深度学习(PyTorch)——循环神经网络(RNN)进阶篇
B站up主“刘二大人”视频 笔记
一、循环神经网络的背景
传统神经网络(包括CNN),输入和输出都是互相独立的。图像上的猫和狗是分隔开的,但有些任务,后续的输出和之前的内容是相关的。例如:我是中国人,我的母语是____。这是一道填空题,需要依赖于之前的输入。
所以,RNN引入“记忆”的概念,也就是输出需要依赖于之前的输入序列,并把关键输入记住。循环2字来源于其每个元素都执行相同的任务。
它并⾮刚性地记忆所有固定⻓度的序列,而是通过隐藏状态来存储之前时间步的信息。
前向神经网络和 CNN 在很多任务中都取得不错的效果,但是这些网络结构的通常比较适合用于一些不具有时间或者序列依赖性的数据,接受的输入通常与上一时刻的输入没有关系。
但是序列数据不同,输入之间存在着先后顺序,当前输入的结果通常与前后的输入都有关。例如一段句子包含 4 个输入单词 :“我”、“去”、“商场”、“打车”,4 个单词通过不同的顺序排列,会有不同的意思,“我打车去商场” 和 “我去商场打车”。因此我们通常需要按照一定的顺序阅读句子才能理解句子的意思。
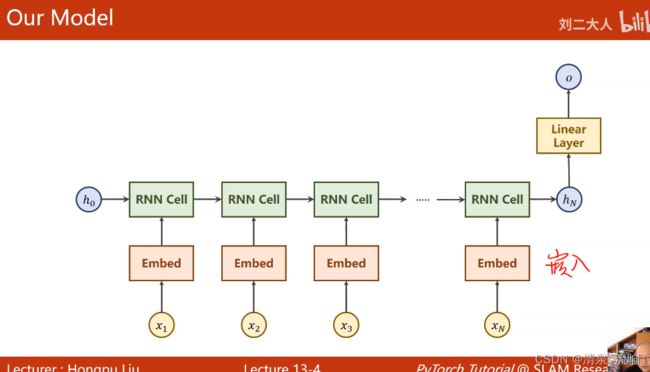
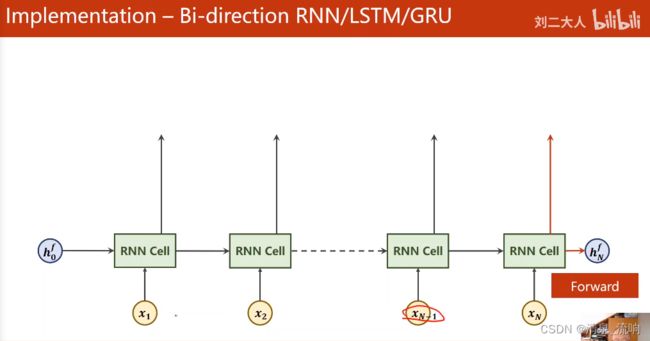
面对这种情况我们就需要用到循环神经网络了,循环神经网络按照顺序处理所有的输入,每一时刻 t,都会存在一个向量 h 保存与 t 时刻相关的信息 (可以是 t 时刻前的信息或者 t 时刻后的信息)。通过向量 h 与输入向量 x,就可以比较准确地判断当前的结果。在下文中的符号表示:
xt 表示 t 时刻的输入向量(例如第 t 个单词的词向量)。
ht 表示 t 时刻的隐藏向量 (包含了从开始一直到 t 时刻的相关信息)。
yt 表示 t 时刻的输出向量 (通常是预测的结果)。
二、循环神经网络训练时出现的问题
由于RNN特有的memory会影响后期其他的RNN的特点,梯度时大时小,learning rate没法个性化的调整,导致RNN在train的过程中,Loss会震荡起伏,为了解决RNN的这个问题,在训练的时候,可以设置临界值,当梯度大于某个临界值,直接截断,用这个临界值作为梯度的大小,防止大幅震荡。
程序如下:
import csv
import gzip
import math
import time
import torch
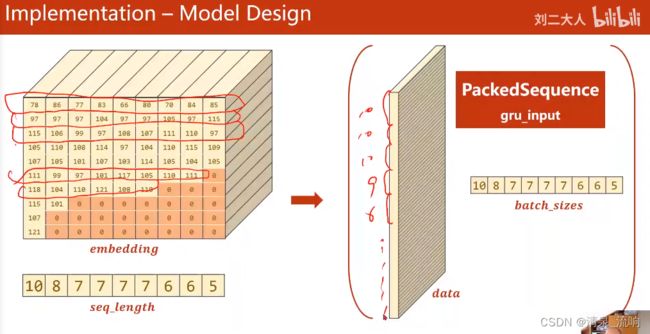
from torch.nn.utils.rnn import pack_padded_sequence
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
import numpy as np
HIDDEN_SIZE = 100 # GRU输出隐层的维度
BATCH_SIZE = 256
N_LAYER = 2 # 用2层的GRU
N_EPOCHS = 100
N_CHARS = 128 # 字母表的大小 ASCII表
USE_GPU = False
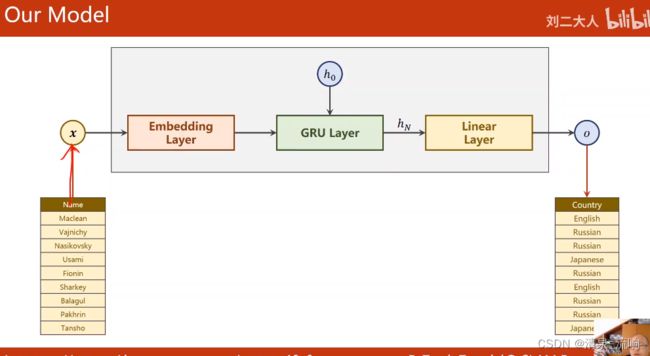
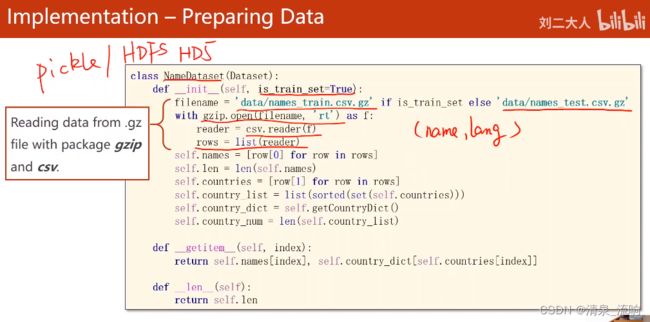
class NameDataset(Dataset):
def __init__(self,is_train_set=True):
filename = 'names_train.csv.gz' if is_train_set else 'names_test.csv.gz'
with gzip.open(filename,'rt') as f:
reader = csv.reader(f)
rows = list(reader) # 得到数据的(name,language)
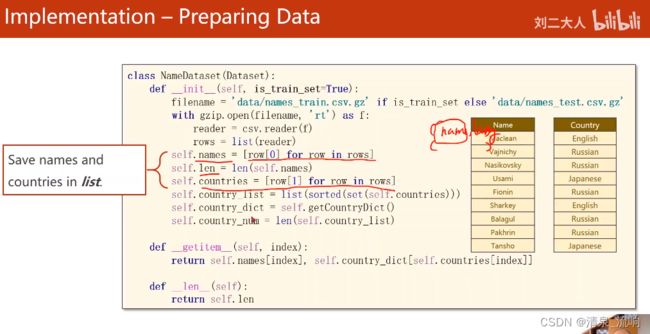
self.names = [row[0] for row in rows] # 得到数据的name
self.len = len(self.names)
self.countries = [row[1] for row in rows] # 得到数据的language
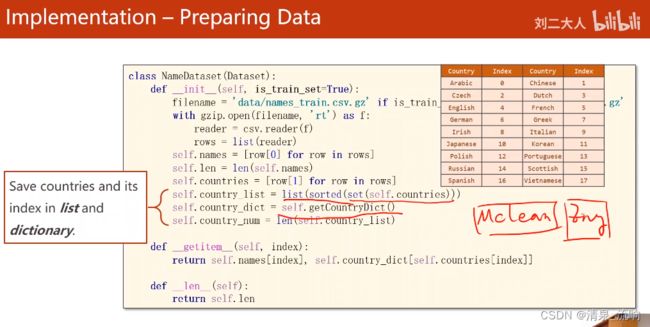
self.country_list = list(sorted(set(self.countries)))
# set把列表变成集合,去除重复元素,然后用sorted排序,最后变成列表
self.country_dict = self.getCountryDict() # 把列表变成词典
self.country_num = len(self.country_list)
# country和index相当于字典的键值对
def __getitem__(self, index): # 获得对应得索引index
return self.names[index],self.country_dict[self.countries[index]]
#
def __len__(self): # 返回数据集长度
return self.len
def getCountryDict(self): # 构造country与index的字典
country_dict = dict()
for idx,country_name in enumerate(self.country_list,0):
country_dict[country_name] = idx
return country_dict
def idx2country(self,index): # 根据索引index返回国家的字符串
return self.country_list[index]
def getCountriesNum(self): # 返回国家的数量
return self.country_num
trainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset,batch_size=BATCH_SIZE,shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset,batch_size=BATCH_SIZE,shuffle=False)
N_COUNTRY = trainset.getCountriesNum() # 多少分类
def create_tensor(tensor): # 判断是否使用GPU
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor
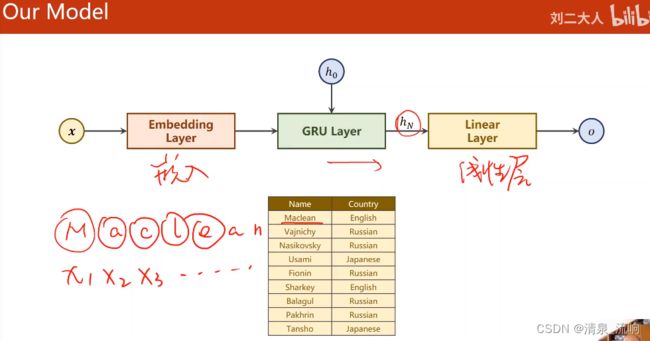
class RNNClassifier(torch.nn.Module):
def __init__(self,input_size,hidden_size,output_size,n_layers=1,bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size,hidden_size)
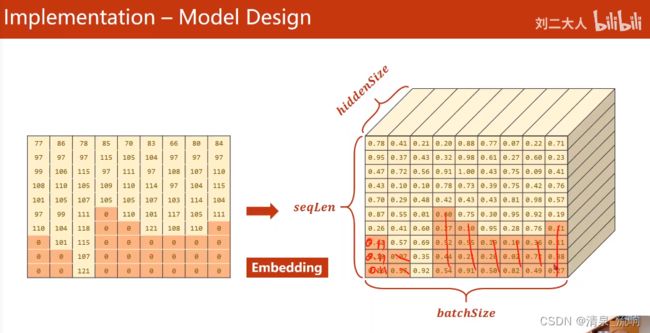
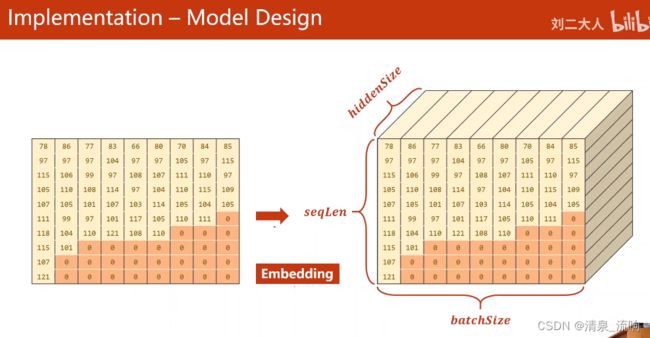
# 输入emb层的维度(seqlen,batchsize),输出emb层的维度(seqlen,batchsize,hiddensize)
self.gru = torch.nn.GRU(hidden_size,hidden_size,n_layers,bidirectional=bidirectional)
#输入GRU维度input:(seqlen,batchsize,hiddensize),hidden:(nlayers*nDirections,batchsize,hiddensize)
#输出GRU维度output:(seqlen,batchsize,hiddensize*nDirections),hidden:(nlayers*nDirections,batchsize,hiddensize)
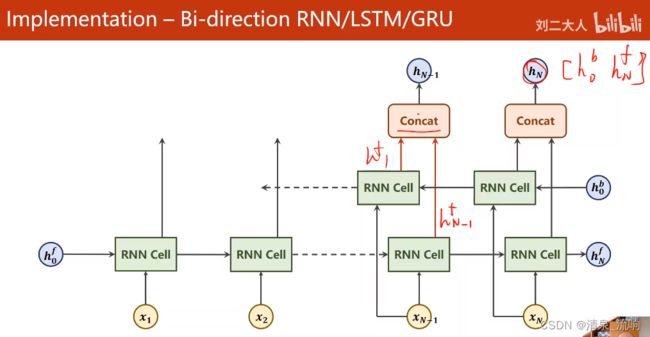
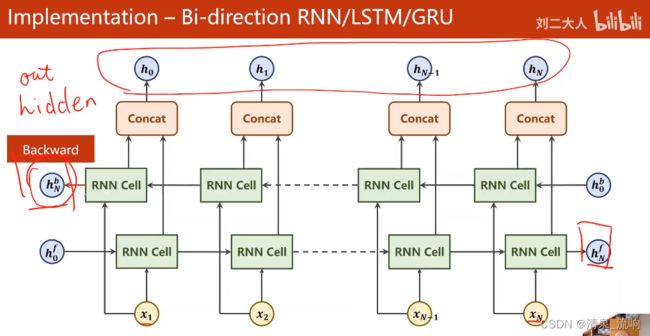
self.fc = torch.nn.Linear(hidden_size * self.n_directions,output_size)
def _init_hidden(self,batch_size): # 创建一个全0的初始隐层
hidden = torch.zeros(self.n_layers*self.n_directions,batch_size,self.hidden_size)
return create_tensor(hidden)
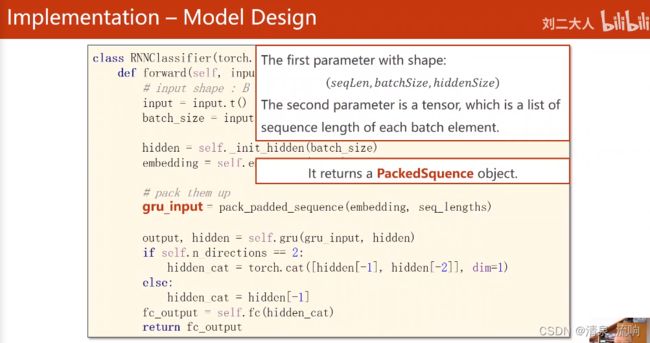
def forward(self,input,seq_lengths):
input = input.t() # 矩阵的装置 batch*seqlen->seqlen*batch
batch_size = input.size(1)
hidden = self._init_hidden(batch_size)
embedding = self.embedding(input) # 输出的维度(seqlen,batchsize,hiddensize)
gru_input = pack_padded_sequence(embedding,seq_lengths)
output,hidden = self.gru(gru_input,hidden)
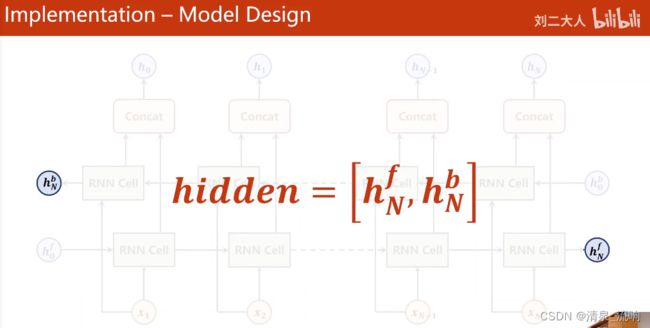
if self.n_directions == 2:
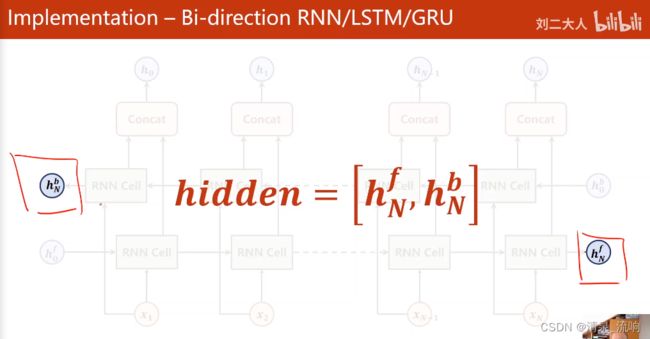
hidden_cat = torch.cat([hidden[-1],hidden[-2]],dim=1)
else:
hidden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
def time_since(since):
s = time.time() - since # 当前时间-开始时间
m = math.floor(s/60) # 变成分钟
s -= m*60
return '%dm %ds' % (m,s) # 返回多少分钟和多少秒
def name2list(name): # 把每一个名字变成列表
arr = [ord(c) for c in name]
return arr,len(arr)
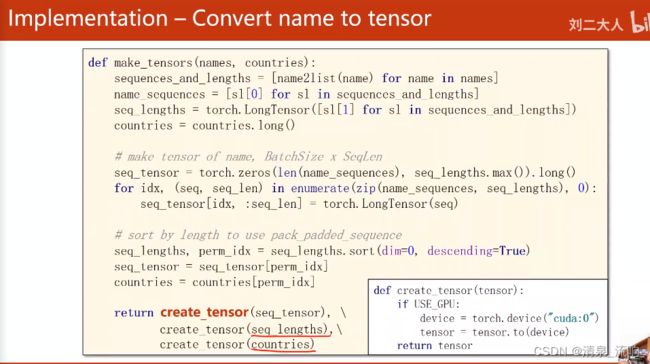
def make_tensors(names,countries):
sequences_and_lengths = [name2list(name) for name in names]
name_sequences = [sl[0] for sl in sequences_and_lengths]
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths])
countries = countries.long()
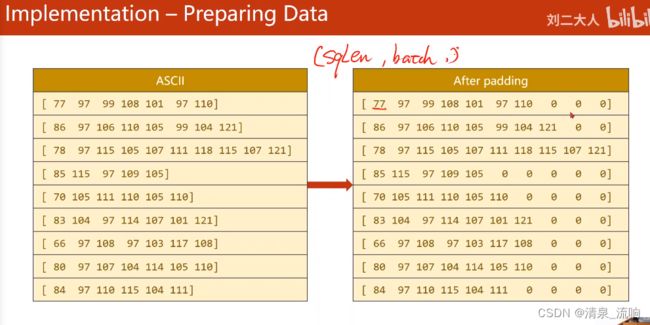
# padding 0
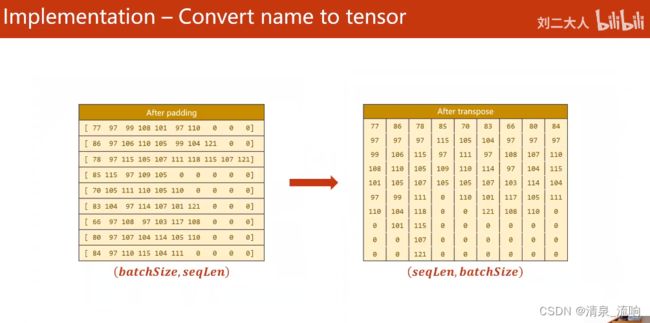
seq_tensor = torch.zeros(len(name_sequences),seq_lengths.max()).long()
for idx,(seq,seq_len) in enumerate(zip(name_sequences,seq_lengths),0):
seq_tensor[idx,:seq_len] = torch.LongTensor(seq)
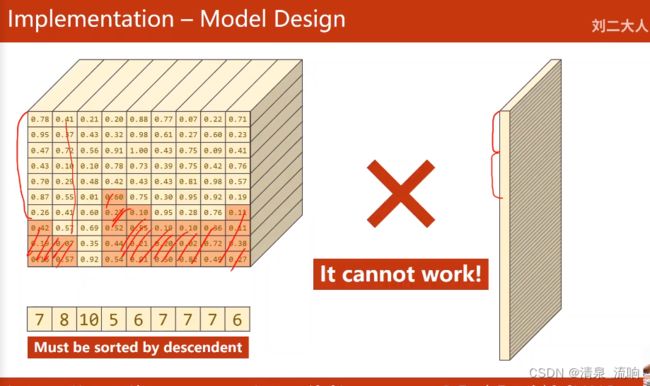
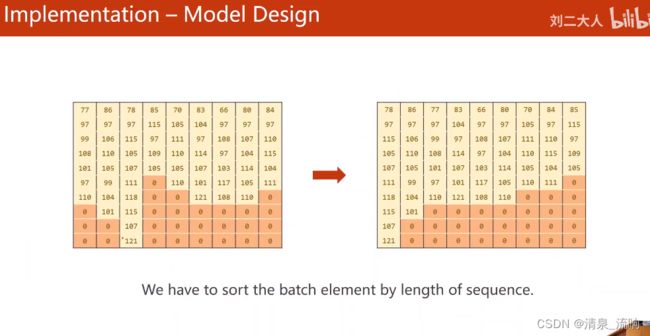
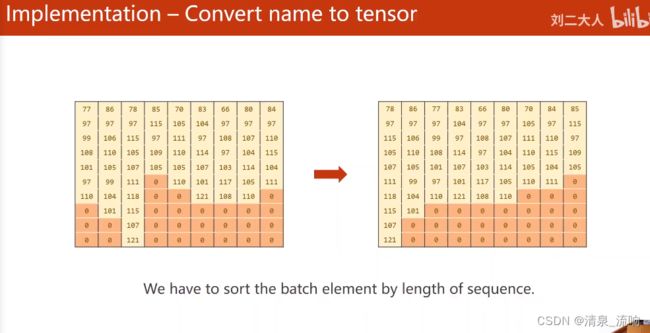
# 按照序列长度进行排序,最长的序列放前面
seq_lengths,perm_idx = seq_lengths.sort(dim=0,descending=True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx]
return create_tensor(seq_tensor),\
create_tensor(seq_lengths),\
create_tensor(countries)
def trainModel():
total_loss = 0
for i,(names,countries) in enumerate(trainloader,1):
inputs,seq_lengths,target = make_tensors(names,countries)
output = classifier(inputs,seq_lengths) # 分类器
loss = criterion(output,target) # 计算损失
optimizer.zero_grad() # 清零
loss.backward() # 反馈
optimizer.step() # 更新
total_loss += loss.item()
if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch}',end='')
print(f'[{i*len(inputs)}/{len(trainset)}]', end='')
print(f'loss={total_loss / (i*len(inputs))}')
return total_loss
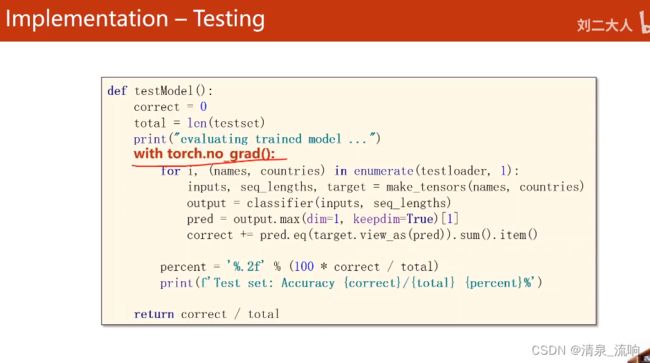
def testModel():
correct = 0
total = len(testset)
print("evaluating trained model ...")
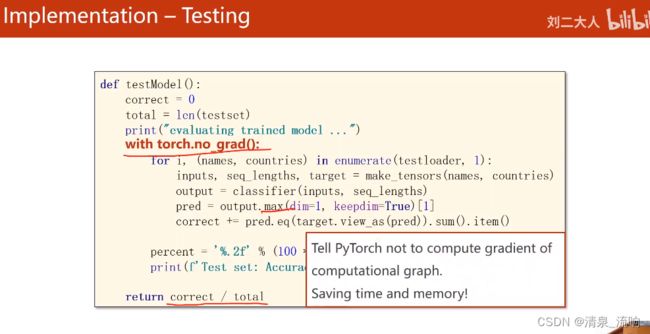
with torch.no_grad():
for i,(names,countries) in enumerate(testloader,1):
inputs,seq_lengths,target = make_tensors(names,countries)
output = classifier(inputs,seq_lengths)
pred = output.max(dim=1,keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
percent = '%.2f' % (100*correct / total)
print(f'Test set:Accuracy {correct}/{total} {percent}%')
return correct / total
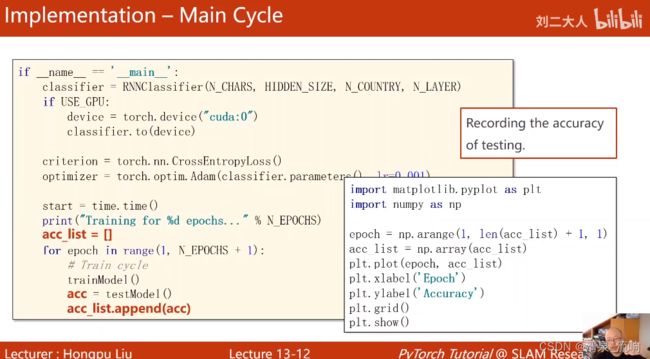
if __name__ == '__main__':
classifier = RNNClassifier(N_CHARS,HIDDEN_SIZE,N_COUNTRY,N_LAYER)
if USE_GPU:
device = torch.device("cuda:0")
classifier.to(device)
criterion = torch.nn.CrossEntropyLoss() # 构造损失函数
optimizer = torch.optim.Adam(classifier.parameters(),lr=0.001) # 构造优化器
start = time.time()
print("Training for %d epochs..." % N_EPOCHS)
acc_list=[]
for epoch in range(1,N_EPOCHS+1):
trainModel()
acc = testModel()
acc_list.append(acc)
epoch = np.arange(1,len(acc_list) + 1,1)
acc_list = np.array(acc_list)
plt.plot(epoch,acc_list)
plt.xlabel("Epoch")
plt.ylabel('Accuracy')
plt.grid()
plt.show()
运行结果如下:

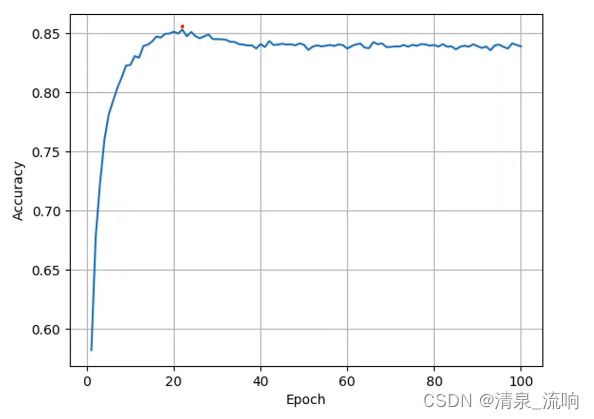
视频截图如下: