淘宝的数据库,主键是如何设计的?
MySQL数据库架构设计的基本功就是对于表结构的设计。
如对于字段类型的选择;表的存储设计,压缩还是非压缩,如何选用压缩算法;表的访问设计,SQL还是NoSQL。
这些问题看似非常简单并容易回答,然而绝大部分的答案却是错的。
某些错的离谱的答案还在网上年复一年的流传着,甚至还成为了所谓的MySQL军规。
其中,一个最明显的错误就是关于MySQL的主键设计。
大部分人的回答如此自信:用8字节的 BIGINT 做主键,而不要用INT。
以上全错。
这样的回答,只站在了数据库这一层,而没有从业务的角度思考主键到底什么?
主键就是一个自增ID么?
站在2021年的时间当下,用自增做主键,架构设计上可能连及格分都拿不到。
1、自增ID的问题
自增ID做主键,简单易懂,几乎所有数据库都支持自增类型,只是实现上各自有所不同而已。
自增ID除了简单,其他都是缺点,总体来看存在以下几方面的问题。
首先,可靠性不高。存在自增ID回溯的问题,这个问题直到最新版本的MySQL 8.0才修复。
其次,安全性不高。对外暴露的接口可以非常容易猜测对应的信息。
比如/User/1/这样的接口,可以非常容易猜测用户ID的值为多少,总用户数量有多少,也可以非常容易地通过接口进行数据的爬取。
另外容易被忽视的一点是,自增ID的性能较差,需要在数据库服务器端生成。
而且业务还需要额外执行一次类似last_insert_id()的函数才能知道刚才插入的自增值,这需要多一次的网络交互。
在海量并发的系统中,多1条SQL,就多一次性能上的开销。
最后也是最重要的一点是,自增ID是局部唯一,只在当前数据库实例中唯一,而不是全局唯一,在任意服务器间都是唯一的。
对于目前分布式系统来说,这简直就是噩梦。
2、淘宝的主键设计
在淘宝的电商业务中,订单服务是一个核心业务。
那么请问,订单表的主键淘宝是如何设计的呢?是自增ID么?
打开淘宝,看一下订单信息:
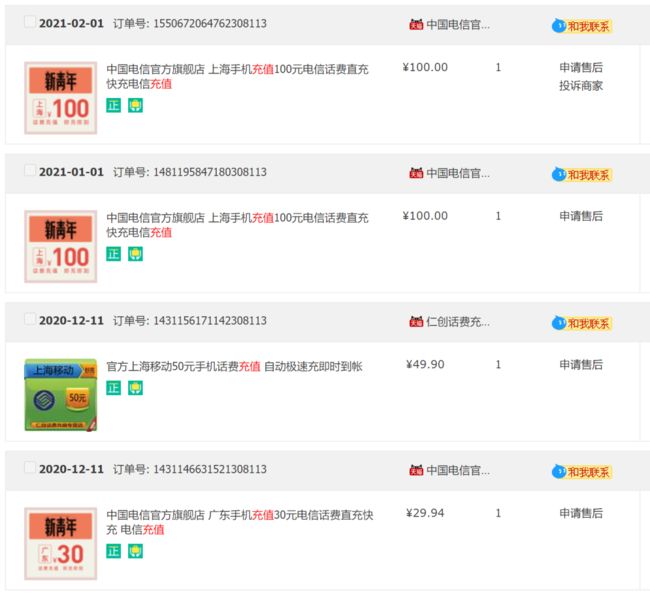
从上图可以发现,订单号不是自增ID!!!
接着,我们详细看下上述4个订单号:
1550672064762308113
1481195847180308113
1431156171142308113
1431146631521308113注意到了什么没?订单号是20位的长度,且订单的最后6位都是一样的,都是08113。
此外,订单号的前面14位部分是单调递增的。
所以,我大胆猜测,淘宝的订单ID设计应该是:
订单ID = 时间 + 去重字段 + 用户ID后6位尾号
这样的设计能做到全局唯一,且对分布式系统查询及其友好。
3、主键的设计
看到这里,姜老师想说的是自增ID只适合用于非核心业务,如告警、日志、监控等信息。
对于核心业务表,主键设计至少应该是全局唯一且是单调递增。全局唯一保证在各系统之间都是唯一的,单调递增是希望插入时不影响数据库性能。
这里姜老师推荐最简单的一种主键设计:UUID。
我知道很多同学会说:UUID啊,虽然全局唯一,但是占用36字节,数据无序,插入性能差。
是的,再一次的以上全错。
在得到上述结论前,是不是应该先回答以下这样问题呢?
-
为什么UUID是全局唯一的?
-
为什么UUID占用36个字节?
-
为什么UUID是无序的?
好吧,接着姜老师来手把手的给你讲解UUID。
MySQL数据库的UUID实现是Version 1的版本实现,其组成如下所示:
UUID = 时间低(4字节)- 时间中高+版本(4字节)- 时钟序列 - MAC地
为了更为详细的讲解UUID的实现,我们以UUID值e0ea12d4-6473-11eb-943c-00155dbaa39d举例,其具体组成如下图所示:
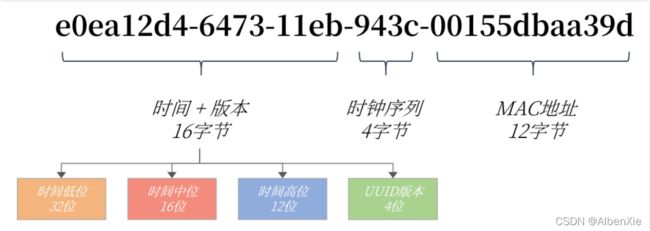
在UUID中他的时间部分占用60位,存储的类似TIMESTAMP的时间戳,但表示的是从1582-10-15 00:00:00.00到现在的100ns的计数。
可以看到UUID存储的时间精度比TIMESTAMPE更高,时间维度发生重复的概率降低到1/100ns。
时钟序列是为了避免时钟被回拨导致产生时间重复的可能性。MAC地址用于全局唯一。这回答了为什么UUID可以是全局唯一的问题。
UUID根据字符串进行存储,设计时还带有无用"-"字符串,因此总共需要36个字节。
最后,为什么UUID是随机无序的呢?
因为UUID的设计中,将时间低位放在最前面,而这部分的数据是一直在变化的,并且是无序!!!
若将时间高低位互换,则时间就是单调递增的了,也就变得单调递增了。
MySQL 8.0解决了UUID存在的问题,除去了UUID字符串中无意义的"-"字符串,并且将字符串用二进制类型保存,这样存储空间降低为了16字节。
更重要的是,他可以更换时间低位和时间高位的存储方式,这样UUID就是有序的UUID了。
可以通过MySQL8.0提供的uuid_to_bin函数实现上述功能,同样的,MySQL也提供了bin_to_uuid函数进行转化:

所以,现在起可以通过函数uuid_to_bin(@uuid,true)将UUID转化为有序UUID了。
全局唯一 + 单调递增,这不就是我们想要的主键实现么?
BTW,8.0之前的版本没有提供这两个函数,有聪明的小伙伴知道怎么实现么?欢迎留言。
4、有序UUID性能测试
16字节的有序UUID,相比之前8字节的自增ID,性能和存储空间对比究竟如何呢?
我们来做一个测试,插入1亿条数据,每条数据占用500字节,含有3个二级索引,最终的结果如下所示:
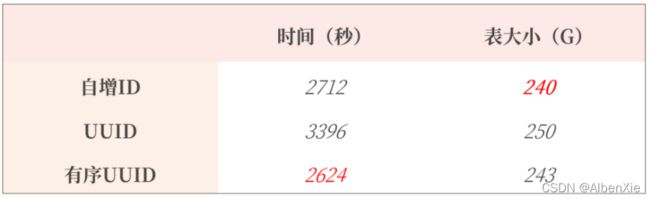
从上图可以看到插入1亿条数据有序UUID是最快的,而且在实际业务使用中有序UUID在业务端就可以生成。还可以进一步减少SQL的交互次数。
另外,虽然有序UUID的相比自增ID多了8个自己,但实际只增大了3G的存储空间。
存储空间的增大并没有小伙伴想象中的那么大。
5、总结
在当今的互联网环境中,非常不推荐自增ID作为主键的数据库设计。
更推荐类似有序UUID的全局唯一的实现。
另外在真实的业务系统中,主键还可以加入业务和系统属性,如用户的尾号,机房的信息等。
这样的主键设计就更为考验架构师的水平了。