Pytorch LSTM 长短期记忆网络
Pytorch LSTM 长短期记忆网络
0. 环境介绍
环境使用 Kaggle 里免费建立的 Notebook
教程使用李沐老师的 动手学深度学习 网站和 视频讲解
小技巧:当遇到函数看不懂的时候可以按 Shift+Tab 查看函数详解。
1. LSTM
LSTM 的设计灵感来自于计算机的逻辑门。
LSTM 引入了记忆单元(Memory cell)。
有些文献认为记忆单元是隐状态的一种特殊类型,它们与隐状态具有相同的形状,其设计的目的是用于记录附加的信息。LSTM 使用门控结构控制记忆单元。
在 LSTM 网络中,记忆单元 c c c 可以在某个时刻捕捉到某个关键信息,并有能力将此关键信息保存一定的时间间隔。记忆单元 c c c 中保存信息的生命周期要长于短期记忆 h h h,但又远远短于长期记忆, 长短期记忆是指长的 “短期记忆”。因此称为长短期记忆(Long Short-Term Memory)。
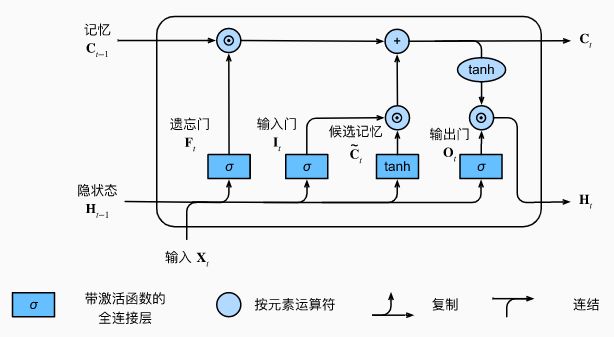
2. 门
- 遗忘门: f t f_t ft 通过上一时刻隐状态 h t − 1 h_{t-1} ht−1 和 当前输入 x t x_t xt 控制上一时刻记忆单元 c t − 1 c_{t-1} ct−1 需要遗忘多少信息。
- 输入门: i t i_t it 控制当前时刻的候选记忆单元 c ~ t \widetilde{c}_t c t 有多少信息需要保存。
- 输出门: o t o_t ot 控制当前时刻的记忆单元 c t c_t ct 有多少信息需要输出给当前隐状态 h t h_t ht。
公式表示:

3. 从零开始实现代码
3.0 导包
!pip install -U d2l
import torch
from torch import nn
from d2l import torch as d2l
3.1 加载数据集
设置批量大小和步数
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
3.2 初始化模型参数
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆单元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
3.3 初始状态函数
在初始化函数中, 长短期记忆网络的隐状态需要返回一个额外的记忆单元, 单元的值为 0 0 0,形状为(批量大小,隐藏单元数)。 因此,我们得到以下的状态初始化。
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
3.4 定义模型
其中要注意:@ 表示矩阵乘法,* 和 + 表示矩阵 point-wise 计算。
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)
3.5 训练预测
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params,
init_lstm_state, lstm)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)

4. 简洁实现
使用 nn.LSTM,训练更快:
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
