PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space 论文笔记
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
论文链接: https://arxiv.org/abs/1706.02413
一、 Problem Statement
Pointnet 没有捕捉local structure信息。解决pointnet没有在不同分辨率下提取特征的问题。在不同层级提取局部特征的能力可以提升网络的泛化性。
二、 Direction
基于PointNet的基础上,引入了一个hierarchical neural network。首先利用潜在的空间距离将点集划分为重叠的局部区域。与CNNs相似,从小区域中提取局部特征,获取精细的几何结构;这些局部特征进一步组合成较大的单元,并进行处理,以生成更高级别的特征。重复这个过程直到我们得到整个点集的特征。 所以PointNet++要解决的两个问题是:
- how to generate the partitioning of the point set
- how to abstract sets of points or local features through a local feature learner
local feature learner作者使用的是PointNet,所以问题就剩下第一个。怎么样产生一个重叠的点集分割区域。
三、 Method

先来看一下PointNet++的网络结构。主要分为三个部分:
- Hierachical point set feature learning
- Segmentation
- Classification
1. Hierachical point set feature learning
先来看看Hierachical point set feature learning。它包括三个部分:
- Sampling layer
- Grouping layer
- PointNet layer
(1) Sampling layer
采样层主要是从输入点中选择一系列的点,这些点是局部区域的中心点。也就是给定输入点 { x 1 , x 2 , . . . , x n } \{x_1, x_2, ...,x_n\} {x1,x2,...,xn},使用迭代的farthest point sampling(FPS)算法获得一个点的子集 { x i 1 , x i 2 , . . . , x i m } \{x_{i_1}, x_{i_2},...,x_{i_m}\} {xi1,xi2,...,xim}, x i j x_{i_j} xij是相对于集合 { x i 1 , x i 2 , . . . , x i j − 1 } \{x_{i_1}, x_{i_2},...,x_{i_{j-1}}\} {xi1,xi2,...,xij−1}的最远点。更详细的算法细节,可以参考[1]。相对于随机采样,这个方法能更好地覆盖全部点云,且产生的感知域是数据依赖的方式。这一层的输入是 N × ( d + C ) N \times (d + C) N×(d+C)。 N N N 是点的个数, d d d为坐标维度, C为点特征的维度。
(2) Grouping layer
这一层的输入是 N × ( d + C ) N \times(d + C) N×(d+C)的点集合 和中心点的坐标,大小为 N ′ × d N' \times d N′×d。输出是维度为 N ′ × K × ( d + C ) N' \times K \times (d + C) N′×K×(d+C)的点集的groups。每一个groups代表一个局部区域。 K K K根据groups不同而变化,但接下来的PointNet layer能够把灵活的点的数量转变为固定长度的局部区域的特征向量。
ball query 算法找出query point的一定半径内所有的点。另一种算法是KNN。但相对于KNN,ball query的局部邻域保证了一个固定的局部尺度,因此能够使得局部区域特征更加的泛化,对于局部的模式识别有更好地效果。
(3) PointNet layer
这一层主要用来提取局部区域的特征。输入是维度为 N ′ × K × ( d + C ) N' \times K \times (d + C) N′×K×(d+C)的点集的groups。输出 N ′ × ( d + C ′ ) N' \times(d + C') N′×(d+C′)。
2. Robust Feature Learning under Non-Uniform Sampling Density
点云是不均匀的,也就是在不同地方有不同的密度。采样后的局部特征可能被破坏,因此我们需要在更大的附近距离找更大的尺度特征。因此,作者提出了 density adaptive PointNet layers,当输入采样密度改变的时候,能够去结合不同尺度的区域特征。如下图所示,这也是所谓的hierarchical network with PointNet,即PointNet++。

作者也提出了两种density adaptive layers:
(1) Multi-scale grouping (MSG)
如上图所示,MSG比较简单直接,就是用不同尺度的grouping layers输出特征向量,拼接特征之后输入PointNet。
(2) Multi-resolution grouping (MRG)
因为MSG的PointNet layers需要对每个中心点处理大量的尺度特征,通常在低层的网络中,中心点的数量较多,计算资源消耗大。因此作者也提出了MRG。grouping layers的输出特征向量分为两部分,一部分是低一层sub-region的特征,另一部分是PointNet对最原始点提取的特征。
3. Point Feature Propagation for Set Segmentation
因为使用了sampling,对于segmentation的时候,我们需要对所有的原始点进行分类。因此需要把来自于采样点的特征传入原始点。在feature propagation 的时候,来自于 N l × ( d + C ) N_l \times (d+C) Nl×(d+C)点的特征传入 N l − 1 N_{l-1} Nl−1层的点。通过 插入特征值来实现特征的传递,具体来说是使用了inverse distance weighted average based on KNN算法。对于 N l − 1 N_{l-1} Nl−1的插值特征,会接着与来自于set abstract level的skip linked point features拼接起来.最后这个拼接起来的特征会经过一个 unit pointnet。重复以上步骤,直到把特征传递给原始点。
f ( j ) ( x ) = ∑ i = 1 k w i ( x ) f i ( j ) ∑ i = 1 k w i ( x ) f^{(j)}(x) = \frac{\sum_{i=1}^kw_i(x)f_i^{(j)}}{\sum_{i=1}^k w_i(x)} f(j)(x)=∑i=1kwi(x)∑i=1kwi(x)fi(j)
其中, w i ( x ) = 1 d ( x , x i ) p , j = 1 , . . . , C w_i(x)=\frac{1}{d(x,x_i)^p},j=1,...,C wi(x)=d(x,xi)p1,j=1,...,C
上式子的 p = 2 , k = 3 p=2, k=3 p=2,k=3,是inverse distance weighted average based on KNN的公式。
4. Experiment
如果不使用MSG或者MRG,就是用single scale grouping, PointNet++虽然在点云上的分类和分割效果有了一定的提升,但是作者发现,其在点云的缺失鲁邦性上似乎变得更差了。其原因是因为激光收集点云的时候总是在近的地方密集,在远的地方稀疏,因此当Sampling和Grouping的操作在稀疏的地方进行的时候,一个点可能代表了很多很多的局部特征,因此一旦缺失,网络的性能就会极大的受影响。
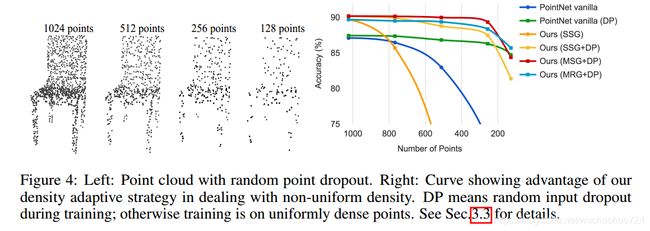 从这张图可以看出,当点云的个数缺失到20%的时候,PointNet++的性能甚至还不如PointNet。添加了random dropout训练会缓解一定程度的影响。如果加入MSG或者MRG,性能会提升不少。
从这张图可以看出,当点云的个数缺失到20%的时候,PointNet++的性能甚至还不如PointNet。添加了random dropout训练会缓解一定程度的影响。如果加入MSG或者MRG,性能会提升不少。
四、 Conclusion
PointNet++ 学习了不同层级的特征,为了解决不均匀点的采样问题,提出了两个set abstractiong layers,能够根据局部点的密度把不同尺度的信息拼接起来。
五、 Reference
- https://zhuanlan.zhihu.com/p/273539387
- https://blog.csdn.net/weixin_39373480/article/details/88878629