【Neo4j】第 3 章:使用 Pure Cypher 为您的业务赋能
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
技术要求
知识图谱
尝试定义知识图谱
从结构化数据构建知识图谱
使用 NLP 从非结构化数据构建知识图谱
自然语言处理
用于 NLP 的 Neo4j 工具
从 Wikidata 向知识图谱添加上下文
介绍 RDF 和 SPARQL
查询维基数据
将 Wikidata 导入 Neo4j
从语义图增强知识图
基于图的搜索
搜索方法
手动构建 Cypher 查询
自动化英语到密码的翻译
使用自然语言处理
使用类翻译模型
推荐引擎
产品相似度推荐
同类产品
经常一起购买的产品
推荐订购
社会推荐
我朋友买的产品
概括
问题
进一步阅读
在前面的章节中,我们介绍了 Neo4j 背后的概念,并学习了如何使用 Cypher 进行查询。现在是时候构建我们的第一个图形数据库工作应用程序了。进入图数据库生态系统的第一步通常是尝试构建您的业务或行业的知识图谱。在本章中,您将了解什么是知识图谱以及如何从结构化或非结构化数据中构建知识图谱。我们将使用一些自然语言处理( NLP )技术并查询现有的知识图谱,例如 Wikidata。然后,我们将关注知识图在现实世界中的两种可能应用:基于图的搜索和推荐。
本章将涵盖以下主题:
- 知识图谱
- 基于图的搜索
- 推荐引擎
技术要求
本章所需的技术和安装如下:
- Neo4j 3.5
- Plugins:
- APOC
- GraphAware NLP 库:https ://github.com/graphaware/neo4j-nlp
- 本章的一些小部分也需要安装 Python3;我们将使用该spaCy包进行 NLP。
- 本章的 GitHub 存储库:https ://github.com/PacktPublishing/Hands-On-Graph-Analytics-with-Neo4j/tree/master/ch3
知识图谱
如果您最近几年一直关注 Neo4j 新闻,您可能听说过很多关于知识图谱的信息。但并不总是很清楚它们是什么。不幸的是,知识图谱并没有通用的定义,但让我们尝试了解这两个词背后隐藏着哪些概念。
尝试定义知识图谱
现代应用程序每天都会产生数 PB 的数据。例如,在 2019 年期间,每分钟谷歌搜索的次数估计超过 44 亿次。在同一时间内,发送了 1800 亿封电子邮件和超过 500,000 条推文,而在 YouTube 上观看的视频数量约为 45 亿。组织这些数据并将其转化为知识是一项真正的挑战。
知识图试图通过将以下内容存储在相同的数据结构中来应对这一挑战:
- 与特定领域相关的实体,例如用户或产品
- 实体之间的关系,例如用户 A 购买了一块冲浪板
- 上下文来理解之前的实体和关系,例如,用户 A 住在夏威夷,是一名冲浪老师
图表是存储所有这些信息的完美结构,因为它很容易聚合来自不同数据源的数据:我们只需要创建新节点(可能带有新标签)和关系。无需更新现有节点。
这些图表可以以多种方式使用。例如,我们可以区分以下内容:
- 业务知识图:您可以构建这样的图来解决企业内的一些特定任务,例如为您的客户提供快速准确的建议。
- 企业知识图谱:为了超越业务知识图谱,您可以构建一个图谱,其目的是支持企业中的多个单元。
- 领域知识图:这更进一步,收集有关特定领域的所有信息,例如医学或运动。
自 2019 年以来,知识图谱甚至有自己的会议,由纽约哥伦比亚大学组织。您可以在https://www.knowledgegraph.tech/浏览过去事件的记录,并了解有关组织如何使用知识图来增强业务能力的更多信息。
在本节的其余部分,我们将学习如何在实践中构建知识图谱。我们将研究几种方法:
- 结构化数据:此类数据可以来自 SQL 等遗留数据库。
- 非结构化数据:这包括我们将使用 NLP 技术分析的文本数据。
- 在线知识图谱,尤其是 Wikidata ( https://www.wikidata.org )。
让我们从结构化数据案例开始。
从结构化数据构建知识图谱
知识图谱只不过是一个图数据库,具有众所周知的实体之间的关系。
实际上,我们已经在第 2 章“密码查询语言”中开始构建知识图谱。事实上,我们在那里构建的图表包含了 GitHub 上与 Neo4j 相关的存储库和用户:它代表了我们对 Neo4j 生态系统的了解。
到目前为止,该图只包含两种信息:
- Neo4j 组织拥有的存储库列表
- 每个存储库的贡献者列表
但我们的知识可以远不止于此。使用 GitHub API,我们可以更深入,例如,收集以下内容:
- 每个 Neo4j 贡献者拥有的存储库列表,或他们贡献的存储库列表
- 分配给每个存储库的标签列表
- 这些贡献者中的每一个都遵循的用户列表
- 关注每个贡献者的用户列表
例如,让我们在一个查询中导入每个存储库贡献者及其拥有的存储库:
MATCH (u:User)-[:OWNS]->(r:Repository)
CALL apoc.load.jsonParams("https://api.github.com/repos/" + u.login + "/" + r.name + "/contributors", {Authorization: 'Token ' + $token}, null) YIELD value AS item
MERGE (u2:User {login: item.login})
MERGE (u2)-[:CONTRIBUTED_TO]->(r)
WITH item, u2
CALL apoc.load.jsonParams(item.repos_url, {Authorization: 'Token ' + $token}, null) YIELD value AS contrib
MERGE (r2:Repository {name: contrib.name})
MERGE (u2)-[:OWNS]->(r2)您可以在 GitHub 上玩耍和扩展有关 Neo4j 社区的知识图谱。在以下部分中,我们将学习如何使用 NLP 来扩展此图并从项目README文件中提取信息。
使用 NLP 从非结构化数据构建知识图谱
NLP 是机器学习的一部分,其目标是理解自然语言。换句话说,NLP 的圣杯是让计算机回答诸如“今天天气怎么样?”之类的问题。
自然语言处理
在 NLP 中,研究人员和计算机科学家试图让计算机理解英语(或任何其他人类语言)句子。他们辛勤工作的成果可以在许多现代应用程序中看到,例如语音助手 Apple Siri 或 Amazon Alexa。
但在进入此类高级系统之前,NLP 可用于执行以下操作:
- 执行情绪分析:对特定品牌的评论是正面的还是负面的?
- 命名实体识别( NER ):我们可以提取给定文本中包含的人名或位置的名称,而不必以正则表达式模式将它们全部列出吗?
这两个问题对人类来说很容易,但对机器来说却非常困难。用于获得非常好的结果的模型超出了本书的范围,但您可以参考进一步阅读部分以了解更多信息。
在下一节中,我们将使用由斯坦福大学 NLP 研究小组提供的预训练模型,该研究小组在https://stanfordnlp.github.io/上提供了最先进的结果。
用于 NLP 的 Neo4j 工具
即使 Neo4j 没有正式支持,使用 Neo4j 的社区成员和公司也提供了一些有趣的插件。其中之一是由 GraphAware 公司开发的,它使 Neo4j 用户能够在 Neo4j 中使用斯坦福 NLP 工具。这就是我们将在本节中使用的库。
GraphAware NLP 库
如果您对实现和更详细的文档感兴趣,可以在GitHub - graphaware/neo4j-nlp: NLP Capabilities in Neo4j获得代码。
要安装此软件包,您需要访问GraphAware Products Download并下载以下 JAR 文件:
-
framework-server-community(如果使用 Neo4j 社区版)或者framework-server-enterprise如果使用企业版
-
nlp
- nlp-stanford-nlp
您还需要从https://stanfordnlp.github.io/CoreNLP/#download上的 Stanford Core NLP 下载经过训练的模型。在本书中,您只需要英语模型。
下载完所有这些 JAR 文件后,您需要将它们复制到我们在第 2 章“密码查询语言plugins”中开始构建的 GitHub 图的目录中。以下是您应该下载的 JAR 文件列表,运行本章中的代码需要这些文件:
apoc-3.5.0.6.jar
graphaware-server-community-all-3.5.11.54.jar
graphaware-nlp-3.5.4.53.16.jar
nlp-stanfordnlp-3.5.4.53.17.jar
stanford-english-corenlp-2018-10-05-models.jar一旦这些 JAR 文件在您的plugins目录中,您必须重新启动图形。要检查一切是否正常,您可以使用以下查询检查 GraphAware NLP 程序是否可用:
CALL dbms.procedures() YIELD name, signature, description, mode
WHERE name =~ 'ga.nlp.*'
RETURN signature, description, mode
ORDER BY name您将看到以下几行:
开始使用 NLP 库之前的最后一步是更新neo4j.conf. 首先,信任程序ga.nlp.并告诉 Neo4j 在哪里寻找插件:
dbms.security.procedures.unrestricted=apoc.*,ga.nlp.*
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware然后,在同一neo4j.conf文件中添加以下两行,特定于 GraphAware 插件:
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.1=com.graphaware.nlp.module.NLPBootstrapper重新启动图表后,您的工作环境就准备好了。让我们导入一些文本数据来运行 NLP 算法。
从 GitHub API 导入测试数据
作为测试数据,我们将使用README图中每个存储库的内容,并查看可以从中提取哪些信息。
从存储库获取的 APIREADME如下:
GET /repos///readme 与我们在上一章中所做的类似,我们将使用apoc.load.jsonParams这些数据将这些数据加载到 Neo4j 中。首先,我们设置我们的 GitHub 访问令牌,如果有的话(可选):
:params {"token": "8de08ffe137afb214b86af9bcac96d2a59d55d56"}然后我们可以运行以下查询来检索README我们图中的所有存储库:
MATCH (u:User)-[:OWNS]->(r:Repository)
CALL apoc.load.jsonParams("https://api.github.com/repos/" + u.login + "/" + r.name + "/readme", {Authorization: "Token " + $token}, null, null, {failOnError: false}) YIELD value
CREATE (d:Document {name: value.name, content:value.content, encoding: value.encoding})
CREATE (d)-[:DESCRIBES]->(r)您会从前面的查询中注意到,我们添加了一个参数{failOnError: false}来防止 APOC 在 API 返回的状态码不是 200 时引发异常。https://github.com/neo4j/license-maven-就是这种情况插件存储库,它没有任何README文件。
检查我们新文档节点的内容,您会发现内容是 base64 编码的。为了使用 NLP 工具,我们必须对其进行解码。令人高兴的是,APOC 为此提供了一个程序。我们只需要清理我们的数据并从下载的内容中删除换行符并调用apoc.text.base64Decode如下:
MATCH (d:Document)
SET d.text = apoc.text.base64Decode(apoc.text.join(split(d.content, "\n"), ""))
RETURN ddbms.security.procedures.whitelist=apoc.text.*
我们的文档节点现在具有人类可读的text属性,包含README. 现在让我们看看如何使用 NLP 来了解有关我们存储库的更多信息。
用 NLP 丰富图
为了使用 GraphAware 工具,第一步是构建 NLP 管道:
CALL ga.nlp.processor.addPipeline({
name:"named_entity_extraction",
textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor',
processingSteps: {tokenize:true, ner:true}
})在这里,我们指定以下内容:
- 管道名称,named_entity_extraction.
- 要使用的文本处理器。GraphAware 支持斯坦福 NLP 和 OpenNLP;在这里,我们使用的是斯坦福模型。
- 处理步骤:
- Tokenization:从文本中提取标记。作为第一个近似值,一个标记可以被视为一个词。
- NER:这是识别命名实体(如人员或位置)的关键步骤。
我们现在可以README通过调用以下过程在文本上运行此管道ga.nlp.annotate:
MATCH (n:Document)
CALL ga.nlp.annotate({text: n.text, id: id(n), checkLanguage: false, pipeline : "named_entity_extraction"}) YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)此过程实际上将更新图形并向其添加节点和关系。生成的图形模式显示在这里,只有一些选定的节点和关系,以使其更具可读性:
我们现在可以检查在我们的存储库中识别了哪些人:
MATCH (n:NER_Person) RETURN n.value此查询的部分结果显示在此处:
╒════════════════╕
│"n.value" │
╞════════════════╡
│"Keanu Reeves" │
├────────────────┤
│"Arthur" │
├────────────────┤
│"Bob" │
├────────────────┤
│"James" │
├────────────────┤
│"Travis CI" │
├────────────────┤
│"Errorf" │
└────────────────┘您可以看到,尽管存在一些错误Errorf或被Travis CI识别为人,NER 仍能够成功识别 Keanu Reeves 和其他匿名贡献者。
我们还可以识别 Keanu Reeves 是在哪个存储库中识别的。根据前面的图形模式,我们要编写的查询如下:
MATCH (r:Repository)<-[:DESCRIBES]-(:Document)-[:HAS_ANNOTATED_TEXT]->(:AnnotatedText)-[:CONTAINS_SENTENCE]->(:Sentence)-[:HAS_TAG]->(:NER_Person {value: 'Keanu Reeves'})
RETURN r.name此查询仅返回一个结果:neo4j-ogm。README对于我下载的版本,这个演员名称实际上在 this中使用(你可以在这里得到不同的结果,因为README随着时间的推移而变化)。
NLP 是扩展知识图谱并从非结构化文本数据中引入结构的绝佳工具。但是还有另一种信息来源,我们也可以使用它来增强知识图谱。事实上,维基媒体基金会等一些组织允许访问他们自己的知识图谱。我们将在下一节学习如何使用 Wikidata 知识图为我们的数据添加更多上下文。
从 Wikidata 向知识图谱添加上下文
Wikidata 用以下词语定义自己:
在实践中,一个 Wikidata 页面,比如关于 Neo4j 的页面 ( https://www.wikidata.org/wiki/Q1628290 ) 包含一个属性列表,例如编程语言或官方网站。
介绍 RDF 和 SPARQL
Wikidata 结构实际上遵循资源描述框架( RDF )。自 1999 年以来作为 W3C 规范的一部分,这种格式允许我们将数据存储为三元组:
(subject, predicate, object)例如,Homer is the father of Bart用 RDF 格式翻译句子如下:
(Homer, is father of, Bart)这个 RDF 三元组可以用更接近 Cypher 的语法编写:
(Homer) - [IS_FATHER] -> (Bart)可以使用同样由 W3C 标准化的 SPARQL 查询语言来查询 RDF 数据。
下面将教您如何针对 Wikidata 构建简单的查询。
查询维基数据
我们将在此处编写的所有查询都可以使用https://query.wikidata.org/上的在线 Wikidata 工具进行测试。
如果你已经完成了第 2 章末尾的评估,Cypher 查询语言,你的 GitHub 图表必须有带有标签Location的节点,包含每个用户被声明居住的城市。如果你跳过第 2 章或评估,你可以找到此图在本章的 GitHub 存储库中。当前的图形模式如下: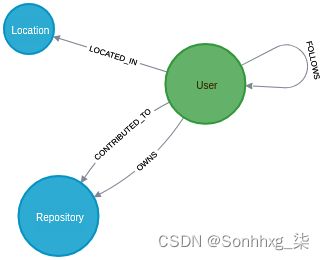
我们的目标是为每个位置分配一个国家/地区。让我们从 Neo4j 贡献者中最常见的位置 Malmö 开始。这是瑞典的一个城市,建造和维护 Neo4j 的公司 Neo Inc. 的主要办事处在这里。
我们如何使用维基数据找到马尔默所在的国家?我们首先需要在 Wikidata 上找到有关马尔默的页面。在您最喜欢的搜索引擎上进行简单搜索应该会引导您访问https://www.wikidata.org/wiki/Q2211。从那里,有两条信息需要注意:
- URL 中的实体标识符:Q2211。对于 Wikidata,Q2211意味着马尔默。
- 如果您在页面上向下滚动,您会找到属性country,它链接到Property属性页面P17:https ://www.wikidata.org/wiki/Property:P17 。
有了这两条信息,我们就可以构建和测试我们的第一个 SPARQL 查询:
SELECT ?country
WHERE {
wd:Q2211 wdt:P17 ?country .
这个查询,使用 Cypher 词,将读取:从标识符为 Q2211 (Malmö) 的实体开始,遵循类型P17(国家) 的关系,并返回该关系结束时的实体。为了进一步与 Cypher 进行比较,前面的 SPARQL 查询可以用 Cypher 编写如下:
MATCH (n {id: wd:Q2211})-[r {id: wdt:P17}]->(country)
RETURN country因此,如果您在 Wikidata 在线 shell 中运行上述 SPARQL,您将获得类似 的结果wd:Q34,其中包含指向 Wikidata 中瑞典页面的链接。太好了,它有效!但是,如果我们想使这种处理自动化,必须单击一个链接来获取国家名称并不是很方便。令人高兴的是,我们可以直接从 SPARQL 获得这些信息。与前一个查询相比的主要区别在于,我们必须指定我们想要返回结果的语言。在这里,我强制语言为英语:
SELECT ?country ?countryLabel
WHERE {
wd:Q2211 wdt:P17 ?country .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}执行此查询,您现在还获得国家名称瑞典,作为结果的第二列。
让我们更进一步。要获得城市标识符 ,Q2211我们必须首先搜索 Wikidata 并在查询中手动引入它。SPARQL 不能为我们执行此搜索吗?正如预期的那样,答案是肯定的,它可以:
SELECT ?city ?cityLabel ?countryLabel WHERE {
?city rdfs:label "Malmö"@en .
?city wdt:P17 ?country .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}我们不是从一个众所周知的实体开始,而是首先在 Wikidata 中执行搜索,以查找其标签(英文标签为 Malmö)的实体。
但是,您会注意到,现在运行此查询会返回三行,均以 Malmö 作为城市标签,但其中两行在瑞典,最后一行在挪威。如果我们只想选择我们感兴趣的马尔默,我们将不得不缩小查询范围并添加更多条件。例如,我们只能选择大城市:
SELECT ?city ?cityLabel ?countryLabel WHERE {
?city rdfs:label "Malmö"@en;
wdt:P31 wd:Q5119 .
?city wdt:P17 ?country .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}在此查询中,我们看到以下内容:
- P31意味着instance of。
- Q1549591是 的标识符big city。
所以前面的粗体声明,翻译成英文,可以读成如下:
Cities
whose label in English is "Malmö"
AND that are instances of "big city" 现在我们只选择瑞典的一个马尔默,这就是Q2211我们在本节开头确定的实体。
接下来,让我们看看如何使用这个查询结果来扩展我们的 Neo4j 知识图谱。
将 Wikidata 导入 Neo4j
为了自动将数据导入 Neo4j,我们将使用 Wikidata 查询 API:
GET https://query.wikidata.org/sparql?format=json&query={SPARQL}使用format=json不是强制性的,但它会强制 API 返回 JSON 结果而不是默认 XML;这是个人喜好问题。这样,我们还可以使用该apoc.load.json过程来解析结果并根据我们的需要创建 Neo4j 节点和关系。请注意,如果您习惯 XML 并且更喜欢操作这种数据格式,APOC 也有一个将 XML 导入 Neo4j 的过程:apoc.load.xml.
Wikidata API 端点的第二个参数是 SPARQL 查询本身,例如我们在上一节中编写的那些。我们可以运行查询来询问马尔默(实体Q2211)的国家和国家标签:
https://query.wikidata.org/sparql?format=json&query=SELECT ?country ?countryLabel WHERE {wd:Q2211 wdt:P17 ?country . SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }}您可以在浏览器中直接看到的结果 JSON 如下:
{
"head": {
"vars": [
"country",
"countryLabel"
]
},
"results": {
"bindings": [
{
"country": {
"type": "uri",
"value": "http://www.wikidata.org/entity/Q34"
},
"countryLabel": {
"xml:lang": "en",
"type": "literal",
"value": "Sweden"
}
}
]
}
}如果我们想用 Neo4j 处理这些数据,我们可以将结果复制到wikidata_malmo_country_result.json文件中(或从本书的 GitHub 存储库下载该文件),并使用apoc.load.json来访问国家名称:
CALL apoc.load.json("wikidata_malmo_country_result.json") YIELD value as item
RETURN item.results.bindings[0].countryLabel.value请记住将要导入的import文件放在活动图形的文件夹中。
但是,如果您还记得第 2 章Cypher查询语言,APOC 还可以自行执行 API 调用。这意味着我们刚刚执行的两个步骤——查询 Wikidata 并将结果保存在文件中,然后将这些数据导入 Neo4j——可以通过以下方式合并为一个步骤:
WITH 'SELECT ?countryLabel WHERE {wd:Q2211 wdt:P17 ?country. SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }}' as query
CALL apoc.load.jsonParams('http://query.wikidata.org/sparql?format=json&query=' + apoc.text.urlencode(query), {}, null) YIELD value as item
RETURN item.results.bindings[0].countryLabel.value此处使用WITH子句不是强制性的。但是如果我们想对所有Location节点运行前面的查询,使用这样的语法很方便:
MATCH (l:Location) WHERE l.name <> ""
WITH l, 'SELECT ?countryLabel WHERE { ?city rdfs:label "' + l.name + '"@en. ?city wdt:P17 ?country. SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } }' as query
CALL apoc.load.jsonParams('http://query.wikidata.org/sparql?format=json&query=' + apoc.text.urlencode(query), {}, null) YIELD value as item
RETURN l.name, item.results.bindings[0].countryLabel.value as country_name这将返回如下结果:
╒═════════════╤═════════════════════════════╕
│"l.name" │"country_name" │
╞═════════════╪═════════════════════════════╡
│"Dresden" │"Germany" │
├─────────────┼─────────────────────────────┤
│"Beijing" │"People's Republic of China" │
├─────────────┼─────────────────────────────┤
│"Seoul" │"South Korea" │
├─────────────┼─────────────────────────────┤
│"Paris" │"France" │
├─────────────┼─────────────────────────────┤
│"Malmö" │"Sweden" │
├─────────────┼─────────────────────────────┤
│"Lund" │"Sweden" │
├─────────────┼─────────────────────────────┤
│"Copenhagen" │"Denmark" │
├─────────────┼─────────────────────────────┤
│"London" │"United Kingdom" │
├─────────────┼─────────────────────────────┤
│"Madrid" │"Spain" │
└─────────────┴─────────────────────────────┘然后可以使用此结果以这种方式创建具有城市和已识别国家/地区之间关系的新国家/地区节点:
MATCH (l:Location) WHERE l.name <> ""
WITH l, 'SELECT ?countryLabel WHERE { ?city rdfs:label "' + l.name + '"@en. ?city wdt:P17 ?country. SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } }' as query
CALL apoc.load.jsonParams('http://query.wikidata.org/sparql?format=json&query=' + apoc.text.urlencode(query), {}, null) YIELD value as item
WITH l, item.results.bindings[0].countryLabel.value as country_name
MERGE (c:Country {name: country_name})
MERGE (l)-[:LOCATED_IN]->(c)得益于免费的在线 Wikidata 资源,我们在 GitHub 上的 Neo4j 社区知识图谱得到了扩展。
https ://github.com/neo4j-labs/neosemantics
如果您浏览 Wikidata,您将看到扩展的许多其他可能性。它不仅包含有关人员和位置的信息,还包含有关一些常用词的信息。例如,您可以搜索rake,您会看到它被归类为一个agricultural toolused byfarmers并且gardeners可以由plasticorsteel或组成wood。以结构化方式存储在那里的信息量令人难以置信。但是还有更多方法可以扩展知识图谱。我们将利用另一个数据源:语义图。
从语义图增强知识图
如果您有兴趣阅读 GraphAware NLP 软件包的文档,您已经看到了我们现在要使用的过程:enrich过程。
此过程使用 ConceptNet 图,它将单词与不同类型的关系联系在一起。我们可以找到同义词和反义词,也可以找到由关系创建或象征的关系。完整列表可在Relations · commonsense/conceptnet5 Wiki · GitHub获得。
让我们看看 ConceptNet 的实际应用。为此,我们首先需要选择一个我们之前使用Tag的 GraphAwareannotate过程的结果。对于这个例子,我将使用动词的Tag对应词"make"并寻找它的同义词。语法如下:
MATCH (t:Tag {value: "make"})
CALL ga.nlp.enrich.concept({tag: t, depth: 1, admissionRelationships:["Synonym"]}
该admittedRelationships参数是 ConceptNet 中定义的关系列表(检查前面的链接)。该过程创建了新标签,以及IS_RELATED_TO新标签和原始标签之间的类型关系,"make". 我们可以使用这个查询轻松地可视化结果:
MATCH (t:Tag {value: "make"})-[:IS_RELATED_TO]->(n)
RETURN t, n
结果如下图所示。您可以看到 ConceptNet 知道生产、构造、创建、原因和许多其他动词是make的同义词:

此信息非常有用,尤其是在尝试构建系统以了解用户意图时。这是我们将在下一节中研究的知识图谱的第一个用例:基于图的搜索。
基于图的搜索
基于图的搜索出现在 2012 年,当时谷歌宣布了其新的基于图的搜索算法。它承诺提供更准确的搜索结果,比以前更接近人类对人类问题的反应。在本节中,我们将讨论不同的搜索方法,以了解基于图的搜索如何成为搜索引擎的一大改进。然后,我们将讨论使用 Neo4j 和机器学习实现基于图的搜索的不同方法。
搜索方法
由于网络应用程序中存在搜索引擎,因此已经使用了几种搜索方法。例如,我们可以考虑分配给博客文章的标签,这些标签有助于对文章进行分类并允许搜索具有给定标签的文章。当您将关键字分配给给定文档时,也会使用此方法。这种方法实现起来很简单,但也很有限:如果你忘记了一个重要的关键字怎么办?
幸运的是,还可以使用全文搜索,它包含匹配的文档,其文本包含用户输入的模式。在这种情况下,无需手动使用关键字注释文档,可以使用文档的全文对其进行索引。Elasticsearch 等工具非常擅长索引文本文档并在其中执行全文搜索。
但这种方法仍然不完美。如果用户选择了与您使用的不同的措辞,但具有相似的含义怎么办?假设您撰写有关机器学习的文章。输入机器学习的用户不会对您的文本感兴趣吗?我们都记得我们不得不在谷歌上重新定义搜索关键字直到我们得到想要的结果的时候。
这就是基于图形的搜索进入游戏的地方。通过为您的数据添加上下文,您将能够识别出数据科学和机器学习实际上是相关的,即使不是同一件事,并且寻找其中一个术语的用户可能会对使用另一种表达方式的文章感兴趣。
为了更好地理解什么是基于图的搜索,让我们看一下 Facebook 在 2013 年给出的定义:
(来源:https ://www.facebook.com/notes/facebook-engineering/under-the-hood-building-graph-search-beta/10151240856103920 )
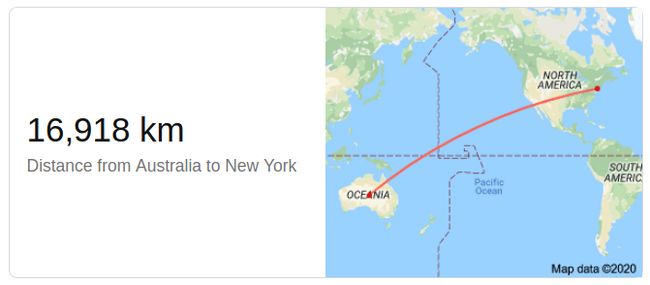
基于图形的搜索实际上早在 2012 年就由 Google 实施。从那时起,您就可以提出以下问题:
- 纽约离澳大利亚多远?
而你直接得到答案:
- 莱昂纳多·迪卡普里奥的电影。
您可以在结果页面的顶部看到莱昂纳多·迪卡普里奥出演的热门电影列表: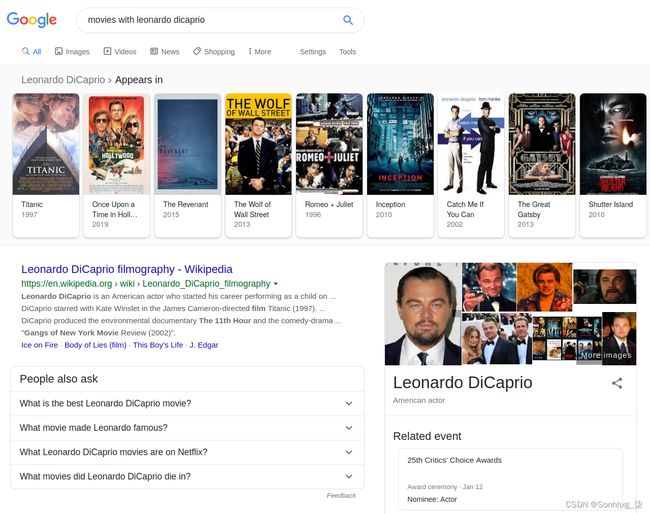
Neo4j 如何帮助实现基于图形的搜索?我们将首先了解 Cypher 如何使它能够回答像前面这样的复杂问题。
手动构建 Cypher 查询
首先,为了理解这个搜索是如何工作的,我们将手动编写一些 Cypher 查询。
下表总结了几种问题以及可能的 Cypher 查询以获得答案:
| 问题(英文) |
密码查询以获得答案 |
回答 |
| “neo4j”存储库是什么时候创建的? |
|
2012-11-12T08:46:15Z |
| 谁拥有“neo4j”存储库? |
|
neo4j |
| 有多少人为“neo4j”做出了贡献? |
|
30 |
| 哪些“neo4j”贡献者住在瑞典? |
|
"sherfert", "henriknyman", "sherfert", ... |
您可以看到 Cypher 允许我们用相当多的字符回答许多不同类型的问题。我们在上一节中建立的基于其他数据源(例如 Wikidata)的知识也很重要。
但是,到目前为止,此过程假定人类正在阅读问题并能够将其翻译成 Cypher。正如您可以想象的那样,这是一个不可扩展的解决方案。这就是为什么我们现在要研究一些技术来自动化这种翻译,通过 NLP 和翻译上下文中使用的最先进的机器学习技术。
自动化英语到密码的翻译
为了自动化英语到密码的翻译,我们可以使用一些基于语言理解的逻辑,或者更进一步,使用用于语言翻译的机器学习技术。
使用自然语言处理
在上一节中,我们使用了一些 NLP 技术来增强我们的知识图谱。可以应用相同的技术来分析用户编写的问题并提取其含义。在这里,我们将使用一个小的 Python 脚本来帮助我们将用户问题转换为 Cypher 查询。
在 NLP 方面,Python 生态系统包含几个可以使用的包。对于我们这里的需求,我们将使用spaCy(spaCy · Industrial-strength Natural Language Processing in Python)。它非常易于使用,特别是如果您不想为技术实现而烦恼。它可以通过 Python 包管理器轻松安装,pip:
pip install -U spacy如果您更conda-forge喜欢使用conda.
现在让我们看看如何spaCy帮助我们构建基于图形的搜索引擎。从一个英文句子比如Leonardo DiCaprio isborn in Los Angeles开始,spaCy可以识别句子的不同部分以及它们之间的关系:
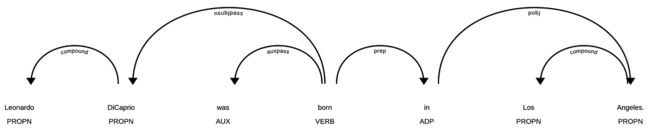
上图是从以下简单代码片段生成的:
import spacy
// load English model
nlp = spacy.load("en_core_web_sm")
text = "Leonardo DiCaprio is born in Los Angeles."
// analyze text
document = nlp(text)
// generate svg image
svg = spacy.displacy.render(document, style="dep")
with open("dep.svg", "w") as f:
f.write(svg)在这些关系之上,我们还可以提取命名实体,就像我们在上一节中使用 GraphAware 和斯坦福 NLP 工具所做的那样。上述文本的结果如下:

可以通过spaCy以下方式访问此信息:
for ent in document.ents:
print(ent.text, ":", ent.label_)这段代码打印以下结果:
Leonardo DiCaprio : PERSON
Los Angeles : GPE莱昂纳多·迪卡普里奥(Leonardo DiCaprio)被公认为PERSON. 根据Data formats · spaCy API Documentation上的文档,GPE 代表国家、城市、州;所以洛杉矶也被正确识别。
这有什么帮助?好吧,现在我们有了实体,我们有了节点标签:
MATCH (:PERSON {name: "Leonardo DiCaprio"})
MATCH (:GPE {name: "Los Angeles"})前面两个 Cypher 查询可以从 Python 生成:
for ent in document.ents:
q = f"MATCH (n:{ent.label_} {{name: '{ent.text}' }})"
print(q)为了确定我们应该使用哪种关系来关联两个实体,我们将在句子中使用动词:
for token in document:
if token.pos_ == "VERB":
print(token.text)唯一的打印结果将是born,因为这是我们句子中唯一的动词。我们可以更新前面的代码来打印 Cypher 关系:
for token in document:
if token.pos_ == "VERB":
print(f"[:{token.text.upper()}]")将所有部分放在一起,我们可以编写一个查询来检查该语句是否为真:
MATCH (n0:PERSON {name: 'Leonardo DiCaprio' })
MATCH (n1:GPE {name: 'Los Angeles' })
RETURN EXISTS((n1)-[:BORN]-(n2))true如果我们正在寻找的模式存在于我们的工作图中,则此查询返回,false否则返回。
如您所见,NLP 非常强大,如果我们想进一步推动分析,可以从中做很多事情。但是所需的工作量非常高,特别是如果我们想要涵盖多个领域(不仅是人员和位置,还包括园艺产品或 GitHub 存储库)。这就是为什么在下一节中,我们将研究 NLP 和机器学习实现的另一种可能性:自动英语到密码翻译器。
使用类翻译模型
正如您从上一段中看到的那样,自然语言理解有助于将人类语言自动转换为 Cypher 查询,但它依赖于一些规则。这些规则必须仔细定义,当规则数量增加时,您可以想象这会变得多么困难。这就是为什么我们也可以在机器学习技术方面找到帮助的原因,尤其是那些与 NLP 的另一部分翻译相关的技术。
翻译包括以(人类)语言获取文本,并以另一种(人类)语言输出文本,如下图所示,其中翻译器是机器学习模型,通常依赖于人工神经网络:

翻译者的目标是为每个单词分配一个值(或一个值向量),这个向量承载着单词的含义。我们将在专门介绍嵌入的章节(第 10 章,从图形到矩阵的图形嵌入)中更详细地讨论这一点。
但是在不知道过程细节的情况下,我们能想象应用相同的逻辑将人类语言翻译成 Cypher 吗?事实上,使用与人类语言翻译相同的技术,我们可以构建模型来将英语句子(问题)转换为 Cypher 查询。
Octavian-AI 公司致力于在他们的english2cypher包中实现这样的模型(GitHub - Octavian-ai/english2cypher: A model to transform english into Cypher queries, based off the CLEVR-graph dataset)。它是使用 TensorFlow 在 Python 中实现的神经网络模型。该模型从有关伦敦地铁的一系列问题中学习,以及他们在 Cypher 中的翻译。训练集如下所示:
english: How many stations are between King's Cross and Paddington?
cypher: MATCH (var1) MATCH (var2)
MATCH tmp1 = shortestPath((var1)-[*]-(var2))
WHERE var1.id="c2b8c082-7c5b-4f70-9b7e-2c45872a6de8"
AND var2.id="40761fab-abd2-4acf-93ae-e8bd06f1e524"
WITH nodes(tmp1) AS var3
RETURN length(var3) - 2即使我们还没有研究过最短路径方法(参见第 4 章,图数据科学库和路径查找),我们也可以理解前面的查询:
- 它从获取问题中提到的两个站点开始。
- 然后它会找到这两个站点之间的最短路径。
- 并统计最短路径中的节点(站)个数。
- 问题的答案是路径的长度,减去 2,因为我们不想计算起点和终点站。
但是机器学习模型的力量在于它们的预测:从一组已知数据(训练数据集)中,它们能够对未知数据进行预测。例如,前面的模型能够回答诸如“利物浦街站和海德公园角之间有多少个车站?”之类的问题。即使它以前从未见过。
为了在您的业务中使用这样的模型,您必须创建一个训练样本,该样本由一系列英语问题组成,相应的 Cypher 查询能够回答这些问题。这部分类似于我们在手动构建 Cypher 查询部分中执行的部分。然后你将不得不训练一个新模型。如果您不熟悉机器学习和模型训练,第 8 章将更详细地介绍该主题,在机器学习中使用基于图的特征。
现在,您可以更好地了解基于图形的搜索是如何工作的,以及如果用户搜索是贵公司的一项重要功能,为什么 Neo4j 是保存数据的好结构。但知识图谱的应用并不局限于搜索引擎。知识图谱的另一个有趣的应用是推荐,我们现在将会发现。
推荐引擎
如果您为电子商务网站工作,现在不可避免地会收到推荐。但电子商务并不是推荐的唯一用例。您还可以收到关于您可能想在 Twitter 上关注的人、您可能参加的聚会或您可能想了解的存储库的推荐。知识图是生成这些建议的好方法。
在本节中,我们将使用我们的 GitHub 图向用户推荐他们可能贡献或关注的新存储库。我们将探讨几种可能性,分为两种情况:您的图表包含一些社交信息(用户可以互相喜欢或关注)或者不包含。我们将从您无权访问任何社交数据的情况开始,因为它是最常见的一种。
产品相似度推荐
推荐产品,无论我们谈论的是电影、园艺工具还是聚会,都有一些共同的模式。以下是一些常识性的断言,可以导致一个好的建议:
- 与已经购买的产品属于同一类别的产品更有可能对用户有用。例如,如果您购买了耙子,这可能意味着您喜欢园艺,因此您可能会对割草机感兴趣。
- 有些产品经常一起购买,例如打印机、墨水和纸张。如果您购买打印机,自然会推荐其他用户也购买的墨水和纸张。
我们将使用 Cypher 看到这两种方法的实现。我们将再次使用 GitHub 图作为游乐场。其结构的重要部分如下图所示:
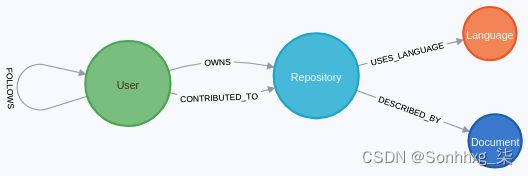
它包含以下实体:
- 节点标签:User、Repository、Language和Document
- 关系:
- 一个User节点拥有或贡献于一个或多个Repository节点。
- 一个Repository节点有一个或多个Language节点。
- 一个User节点可以跟随另一个User节点。
多亏了 GitHub API,这种USES_LANGUAGE关系甚至拥有一个属性,可以量化使用该语言的代码字节数。
同类产品
在 GitHub 图中,我们将语言视为对存储库进行分类。所有使用 Scala 的存储库都属于同一类别。对于给定的用户,我们可以通过以下方式获取他们贡献的存储库使用的语言:
MATCH (:User {login: "boggle"})-[:CONTRIBUTED_TO]->(repo:Repository)-[:USES_LANGUAGE]->(lang:Language)
RETURN lang如果我们想找到使用相同语言的其他存储库,我们可以通过这种方式从语言节点扩展路径到其他存储库:
MATCH (u:User {login: "boggle"})-[:CONTRIBUTED_TO]->(repo:Repository)-[:USES_LANGUAGE]->(lang:Language)<-[:USES_LANGUAGE]-(recommendation:Repository)
WHERE NOT EXISTS ((u)-[:CONTRIBUTED_TO]->(repo))
RETURN recommendation例如,用户对存储库boggle做出了贡献,该neo4j存储库部分使用 Scala 编写。使用该技术,我们会向该用户推荐存储库neotrients或JUnitSlowTestDiscovery,也使用 Scala:
然而,推荐所有使用 Scala 的存储库就像推荐所有园艺工具,因为用户购买了一把耙子。它可能不够准确,尤其是当类别包含大量项目时。让我们看看还有哪些其他类型的方法可以用来改进这项技术。
经常一起购买的产品
一种可能的解决方案是信任您的用户。有关他们行为的信息也很有价值。
考虑下图中的模式: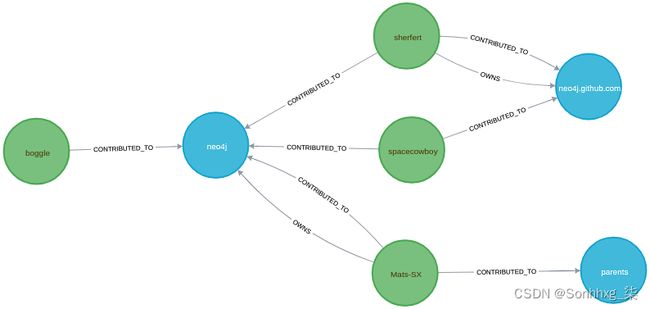
用户boggle对存储库做出了贡献neo4j。另外三个用户对其做出了贡献,并且还对存储库parents和neo4j.github.com. 也许boggle有兴趣为这些存储库之一做出贡献:
MATCH (user:User {login: "boggle"})-[:CONTRIBUTED_TO]->(common_repository:Repository)<-[:CONTRIBUTED_TO]-(other_user:User)-[:CONTRIBUTED_TO]->(recommendation:Repository)
WHERE user <> other_user
RETURN recommendation我们甚至可以将这种方法和前一种方法组合在一起,方法是只选择使用用户知道的语言并至少有一个共同贡献者的存储库:
MATCH (user:User {login: "boggle"})-[:CONTRIBUTED_TO]->(common_repository:Repository)<-[:CONTRIBUTED_TO]-(other_user:User)-[:CONTRIBUTED_TO]->(recommendation:Repository)
MATCH (common_repository)-[:USES_LANGUAGE]->(:Language)<-[:USES_LANGUAGE]-(recommendation)
WHERE user <> other_user
RETURN recommendation当只有几个匹配项时,我们可以显示所有返回的项目。但是如果你的数据库增长,你会发现很多可能的建议。在这种情况下,找到一种对推荐项目进行排名的方法将是必不可少的。
推荐订购
再看上图,可以看到仓库neo4j.github.com是两个人共享的,而parents仓库只有一个人推荐。该信息可用于对推荐进行排名。相应的 Cypher 查询如下:
MATCH (user:User {login: "boggle"})-[:CONTRIBUTED_TO]->(common_repository:Repository)<-[:CONTRIBUTED_TO]-(other_user:User)-[:CONTRIBUTED_TO]->(recommendation:Repository)
WHERE user <> other_user
WITH recommendation, COUNT(other_user) as reco_importance
RETURN recommendation
ORDER BY reco_importance DESC
LIMIT 5引入新WITH子句来执行聚合:对于每个可能的推荐存储库,我们计算有多少用户会推荐它。
这是使用用户数据提供准确推荐的第一种方式。另一种方法是在可能的情况下考虑使用社会关系,正如我们现在将看到的那样。
社会推荐
如果您的知识图谱包含与用户之间的社交链接相关的数据,例如 GitHub 或 Medium,则一个全新的推荐领域向您开放。因为您知道给定用户喜欢或关注的人,所以您可以更好地了解该用户可能喜欢哪种类型的内容。例如,如果您在 Medium 上关注的某个人为某个故事鼓掌,那么与您在 Medium 上找到的任何其他随机故事相比,您更有可能也会喜欢它。
FOLLOWS幸运的是,通过关系,我们的 GitHub 知识图中有一些社交数据。因此将使用此信息向我们的用户提供其他建议。
我朋友买的产品
如果我们想向我们的 GitHub 用户推荐新的仓库,我们可以考虑以下规则:我关注的用户的仓库更可能引起我的兴趣,否则我不会关注这些用户。我们可以使用 Cypher 来识别这些存储库:
MATCH (u:User {login: "mkhq"})-[:FOLLOWS]->(following:User)-[:CONTRIBUTED_TO]->(recommendation:Repository)
WHERE NOT EXISTS ((u)-[:CONTRIBUTED_TO]->(recommendation))
RETURN DISTINCT recommendation此查询匹配类似于以下的模式:
我们也可以在这里使用推荐排序。我关注的同时为给定存储库做出贡献的人越多,我也会为它做出贡献的可能性就越高。这通过以下方式转换为 Cypher:
MATCH (u:User {login: "mkhq"})-[:FOLLOWS]->(following:User)-[:CONTRIBUTED_TO]->(recommendation:Repository)
WHERE NOT EXISTS ((u)-[:CONTRIBUTED_TO]->(recommendation))
WITH user, recommendation, COUNT(following) as nb_following_contributed_to_repo
RETURN recommendation
ORDER BY nb_following_contributed_to_repo DESC
LIMIT 5查询的第一部分与前一部分完全相同,而第二部分与我们在上一节中编写的查询类似:对于每个可能的推荐,我们计算有多少用户mkhg关注会推荐它。
我们已经看到了几种基于纯 Cypher 查找推荐的方法。它们可以根据您的数据进行扩展:您对产品和客户的了解越多,建议就越精确。在接下来的章节中,我们将发现在同一社区内创建节点集群的算法。这个社区的概念也可以用在推荐的上下文中,假设同一社区内的用户更有可能喜欢或购买相同的产品。更多细节将在第 7 章社区检测和相似性措施中给出。
概括
本章详细描述了如何创建知识图谱,可以使用已经结构化的数据,例如 API 结果,也可以使用可以查询的现有知识图谱,例如 Wikidata。我们还学习了如何使用 NLP 和命名实体识别从非结构化数据中提取信息,例如人工书写的文本,并将这些信息转化为结构化图。我们还了解了知识图谱的两个重要应用:基于图的搜索,谷歌用来向用户提供更准确结果的方法,以及推荐,这是当今电子商务的必要步骤。
所有这些都是通过 Cypher 完成的,并通过一些插件(例如 APOC 或 NLP GraphAware 插件)进行了扩展。在本书的其余部分,我们将在处理图形分析时广泛使用另一个非常重要的库:Neo4j 图形算法库。下一章将介绍它并在最短路径查找器挑战的背景下给出应用示例。
问题
使用 Wikidata,我们可以将什么样的上下文信息添加到存储库语言中?
进一步阅读
-
如果您是 NLP 新手并想了解更多信息,可以从自然语言处理基础知识、D. Gunning 和 S. Ghosh、Packt Publishing开始。
- 然后,考虑查看使用 Python 进行自然语言处理的动手实践, R. Shanmugamani 和 R. Arumugam, Packt Publishing。
- W3C 规范:
- RDF:https ://www.w3.org/TR/rdf-concepts/
- SPARQL:https ://www.w3.org/TR/rdf-sparql-query/
- 谷歌翻译使用的神经机器翻译模型:
- 谷歌的初始论文:https ://research.google/pubs/pub45610/
- 使用 Tensorflow 的实现:https ://github.com/tensorflow/nmt