机器学习算法(七):支持向量机SVM
目录
1 SVM基本概念
2 硬间隔支持向量机
2.1 SVM的基本型
2.2 SVM求解
2.2.1 SVM拉格朗日对偶问题
2.2.2 为什么支持向量机要用拉格朗日对偶算法来解最大化间隔问题?
2.2.3 SVM问题的KKT条件
2.3 有约束最优化问题的数学模型
2.3.1 有约束优化问题的几何意象
2.3.2 拉格朗日乘子法
2.3.3 KKT条件
2.3.4 拉格朗日对偶
2.3.5 拉格朗日对偶函数示例
3 软间隔支持向量机
4 非线性支持向量机
5 支持向量回归SVR
6 常用核函数
7. SVM的优缺点
8 SMO算法
1 SVM基本概念
SVM的全称是Support Vector Machine,即支持向量机,主要用于解决模式识别领域中的数据分类问题,属于有监督学习算法的一种。其基本模型是在特征空间上找到最佳的分离超平面使得训练集上正负样本间隔最大。SVM是用来解决二分类问题的有监督学习算法,在引入了核方法之后SVM也可以用来解决非线性问题。
一般SVM有下面三种:
- 硬间隔支持向量机(线性可分支持向量机):当训练数据线性可分时,可通过硬间隔最大化学得一个线性可分支持向量机。
- 软间隔支持向量机:当训练数据近似线性可分时,可通过软间隔最大化学得一个线性支持向量机。
- 非线性支持向量机:当训练数据线性不可分时,可通过核方法以及软间隔最大化学得一个非线性支持向量机。
2 硬间隔支持向量机
2.1 SVM的基本型
给定训练样本集![]() ,i表示第i个样本,n表示样本容量。分类学习最基本的想法就是基于训练集D在特征空间中找到一个最佳划分超平面将正负样本分开,而SVM算法解决的就是如何找到最佳超平面的问题。超平面可通过如下的线性方程来描述:
,i表示第i个样本,n表示样本容量。分类学习最基本的想法就是基于训练集D在特征空间中找到一个最佳划分超平面将正负样本分开,而SVM算法解决的就是如何找到最佳超平面的问题。超平面可通过如下的线性方程来描述:
![]()
其中![]() 表示法向量,决定了超平面的方向;b表示偏移量,决定了超平面与原点之间的距离。
表示法向量,决定了超平面的方向;b表示偏移量,决定了超平面与原点之间的距离。
对于训练数据集D假设找到了最佳超平面![]() ,定义决策分类函数
,定义决策分类函数

该分类决策函数也称为线性可分支持向量机。
在测试时对于线性可分支持向量机可以用一个样本离划分超平面的距离来表示分类预测的可靠程度,如果样本离划分超平面越远则对该样本的分类越可靠,反之就不那么可靠。
那么,什么样的划分超平面是最佳超平面呢?
对于图1有A、B、C三个超平面,很明显应该选择超平面B,也就是说超平面首先应该能满足将两类样本点分开。
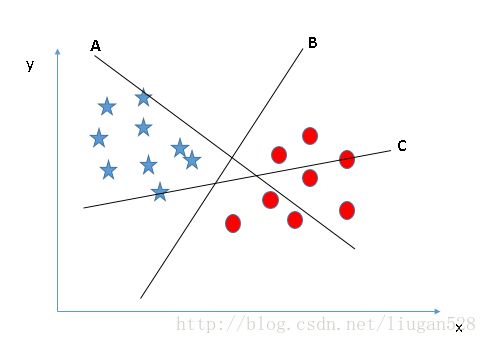
图1
对于图2的A、B、C三个超平面,应该选择超平面C,因为使用超平面C进行划分对训练样本局部扰动的“容忍”度最好,分类的鲁棒性最强。例如,由于训练集的局限性或噪声的干扰,训练集外的样本可能比图2中的训练样本更接近两个类目前的分隔界,在分类决策的时候就会出现错误,而超平面C受影响最小,也就是说超平面C所产生的分类结果是最鲁棒性的、是最可信的,对未见样本的泛化能力最强。
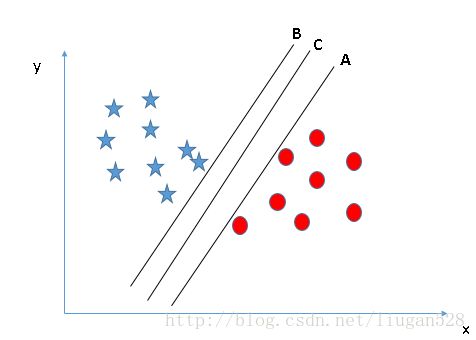
图2
下面以图3中示例进行推导得出最佳超平面。
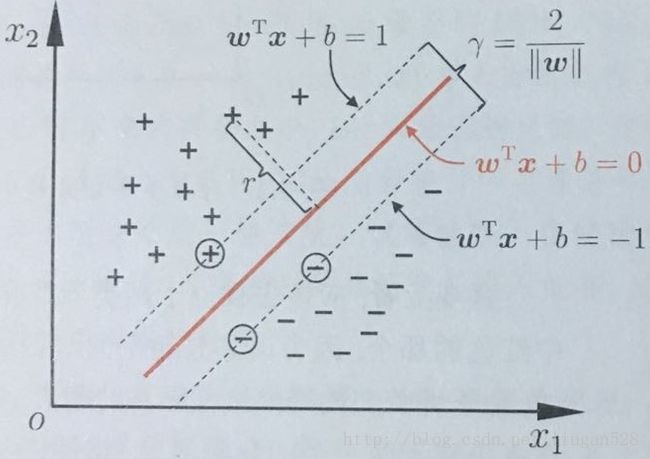
图3
空间中超平面可记为![]() ,根据点到平面的距离公式,空间中任意点
,根据点到平面的距离公式,空间中任意点![]() 到超平面
到超平面![]() 的距离可写为:
的距离可写为:

这里 是向量的模,表示在空间中向量的长度。假设超平面
是向量的模,表示在空间中向量的长度。假设超平面![]() 能将训练样本正确分类,那么对于正样本一侧的任意一个样本
能将训练样本正确分类,那么对于正样本一侧的任意一个样本![]() ,应该需要满足该样本点往超平面的法向量
,应该需要满足该样本点往超平面的法向量 (法向量,是空间解析几何的一个概念,垂直于平面的直线所表示的向量为该平面的法向量。)的投影到原点的距离大于一定值c的时候使得该样本点被预测为正样本一类,即存在数值c使得当
(法向量,是空间解析几何的一个概念,垂直于平面的直线所表示的向量为该平面的法向量。)的投影到原点的距离大于一定值c的时候使得该样本点被预测为正样本一类,即存在数值c使得当![]() 时
时![]() 。
。![]() 又可写为
又可写为![]() 。在训练的时候我们要求限制条件更严格点以使最终得到的分类器鲁棒性更强,所以我们要求
。在训练的时候我们要求限制条件更严格点以使最终得到的分类器鲁棒性更强,所以我们要求 。也可以写为大于其它距离,但都可以通过同比例缩放和b来使得使其变为1,因此为计算方便这里直接选择1。同样对于负样本应该有
。也可以写为大于其它距离,但都可以通过同比例缩放和b来使得使其变为1,因此为计算方便这里直接选择1。同样对于负样本应该有![]() 时
时 。
。

公式(4)可以认为是SVM优化问题的约束条件的基本描述。
亦即:

如图3所示,距离最佳超平面![]() 最近的几个训练样本点使上式中的等号成立,它们被称为“支持向量”(support vector)。记超平面
最近的几个训练样本点使上式中的等号成立,它们被称为“支持向量”(support vector)。记超平面![]() 和
和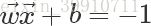 之间的距离为
之间的距离为![]() ,该距离又被称为“间隔”(margin),SVM的核心之一就是想办法将“间隔”
,该距离又被称为“间隔”(margin),SVM的核心之一就是想办法将“间隔”![]() 最大化。
最大化。
下面我们推导一下![]() 与哪些因素有关:
与哪些因素有关:
注:

记超平面![]() 上的正样本为
上的正样本为![]() ,超平面上的负样本为
,超平面上的负样本为 ,则根据向量的加减法规则
,则根据向量的加减法规则![]() 减去得到的向量在最佳超平面的法向量方向的投影即为“间隔”
减去得到的向量在最佳超平面的法向量方向的投影即为“间隔”![]() :
:

而![]() ,,即:
,,即:

将(7)带入(6)可得:

也就是说使两类样本距离最大的因素仅仅和最佳超平面的法向量有关!
要找到具有“最大间隔”(maximum margin)的最佳超平面,就是找到能满足式(4)中约束的参数、b使得![]() 最大,即:
最大,即:

显然(9)等价于

这就是SVM的基本型。
2.2 SVM求解
2.2.1 SVM拉格朗日对偶问题
根据SVM的基本型求解出和b即可得到最佳超平面对应的模型:
![]() (2.1)
(2.1)
sign(x)或者Sign(x)叫做符号函数,在数学和计算机运算中,其功能是取某个数的符号(正或负):
- 当x>0,sign(x)=1;
- 当x=0,sign(x)=0;
- 当x<0, sign(x)=-1;
在通信中,sign(t)表示这样一种信号:
- 当t≥0,sign(t)=1; 即从t=0时刻开始,信号的幅度均为1;
- 当t<0, sign(t)=-1;在t=0时刻之前,信号幅度均为-1
该求解问题本身是一个凸二次规划(convex quadratic propgramming)问题,可以通过开源的优化计算包进行求解,我们可以将该凸二次规划问题通过拉格朗日对偶性来解决。


可知我们并不关心单个样本是如何的,我们只关心样本间两两的乘积,这也为后面核方法提供了很大的便利。
求解出![]() 之后,再求解出和b即可得到SVM决策模型:
之后,再求解出和b即可得到SVM决策模型:
 (2.5)
(2.5)
2.2.2 为什么支持向量机要用拉格朗日对偶算法来解最大化间隔问题?
用拉格朗日对偶并没有改变最优解,而是改变了算法复杂度:
- 在原问题下,求解算法的复杂度与样本维度(等于权值w的维度)有关;
- 而在对偶问题下,求解算法的复杂度与样本数量(等于拉格朗日算子a的数量)有关。
因此,如果你是做线性分类,且样本维度低于样本数量的话,在原问题下求解就好了,Liblinear之类的线性SVM默认都是这样做的;
但如果你是做非线性分类,那就会涉及到升维(比如使用高斯核做核函数,其实是将样本升到无穷维),升维后的样本维度往往会远大于样本数量,此时显然在对偶问题下求解会更好。
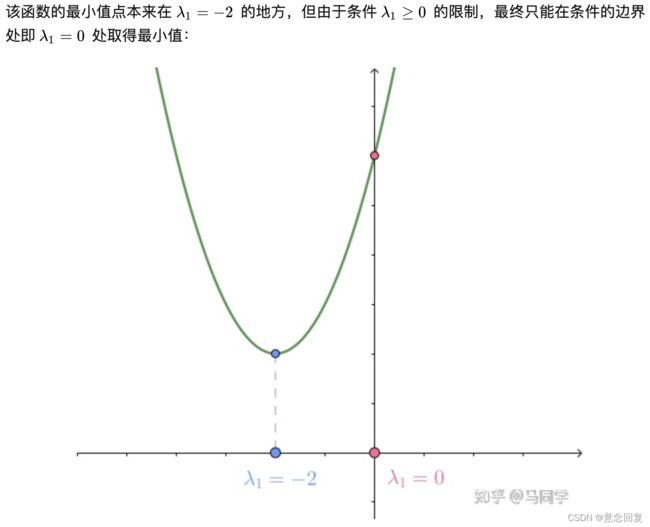
- 问题1:一般问题为什么要用拉格朗日对偶 ?
- 问题2:SVM用拉格朗日乘子法在求解以及表示(非线性支持向量机)的好处?
为了不出现歧义,约定:
- 原问题是包含不等式(等式)约束的求最小值问题,原问题可以等价为min max(极小极大问题)
- 对偶问题最终形式是max min(极大极小问题)
答:
问题1:一般问题为什么要用拉格朗日对偶,一般我们常用的解决极小值的方法是各种下降,包括梯度下降,随机梯度下降,坐标轴下降等等,但是这里有个隐含的要求:该问题是一个凸问题,否则会陷入局部最优。
可以证明原问题无论是怎样的问题,对偶问题一定是一个凸问题,并且对偶问题的解一定是原问题解的一个下界。求问为什么对偶问题一定是凸优化问题? - 知乎
根据原问题是否满足Slater条件,对偶可能是强对偶或者弱对偶,如果是强对偶那么问题直接得到结果。
如果是弱对偶那么对偶问题给出的是一个下界,这里通过不停构造更大的下界来求得原问题的最小值(很多优化算法都是这样的思路)
问题2:SVM用拉格朗日乘子法的好处
原问题转换为对偶问题后,可以使用SMO算法,是二次规划问题,二次规划问题相对是有成熟的方法来解决。
原问题转换为对偶问题后,支持向量会更加清晰,并且出现内积,非线性问题的方法(核函数)自然就被引入了。
1 原算法与对偶算法
对于支持向量机而言,对偶算法是借助拉格朗日对偶性从原算法(Primal Problem)推出的,两者完全等价,只是求解了不同的条件极值(下面是硬间隔支持向量机的原算法和对偶算法):
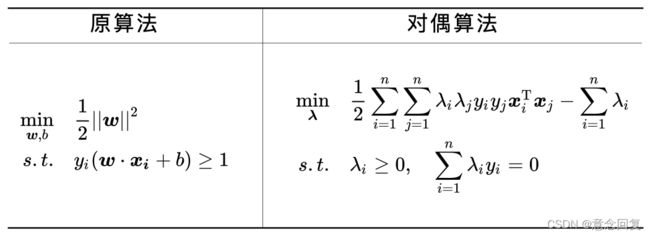
从上面的对比可以看出,对偶算法主要有三点改进使得决策边界的求解不再困难:
- 对偶算法中没有
 和
和  ,这样求解比较简单
,这样求解比较简单 - 对偶算法限制条件中的
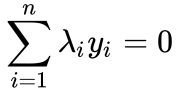 很容易消去,在后面的例子中可以看到
很容易消去,在后面的例子中可以看到 - 更重要的是,原算法的限制条件为较为复杂的线性不等式
 ,而消去
,而消去 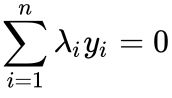 的对偶算法,其限制条件只为简单的
的对偶算法,其限制条件只为简单的 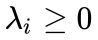 ,这会极大地降低求解的难度。
,这会极大地降低求解的难度。
这么说可能不太直观,下面会用例子来进一步说明。
2 例子
假设数据集![]() 为:
为:
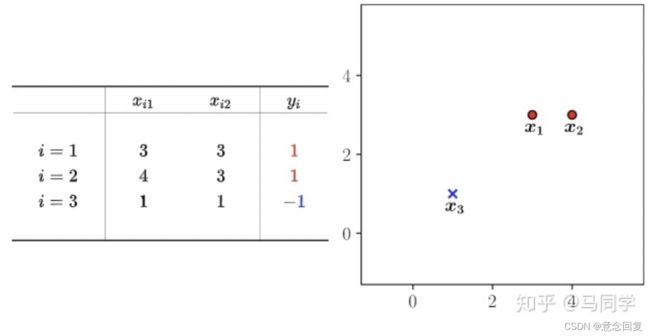
下面会通过原算法、对偶算法来分别计算硬间隔支持向量机的决策边界。
3 原算法求解
很多资料都没介绍原算法怎么计算,主要是因为原算法中的限制条件为较为复杂的线性不等式 ![]() ,要正儿八经地去计算要涉及到二次规划中较为复杂的理论。本文也没有打算正面去计算,下面的计算过程会用到一些技巧。
,要正儿八经地去计算要涉及到二次规划中较为复杂的理论。本文也没有打算正面去计算,下面的计算过程会用到一些技巧。






4 对偶算法求解
对偶算法的限制条件比较简单,看上去过程也较多,但只要按部就班就可以解出。




为什么支持向量机要用拉格朗日对偶算法来解最大化间隔问题? - 知乎
2.2.3 SVM问题的KKT条件
拉格朗日乘子法和KKT条:拉格朗日乘子法和KKT条件_意念回复的博客-CSDN博客
在(10)中有不等式约束,因此上述过程满足Karush-Kuhn-Tucker(KKT)条件:
 (2.6)
(2.6)
对于任意样本![]() 总有
总有![]() 或
或![]() 。如果
。如果![]() 则由式(2.5)可知该样本点对求解最佳超平面没有任何影响。当
则由式(2.5)可知该样本点对求解最佳超平面没有任何影响。当![]() 时必有
时必有![]() ,表明对应的样本点在最大间隔边界上,即对应着支持向量。也由此得出了SVM的一个重要性质:训练完成之后,大部分的训练样本都不需要保留,最终的模型仅与支持向量有关。
,表明对应的样本点在最大间隔边界上,即对应着支持向量。也由此得出了SVM的一个重要性质:训练完成之后,大部分的训练样本都不需要保留,最终的模型仅与支持向量有关。
那么对于式(2.4)该如何求解![]() 呢?很明显这是一个二次规划问题,可使用通用的二次规划算法来求解,但是SVM的算法复杂度是
呢?很明显这是一个二次规划问题,可使用通用的二次规划算法来求解,但是SVM的算法复杂度是![]() ,在实际问题中这种开销太大了。为了有效求解该二次规划问题,人们通过利用问题本身的特性,提出了很多高效算法,Sequential Minimal Optimization(SMO)就是一个常用的高效算法。在利用SMO算法进行求解的时候就需要用到上面的KKT条件。利用SMO算法求出
,在实际问题中这种开销太大了。为了有效求解该二次规划问题,人们通过利用问题本身的特性,提出了很多高效算法,Sequential Minimal Optimization(SMO)就是一个常用的高效算法。在利用SMO算法进行求解的时候就需要用到上面的KKT条件。利用SMO算法求出![]() 之后根据:
之后根据:
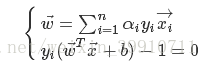 (2.7)
(2.7)
即可求出和b。求解出和b之后就可利用。
 (2.8)
(2.8)
进行预测分类了,注意在测试的时候不需要−1,测试时没有训练的时候要求严格。
2.3 有约束最优化问题的数学模型
SVM问题是一个不等式约束条件下的优化问题。
下面讲解的思路以及重点关注哪些问题:
1)有约束优化问题的几何意象:闭上眼睛你看到什么?
2)拉格朗日乘子法:约束条件怎么跑到目标函数里面去了?
3)KKT条件:约束条件是不等式该怎么办?
4)拉格朗日对偶:最小化问题怎么变成了最大化问题?
5)实例演示:拉格朗日对偶函数到底啥样子?
6)SVM优化算法的实现:数学讲了辣么多,到底要怎么用啊?
2.3.1 有约束优化问题的几何意象
约束条件一般分为等式约束和不等式约束两种,前者表示为
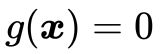
(注意这里的跟第二章里面的样本x没有任何关系,只是一种通用的表示);后者表示为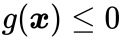 (你可能会问为什么不是
(你可能会问为什么不是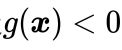 ,别着急,到KKT那里你就明白了)。
,别着急,到KKT那里你就明白了)。
(1)等式约束
假设 (就是这个向量一共有d个标量组成),则
(就是这个向量一共有d个标量组成),则![]() 的几何意象就是d维空间中的d-1维曲面,如果函数是线性的,则是个d-1维的超平面。那么有约束优化问题就要求在这个d-1维的曲面或者超平面上找到能使得目标函数最小的点,这个d-1维的曲面就是“可行解区域”。
的几何意象就是d维空间中的d-1维曲面,如果函数是线性的,则是个d-1维的超平面。那么有约束优化问题就要求在这个d-1维的曲面或者超平面上找到能使得目标函数最小的点,这个d-1维的曲面就是“可行解区域”。
(2)不等式约束
对于不等式约束条件, ,则可行解区域从d-1维曲面扩展成为d维空间的一个子集。我们可以从d=2的二维空间进行对比理解。等式约束对应的可行解空间就是一条线;不等式约束对应的则是这条线以及线的某一侧对应的区域,就像下面这幅图的样子(图中的目标函数等高线其实就是等值线,在同一条等值线上的点对应的目标函数值相同)。
,则可行解区域从d-1维曲面扩展成为d维空间的一个子集。我们可以从d=2的二维空间进行对比理解。等式约束对应的可行解空间就是一条线;不等式约束对应的则是这条线以及线的某一侧对应的区域,就像下面这幅图的样子(图中的目标函数等高线其实就是等值线,在同一条等值线上的点对应的目标函数值相同)。
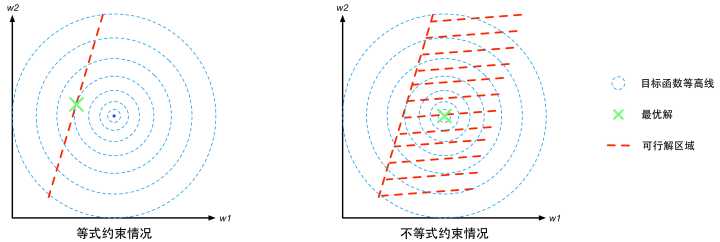
图4 有约束优化问题的几何意象图
2.3.2 拉格朗日乘子法
首先定义原始目标函数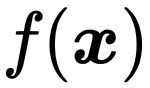 ,拉格朗日乘子法的基本思想是把约束条件转化为新的目标函数的一部分(关于的意义我们一会儿再解释),从而使有约束优化问题变成我们习惯的无约束优化问题。那么该如何去改造原来的目标函数使得新的目标函数的最优解恰好就在可行解区域中呢?这需要我们去分析可行解区域中最优解的特点。
,拉格朗日乘子法的基本思想是把约束条件转化为新的目标函数的一部分(关于的意义我们一会儿再解释),从而使有约束优化问题变成我们习惯的无约束优化问题。那么该如何去改造原来的目标函数使得新的目标函数的最优解恰好就在可行解区域中呢?这需要我们去分析可行解区域中最优解的特点。
1)最优解的特点分析
这里比较有代表性的是等式约束条件(不等式约束条件的情况我们在KKT条件里再讲)。我们观察一下图4中的红色虚线(可行解空间)和蓝色虚线(目标函数的等值线),发现这个被约束的最优解恰好在二者相切的位置。为了解释这一点,我们先介绍梯度的概念。梯度可以直观的认为是函数的变化量,可以描述为包含变化方向和变化幅度的一个向量。然后我们给出一个推论:
① 推论1:在等式约束条件下的优化问题的最优解x,原始目标函数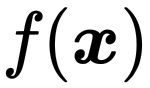 的梯度向量必然与约束条件的切线方向垂直。”
的梯度向量必然与约束条件的切线方向垂直。”
关于推论1的粗浅的论证如下:
如果梯度矢量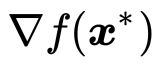 不垂直于在
不垂直于在 点的切线方向,就会在
点的切线方向,就会在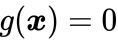 的切线方向上存在不等于0的分量,也就是说在相遇点
的切线方向上存在不等于0的分量,也就是说在相遇点![]() 附近,
附近,![]() 还在沿着
还在沿着![]() 变化。这意味在上
变化。这意味在上![]() 这一点的附近一定有一个点的函数值比
这一点的附近一定有一个点的函数值比![]() 更小,那么就不会是那个约束条件下的最优解了。所以,梯度向量必然与约束条件的切线方向垂直。
更小,那么就不会是那个约束条件下的最优解了。所以,梯度向量必然与约束条件的切线方向垂直。
② 推论2:“函数的梯度方向也必然与函数自身等值线切线方向垂直。”
推论2的粗浅论证:与推论1 的论证基本相同,如果的梯度方向不垂直于该点等值线的切线方向,就会在等值线上有变化,这条线也就不能称之为等值线了。
根据推论1和推论2,函数的梯度方向在点同时垂直于约束条件和自身的等值线的切线方向,也就是说函数的等值线与约束条件曲线在点具有相同(或相反)的法线方向,所以它们在该点也必然相切。
让我们再进一步,约束条件也可以被视为函数的一条等值线。按照推论2中“函数的梯度方向必然与自身的等值线切线方向垂直”的说法,函数在点的梯度矢量也与的切线方向垂直。
到此我们可以将目标函数和约束条件视为两个具有平等地位的函数,并得到推论3:
③ 推论3:“函数与![]() 函数的等值线在最优解点处相切,即两者在
函数的等值线在最优解点处相切,即两者在![]() 点的梯度方向相同或相反”,于是我们可以写出公式(11),用来描述最优解的一个特性:
点的梯度方向相同或相反”,于是我们可以写出公式(11),用来描述最优解的一个特性:
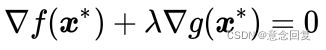 (11)
(11)
这里增加了一个新变量 ,用来描述两个梯度矢量的长度比例。那么是不是有了公式(11)就能确定的具体数值了呢?显然不行!从代数解方程的角度看,公式(11)相当于d个方程(假设是d维向量,函数的梯度就是d个偏导数组成的向量,而未知数除了的d个分量以外,还有1个
,用来描述两个梯度矢量的长度比例。那么是不是有了公式(11)就能确定的具体数值了呢?显然不行!从代数解方程的角度看,公式(11)相当于d个方程(假设是d维向量,函数的梯度就是d个偏导数组成的向量,而未知数除了的d个分量以外,还有1个 。所以相当于用d个方程求解d+1个未知量,应有无穷多组解;从几何角度看,在任意曲线(k为值域范围内的任意实数)上都能至少找到一个满足公式(11)的点,也就是可以找到无穷多个这样的相切点。所以我们还需要增加一点限制,使得无穷多个解变成一个解。好在这个限制是现成的,那就是:
。所以相当于用d个方程求解d+1个未知量,应有无穷多组解;从几何角度看,在任意曲线(k为值域范围内的任意实数)上都能至少找到一个满足公式(11)的点,也就是可以找到无穷多个这样的相切点。所以我们还需要增加一点限制,使得无穷多个解变成一个解。好在这个限制是现成的,那就是:
 (12)
(12)
把公式(11)和(12)放在一起,我们有d+1个方程,解d+1个未知数,方程有唯一解,这样就能找到这个最优点了。
2)构造拉格朗日函数
虽然根据公式(11)和(12),已经可以求出等式约束条件下的最优解了,但为了在数学上更加便捷和优雅一点,我们按照本节初提到的思想,构造一个拉格朗日函数,将有约束优化问题转为无约束优化问题。拉格朗日函数具体形式如下:
 (13)
(13)
新的拉格朗日目标函数有两个自变量 ,根据我们熟悉的求解无约束优化问题的思路,将公式(13)分别对求导,令结果等于零,就可以建立两个方程。很容易就能发现这两个由导数等于0构造出来的方程正好就是公式(11)和(12)。说明新构造的拉格朗日目标函数的优化问题完全等价于原来的等式约束条件下的优化问题。
,根据我们熟悉的求解无约束优化问题的思路,将公式(13)分别对求导,令结果等于零,就可以建立两个方程。很容易就能发现这两个由导数等于0构造出来的方程正好就是公式(11)和(12)。说明新构造的拉格朗日目标函数的优化问题完全等价于原来的等式约束条件下的优化问题。
但是,如何求解约束条件是不等式的问题?
2.3.3 KKT条件
对于不等式约束条件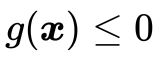 的情况,如图5所示,最优解所在的位置有两种可能,或者在边界曲线上或者在可行解区域内部满足不等式
的情况,如图5所示,最优解所在的位置有两种可能,或者在边界曲线上或者在可行解区域内部满足不等式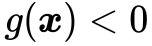 的地方。
的地方。

图5:不等式约束条件下最优解位置分布的两种情况
① 第一种情况:最优解在边界上,就相当于约束条件就是。参考图5,注意此时目标函数的最优解在可行解区域外面,所以函数在最优解附近的变化趋势是“在可行解区域内侧较大而在区域外侧较小”,与之对应的是函数![]() 在可行解区域内小于0,在区域外大于零,所以在最优解附近的变化趋势是内部较小而外部较大。这意味着目标函数的梯度方向与约束条件函数
在可行解区域内小于0,在区域外大于零,所以在最优解附近的变化趋势是内部较小而外部较大。这意味着目标函数的梯度方向与约束条件函数![]() 的梯度方向相反。因此根据公式(11),可以推断出参数
的梯度方向相反。因此根据公式(11),可以推断出参数![]() 。
。
② 第二种情况:如果在区域内,则相当于约束条件没有起作用,因此公式(13)的拉格朗日函数中的参数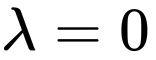 。整合这两种情况,可以写出一个约束条件的统一表达,如公式(14)所示。
。整合这两种情况,可以写出一个约束条件的统一表达,如公式(14)所示。
 (14)
(14)
其中第一个式子是约束条件本身。第二个式子是对拉格朗日乘子 的描述。第三个式子是第一种情况和第二种情况的整合:在第一种情况里,
的描述。第三个式子是第一种情况和第二种情况的整合:在第一种情况里,![]() ;在第二种情况下,
;在第二种情况下,![]() 。所以无论哪一种情况都有。公式(14)就称为Karush-Kuhn-Tucker条件,简称KKT条件。
。所以无论哪一种情况都有。公式(14)就称为Karush-Kuhn-Tucker条件,简称KKT条件。
推导除了KKT条件,感觉有点奇怪。因为本来问题的约束条件就是一个,怎么这个KKT条件又多弄出来两条,这不是让问题变得更复杂了吗?这里我们要适当的解释一下:
1)KKT条件是对最优解的约束,而原始问题中的约束条件是对可行解的约束。
2)KKT条件的推导对于后面马上要介绍的拉格朗日对偶问题的推导很重要。
2.3.4 拉格朗日对偶
按照前面等式约束条件下的优化问题的求解思路,构造拉格朗日方程的目的是将约束条件放到目标函数中,从而将有约束优化问题转换为无约束优化问题。我们仍然秉承这一思路去解决不等式约束条件下的优化问题,那么如何针对不等式约束条件下的优化问题构建拉格朗日函数呢?
因为我们要求解的是最小化问题,所以一个直观的想法是如果能够构造一个函数,使得该函数在可行解区域内与原目标函数完全一致,而在可行解区域外的数值非常大,甚至是无穷大,那么这个没有约束条件的新目标函数的优化问题就与原来有约束条件的原始目标函数的优化是等价的问题。
拉格朗日对偶问题其实就是沿着这一思路往下走的过程中,为了方便求解而使用的一种技巧。于是在这里出现了三个问题:1)有约束的原始目标函数优化问题;2)新构造的拉格朗日目标函数优化问题;3)拉格朗日对偶函数的优化问题。我们希望的是这三个问题具有完全相同的最优解,而在数学技巧上通常第三个问题——拉格朗日对偶优化问题——最好解决。所以拉格朗日对偶不是必须的,只是一条捷径。
1)原始目标函数(有约束条件)
为了接下来的讨论,更具有一般性,我们把等式约束条件也放进来,进而有约束的原始目标函数优化问题重新给出统一的描述:
 (15)
(15)
公式(15)表示m个等式约束条件和n个不等式约束条件下的目标函数的最小化问题。
2)新构造的目标函数(没有约束条件)
接下来我们构造一个基于广义拉格朗日函数的新目标函数,记为:
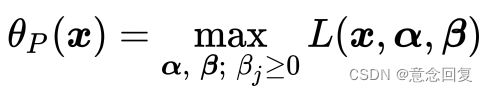 (16)
(16)
其中 为广义拉格朗日函数,定义为:
为广义拉格朗日函数,定义为:
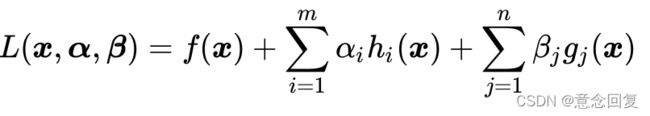 (17)
(17)
这里, ,是我们在构造新目标函数时加入的系数变量,同时也是公式(16)中最大化问题的自变量。将公式(17)带入公式(16)有:
,是我们在构造新目标函数时加入的系数变量,同时也是公式(16)中最大化问题的自变量。将公式(17)带入公式(16)有:
 (18)
(18)
我们对比公式(15)中的约束条件,将论域范围分为可行解区域和可行解区域外两个部分对公式(18)的取值进行分析,将可行解区域记为 ,当
,当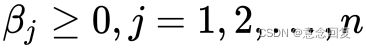 时有:
时有:
① 可行解区域内:由于 , 且系数
, 且系数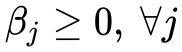 ,所以有:
,所以有:
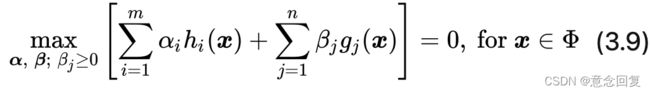 (19)
(19)
② 可行解区域外:代表公式(15)中至少有一组约束条件没有得到满足。如果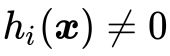 ,则调整系数
,则调整系数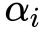 就可以使
就可以使![]() ;如果
;如果![]() ,调整系数
,调整系数![]() 就可以使
就可以使![]() 。这意味着,此时有
。这意味着,此时有
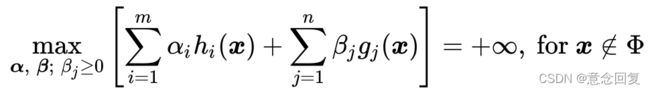 (20)
(20)
把公式(18),(19)和(20)结合在一起就得到我们新构造的目标函数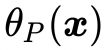 的取值分布情况:
的取值分布情况:
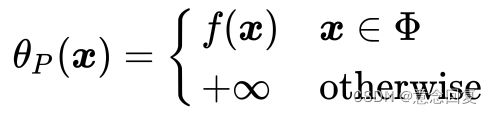 (21)
(21)
此时我们回想最初构造新目标函数的初衷,就是为了建立一个在可行解区域内与原目标函数相同,在可行解区域外函数值趋近于无穷大的新函数。看看公式(21),做到了。
现在约束条件已经没了,接下来我们就可以求解公式(22)的问题
 (22)
(22)
这个问题的解就等价于有约束条件下的原始目标函数![]() 最小化问题(公式15)的解。
最小化问题(公式15)的解。
3)对偶问题
尽管公式(22)描述的无约束优化问题看起来很美好,但一旦你尝试着手处理这个问题,就会发现一个麻烦。什么麻烦呢?那就是我们很难建立的显示表达式。如果再直白一点,我们很难直接从公式(18)里面把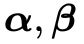 这两组参数拿掉,这样我们就没法通过令
这两组参数拿掉,这样我们就没法通过令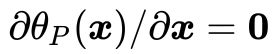 的方法求解出最优解
的方法求解出最优解![]() 。
。
要解决这个问题,就得用一点数学技巧了,这个技巧就是对偶问题。我们先把公式(16)和公式(22)放在一起,
(16)
(22)
得到关于新构造的目标函数的无约束优化的一种表达:
 (23)
(23)
然后我们再构造另一个函数,叫做 ,然后给出另外一个优化问题的描述:
,然后给出另外一个优化问题的描述:
 (24)
(24)
对比公式(23)和(24),发现两者之间存在一种对称的美感。所以我们就把(24)称作是(23)的对偶问题。现在我们可以解释一下中的P是原始问题Primary的缩写,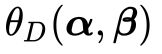 中的D是对偶问题Dual的缩写。如果我们能够想办法证明(24)和(23)存在相同的解
中的D是对偶问题Dual的缩写。如果我们能够想办法证明(24)和(23)存在相同的解 ,那我们就可以在对偶问题中选择比较简单的一个来求解。
,那我们就可以在对偶问题中选择比较简单的一个来求解。
4)对偶问题同解的证明
① 定理一:对于任意![]() 和
和![]() 有:
有:
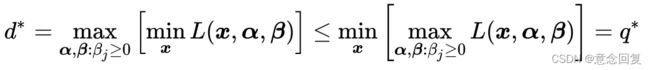
定理一的证明:

即
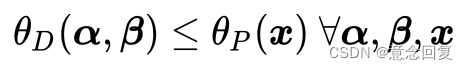
所以 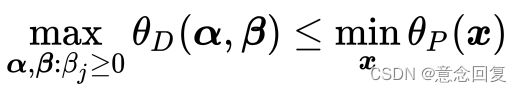
即:
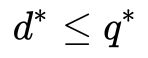
这里的 分别是对偶问题和原始问题的最优值。
分别是对偶问题和原始问题的最优值。
定理一既引入了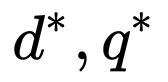 的概念,同时也描述了两者之间的关系。我们可以在这个基础上再给一个推论:如果能够找到一组
的概念,同时也描述了两者之间的关系。我们可以在这个基础上再给一个推论:如果能够找到一组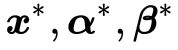 使得
使得 ,那么就应该有:
,那么就应该有:
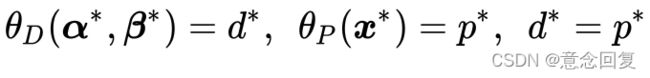
这个推论实际上已经涉及了原始问题与对偶问题的“强对偶性”。当 时,我们称原始问题与对偶问题之间“弱对偶性”成立;若
时,我们称原始问题与对偶问题之间“弱对偶性”成立;若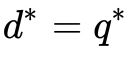 ,则称“强对偶性”成立。
,则称“强对偶性”成立。
如果我们希望能够使用拉格朗日对偶问题替换原始问题进行求解,则需要“强对偶性”作为前提条件。于是我们的问题变成了什么情况下,强对偶性才能够在SVM问题中成立。关于这个问题我们给出定理二:
② 定理二:
对于原始问题和对偶问题,假设函数 和不等式约束条件为凸函数,等式约束条件中的为仿射函数(即由一阶多项式构成的函数,
和不等式约束条件为凸函数,等式约束条件中的为仿射函数(即由一阶多项式构成的函数,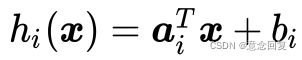 ,
,![]() 均为列向量,
均为列向量,![]() 为标量);并且至少存在一个
为标量);并且至少存在一个![]() 使所有不等式约束条件严格成立,即
使所有不等式约束条件严格成立,即![]() ,则存在
,则存在![]() 使得是原始问题
使得是原始问题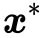 的最优解,
的最优解,![]() 是对偶问题的最优解且有:
是对偶问题的最优解且有: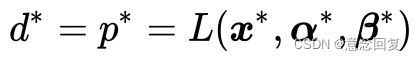 ,并其充分必要条件如下:
,并其充分必要条件如下:
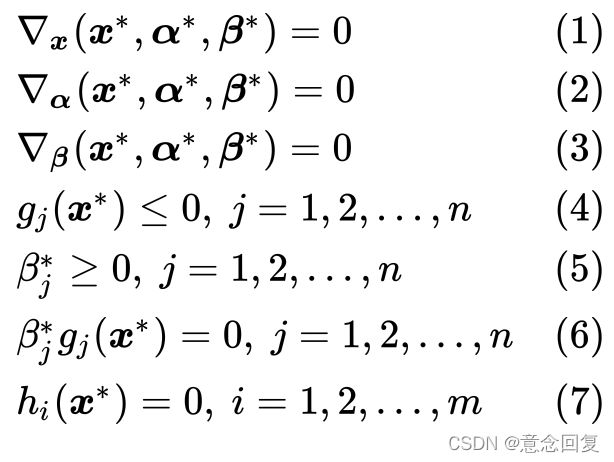 (25)
(25)
再次强调一下,公式(25)是使 为原始问题的最优解,
为原始问题的最优解,![]() 为对偶问题的最优解,且的充分必要条件。公式(25)中的(1)~(3),是为了求解最优化要求目标函数相对于三个变量
为对偶问题的最优解,且的充分必要条件。公式(25)中的(1)~(3),是为了求解最优化要求目标函数相对于三个变量![]() 的梯度为0;(4)~(6)为KKT条件(见公式14(3)),这也是我们为什么要在3.3节先介绍KKT条件的原因;(7)为等式约束条件。
的梯度为0;(4)~(6)为KKT条件(见公式14(3)),这也是我们为什么要在3.3节先介绍KKT条件的原因;(7)为等式约束条件。
2.3.5 拉格朗日对偶函数示例

图6:有约束条件下的最优化问题可视化案例。
图6中的优化问题可以写作:
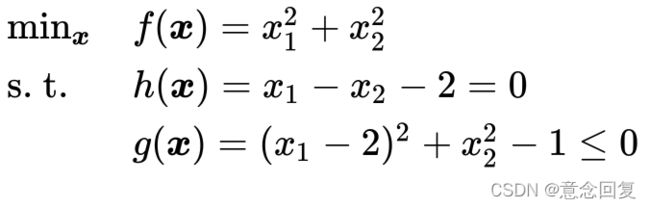 (26)
(26)
之所以说这个案例比较典型是因为它与线性SVM的数学模型非常相似,且包含了等式和不等式两种不同的约束条件。更重要的是,这两个约束条件在优化问题中都起到了作用。如图6所示,如果没有任何约束条件,最优解在坐标原点(0, 0)处(青色X);如果只有不等式约束条件![]() ,最优解在坐标(1,0)处(红色X);如果只有等式约束条件
,最优解在坐标(1,0)处(红色X);如果只有等式约束条件![]() ,最优解在坐标(1,-1)处(绿色+);如果两个约束条件都有,最优解在
,最优解在坐标(1,-1)处(绿色+);如果两个约束条件都有,最优解在 处(黄色O)。
处(黄色O)。
针对这一问题,我们可以设计拉格朗日函数如下:
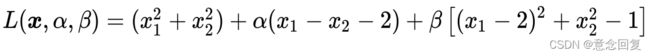 (27)
(27)
根据公式(21),函数  只在绿色直线在红色圆圈内的部分——也就是直线
只在绿色直线在红色圆圈内的部分——也就是直线 在圆
在圆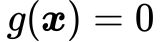 上的弦——与原目标函数
上的弦——与原目标函数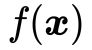 取相同的值,而在其他地方均有
取相同的值,而在其他地方均有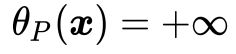 ,如图7所示。
,如图7所示。
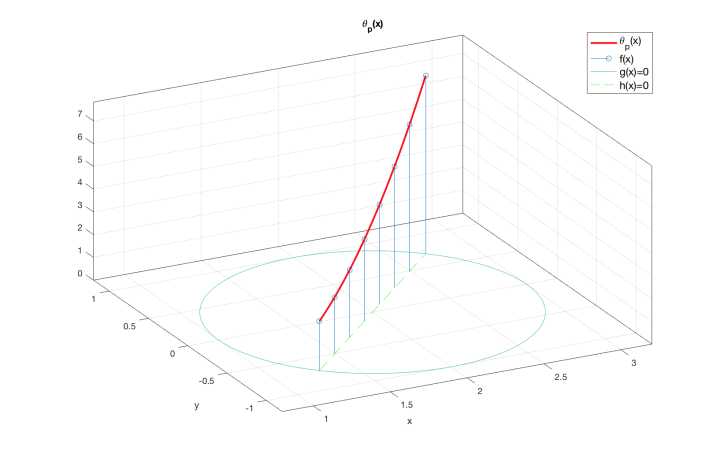
图7: (除了图中绿色虚线部分,其他部分的函数值均为无穷大)
(需要注意的是,此处不能使用对 求导等于0的方式消掉 ,因为函数 在
在 ![]() 为确定值时,是
为确定值时,是![]() 的线性函数,其极大值并不在梯度为0的地方)。由于函数
的线性函数,其极大值并不在梯度为0的地方)。由于函数  在没有约束条件下的最优解并不在这条弦上,所以显然对 求导等于零的方法是找不到最优解
在没有约束条件下的最优解并不在这条弦上,所以显然对 求导等于零的方法是找不到最优解![]() 的。但是对于这个简单的问题,还是能够从图中看到最优解应该在 :
的。但是对于这个简单的问题,还是能够从图中看到最优解应该在 :

由于该最优解是在 和 的交点处,所以可以很容易地理解:当  时,无论
时,无论 取什么值都可以使函数
取什么值都可以使函数 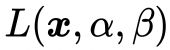 达到最小值。然而这个最优解是依靠几何推理的方式找到的,对于复杂的问题,这种方法似乎不具有可推广性。
达到最小值。然而这个最优解是依靠几何推理的方式找到的,对于复杂的问题,这种方法似乎不具有可推广性。
那么,我们不妨尝试一下,用拉格朗日对偶的方式看看这个问题。我们将 视为常数,这时 就只是![]() 的函数。我们可以通过求导等于零的方式寻找其最小值,即
的函数。我们可以通过求导等于零的方式寻找其最小值,即  。我们对公式(27)对
。我们对公式(27)对 ![]() 分别求偏导,令其等于0,有:
分别求偏导,令其等于0,有:
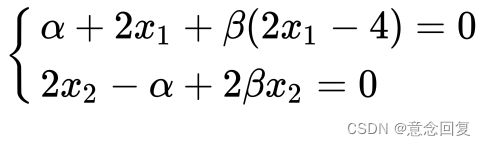 (28)
(28)
可以解得:
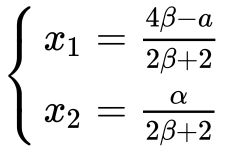 (29)
(29)
将(29)带入(27)可以得到:
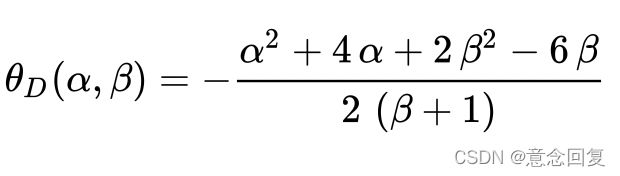 (30)
(30)
考虑到(25)中的条件(5),我们将函数(30)在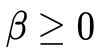 的
的  论域画出来,如图8所示。可以通过
论域画出来,如图8所示。可以通过  对 求导等于0的方式解出最优解
对 求导等于0的方式解出最优解 ,将其带入公式(29)可以得到
,将其带入公式(29)可以得到
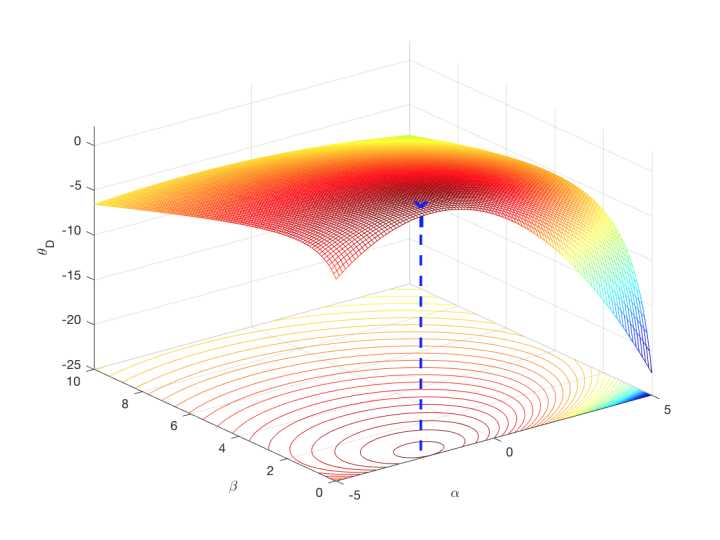
图8
最后通过对比,我们看到拉格朗日原始问题和对偶问题得到了相同的最优解(原始问题的最优解中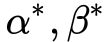 可以是任何值)。
可以是任何值)。
鞍点:
鞍点的概念大家可以去网上找,形态上顾名思义,就是马鞍的中心点,在一个方向上局部极大值,在另一个方向上局部极小值。这件事跟我们的拉格朗日函数有什么关系呢?由于这个例子中的拉格朗日函数包含 四个自变量,无法直接显示。为了更好的可视化,我们固定住其中两个变量,令
四个自变量,无法直接显示。为了更好的可视化,我们固定住其中两个变量,令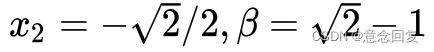 。此时拉格朗日函数就变成一个可以可视化的二元函数
。此时拉格朗日函数就变成一个可以可视化的二元函数![]() ,我们把它的曲面画出来。
,我们把它的曲面画出来。
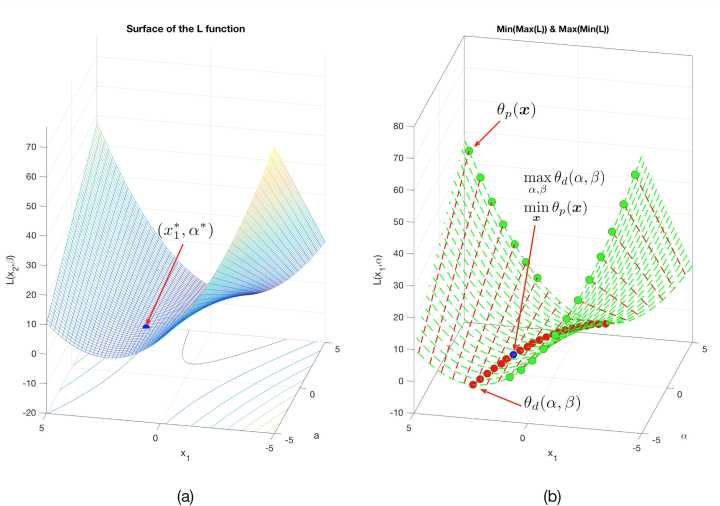
图9: ![]() 可视化效果
可视化效果
图9(a)中的最优点  可以能够两个角度去定义,如图9(b)所示。(为加以区别二维和四维的情况,我们将四维情况对应的
可以能够两个角度去定义,如图9(b)所示。(为加以区别二维和四维的情况,我们将四维情况对应的 ![]() 大写的下角标P和D改写为小写的p和d)。
大写的下角标P和D改写为小写的p和d)。
第一种定义(原始问题):沿着与![]() 轴平行的方向将曲面切成无数条曲线(红色虚线),在每条红色虚线上找到最大值(绿色圆点),即
轴平行的方向将曲面切成无数条曲线(红色虚线),在每条红色虚线上找到最大值(绿色圆点),即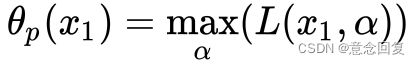 ,然后在所有的
,然后在所有的 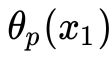 找到最小的那个(蓝色圆点),即
找到最小的那个(蓝色圆点),即 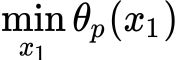 。
。
第二种定义(对偶问题):沿着与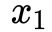 轴平行的方向将曲面切成无数条曲线(绿色虚线),在每条绿色虚线上找到最小值(红色圆点),即
轴平行的方向将曲面切成无数条曲线(绿色虚线),在每条绿色虚线上找到最小值(红色圆点),即 ,然后在所有的
,然后在所有的 ![]() 中找到最大的那个(蓝色圆点),即
中找到最大的那个(蓝色圆点),即 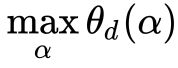 。
。
从图9的二维情况思考神秘的四维空间中的拉格朗日函数, 就变成了
就变成了 ![]() ,
,![]() ,如图9(b)所示。其实四元函数
,如图9(b)所示。其实四元函数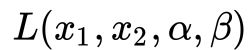 就是一个定义在4维空间上的鞍形函数,这个从两种思路共同得到的蓝色点就是函数 的鞍点,也就是我们要找的最优解。在这个二元化的图中,拉格朗日对偶问题和拉格朗日原始问题的差别就是:原始问题采用第一种定义去求解鞍点,对偶问题采用第二种方法去求解鞍点。
就是一个定义在4维空间上的鞍形函数,这个从两种思路共同得到的蓝色点就是函数 的鞍点,也就是我们要找的最优解。在这个二元化的图中,拉格朗日对偶问题和拉格朗日原始问题的差别就是:原始问题采用第一种定义去求解鞍点,对偶问题采用第二种方法去求解鞍点。
3 软间隔支持向量机
在现实任务中很难找到一个超平面将不同类别的样本完全划分开,即很难找到合适的核函数使得训练样本在特征空间中线性可分。退一步说,即使找到了一个可以使训练集在特征空间中完全分开的核函数,也很难确定这个线性可分的结果是不是由于过拟合导致的。解决该问题的办法是在一定程度上运行SVM在一些样本上出错,为此引入了“软间隔”(soft margin)的概念,如图10所示:
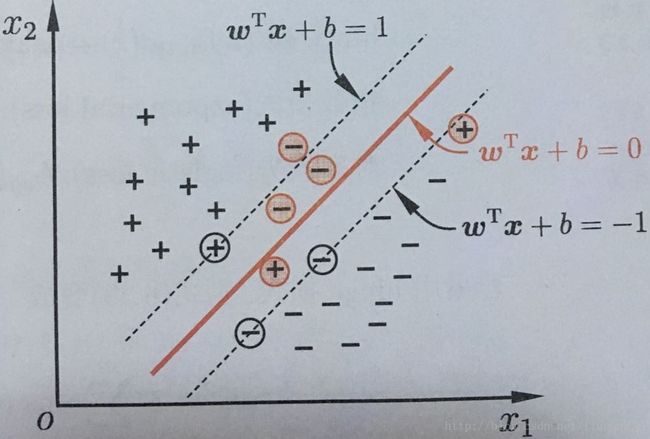
图10
具体来说,硬间隔支持向量机要求所有的样本均被最佳超平面正确划分,而软间隔支持向量机允许某些样本点不满足间隔大于等于1的条件![]() ,当然在最大化间隔的时候也要限制不满足间隔大于等于1的样本的个数使之尽可能的少。于是我们引入一个惩罚系数C>0,并对每个样本点
,当然在最大化间隔的时候也要限制不满足间隔大于等于1的样本的个数使之尽可能的少。于是我们引入一个惩罚系数C>0,并对每个样本点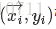 引入一个松弛变量(slack variables)ξ≥0,此时可将式(10)改写为
引入一个松弛变量(slack variables)ξ≥0,此时可将式(10)改写为
 (31)
(31)
上式中约束条件改为![]() ,表示间隔加上松弛变量大于等于1;优化目标改为
,表示间隔加上松弛变量大于等于1;优化目标改为![]() 表示对每个松弛变量都要有一个代价损失
表示对每个松弛变量都要有一个代价损失![]() ,C越大对误分类的惩罚越大、C越小对误分类的惩罚越小。
,C越大对误分类的惩罚越大、C越小对误分类的惩罚越小。
式(31)是软间隔支持向量机的原始问题。可以证明![]() 的解是唯一的,b的解不是唯一的,b的解是在一个区间内。假设求解软间隔支持向量机间隔最大化问题得到的最佳超平面是
的解是唯一的,b的解不是唯一的,b的解是在一个区间内。假设求解软间隔支持向量机间隔最大化问题得到的最佳超平面是![]() ,对应的分类决策函数为
,对应的分类决策函数为
![]() (32)
(32)
![]() 称为软间隔支持向量机。
称为软间隔支持向量机。
利用拉格朗日乘子法可得到下式的拉格朗日函数:
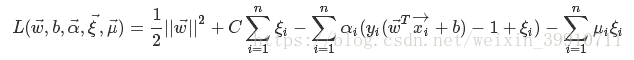 (33)
(33)
其中![]() 是拉格朗日乘子。
是拉格朗日乘子。
令 分别对
分别对![]() 求偏导并将偏导数为零可得:
求偏导并将偏导数为零可得:
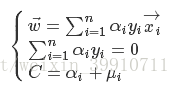 (34)
(34)
将式(34)带入式(33)便可得到式(31)的对偶问题:
 (35)
(35)
对比软间隔支持向量机的对偶问题和硬间隔支持向量机的对偶问题可发现二者的唯一差别就在于对偶变量的约束不同,软间隔支持向量机对对偶变量的约束是![]() ,硬间隔支持向量机对对偶变量的约束是
,硬间隔支持向量机对对偶变量的约束是![]() ,于是可采用和硬间隔支持向量机相同的解法求解式(35)。同理在引入核方法之后同样能得到与式(35)同样的支持向量展开式。
,于是可采用和硬间隔支持向量机相同的解法求解式(35)。同理在引入核方法之后同样能得到与式(35)同样的支持向量展开式。
对于软间隔支持向量机,KKT条件要求:
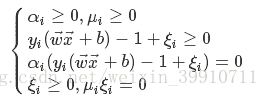 (36)
(36)
同硬间隔支持向量机类似,对任意训练样本![]() ,总有
,总有![]() 或
或![]() ,若
,若![]() ,则该样本不会对最佳决策面有任何影响;若
,则该样本不会对最佳决策面有任何影响;若![]() 则必有
则必有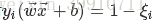 ,也就是说该样本是支持向量。由式(34)可知若
,也就是说该样本是支持向量。由式(34)可知若![]() 则μi>0进而有
则μi>0进而有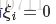 ,即该样本处在最大间隔边界上;若αi=C则μi=0此时如果
,即该样本处在最大间隔边界上;若αi=C则μi=0此时如果 则该样本处于最大间隔内部,如果
则该样本处于最大间隔内部,如果![]() 则该样本处于最大间隔外部即被分错了。由此也可看出,软间隔支持向量机的最终模型仅与支持向量有关。
则该样本处于最大间隔外部即被分错了。由此也可看出,软间隔支持向量机的最终模型仅与支持向量有关。
4 非线性支持向量机
现实任务中原始的样本空间D中很可能并不存在一个能正确划分两类样本的超平面。例如图10中所示的问题就无法找到一个超平面将两类样本进行很好的划分。
对于这样的问题可以通过将样本从原始空间映射到特征空间使得样本在映射后的特征空间里线性可分。例如对图11做特征映射![]() 可得到如图12所示的样本分布,这样就很好进行线性划分了。
可得到如图12所示的样本分布,这样就很好进行线性划分了。

图11
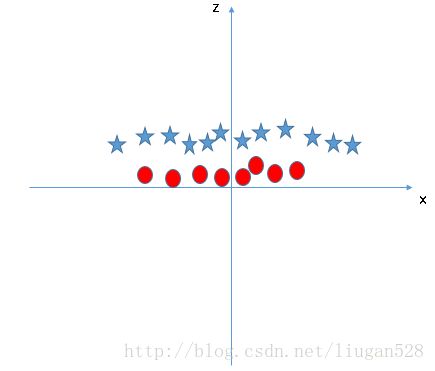
图12
令![]() 表示将样本点
表示将样本点![]() 映射后的特征向量,类似于线性可分支持向量机中的表示方法,在特征空间中划分超平面所对应的模型可表示为
映射后的特征向量,类似于线性可分支持向量机中的表示方法,在特征空间中划分超平面所对应的模型可表示为
![]() (37)
(37)
其中x为![]() 。
。![]() 和b是待求解的模型参数。类似式(10),有
和b是待求解的模型参数。类似式(10),有
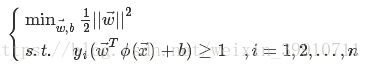 (38)
(38)
其拉格朗日对偶问题是
 (39)
(39)
求解(39)需要计算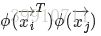 ,即样本映射到特征空间之后的内积,由于特征空间可能维度很高,甚至可能是无穷维,因此直接计算通常是很困难的,在上文中我们提到其实我们根本不关心单个样本的表现,只关心特征空间中样本间两两的乘积,因此我们没有必要把原始空间的样本一个个地映射到特征空间中,只需要想法办求解出样本对应到特征空间中样本间两两的乘积即可。为了解决该问题可设想存在核函数:
,即样本映射到特征空间之后的内积,由于特征空间可能维度很高,甚至可能是无穷维,因此直接计算通常是很困难的,在上文中我们提到其实我们根本不关心单个样本的表现,只关心特征空间中样本间两两的乘积,因此我们没有必要把原始空间的样本一个个地映射到特征空间中,只需要想法办求解出样本对应到特征空间中样本间两两的乘积即可。为了解决该问题可设想存在核函数:
![]() (40)
(40)
也就是说![]() 与
与![]() 在特征空间的内积等于它们在原始空间中通过函数κ(⋅,⋅)计算的结果,这给求解带来很大的方便。于是式(39)可写为:
在特征空间的内积等于它们在原始空间中通过函数κ(⋅,⋅)计算的结果,这给求解带来很大的方便。于是式(39)可写为:
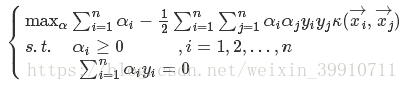 (41)
(41)
同样的我们只关心在高维空间中样本之间两两点乘的结果而不关心样本是如何变换到高维空间中去的。求解后即可得到
 (42)
(42)
剩余的问题同样是求解![]() ,然后求解
,然后求解![]() 和b即可得到最佳超平面。
和b即可得到最佳超平面。
5 支持向量回归SVR
支持向量机不仅可以用来解决分类问题还可以用来解决回归问题,称为支持向量回归(Support Vector Regression,SVR)。
对于样本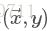 通常根据模型的输出
通常根据模型的输出![]() 与真实值(即ground truth)yi之间的差别来计算损失,当且仅当
与真实值(即ground truth)yi之间的差别来计算损失,当且仅当![]() 时损失才为零。SVR的基本思路是允许预测值
时损失才为零。SVR的基本思路是允许预测值 与
与![]() 之间最多有ε的偏差,当
之间最多有ε的偏差,当![]() 时认为预测正确不计算损失,仅当
时认为预测正确不计算损失,仅当![]() 时才计算损失。SVR问题可描述为:
时才计算损失。SVR问题可描述为:
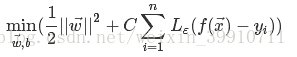 (43)
(43)
其中,C≥0为惩罚项,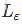 为损失函数,定义为:
为损失函数,定义为:
 (44)
(44)
进一步地引入松弛变量![]() ,则新的最优化问题为:
,则新的最优化问题为:
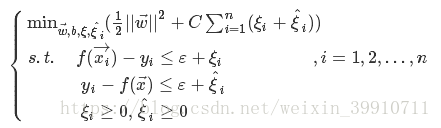 (45)
(45)
这就是SVR的原始问题。类似地引入拉格朗日乘子![]() ,则对应的拉格朗日函数为:
,则对应的拉格朗日函数为:
 (46)
(46)
![]() 对
对![]() 的偏导数为零可得:
的偏导数为零可得:
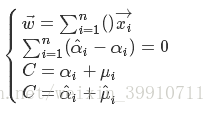 (47)
(47)
将式(47)代入式(46)即可得到SVR的对偶问题:
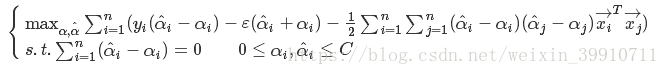 (48)
(48)
其KKT条件为:
 (49)
(49)
SVR的解形如:
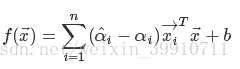 (50)
(50)
进一步地如果引入核函数则SVR可表示为:
 (51)
(51)
其中![]() 为核函数。
为核函数。
6 常用核函数

7. SVM的优缺点
优点:
SVM在中小量样本规模的时候容易得到数据和特征之间的非线性关系,可以避免使用神经网络结构选择和局部极小值问题,可解释性强,可以解决高维问题。
缺点:
SVM对缺失数据敏感,对非线性问题没有通用的解决方案,核函数的正确选择不容易,计算复杂度高,主流的算法可以达到![]() 的复杂度,这对大规模的数据是吃不消的。
的复杂度,这对大规模的数据是吃不消的。
8 SMO算法
视频:【极简机器学习】02 支持向量机_哔哩哔哩_bilibili
SVM解释:五、SMO算法_guoziqing506的博客-CSDN博客_smo算法
 (A)
(A)
SMO算法是用来高效地求解公式(A)所示的SVM核心优化问题的。
我们知道,解决这样一个有多变量(个)的优化问题确实比较困难,但是如果能多次迭代,每次选择两个变量优化,同时把其他变量看做是固定的常数,这样“分而治之”的话,问题似乎就容易多了。SMO算法的基本思想正是这样一种“分治法”。
显然,这样做有两个问题需要解决:
- 每次选择哪两个变量?
- 每次迭代如何进行优化计算?
最小序列最优化算法。
(1)每次迭代如何进行优化计算?

(2)如何选择两个λ?
选择λ2遵从上图中右下角的三个要求,当第一个要求取到的效果不好时,选择第二个要求,当第二个要求的效果也不好时,选第三个要求。
(3)总结:
如果都满足KTT 条件,则SMO算法的迭代终止。
参考:
SVM_GarryLau的博客-CSDN博客_svm
SVM支持向量机算法介绍_千寻~的博客-CSDN博客_支持向量机算法
零基础学Support Vector Machine(SVM)_六半的博客-CSDN博客
支持向量机通俗导论(理解SVM的三层境界)_v_JULY_v的博客-CSDN博客_svm算法
http://lib.csdn.net/article/machinelearning/34998
拉格朗日乘子法和KKT条:拉格朗日乘子法和KKT条件 - PilgrimHui - 博客园