Yolov5
Yolov5
文章目录
- Yolov5
-
-
- 一. Yolov5 现状
- 二. Yolov5 模型结构
- (一)Yolov5 2.0
- (二)Yolov5 6.0
-
- 输入端
- BackBone基准网络
- Head网络
- 三. Yolov5 模型推理流程
- 四. Yolov5 输入端
-
- (一)Mosaic数据增强
- (二)自适应锚框计算
- (三)自适应图片缩放
- 五. Yolov5 BackBone
-
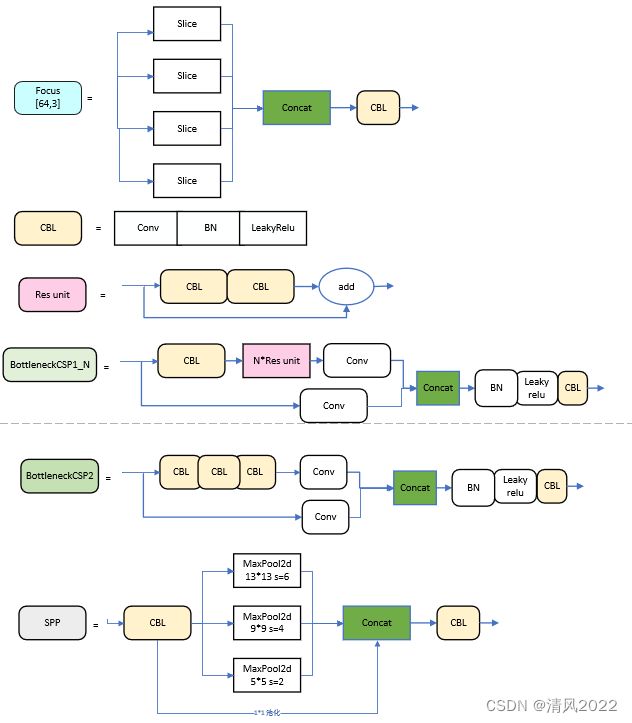
- (一)Focus结构
- (二)CSP结构
- (三)SPP结构 /SPPF结构
- 六. Yolov5 Head
-
- (一) FPN+PAN的结构
- (二)损失函数
- (三)nms非极大值抑制改进
- (四) 激活函数
- 七 . Yolov5 V2.0模型结构代码
-
一. Yolov5 现状
Yolov5 gitlab代码已经更新到V6.0,不同版本的模型结构都有所差异。比如Conv 模块各版本差异示例如下
| yolov5版本 | Conv模块激活函数 |
|---|---|
| 1.0 | LeakyRelu |
| 2.0 | LeakyRelu |
| 3.0 | LeakyRelu |
| 3.1 | hswish |
| 4.0 | SiLU |
| 5.0 | SiLU |
| 6.0 | SiLU |
Yolov5每个版本具有4个开源模型,具体包括:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四种,YOLOv5s模型最小,其它的模型都在此基础上对网络进行加深与加宽。
二. Yolov5 模型结构
(一)Yolov5 2.0
输出:255=(nc+5)*3

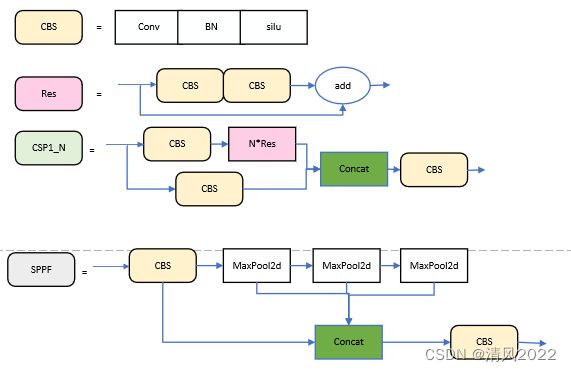
(二)Yolov5 6.0
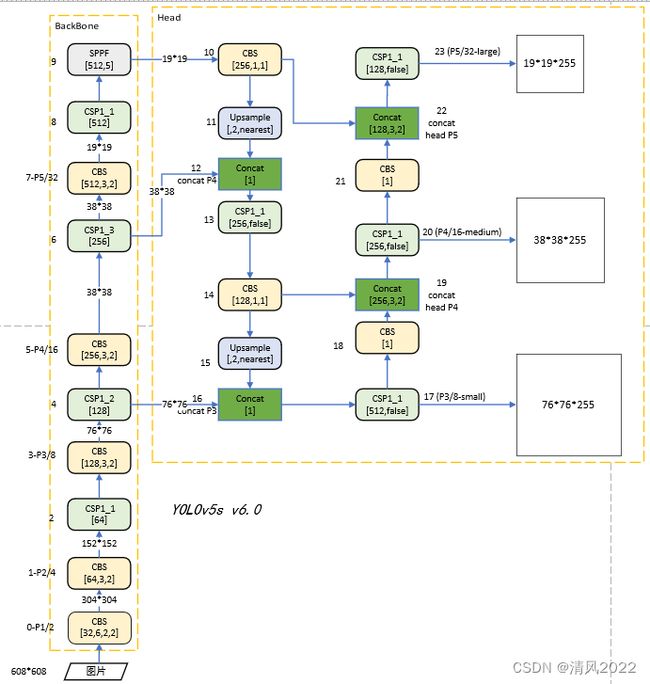
输入端
在模型训练阶段,做了一些改进操作,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
BackBone基准网络
融合其它检测算法中的一些新思路,主要包括:Focus结构,CSP结构;
Head网络
目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
输出层的锚框机制与YOLOv3相同,主要改进的是训练时的损失函数GIOU_Loss。
三. Yolov5 模型推理流程
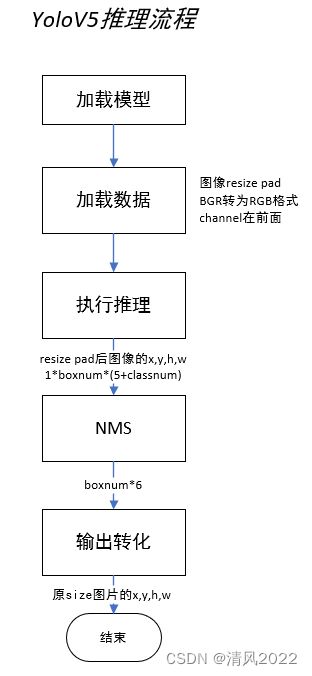
四. Yolov5 输入端
(一)Mosaic数据增强
Yolov5的输入端采用了和Yolov4一样的Mosaic数据增强的方式。
(二)自适应锚框计算
在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。
(三)自适应图片缩放
在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。
因此在Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。
五. Yolov5 BackBone
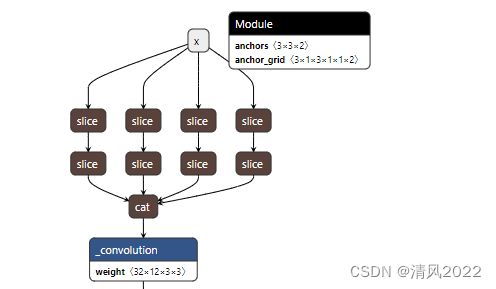
(一)Focus结构
2.0版本
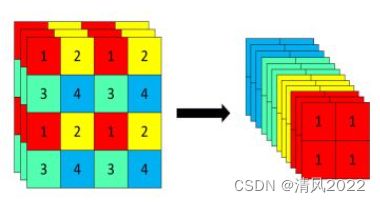
比如右图的切片示意图。
以Yolov5s的结构为例,原始608×608×3的图像输入Focus结构,采用切片操作,先变成304×304×12的特征图,再经过一次32个卷积核的卷积操作,最终变成304×304×32的特征图。
(二)CSP结构
(三)SPP结构 /SPPF结构
2.0版本SPP,输出尺寸和输出尺寸保持一致
6.0版本SPPF
六. Yolov5 Head
(一) FPN+PAN的结构
(二)损失函数
GIOU
(三)nms非极大值抑制改进
加权nms的方式
NMS算法是略显粗暴,因为NMS直接将删除所有IoU大于阈值的框。soft-NMS吸取了NMS的教训,在算法执行过程中不是简单的对IoU大于阈值的检测框删除,而是降低得分。算法流程同NMS相同,但是对原置信度得分使用函数运算,目标是降低置信度得分。
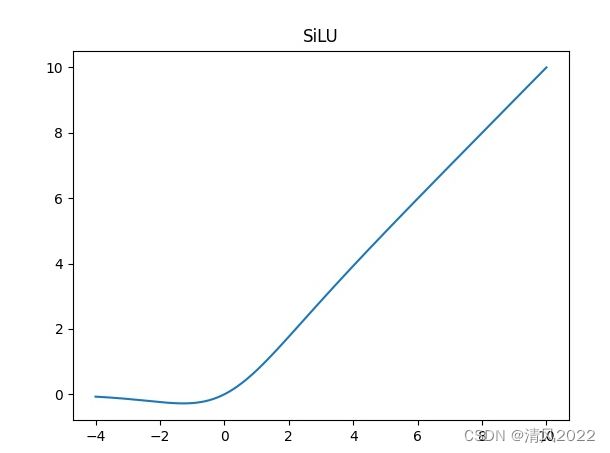
(四) 激活函数
silu(x)= x * sigmoid(x)
七 . Yolov5 V2.0模型结构代码
#yolo5s.yaml V2.0
# parameters
nc: 80 # number of classes 从1开始算起
depth_multiple: 0.33 # model depth multiple 模型深度
width_multiple: 0.50 # layer channel multiple 卷积核的个数,Bottleneck层使用
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4,128个卷积核个数。根据 [128, 3, 2] 解析得到[32, 64, 3, 2] ,32是输入,64是输出(128*0.5=64),3表示3×3的卷积核,2表示步长为2。
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[128, 3, 2] 这是固定的,
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 false表示无残差结构
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]