx_1=c_1x_1 λ1=1,其他∣λi∣<1⇒μk=Akμ0=c1λ1kx1=c1x1
Q1:每一列相加=1⇒ λ 1 = 1 ? λ_1=1? λ1=1?
Proof:
如果 ∣ A − λ ′ I ∣ = 0 则 λ = λ ′ |A-λ'I|=0则λ=λ' ∣A−λ′I∣=0则λ=λ′换言之,λ是使得 ( A − λ ′ I ) (A-λ'I) (A−λ′I)奇异的数
下要证明 ( A − I ) (A-I) (A−I)奇异:
( A − I ) T [ 1 1 1 ] = [ 0 0 0 ] (A-I)^T \begin{bmatrix} 1 \\1\\1\end{bmatrix}=\begin{bmatrix} 0\\0\\0 \end{bmatrix} (A−I)T⎣⎡111⎦⎤=⎣⎡000⎦⎤⇒ ( A − I ) T 列 向 量 线 性 相 关 , ( A − I ) 行 向 量 线 性 相 关 , r a n k ( ( A − I ) ) > 0 有 零 行 , 则 d e t ( A − I ) = 0 (A-I)^T列向量线性相关,(A-I)行向量线性相关,rank((A-I))>0有零行,则det(A-I)=0 (A−I)T列向量线性相关,(A−I)行向量线性相关,rank((A−I))>0有零行,则det(A−I)=0
Q2:零空间中的向量一定是特征向量
Proof: A x = 0 , x Ax=0,x Ax=0,x在零空间中,则 A x = 0 x , x Ax=0x,x Ax=0x,x是特征值为0的特征向量。在Q1中, ( A − I ) T x = 0 (A-I)^Tx=0 (A−I)Tx=0, x x x是 ( A − I ) T (A-I)^T (A−I)T的特征向量,0是特征值,则 A A A的λ=1