《windows 程序设计》读书笔记 二
目录
Unicode 历史及介绍
美国标准 ASCII:
Unicode 方案:
宽字符和 C 语言:
宽字符和 Windows:
Windows 函数调用:(Unicode 和 Ascii 版都使用了通用别名)
在 Windows 中使用 sprintf 系列函数:(代替 C 中的 printf 函数)
格式化的消息框:
本书的 UNICODE 字符讨论:(sizeof、Debug 和 Release、WindowsNT 和 Windows98)
Unicode 历史及介绍
美国标准 ASCII:
美国国家信息交换标准码 (ASCII) 起源于 20 世纪 50 年代末,并于 1967 年底终定型。ASCII 的开发过程中,对于代码的宽度应该是 6 位、7 位或是 8 位,一直争议不断。考候到可靠性,不能使用转换字符,因此 ASCII 不能使用 6 位编码,考虑到成本价格,也排除了 8 位编码的可能性。(位数多在当时是非常昂贵的)最后使用的代码有 26 个小写字母, 26 个大写字母,10 个数字,32 个符号,33 个控制码,一个空格码,总共有 128 个代码。ASCII 码目前记录在美国国家标准学会出版的 ANSI X3.4 - 1986 中, “编码字符集,7 位美国国家信息交换标准码 (7 位 ASCII)"
下图显示的 ASCII 与此 ANSI 文件中出现的 ASCII 非常相似:
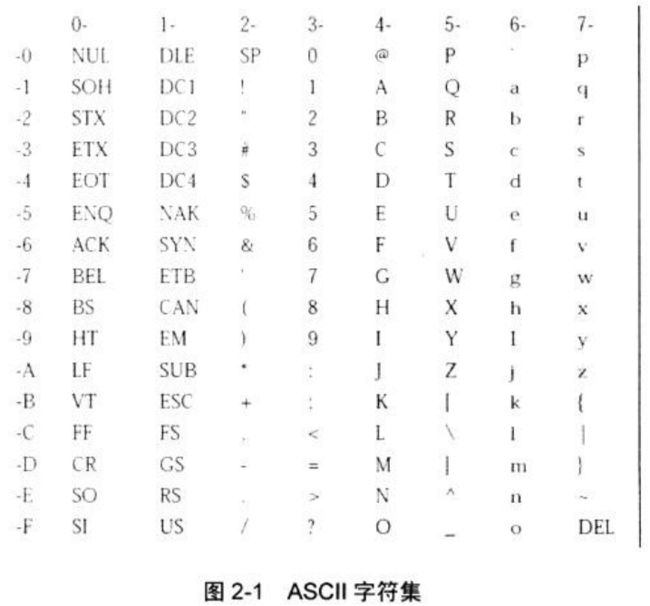
ASCII 好处多多。例如,26个子母的代码是连续的 (EBCDIC 编码就并非如此)。大小写字母只要翻转 1 位就可以互相转换。10 个数字的代码来自于数字值。(在BCDIC,“0” 的代码字符之后就是 “9” 的代码字符! )
最重要的是,ASCII 码是一种非常可靠的标准。没有其他哪一种标准能像 ASCII 一样普及,它扎根于我们的键盘、视频显示器、系统硬件、打印机、字体文件,操作系统和因特网。
扩展 ASCII:
到了早期小型计算机发展的时候,8 位字节的标准得以巩固。因此如果用一个字节来存储字符,就有 128 个额外的字符可以用来补充 ASCII。
Windows 自有的字符集被称为 “ANSI 字符集”,因为它是基于 ANSI 和 ISO 标准的一个草案,而此草案最终成为ANSI/ISO 8859-1-1987,“ 美国国家信息处理标准—— 8 位单字节编码图形字符集一第 1 部分:拉丁字母第 1号 ”。这也简称为 “拉丁语-1”
下图展示了印刷在 Windows1.0 程序员参考上的原始版本的 ANSI 字符集:

Unicode 方案:
如果有太多的东西以全于用 8 位值根本无法表示,我们就试着使用更多位的值,例如也许用 16 位值。这就是简单到可笑的 Unicode 的概念。与其用很容易混淆的多个 256 字符的代码映射或者是混合使用有 1 字节的代码和 2 字节代码的双字节字符集,还不如使用 Unicode,一种统一的 16 位系统,它可以代表 65536 个字符。这对世界上的所有书面语言的所有字符和象形文字来说都已经足够了,其中还可以句括一批数学、符号以及装饰标志的集合。
最开始的 128 个 Unicode 字符 (16 位码从 0x0000 到 0x007F ) 是 ASCII 码,而之后的 128 个 Unicode 字符 (代码从0x0080 到 0x00FF) 是 ISO 8859-1 ASCII 扩展码。在 Unicode 里面的各个字符区块同样基于现有的标准。这是为了便于进行代码转换。希腊字母表使用从 0x0370 到 0x03FF 的代码,西里尔文使用从 0x0400 到 0x04FF 的代码,亚美尼亚文使用从 0x0530 到 0x058F 的代码,而希伯来语使用从 0x0590 到 0x05FF 的代码。汉语、日语和韩语 (统称为中日韩) 的象形文字占用从 0x3000 到 0x9FFF 的代码。
宽字符和 C 语言:
(TCHAR.H 定义了通用别名 TCHAR)
C 语言中的宽字符是基于 wchar_t 数据类型的。这个数据类型被定义在多个头文件中,包括 WCHAR.H
typedef unsigned short wchar_ t; //因此 wchar_t 数据类型和一个无符号短整型一样,都是 16 位宽
可以用下面的语句来定义一个包含单个宽字符的变量:
wchar_t c = 'A';
变量 c 是一个两个字节的值 0x0041,这是 Unicode 中字母 A 的代表。(然而,因为 Intel 微处理器存储多字节数值时总是最低有效字节优先,所以这些字节实际上在内存中是以 0x41undefined 0x00 来存储的)
还可以如下定义一个已初始化的指向宽字符串的指针:
wchar_t *p = L"Hello!"; //注意,大写的字母 L (长整型) 紧接左引号。这向编译器表明这个字符串将用宽字符存
储
每个字符占用 2 个字节。指针变量 p 还是需要 4 个字节的存储空间,但是这个字符串需要 14 个字节——每个字符需要两个字节,再加上最后的 0 需要两个字节。
同样,还可以如下定义一个宽字符的数组:
static wchar_t a[] = L"Hello!";
也可以在单个字符常量前面使用 L 前缀,以表明它们应被解释为宽字符:
wchar_t C = L'A';
这个字符串同样需要 14 个字节的存储空间,而且 sizeof(a) 也会返回 14。你可以索引 a 数组来得到每个单独的字符。 a[1] 的值是宽字符 'e' 或 0x0065。
虽然这看起来像是一个录入错误,引号之前的那个 L 是非常重要的,而且这两个符号之间绝对不能有空格。只有有了这个 L,编译器才知道你想要字符串用每个字符两个字节的方式存储。好在如果忘记包括 L,C 编译器通常会显示一个警告或错误消息。
宽字符库函数:
宽字符版本的 strlen 函数被称为 wcslen (“宽字符字符串长度”),并定义在 STRING.H (也就是 strlen 被定义的地方) 和 WCHAR.H中。
strlen 函数的声明如下:
size_t __cdecl strlen (const char*) ;
而 wcslen 函数的声明如下:
size_t __cdecl wcslen(const wchar_t*);
该函数返回的结果是 6undefined 也就是字符串中的字符个数。请记住,在使用宽字符的时候,字符串的字符长度并没有改变,改变的只是字节长度。
所有你喜爱的 c 语言中那些使用字符串参数的运行库函数都有宽字符的版本。例如 wprintf 是宽字符版本的 printf。这些函数都被定义在 WCHAR.H 和定义正常函数的头文件中。
维护一个源代码文件 TCHAR.H:(该文件内全是别名定义,不包含任何实体函数)
宽字符串会占用两倍的空间,你会看到,宽字符运行库函数比正常的的数要大。为此你可能希望创建两个版本的程序,一个用 ASCII 字符串而另一个使用 Unicode 字符串。而最好的办法则是维护一个单一的源代码文件,但可以编译成 ASCII 或 Unicode。
使用包含在 Microsoft Visual C ++ 中的 TCHAR.H 头文件。这个头文件并不是 ANSI C 标准的一部分,所以其中定义的每一个函数和宏都有一个下划线前缀。
ANSI C是由美国国家标准协会(ANSI)及国际标准化组织(ISO)推出的关于C语言的标准。ANSI C 主要标准化了现存的实现, 同时增加了一些来自 C++ 的内容 (主要是函数原型) 并支持多国字符集 (包括备受争议的三字符序列)。 ANSI C 标准同时规定了 C 运行期库例程的标准。
TCHAR.H 为那些需要字符串参数的普通运行库函数提供了一 系列的替代名称。这些函数有时被称为 “通用” 的函数名字,因为它们可以指 Unicode 或非 Unicode 版本的函数。
举例 TCHAR.H 提供了一个 _tcslen 来作为计算长度的通用函数名:(可以理解为函数名是指针,指向真实函数名)
当 _UNICODE 的标识符被定义了并且 TCHAR.H 头文件被包含在你的程序中,_tcslen 就被定义为 wcslen:
#define _tcslen wcslen
如果 UNICODE 并没有被定义,那么 _tcslen 就被定义为 strlen:
#define _tcslen strlen
同样的 TCHAR 这个新的数据类型解决了两个字符数据类型的问题(可以理解为类型是变量,由其它变量赋值而来)
如果 _UNICODE 标识符被定义了,TCHAR 就是 wchar_t:
typedef wchar_t TCHAR;
否则的话,TCHAR 就是一个简单的 char:
typedef char TCHAR;
解决字符串文字中 L 这一棘手的问题:(TCHAR.H 中)
如果 _UNICODE 标识符被定义,一个叫 __T 的宏是如下定义的:
#define __T(x) L##x
这是相当模糊的语法,但它在 ANSI C 标准的 C 预理器中。那一对数字符号被称为 “令牌粘贴”,它使得字母 L 和宏参数拼接在一起。因此,如果宏参数是 "Hello!", 那么在内部 L##x 就是 L"Hello!"。
否则 _UNICODE标识符没有被定义,__T 宏就简单地如下定义:
#define __T(x) x
无论如何,其它两个宏定义成和 __T(x) 一样的:(这两个宏指向 __T(x),__T(x) 指向处理过的字符串,用于解决参数问题)
#define _T(x) __T(x) //这两个宏处理都是一样的, 简易程度不同而已
#define _TEXT(x) __T(x)
举例将字符串定义在 _T 或_TEXT 宏内:
_TEXT ("Hello!") //首先把 _TEXT("Hello!") 指向 __T("Hello!") ,然后转变成 L"Hello!" 或 "Hello!" 就是字符串二层转换而已
这样做的结果是,如果 _UNICODE 标识符被定义了undefined字符串就被解释为是由宽字符组成的,如果没有被定义,它则被解释为 8 位的字符串。
宽字符和 Windows:
(WINNT.H 定义了通用别名 TCHAR,windows 使用 C 的类型定义文件 CTYPE.H)
Windows 头文件的类型:
Windows 程序包含着 WINDOWS.H 头文件。该文件又包含着许多其他头文件,例如 WINDEF.H 。该文件中又有许多在 Windows 中使用的基本数据类型的定义,同时它本身也包含 WINNT.H。WINNT.H 则负责处理基本的 Unicode 支持功能。
WINNT.H 在一开始就包含 C 的头文件 CTYPE.H,而这是 C 的众多头文件之一,包含着 wchar_t 的定义。
WINNT.H 定义了两个新的被称作 CHAR 和 WCHAR 的数据类型:
typedef char CHAR;
typedef wchar_t WCHAR; // WC,Wide Char 类型,两个类型都从 C 中重命名而来
CHAR 和 WCHAR 是写 Windows 程序时推荐使用的数据类型,它们分别用于定义 8 位或者 16 位的字符。WCHAR 定义后面的注释 wc undefined是建议使用匈牙利标记法来说明这是一个基于 WCHAR 数据类型的变量,即这是一个宽字符。
WINNT.H 头文件定义了可用做 8 位字符串指针的 6 种数据类型和可用做 const 8 位字符串指针的 4 种数据类型:
(只是在原类型基础上加了个指针引用)
![]()
前缀 N 和 L 代表着 “近” (near) 和 “远”(long),指的是 16 位 Windows 系统中的两种大小不同的指针。但在 Win32 中 near 和 long 指针则没有区别。
同样地 WINNT.H 还定义了可作为 16 位字符串指针的 6 种数据类型和可作为 const1 6 位字符串指针的 4 种数据类型:
(只是在原类型基础上加了个指针引用)
![]()
这样,我们就有了数据类型 CHAR( 8 位的 char ) 和 WCHAR ( 16 位的 wchar_t), 以及指向 CHAR 和 WCHAR 的各种指针。
WINNT.H 头文件定义了通用字符类型:(TCHAR 和其指针引用)
像在 TCHAR.H 中一样(参见前面宽字符和 C 语言部分),WINNT.H 将 TCHAR 定义为一个通用的字符类型。如果标识符 UNICODE (没有下划线) 被定义了,则 TCHAR 和指向 TCHAR 的指针就分别被定义为 WCHAR 和指向 WCHAR 的指针;如果标识符 UNICODE 没有被定义,则 TCHAR 和指向 TCHAR 的指针就分别被定义为 char 和指向 char 的指针;

如果 TCHAR 已经在某个头文件中被定义了,WINNT.H 和 WCHAR.H 头文件都能防止 TCHAR 数据类型被重复定义。不管怎样,无论何时你在你的程序中使用其他头文件时,都应在所有其他头文件之前先包含 WINDOWS.H 头文件。(所以先包含该 WINDOWS.H 的作用之一就是通用数据类型定义和防止重复定义)
WINNT.H 头文件还定义了一个宏,它将 L 添加到一个字符串的第一个引号前:(TEXT(quote))
如果 UNICODE 标识符被定义了,那么一个被称作 TEXT 的宏则定义如下:
#define __TEXT(quote) L##quote
如果标识符 UNICODE 没有被定义,则如下定义 __TEXT 宏:
#define __TEXT(quote) quote
而不管怎样,TEXT 宏可如下定义:
#define TEXT(quote) __TEXT(quote) //和前面 "宽字符和 C 语言" 目录中“ 解决字符串文字中 L 这一棘手的问题:(TCHAR.H 中)” 一样,只是 WINNT.H 把两个下划线给省掉了。
Windows 函数调用:(Unicode 和 Ascii 版都使用了通用别名)
从 Windows 1.0 到 Windows 3.1 的过去的 16 位版本的 Windows 中,MessageBox 函数是存在于动态链接库 USER.EXE 中的。在 Windows 3.1 软件开发工具包所包含的 WINDOWS.H 中,MessageBox 函数的定义如下:
int WINAPI MessageBox (HWND,LPCSTR,LPCSTR,UINT) ;
注意,函数的第二个和第三个参数是指向常量字符串的指针。当 Windows 编译和链接一个 Win16 程序时,它并不处理 MessageBox 调用。而是通过执行程序 .EXE 文件中的一张表格,允许 Windows 将该程序的调用与动态链接库 USER 中的 MessageBox 函数动态链接起来。
而 32 位的 Windows (这包括 Windows NT 的所有版本、Windows 95 和 Windows 98 ),除了含有与 16 位 Windows 兼容的 USER.EXE外,还含有一个称为 USER32.DLL 的动态链接库,该动态链接库含有 32 位用户界面函数的入口点,其中包括了 32 位版本的函数 MessageBox。
MessageBoxA 在 WINUSER.H 中的定义如下:
WINUSERAPI int WINAPI MessageBoxA (HWND hWndundefined LPCSTR lpTextundefined LPCSTR lpCaptionundefined UINT uType) ;
MessageBoxW 的定义如下:
WINUSERAPI int WINAPI MessageBoxW (HWND hWndundefined LPCWSTR lpTextundefined LPCWSTR lpCaptionundefined UINT uType) ;
通用别名定义如下:(WINUSER.H)
如果需要在程序中混合调用并匹配 ASCII 和宽字符函数,则可以明确使用 MessageBoxA 和 MessageBoxW 函数。但大多数程序员会继续使用 MessageBox 。
根据是否已定义 UNICODE 标识符,MessageBox 将实际调用 MessageBoxA 或是 MessageBoxW 。

在 Windows 中使用 sprintf 系列函数:(代替 C 中的 printf 函数)
不能在 Windows 程序中使用 printf 函数。虽然可以在 Windows 中使用绝大多数的 C 语言运行库函数——实际上,相较于 Windows 中相应的函数,很多程序员更愿意使用 C 的内存管理和文件 I/O 函数。
但是 Windows 不存在标准输入 (standard input) 和标准输出 (standard output) 的概念(也许因为 windows 只有图形化和文本,只能先将字符输出到第一个参数指向的缓冲区中)。所以你可以在 Windows 程序中使用 fprintf 函数,但不能使用 printf 函数。
你仍然可以使用 sprintf 和 sprintf 系列的其他函数来显示文本。除了将格式化后的字符串内容输出到函数第一个参数所提供的字符串缓冲区以外,这些函数的功能和 printf 函数一样。然后就可以用这个字符串做任何事 (例如,可以将输出字符串传给 MessageBox )。
回忆一下,printf 函数是如下定义的:
![]()
//第一个参数是一个格式字符串,后面是与格式字符串中的代码相对应的不同类型的多个参数
sprintf 函数定义如下:
![]()
//第一个参数是一一个字符缓冲区; 后面是一个格式字符串。sprintf 并不是将格式化结果写到标准输出,而是将其存入 szBuffer。该函数返回该字符串的长度。
在字符模式编程环境中,C 语句:
![]()
的功能等同于下面的语句:(同样是字符模式,puts 是字符模式的输出)

//而在Windows中,需要使用 MessageBox 而不是puts来显示结果
printf 出错并可能造成程序崩溃。使用 sprintf 时,除此之外还要考虑一点,定义的字符串缓冲区必须足够大以存放结果。Microsoft 的专用函数 _snprintf 解决了这一问题, 此函数引进了另一个参数来指定字符缓冲区的大小。
sprintf 还有一个变形函数 vsprintf,它只有三个参数(用单个指针指向可变参数)。当需要对可变参数执行像 printf 一样的格式化时, 可以用 vsprintf 来实现你自己的函数。
vsprintf 的前两个参数与 sprintf 相同:(其实都一样,只是 vsprintf 第三个参数是指向数组的指针而已)
一个用于保存结果的字符缓冲区和一个格式字符串。第三个参数是指向待格式化的参数数组的指针。实际上,该指针指向在堆栈中供函数调用的变量(因为压入堆栈了嘛)。宏 va_list,va_start 和 va_end (在 STDARG.H 中定义) 帮助处理堆栈指针。(我们在本章最后的 SCRNSIZE 程序中表明了如何使用这些宏)
sprintf 函数可以用 vsprintf 函数这样编写:(pArgs 是一个堆栈指针,用一个指针代替可变参数)
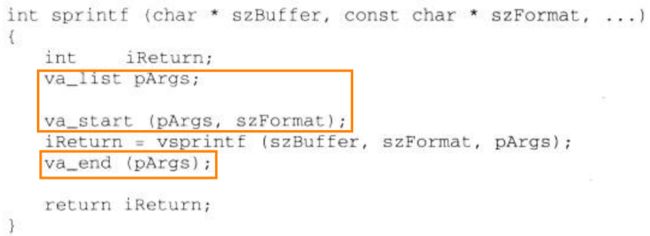
//va_start 宏将 pArg 设为指向一个在堆栈参数 szFormat 之上的堆栈变量
因为很多早期的 Windows 程序使用了 sprintf 和 vsprintf,最终导致 Microsoft 在 Windows API 中增添了两个相似的函数,就是 wsprintf 和 wvsprintf 函数,它们在功能上与 sprintf 和 vsprintf 相同,不同的是它们不能处理浮点格式。
然后又随着宽字符的引入,sprinf 系列的函数增加了许多。
下表列出了 Microsoft 版的 C 语言运行库和 Windows 所支持的所有 sprintf 类函数:
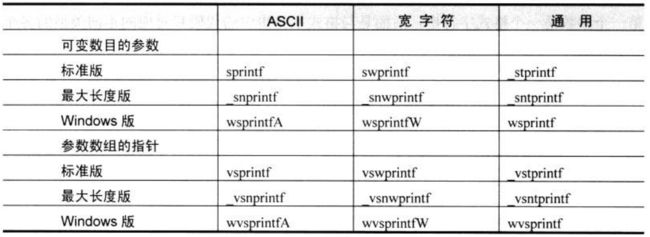
格式化的消息框:
如下所示的 SCRNSIZE 程序展示了如何实现 MessageBoxPrintf 函数,该函数能像 printf 那样接收各种各样大量的参数并对它们进行格式化。
这个程序以像素为单位显示了视屏显示器的宽度和高度,这些像素信息是从 GetSystemMetrics 函数得到的。GetSystemMetrics 函数是个很有用的函数,能帮助你得到 Windows 上的不同对象的大小信息。后面会说如何使用 GetSystemMetrics 函数在一个 Windows 的窗口中显示和滚动多行文本。
#include
#include
int CDECL MessageBoxPrintf (TCHAR * szCaptionundefined TCHAR * szFormatundefined ...)
{
TCHAR szBuffer [1024] ;
va_list pArgList ; //宏定义参数,该参数等于 szFormat 参数的地址加 szFormat 参数的大小,相当于跨过 szFormat 参数作为指针指向第三个参数。
// The va_start macro (defined in STDARG.H) is usually equivalent to:
// pArgList = (char *) &szFormat + sizeof (szFormat) ;
va_start (pArgListundefined szFormat) ;
// The last argument to wvsprintf points to the arguments
_vsntprintf (szBufferundefined sizeof (szBuffer) / sizeof (TCHAR)undefined
szFormatundefined pArgList) ;
// The va_end macro just zeroes out pArgList for no good reason
va_end (pArgList) ; //The va_end macro just zeroes out pArgList for no good reason
return MessageBox (NULLundefined szBufferundefined szCaptionundefined 0) ;
}
int WINAPI WinMain (HINSTANCE hInstanceundefined HINSTANCE hPrevInstanceundefined
PSTR szCmdLineundefined int iCmdShow)
{
int cxScreenundefined cyScreen ;
cxScreen = GetSystemMetrics (SM_CXSCREEN) ; //获取视屏显示器的宽度和高度
cyScreen = GetSystemMetrics (SM_CYSCREEN) ;
MessageBoxPrintf (TEXT ("ScrnSize")undefined
TEXT ("The screen is %i pixels wide by %i pixels high.")undefined
cxScreenundefined cyScreen) ;
return 0 ;
}
本书的 UNICODE 字符讨论:(sizeof、Debug 和 Release、WindowsNT 和 Windows98)
本书只限于讨论怎样通过定义 UNICODE 标识符来编译程序。这包括使用 TCHAR 定义所有的字符和字符串,对字符串文本使用 TEXT 宏,以及注意不要混淆字节和字符。
例如,注意 SCRNSIZE 中的 _vsntprintf 调用(这是通用格式,所以有宽字符时会表示为 unicode 版本),它的第二个参数是字符缓冲区的长度。通常,你会使用 sizeof(szBuffer), 但如果缓冲区中有宽字符,那么它返回的将不是缓冲区的字符长度,而是缓冲区按字节计算的长度。所以必须把返回值除以 sizeof(TCHAR) 以得到正确的字符串长度(因为宽字符版的 _vsntprintf 单个长度就是一个宽字符)。(sizeof 函数计算的是字节的长度,对于unicode 字符需要除以其单个字符长度)
通常,在 Visual C++ Developer Studio 中,可以用 Debug (调试) 和 Release (发布) 这两种不同的设定来编译程序。为了方便读者,我修改了本书范例程序的 Debug 设定,定义了 UNICODE 标识符。对那些使用字符串作参数的 C 运行库函数的程序,在 Debug 设定中也定义了 _UNICODE 标识符。(从 Project 菜单中选择 Settings,然后单击 C/C++ 标签来设定 Debug 程序)。这样,就可以很方便地重新编译和链接程序以供测试。
本书中所有的范例程序 (无论是否为 Unicode 编译) 都可以在 WindowsNT 下执行。除了极少数例外,本书中按 Unicode 编译的程序都不能在 Windows 98 中执行,而按非 Unicode 版编译的程序则可以。
本章和第 1 章的程序就是少数例外中的两个。MesageBoxW 是 Windows 98 支持的少数宽字符 Windows 函数之一 。而如果在 SCRNSIZE.C 中(前面格式化的消息框目录中),用 Windows 函数 wprintf 取代 _vsntprintf (你还必须删除该函数的第二个参数) 的话,那么 SCRNSIZE.C 的 Unicode 版将不能在 Windows 98 下执行,因为 Windows 98 不支持 wprintfW。