EPSANet: 卷积神经网络上的有效金字塔挤压注意力块
摘要:通过将注意力模块嵌入其中可以有效地提高深度卷积神经网络的性能。在这项工作中,提出了一种新颖的轻巧有效的注意方法,称为金字塔挤压注意 (PSA) 模块。通过在ResNet的瓶颈块中用PSA模块替换3x3卷积,获得了一种新颖的代表性块,称为有效金字塔挤压注意 (EPSA)。可以轻松地将EPSA块作为即插即用组件添加到完善的骨干网中,并且可以实现模型性能的显着改善。因此,通过堆叠这些ResNet风格的EPSA块,在这项工作中开发了一种简单有效的主干体系结构EPSANet。相应地,所提出的EPSANet可以为各种计算机视觉任务提供更强的多尺度表示能力,包括但不限于图像分类、对象检测、实例分割等。EPSANet的性能优于大多数最先进的渠道关注方法。
引言
注意机制广泛应用于许多计算机视觉领域,例如图像分类,对象检测,实例分割,语义分割,场景解析和动作定位 [1、2、3、4、5、6、7]。具体来说,注意方法有两种,即渠道注意和空间注意。最近,已经证明,通过采用渠道注意力,空间注意力或两者都可以实现显着的性能改进 [8,9,10,11,12]。最常用的渠道关注方法是挤压和引用 (SE) 模块 [13],它可以以相当低的成本显着提高性能。SENet的缺点在于它忽略了空间信息的重要性。因此,提出了瓶颈注意模块 (BAM) [14] 和卷积块注意模块 (CBAM) [5],通过有效结合空间和渠道注意来丰富注意图。然而,仍然存在两个重要且具有挑战性的问题。第一个是如何高效地捕获和利用不同尺度的特征图的空间信息,以丰富特征空间。第二个问题是,通道或空间注意力只能有效地捕获本地信息,但无法建立远程通道依赖性。相应地,提出了许多方法来解决这两个问题。提出了基于多尺度特征表示和跨通道信息交互的方法,例如PyConv [15],Res2Net [16] 和hs-resnet [17]。另一方面,可以建立远程信道依赖性,如 [2,18,19] 所示。但是,上述所有方法都带来了更高的模型复杂度,因此网络遭受了沉重的计算负担。根据以上观察,我们认为有必要开发一个低成本但有效的注意模块。在这项工作中,提出了一种名为金字塔挤压注意 (PSA) 的低成本高性能新颖模块。PSA模块具有在多个尺度上处理输入张量的能力。具体地,通过使用多尺度金字塔卷积结构来集成输入特征图的信息。同时,通过压缩输入张量的通道维数,可以有效地从每个通道特征图中提取不同尺度的空间信息。通过这样做,可以更精确地合并相邻尺度的上下文特征。最后,通过提取多尺度特征图的通道注意力权重来构建跨维度交互。使用Softmax操作来重新校准相应通道的注意力权重,从而建立了远程通道依赖性。结果,通过用ResNet瓶颈块中的PSA模块替换3x3卷积,获得了一种名为高效金字塔挤压注意 (EPSA) 的新型块。此外,通过将这些EPSA块堆叠为ResNet样式,提出了一个名为EPSANet的网络。如图1所示,所提出的EPSANet不仅在Top-1精度方面优于现有技术,而且在所需参数方面效率更高。
这项工作的主要贡献总结如下:
- 提出了一种新颖的高效金字塔挤压注意 (EPSA) 块,该块可以有效地提取多尺度空间信息,并发展出远程信道依赖性。所提出的EPSA模块非常灵活且可扩展,因此可以应用于各种各样的网络体系结构,用于计算机视觉的许多任务。
- 提出了一种名为EPSANet的新型主干体系结构,该体系结构可以学习更丰富的多尺度特征表示,并自适应地重新校准跨维度的通道注意力权重。
- 广泛的实验表明,所提出的EPSANet可以在ImageNet和COCO数据集上跨图像分类,对象检测和实例分割实现良好的效果
相关工作
注意力机制
注意机制用于加强信息最丰富的特征表达的分配,同时抑制不太有用的特征表达,从而使模型自适应地关注上下文中的重要区域。[13] 中的挤压和激励 (SE) 注意可以通过选择性地调制通道的规模来捕获通道相关性。[5] 中的CBAM通过为具有大尺寸内核的渠道注意力添加最大池特征来丰富注意力图。在CBAM的激励下,[20] 中的GSoP提出了一种二阶池化方法来提取更丰富的特征聚合。最近,提出了非本地块 [19] 来构建密集的空间特征图,并通过非本地操作捕获远程依赖性。基于非局部块,双注意网络 (A2Net) [8] 引入了一种新颖的关系函数,将具有空间信息的注意嵌入到特征图中。随后,[21] 中的SKNet引入了一种动态选择注意机制,该机制允许每个神经元根据输入特征图的多个尺度自适应地调整其感受野大小。ResNeSt [12] 提出了一个类似的拆分注意力块,该块可以跨输入特征图的组进行关注。Fcanet [9] 提出了一种新颖的多频谱信道注意,实现了频域信道注意机制的预处理。GCNet [1] 引入了一个简单的空间注意模块,因此开发了远程通道依赖性。ECANet [11] 采用一维卷积层来减少完全连接层的冗余。DANet [18] 通过将来自不同分支的这两个注意模块相加,自适应地将局部特征与其全局依赖关系集成在一起。上述方法要么专注于设计更复杂的注意力模块,这些模块不可避免地会带来更大的计算成本,要么无法建立远程信道依赖性。因此,为了进一步提高模型的效率和降低模型的复杂度,提出了一种新的关注模块PSA,该模块旨在学习低模型复杂度的注意力权重,并有效地将局部和全局注意力整合起来,建立远程信道依赖性。
多尺度表示
多尺度特征表示的能力对于各种视觉任务至关重要,例如实例分割 [22],人脸分析 [23],对象检测 [24],显着对象检测 [25] 和语义分割 [7]。设计一个可以更有效地提取多尺度特征以完成视觉识别任务的算子至关重要。通过将用于多尺度特征提取的算子嵌入到卷积神经网络 (CNN) 中,可以获得更有效的特征表示能力。另一方面,cnn可以通过一堆卷积算子自然地学习粗到细的多尺度特征。因此,设计更好的卷积算子是改进cnn多尺度表示的关键
方法
回顾SEnet
通道注意机制允许网络选择性地对每个通道的重要性进行加权,从而产生更多的信息性输出。SE块由两部分组成: 挤压和激励,分别用于编码全局信息和自适应地重新校准信道关系。通常,可以通过使用全局平均池化来生成信道统计信息,该全局平均池用于将全局空间信息嵌入到信道描述符中。
![]()
使用两个全连接的层,可以更有效地组合通道之间的线性信息,并且有助于高低通道尺寸信息的交互。符号 σ 表示激励函数,实践中通常使用Sigmoid函数。通过使用激励函数,我们可以在信道交互之后为信道分配权重,从而可以更有效地提取信息。
PSA模块
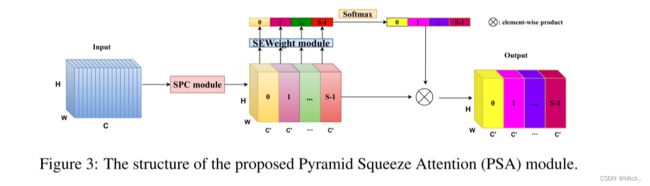
PSA模块主要通过四个步骤实现。
- 首先,通过SPC 模块,获得信道上的多尺度特征图。
- 其次,通过使用SEWeight模块提取具有不同比例的特征图的注意力,获得逐通道的注意力向量。
- 第三,通过使用Softmax重新校准通道注意向量来获得多尺度通道的重新校准权重。
- 第四,将元素乘积的操作应用于重新校准的权重和相应的特征图。最后,可以获得更丰富的多尺度特征信息的精细特征图作为输出。
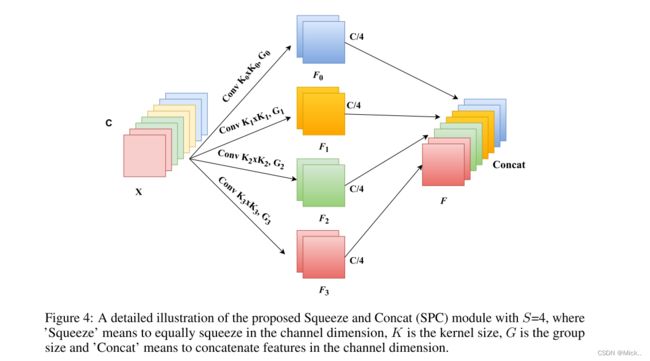
如图4所示,在提出的PSA中实现多尺度特征提取的基本算子是SPC,我们以多分支的方式提取输入特征图的空间信息,每个分支的输入通道维数为C。对于每个分支,它独立地学习多尺度空间信息,并以本地方式建立跨通道交互。但是,随着内核大小的增加,参数数量将大大提高。为了在不增加计算成本的情况下以不同的核尺度处理输入张量,引入了一种群卷积方法。此外,我们设计了一种新颖的准则,用于在不增加参数数量的情况下选择组大小。
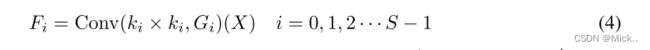
![]()
![]()
所述SEWeight模块用于从不同尺度的输入特征图中获取注意力权重。通过这样做,我们的PSA模块可以融合不同尺度的上下文信息,并为高级特征图产生更好的像素级注意力。进一步地,为了实现注意信息的交互,在不破坏原始信道注意向量的情况下融合跨维度向量。从而以串联的方式获得整个多尺度信道注意向量。
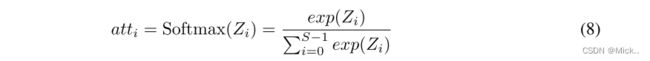
其中Softmax用于获得多尺度通道的重新校准权重atti,其中包含空间上的所有位置信息和通道中的注意权重。通过这样做,实现了本地和全球渠道注意力之间的交互。接下来,将特征重新校准的通道注意以串联的方式进行融合和拼接,从而可以得到整个通道注意向量为
![]()
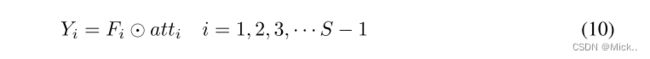
import torch
import torch.nn as nn
import math
class SEWeightModule(nn.Module):
def __init__(self, channels, reduction=16):
super(SEWeightModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(channels, channels//reduction, kernel_size=1, padding=0)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(channels//reduction, channels, kernel_size=1, padding=0)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.avg_pool(x)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
weight = self.sigmoid(out)
return weight
def conv(in_planes, out_planes, kernel_size=3, stride=1, padding=1, dilation=1, groups=1):
"""standard convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=False)
class PSAModule(nn.Module):
def __init__(self, input_channels, out_channels, conv_kernels=[3, 5, 7, 9], stride=1, conv_groups=[1, 4, 8, 16]):
super(PSAModule, self).__init__()
#四个不同大小的卷积核,采用的是分组卷积。
self.conv_1 = conv(input_channels, out_channels // 4, kernel_size=conv_kernels[0], padding=conv_kernels[0] // 2,
stride=stride, groups=conv_groups[0])
self.conv_2 = conv(input_channels, out_channels // 4, kernel_size=conv_kernels[1], padding=conv_kernels[1] // 2,
stride=stride, groups=conv_groups[1])
self.conv_3 = conv(input_channels, out_channels // 4, kernel_size=conv_kernels[2], padding=conv_kernels[2] // 2,
stride=stride, groups=conv_groups[2])
self.conv_4 = conv(input_channels, out_channels // 4, kernel_size=conv_kernels[3], padding=conv_kernels[3] // 2,
stride=stride, groups=conv_groups[3])
self.se = SEWeightModule(out_channels // 4)
self.split_channel = out_channels // 4
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
batch_size = x.shape[0]
x1 = self.conv_1(x)
x2 = self.conv_2(x)
x3 = self.conv_3(x)
x4 = self.conv_4(x)
feats = torch.cat((x1, x2, x3, x4), dim=1)
feats = feats.view(batch_size, 4, self.split_channel, feats.shape[2], feats.shape[3])
x1_se = self.se(x1)
x2_se = self.se(x2)
x3_se = self.se(x3)
x4_se = self.se(x4)
x_se = torch.cat((x1_se, x2_se, x3_se, x4_se), dim=1)
attention_vectors = x_se.view(batch_size, 4, self.split_channel, 1, 1)
attention_vectors = self.softmax(attention_vectors)
feats_weight = feats * attention_vectors
for i in range(4):
x_se_weight_fp = feats_weight[:, i, :, :]
if i == 0:
out = x_se_weight_fp
else:
out = torch.cat((x_se_weight_fp, out), 1)
return out
if __name__=='__main__':
model=PSAModule(input_channels=64, out_channels=64)
input=torch.randn(1,64,64,64)
output=model(input)
print(output.shape)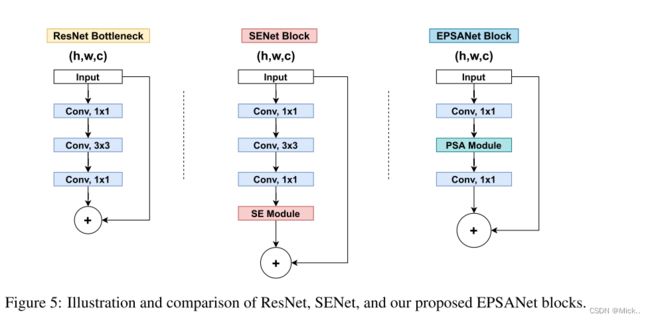
上图介绍了三个不同的resnet风格的残差块。
参考文献:
murufeng/EPSANet (github.com)
EPSANet: 一种高效的多尺度通道注意力机制,主要提出了金字塔分割注意力模块,即插即用,效果显著,已开源! - 知乎 (zhihu.com)
import torch
import torch.nn as nn
import math
class SEWeightModule(nn.Module):
def __init__(self, channels, reduction=16):
super(SEWeightModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(channels, channels//reduction, kernel_size=1, padding=0)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(channels//reduction, channels, kernel_size=1, padding=0)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.avg_pool(x)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
weight = self.sigmoid(out)
return weight
def conv(in_planes, out_planes, kernel_size=3, stride=1, padding=1, dilation=1, groups=1):
"""standard convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class PSAModule(nn.Module):
def __init__(self, inplans, planes, conv_kernels=[3, 5, 7, 9], stride=1, conv_groups=[1, 4, 8, 16]):
super(PSAModule, self).__init__()
self.conv_1 = conv(inplans, planes//4, kernel_size=conv_kernels[0], padding=conv_kernels[0]//2,
stride=stride, groups=conv_groups[0])
self.conv_2 = conv(inplans, planes//4, kernel_size=conv_kernels[1], padding=conv_kernels[1]//2,
stride=stride, groups=conv_groups[1])
self.conv_3 = conv(inplans, planes//4, kernel_size=conv_kernels[2], padding=conv_kernels[2]//2,
stride=stride, groups=conv_groups[2])
self.conv_4 = conv(inplans, planes//4, kernel_size=conv_kernels[3], padding=conv_kernels[3]//2,
stride=stride, groups=conv_groups[3])
self.se = SEWeightModule(planes // 4)
self.split_channel = planes // 4
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
batch_size = x.shape[0]
x1 = self.conv_1(x)
x2 = self.conv_2(x)
x3 = self.conv_3(x)
x4 = self.conv_4(x)
feats = torch.cat((x1, x2, x3, x4), dim=1)
feats = feats.view(batch_size, 4, self.split_channel, feats.shape[2], feats.shape[3])
x1_se = self.se(x1)
x2_se = self.se(x2)
x3_se = self.se(x3)
x4_se = self.se(x4)
x_se = torch.cat((x1_se, x2_se, x3_se, x4_se), dim=1)
attention_vectors = x_se.view(batch_size, 4, self.split_channel, 1, 1)
attention_vectors = self.softmax(attention_vectors)
feats_weight = feats * attention_vectors
for i in range(4):
x_se_weight_fp = feats_weight[:, i, :, :]
if i == 0:
out = x_se_weight_fp
else:
out = torch.cat((x_se_weight_fp, out), 1)
return out
class EPSABlock(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, norm_layer=None, conv_kernels=[3, 5, 7, 9],
conv_groups=[1, 4, 8, 16]):
super(EPSABlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, planes)
self.bn1 = norm_layer(planes)
self.conv2 = PSAModule(planes, planes, stride=stride, conv_kernels=conv_kernels, conv_groups=conv_groups)
self.bn2 = norm_layer(planes)
self.conv3 = conv1x1(planes, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class EPSANet(nn.Module):
def __init__(self,block, layers, num_classes=1000):
super(EPSANet, self).__init__()
self.inplanes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layers(block, 64, layers[0], stride=1)
self.layer2 = self._make_layers(block, 128, layers[1], stride=2)
self.layer3 = self._make_layers(block, 256, layers[2], stride=2)
self.layer4 = self._make_layers(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layers(self, block, planes, num_blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, num_blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
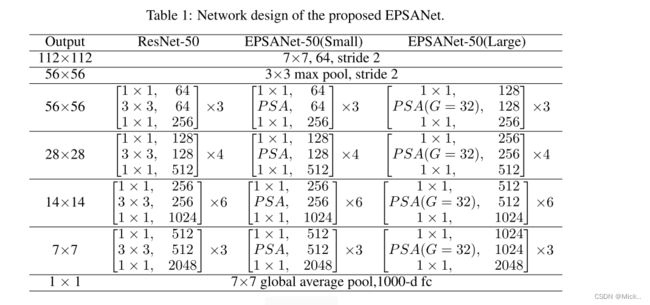
def epsanet50():
model = EPSANet(EPSABlock, [3, 4, 6, 3], num_classes=1000)
return model
def epsanet101():
model = EPSANet(EPSABlock, [3, 4, 23, 3], num_classes=1000)
return model