时间序列常用算法总结
时间序列预测算法总结
文章目录
- 时间序列预测算法总结
- 前言
-
- 一、基于统计的时序数据建模方法
-
- 1.1传统时序数据建模方法
-
- 1.1.1周期因子法
- 1.1.2移动平均法
- 1.1.3ARIMA模型
-
- 1.1.3.1模型原理
-
- 1.平稳性要求
- 2.AR模型
- 3.MA模型
- 4.ARMA模型
- 5.ARIMA模型
- 1.1.3.2.建模过程
-
- 1.序列平稳化
- 2.模型识别
- 3 模型检验
- 4 模型预测
- 1.1.4时间序列分解模型
- 1.2 基于机器学习的建模方法
-
- 1.2.1 K近邻算法
- 1.2.2 SVM
- 1.2.1 随机森林
- 1.2.2 Xgboost
- 1.2.3 lightgbm
- 二、基于深度学习的时序数据建模方法
-
- 2.1 LSTM
- 2.2 seq2seq模型
前言
时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征。这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大小的值改变顺序后输入模型产生的结果是不同的。
从时间的序列的平稳性来看,时间序列可以分为平稳序列与非平稳序列,其中平稳序列就是指存在某种周期,季节性及趋势的方差和均值不随时间变化的序列;从变量数目来看分为单变量时间序列与多变量时间序列。
下面就我最近看到的时间序列预测方法进行总结:主要分为基于统计的预测方法与基于深度学习的预测方法
一、基于统计的时序数据建模方法
基于统计的时序数据建模方法也分为两类,一种比较传统时间序列建模方法,比如移动平均法,指数平滑法,AR,MA,ARMA等;一种是基于机器学习的方法,比如随机森林,Xgboost,LightGBM等。
1.1传统时序数据建模方法
传统时序数据建模方法一般都是针对于单变量的预测(自回归),这类方法比较适用于小规模数据集,比如电力负荷预测,燃气预测,某商场的客流量预测等。
1.1.1周期因子法
周期因子法是提取时间序列的周期性特征进行预测,使用的前提是一定要有明显的周期性。
方法步骤:
-
观察序列,查看该序列是否有明显的周期性,若有就可以尽可能准确的提取这种周期特征,进行预测。
-
计算周期因子factors
-
将数据转换成一个方阵,其中行表示一个周期包含的所有时刻数据,列表示不同周期在同一时刻的数据
-
将时序数据除以周期的周期均值,得到一个比值
-
按列取每个周期的中位数,这个中位数就表示周期因子
-
-
计算base
- base值根据测试数据的效果来确定的,可以取某个周期的平均值作为base,但是这并不一定是一个好方法,因为对于时间序列预测,可能取一个周期中的最后几天更能反映最新的情况。而且为了防止一些离群情况(比如一些节假日的客流量就会异常大),这种情况就需要去掉周期性因素再平均(即将其处以周期因子)。除此之外,也可比取周期的均值和中位数将其融合来作为base,融合的比例按照测试集的表现来确定;也可以根据与预测的时间距离来赋予不同的权重。
-
计算预测值,即将周期因子(factors)与base相乘
1.1.2移动平均法
移动平均法(moving average method)是根据时间序列,逐项推移,依次计算包含一定项数的序时平均数,以此进行预测的方法。移动平均法包括一次移动平均法和加权移动平均法。
-
简单移动平均
简单移动平均的各元素的权重都相等。简单的移动平均的计算公式如下:
F t = ( A t − 1 + A t − 2 + . . . + A t − n ) / n F_t =(A_{t-1}+A_{t-2}+...+A_{t-n})/n Ft=(At−1+At−2+...+At−n)/n- F t F_t Ft表示对下一期的预测值
- n n n表示移动平均的时期个数
- A t − i A_{t-i} At−i表示前i的实际值
-
加权移动平均
加权移动平均给固定跨越期限内的每个变量值以不同的权重。其原理是:历史各期的数据信息对预测未来时期值的作用是不一样的。除了以n为周期的周期性变化外,远离目标期的变量值的影响力相对较低,故应给予较低的权重。 加权移动平均法的计算公式如下:
F t = w 1 A t − 1 + w 2 A t − 2 + w 3 A t − 3 + … + w n A t − n F_t=w_1A_{t-1}+w_2A_{t-2}+w_3A_{t-3}+…+w_nA_{t-n} Ft=w1At−1+w2At−2+w3At−3+…+wnAt−n- F t F_t Ft表示对下一时刻的预测值
- w i w_i wi第t-i时刻的权重;
- n n n预测的时刻数,其中 w 1 + w 2 + … + w n = 1 w_1+ w_2+…+ w_n=1 w1+w2+…+wn=1
在运用加权平均时,权重的选择是一个需要注意的问题。经验法和试算法是选择权重的最简单的方法。一般而言,最近期的数据最能预示未来的情况,因而权重应大些。例如,根据前一个月的利润和生产能力比起根据前几个月能更好的估测下个月的利润和生产能力。但是,如果数据是季节性的,则权重也应是季节性的。
1.1.3ARIMA模型
自回归模型描述当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测。
1.1.3.1模型原理
1.平稳性要求
ARIMA模型最重要的地方在于时序数据的平稳性。平稳性是要求经由样本时间序列得到的拟合曲线在未来的短时间内能够顺着现有的形态惯性地延续下去,即数据的均值、方差理论上不应有过大的变化。平稳性可以分为严平稳与弱平稳两类。严平稳指的是数据的分布不随着时间的改变而改变;而弱平稳指的是数据的期望与向关系数(即依赖性)不发生改变。在实际应用的过程中,严平稳过于理想化与理论化,绝大多数的情况应该属于弱平稳。对于不平稳的数据,我们应当对数据进行平文化处理。最常用的手段便是差分法,计算时间序列中t时刻与t-1时刻的差值,从而得到一个新的、更平稳的时间序列。
2.AR模型
自回归模型首先需要确定一个阶数p,表示用几期的历史值来预测当前值。p阶自回归模型的公式定义为:
y t = μ + ∑ i = 1 p γ i y t − i + ϵ t y_{t}=\mu+\sum_{i=1}^{p} \gamma_{i} y_{t-i}+\epsilon_{t} yt=μ+i=1∑pγiyt−i+ϵt
上式中 y t y_t yt是当前值, u u u是常数项, p p p是阶数$ r_i 是 自 相 关 系 数 , 是自相关系数, 是自相关系数,\epsilon_{t}$是误差。
自回归模型有很多的限制:
1、自回归模型是用自身的数据进行预测
2、时间序列数据必须具有平稳性
3、自回归只适用于预测与自身前期相关的现象
3.MA模型
移动平均模型关注的是自回归模型中的误差项的累加 ,q阶自回归过程的公式定义如下:
y t = μ + ϵ t + ∑ i = 1 q θ i ϵ t − i y_{t}=\mu+\epsilon_{t}+\sum_{i=1}^{q} \theta_{i} \epsilon_{t-i} yt=μ+ϵt+i=1∑qθiϵt−i
移动平均法能有效地消除预测中的随机波动
4.ARMA模型
自回归模型AR和移动平均模型MA模型相结合,我们就得到了自回归移动平均模型ARMA(p,q),计算公式如下:
y t = μ + ∑ i = 1 p γ i y t − i + ϵ t + ∑ i = 1 q θ i ϵ t − i y_{t}=\mu+\sum_{i=1}^{p} \gamma_{i} y_{t-i}+\epsilon_{t}+\sum_{i=1}^{q} \theta_{i} \epsilon_{t-i} yt=μ+i=1∑pγiyt−i+ϵt+i=1∑qθiϵt−i
5.ARIMA模型
如果原始数据不满足平稳性要求而进行了差分,将自回归模型、移动平均模型和差分法结合,我们就得到了差分自回归移动平均模型ARIMA(p,d,q),其中d是需要对数据进行差分的阶数。差分之后就和ARMA模型是完全相同的了。
1.1.3.2.建模过程
一般来说,建立ARIMA模型一般有三个阶段,分别是序列平稳化,模型识别和模型检验,接下来,我们一步步来介绍:
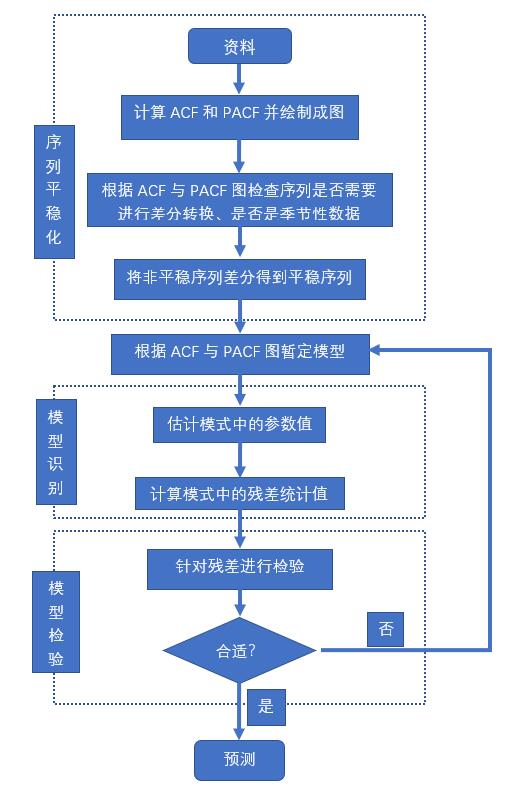
1.序列平稳化
因为移动自回归模型有平稳性的要求,所以第一步就需要看是否平稳,如果平稳就可以进行后续的模型识别与模型检验,如果不平稳就要看是否需要进行差分,是否有季节性因素等等,最终得到平稳化的序列。
2.模型识别
模型的识别问题,主要是确定p,d,q三个参数,差分的阶数d一般通过观察图示,1阶或2阶即可。这里我们主要介绍p和q的确定。我们首先介绍两个函数。
(1)自相关函数ACF(autocorrelation function)
自相关函数ACF描述的是时间序列观测值与其过去的观测值之间的线性相关性。计算公式如下:
A C F ( k ) = ρ k = Cov ( y t , y t − k ) Var ( y t ) A C F(k)=\rho_{k}=\frac{\operatorname{Cov}\left(y_{t}, y_{t-k}\right)}{\operatorname{Var}\left(y_{t}\right)} ACF(k)=ρk=Var(yt)Cov(yt,yt−k)
其中k代表滞后期数,如果k=2,则代表 y t y_t yt和 y t − 2 y_{t-2} yt−2
(2)偏自相关函数PACF(partial autocorrelation function)
偏自相关函数PACF描述的是在给定中间观测值的条件下,时间序列观测值预期过去的观测值之间的线性相关性。
举个简单的例子,假设k=3,那么我们描述的是 y t y_t yt和 y t − 3 y_{t-3} yt−3之间的相关性,但是这个相关性还受到 y t − 1 y_{t-1} yt−1和 y t − 2 y_{t-2} yt−2的影响。PACF剔除了这个影响,而ACF包含这个影响。
拖尾和截尾
拖尾指序列以指数率单调递减或震荡衰减,而截尾指序列从某个时点变得非常小:
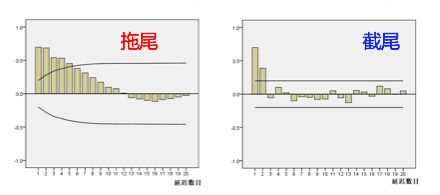
出现以下情况,通常视为(偏)自相关系数d阶截尾:
1)在最初的d阶明显大于2倍标准差范围
2)之后几乎95%的(偏)自相关系数都落在2倍标准差范围以内
3)且由非零自相关系数衰减为在零附近小值波动的过程非常突然
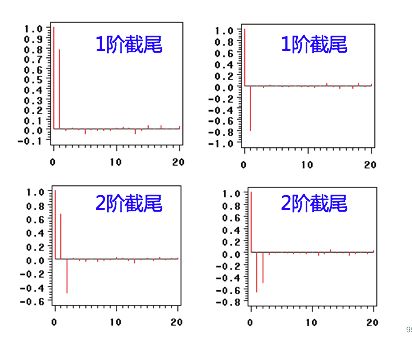
出现以下情况,通常视为(偏)自相关系数拖尾:
1)如果有超过5%的样本(偏)自相关系数都落入2倍标准差范围之外
2)或者是由显著非0的(偏)自相关系数衰减为小值波动的过程比较缓慢或非常连续。
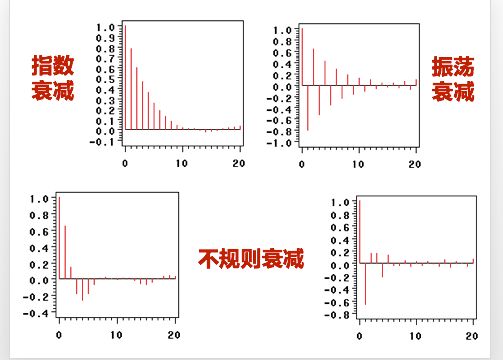
p,q阶数的确定
根据刚才判定截尾和拖尾的准则,p,q的确定基于如下的规则:
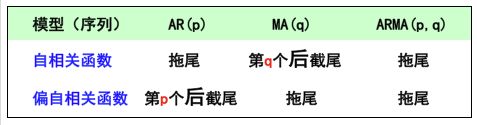
根据不同的截尾和拖尾的情况,我们可以选择AR模型,也可以选择MA模型,当然也可以选择ARIMA模型。
由于通过拖尾和截尾对模型进行定阶的方法,往往具有很强的主观性。回想我们之前在参数预估的时候往往是怎么做的,不就是损失和正则项的加权么?我们这里能不能结合最终的预测误差来确定p,q的阶数呢?在相同的预测误差情况下,根据奥斯卡姆剃刀准则,模型越小是越好的。那么,平衡预测误差和参数个数,我们可以根据信息准则函数法,来确定模型的阶数。预测误差通常用平方误差即残差平方和来表示。
常用的信息准则函数法有下面几种:
(1)AIC准则
AIC准则全称为全称是最小化信息量准则(Akaike Information Criterion),计算公式如下:
AIC = =2 *(模型参数的个数)-2ln(模型的极大似然函数)
(2)BIC准则
AIC准则存在一定的不足之处。当样本容量很大时,在AIC准则中拟合误差提供的信息就要受到样本容量的放大,而参数个数的惩罚因子却和样本容量没关系(一直是2),因此当样本容量很大时,使用AIC准则选择的模型不收敛与真实模型,它通常比真实模型所含的未知参数个数要多。BIC(Bayesian InformationCriterion)贝叶斯信息准则弥补了AIC的不足,计算公式如下:
BIC = ln(n) * (模型中参数的个数) - 2ln(模型的极大似然函数值),n是样本容量
一般来说,BIC准则得到的ARMA模型的阶数较AIC的低。
3 模型检验
这里的模型检验主要有两个:
1)检验参数估计的显著性(t检验)
2)检验残差序列的随机性,即残差之间是独立的
残差序列的随机性可以通过自相关函数法来检验,即做残差的自相关函数图,如果稳定在0值附近则证明通过了残差检验
4 模型预测
预测主要有两个函数,一个是predict函数,一个是forecast函数,predict中进行预测的时间段必须在我们训练ARIMA模型的数据中,forecast则是对训练数据集末尾下一个时间段的值进行预估。
1.1.4时间序列分解模型
将时间序列分解为趋势,季节性,节假日,残差。分解方法一般有小波分解,经验模态分解以及傅立叶变换等。然后对分解的序列逐个分析,逐个实现,最后叠加。
1.2 基于机器学习的建模方法
机器学习方法要求将时间问题构造为有监督学习问题,即回归问题。这将要求将序列的滞后观测值作为输入特征,丢弃数据中的时间关系,该类方法不仅可以进行单变量时间序列预测,还可以做多变量时间序列预测。常用的非线性和集成方法有K近邻算法,SVM,随机森林,Xgboost,lightgbm等。
为了确保模型拟合和评估,要保留数据中的时间结构,需要做大量的特征工程,来增加特征,专业程度较高。
1.2.1 K近邻算法
k近邻法(k-nearest neighbor, kNN)是一种基本分类与回归方法,其基本做法是:给定测试实例,基于某种距离度量找出训练集中与其最靠近的k个实例点,然后基于这k个最近邻的信息来进行预测。
通常,在分类任务中可使用“投票法”,即选择这k个实例中出现最多的标记类别作为预测结果;在回归任务中可使用“平均法”,即将这k个实例的实值输出标记的平均值作为预测结果;还可基于距离远近进行加权平均或加权投票,距离越近的实例权重越大。
步骤:
- 输入训练集:
D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } D=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\} D={(x1,y1),(x2,y2),⋯,(xN,yN)}
x i ∈ X ⊆ R n x_{i} \in X \subseteq R^{n} xi∈X⊆Rn为实例的特征向量, y i ∈ Y = { c 1 , c 2 , ⋯ , c k } y_{i} \in Y=\left\{c_{1}, c_{2}, \cdots, c_{k}\right\} yi∈Y={c1,c2,⋯,ck}为实例的值, i = 1 , 2 , … , N i=1,2,…,N i=1,2,…,N。
-
输出:实例x的预测值
-
根据给定的距离度量,在训练集D中找出与x最近邻的k个点,涵盖这k个点的x的领域记作 N k ( x ) N_{k}(x) Nk(x)
-
在 N k ( x ) N_{k}(x) Nk(x)中对所有邻居求均值,得到预测值
from sklearn.neighbors import KNeighborsClassifier as KNN knc = KNN(n_neighbors =6,) knc.fit(X,Y)
1.2.2 SVM
SVM算法功能非常强大:不仅支持线性与非线性的分类,也支持线性与非线性回归。它的主要思想是逆转目标:在分类问题中,是要在两个类别中拟合最大可能的街道(间隔),同时限制间隔侵犯(margin violations);而在SVM回归中,它会尝试尽可能地拟合更多的数据实例到街道(间隔)上,同时限制间隔侵犯(margin violation,也就是指远离街道的实例)。街道的宽度由超参数ϵ控制。下图展示的是两个线性SVM回归模型在一些随机线性数据上训练之后的结果,其中一个有较大的间隔(ϵ = 1.5),另一个的间隔较小(ϵ = 0.5)。
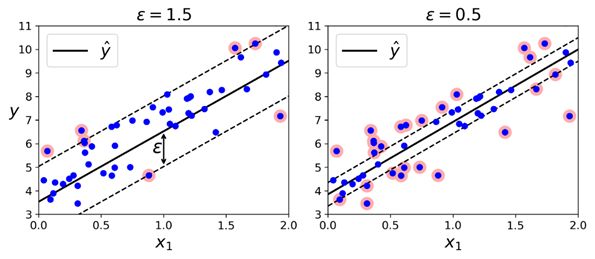
如果后续增加的训练数据包含在间隔内,则不会对模型的预测产生影响,所以这个模型也被称为是ϵ-insensitive。
我们可以使用sk-learn的LinearSVR类训练一个SVM回归,下面的代码对应的是上图中左边的模型(训练数据需要先做缩放以及中心化的操作,中心化又叫零均值化,是指变量减去它的均值。其实就是一个平移的过程,平移后所有数据的中心是(0, 0)):
from sklearn.svm import LinearSVR
svm_reg = LinearSVR(epsilon=1.5)
svm_reg.fit(X, y)
再处理非线性的回归任务时,也可以使用核化的SVM模型。例如,下图展示的是SVM回归在一个随机的二次训练集上的表现,使用的是二阶多项式核:
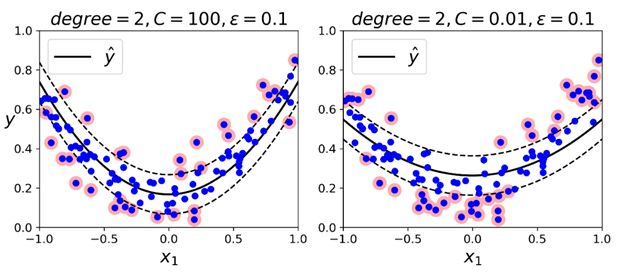
左边的图中有一个较小的正则(超参数C的值较大),而右边图中的正则较大(较小的C值)。
下面的代码上图中左边的图对应的模型,使用的是sk-learn SVR类(支持核方法)。SVR类等同于分类问题中的SVC类,并且LinearSVR类等同于分类问题中的LinearSVC类。LinearSVR类会随着训练集的大小线性扩展(与LinearSVC类一样);而SVR类在训练集剧增时,速度会严重下降(与SVC类一致):
from sklearn.svm import SVR
svm_poly_reg = SVR(kernel='poly', degree=2, C=100, epsilon=0.1)
svm_poly_reg.fit(X, y)
1.2.1 随机森林
随机森林属于Bagging类算法,而Bagging 又属于集成学习的一种方法(集成学习方法大致分为Boosting和Bagging方法),集成学习的大致思路是训练多个弱模型打包起来组成一个强模型,强模型的性能要比单个弱模型好很多(三个臭皮匠顶一个诸葛亮。注意:这里的弱和强是相对的),其中的弱模型可以是决策树、SVM等模型,在随机森林中,弱模型选用决策树。
在训练阶段,随机森林使用bootstrap采样从输入训练数据集中采集多个不同的子训练数据集来依次训练多个不同决策树;在预测阶段,随机森林将内部多个决策树的预测结果取平均得到最终的结果。
具体步骤如下:
-
(1)从训练集中随机抽取一定数量的样本,作为每棵树的根节点样本;
-
(2)在建立决策树时,随机抽取一定数量的候选属性,从中选择最合适属性作为分裂节点;
-
(3)建立好随机森林以后,对于测试样本,进入每一颗决策树进行类型输出或回归输出;若是分类问题,以投票的方式输出最终类别,若是回归问题,每一颗决策树输出的均值作为最终结果
from sklearn.ensemble import RandomForestRegressor regressor = RandomForestRegressor(n_estimators=100,random_state=0) regressor.fit(X,Y)
1.2.2 Xgboost
XGBoost里,每棵树是不断加入,每加一棵树希望效果能够得到提升。实质上,每添加一棵树其实是学习一个新函数去拟合上次预测的残差,最后预测结果是每棵树样本所在的叶子节点的分数之和。
y ^ = ϕ ( x i ) = ∑ k = 1 K f k ( x i ) \hat{y}=\phi\left(x_{i}\right)=\sum_{k=1}^{K} f_{k}\left(x_{i}\right) y^=ϕ(xi)=k=1∑Kfk(xi)
$ f_k(xi) 是 第 是第 是第i 个 样 本 在 第 个样本在第 个样本在第k$个决策树上的预测分数。
详细解释看https://blog.csdn.net/a819825294/article/details/51206410
from xgboost.sklearn import XGBRegressor
clf = XGBRegressor()
clf.fit(X,Y)
1.2.3 lightgbm
LightGBM原理和XGBoost类似,通过损失函数的泰勒展开式近似表达残差(包含了一阶和二阶导数信息),另外利用正则化项控制模型的复杂度。但是LightGBM最大的特点是,
-
通过使用leaf-wise分裂策略代替XGBoost的level-wise分裂策略,通过只选择分裂增益最大的结点进行分裂,避免了某些结点增益较小带来的开销。
-
另外LightGBM通过使用基于直方图的决策树算法,只保存特征离散化之后的值,代替XGBoost使用exact算法中使用的预排序算法(预排序算法既要保存原始特征的值,也要保存这个值所处的顺序索引),减少了内存的使用,并加速的模型的训练速度。
import lightgbm as lgb gbm = lgb.LGBMRegressor() gbm.fit(X,Y)
二、基于深度学习的时序数据建模方法
一般来说,神经网络在自回归型问题上并没有被证明是非常有效的。然而,卷积神经网络等技术能够从原始数据(包括一维信号数据)中自动学习复杂特征。而递归神经网络,例如LSTM,能够直接在多个输入数据的并行序列中学习。这些方法可以处理大量数据和多个输入变量(特征)任务。
实际上在基于深度学习的时序数据建模方法中,比如LSTM,seq2seq,attention等都是特征提取器,将时序数据转换成有监督的学习问题,即(X,y)训练集对,通过使用X来对y进行预测。
2.1 LSTM
长短期记忆(Long Short-Term Memory ) LSTM 递归神经网络这样的神经网络几乎可以完美地模拟多个输入变量的问题。这在时间序列预测中是一个很大的好处,经典的线性方法很难适应多元或多输入预测问题。
典型的RNN网路结构如下:
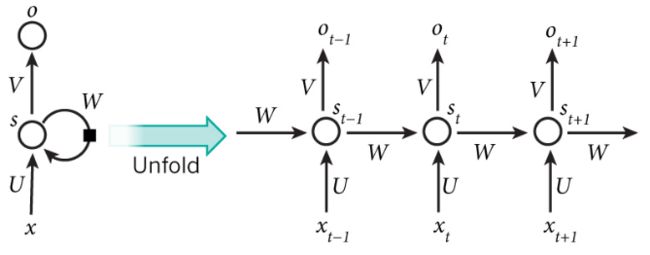
右侧为计算时便于理解记忆而产开的结构。简单说,x为输入层,o为输出层,s为隐含层,而t指第几次的计算; V , W , U V,W,U V,W,U为权重,其中计算第t次的隐含层状态时为 S t = f ( U ∗ X t + W ∗ S t − 1 ) S_t = f(U*X_t + W*S_{t-1}) St=f(U∗Xt+W∗St−1),实现当前输入结果与之前的计算挂钩的目的。
RNN的局限:
由于RNN模型如果需要实现长期记忆的话需要将当前的隐含态的计算与前n次的计算挂钩,即 S t = f ( U ∗ X t + W 1 ∗ S t − 1 + W 2 ∗ S t − 2 + . . . + W n ∗ S t − n ) S_t = f(U*X_t + W_1*S_{t-1} + W_2*S_{t-2} + ... + W_n*S_{t-n}) St=f(U∗Xt+W1∗St−1+W2∗St−2+...+Wn∗St−n),那样的话计算量会呈指数式增长,导致模型训练的时间大幅增加,因此RNN模型一般直接用来进行长期记忆计算。
LSTM模型
LSTM(Long Short-Term Memory)模型是一种RNN的变型,最早由Juergen Schmidhuber提出的。经典的LSTM模型结构如下:
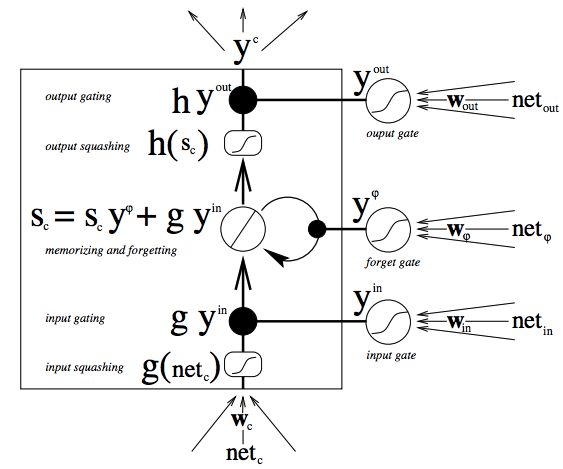
LSTM的特点就是在RNN结构以外添加了各层的阀门节点。阀门有3类:遗忘阀门(forget gate),输入阀门(input gate)和输出阀门(output gate)。这些阀门可以打开或关闭,用于将判断模型网络的记忆态(之前网络的状态)在该层输出的结果是否达到阈值从而加入到当前该层的计算中。如图中所示,阀门节点利用sigmoid函数将网络的记忆态作为输入计算;如果输出结果达到阈值则将该阀门输出与当前层的的计算结果相乘作为下一层的输入(PS:这里的相乘是在指矩阵中的逐元素相乘);如果没有达到阈值则将该输出结果遗忘掉。每一层包括阀门节点的权重都会在每一次模型反向传播训练过程中更新。更具体的LSTM的判断计算过程如下图所示:
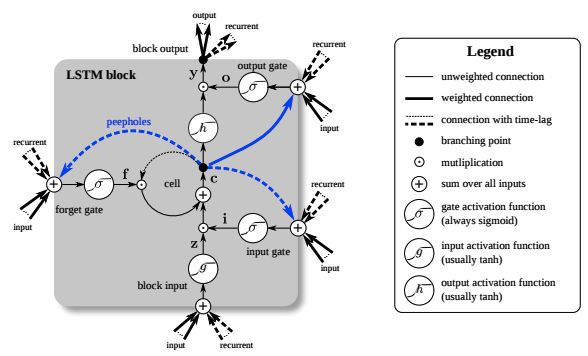
LSTM模型的记忆功能就是由这些阀门节点实现的。当阀门打开的时候,前面模型的训练结果就会关联到当前的模型计算,而当阀门关闭的时候之前的计算结果就不再影响当前的计算。因此,通过调节阀门的开关我们就可以实现早期序列对最终结果的影响。而当你不不希望之前结果对之后产生影响,比如自然语言处理中的开始分析新段落或新章节,那么把阀门关掉即可。
下图具体演示了阀门是如何工作的:通过阀门控制使序列第1的输入的变量影响到了序列第4,6的的变量计算结果。
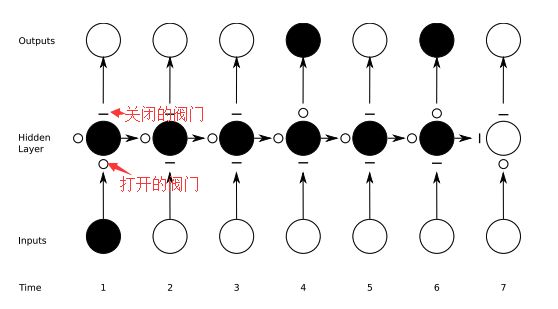
黑色实心圆代表对该节点的计算结果输出到下一层或下一次计算;空心圆则表示该节点的计算结果没有输入到网络或者没有从上一次收到信号。
2.2 seq2seq模型
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,当然也可以用以时间序列,使用前期的数据来对后期数据进行预测
seq2seq属于encoder-decoder结构的一种,这里看看常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码;而decoder则负责根据encoder得到向量生成指定的序列,这个过程也称为解码。
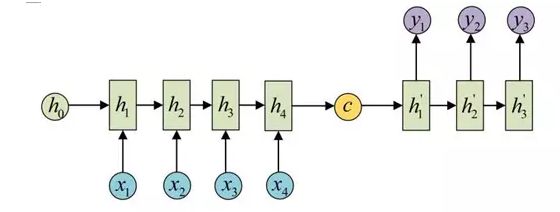
- 如何训练
RNN是可以学习概率分布,然后进行预测,比如我们输入t时刻的数据后,预测t+1时刻的数据,时间序列预测就是比较常见的一种数据形式。为了得到概率分布,一般会在RNN的输出层使用softmax激活函数,就可以得到每个分类的概率。
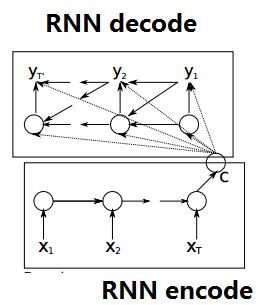
而对于encoder-decoder模型,设有输入序列 x 1 , x 2 , . . . , x T x_1,x_2,...,x_T x1,x2,...,xT,输出序列 y 1 , y 2 , . . . , y T y_1,y_2,...,y_T y1,y2,...,yT,输入序列和输出序列的长度可能不同。那么其实就需要根据输入序列去得到输出序列可能输出的词概率,于是有下面的条件概率发生 x 1 , x 2 , . . . , x T x_1,x_2,...,x_T x1,x2,...,xT的情况下发生的 y 1 , y 2 , . . . , y T y_1,y_2,...,y_T y1,y2,...,yT概率等于 p ( y t ∣ v , y 1 , y 2 , . . . , y t − 1 ) p(y_t|v,y_1,y_2,...,y_{t-1}) p(yt∣v,y1,y2,...,yt−1)连乘,如下公式所示。其中v表示 x 1 , x 2 , . . . , x T x_1,x_2,...,x_T x1,x2,...,xT对应的隐含状态向量,它其实可以等同表示输入序列。
p ( y 1 , y 2 , . . . , y T ∣ x 1 , x 2 , . . . , x T ) = Π t = 1 T p ( y t ∣ x 1 , . . . , x t − 1 , y 1 , . . . , y t − 1 ) = Π t = 1 T p ( y t ∣ v , y 1 , . . . , y t − 1 ) p(y_1,y_2,...,y_T|x_1,x_2,...,x_T) = \Pi^T_{t=1}p(y_t|x_1,...,x_{t-1},y_1,...,y_{t-1}) = \Pi^T_{t=1}p(y_t|v,y_1,...,y_t-1) p(y1,y2,...,yT∣x1,x2,...,xT)=Πt=1Tp(yt∣x1,...,xt−1,y1,...,yt−1)=Πt=1Tp(yt∣v,y1,...,yt−1)
此时 h t = f ( h t − 1 , y t − 1 , v ) h_t = f(h_{t-1},y_{t-1},v) ht=f(ht−1,yt−1,v),decode编码器中隐含状态与上一时刻状态、上一时刻输出和状态v都有关(这里不同于RNN,RNN是与当前时刻的输入相关,而decode编码器是将上一时刻的输出输入到RNN中。于是decoder的某一时刻的概率分布可用下式表示, p ( y t ∣ v , y 1 , y 2 , . . . , y t − 1 ) = g ( h t , y t − 1 , v ) p(y_t|v,y_1,y_2,...,y_{t-1}) = g(h_t,y_{t-1},v) p(yt∣v,y1,y2,...,yt−1)=g(ht,yt−1,v),所以对于训练样本,我们要做的就是在整个训练样本下,所有样本的 p ( y 1 , y 2 , . . . , y T ∣ x 1 , . . . , x T ) p(y_1,y_2,...,y_T|x_1,...,x_T) p(y1,y2,...,yT∣x1,...,xT)概率之和最大。对应的对数似然条件概率函数为 1 N Σ n = 1 N l o g ( y n ∣ x n , θ ) \frac {1}{N} \Sigma^N_{n=1} log(y_n|x_n,θ) N1Σn=1Nlog(yn∣xn,θ)使之最大化, θ θ θ则是待确定的模型参数。