语义分割系列10-DFANet(pytorch实现)
DFANet:《DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation》
DFANet发表于2019CVPR,是旷视提出的一种用于实时语义分割的深度特征聚合算法。
DFANet论文的主要实现目标是提出一个能够在资源受限条件下快速实现分割的模型。也就是两个核心:“轻量”+“快速”。
论文部分
绪论
与其他轻量级的模型相比,DFANet拥有更少的计算量和更高的分割精度,见图1。
 图1 各模型对比
图1 各模型对比
在绪论部分,作者主要介绍了几个观点:
- 先前的网络中,通过U形网络,利用高分辨率的特征图来帮助恢复上采样时花费了大量的时间。
- 如果单纯的减小输入图像的尺寸来减少时间消耗,就容易导致失去一些重要的边界特征、小物体的细节特征等。
- 如果使用浅层的网络,则会导致网络提取特征的能力不足。
- 有一些模型采用多分支结构来融合空间信息和上下文信息(图2a),但是这些分支在高分辨率图像上的反复处理也会大幅限制速度,而且这些分支之间往往相互独立,限制了模型的学习能力。
- 目前语义分割网络的backbone多为Resnet、Xception、DenseNet,为了实现网络轻量化,使用Depthwise Separable Convolution的Xception是一个不错的选择。
- 主流的语义分割结构,如SPP(图2b),这种金字塔结构虽然能够富集上下文特征,但是计算量十分大。
- 很多语义分割结构中特征重用的思想也启发了作者(图2c d)。
- SeNet的通道注意力启发了EncNet,在EncNet中使用的上下文编码模块则启发了作者,在DFANet中,作者也采用了类似的方法来对通道做一个通道注意力机制。
有了上诉观点的启发,作者提出了一种多分支的框架来融合空间细节和上下文信息,其中以修改过的Xception(论文中命名为XceptionA和XceptionB)为backbone网络。
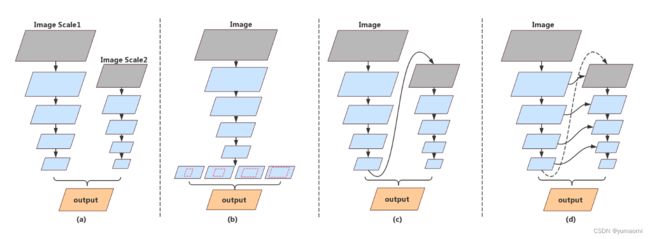 图2 一些语义分割网络的结构
图2 一些语义分割网络的结构
(a)多分支结构 (b)SPP结构 (c)在network上的特征重用 (d)在每个stage上的特征重用
模型
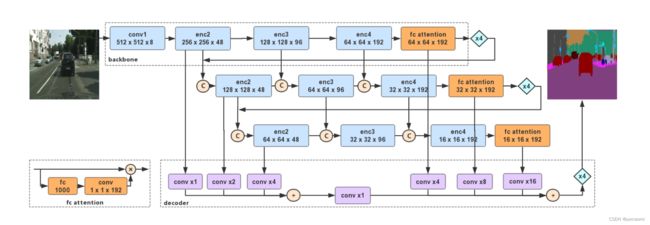 图3 DFANet
图3 DFANet
有了绪论部分的铺垫,作者提出了DFANet。
模型部分,以XceptionA为backbone,延续了常用的Encoder-Decoder结构。
在Encoder结构中,分为3个分支,每个分支都包含了三个encode模块和一个实现通道注意力的fc attention模块,而每一个模块的输出都和下一个分支中的输入相融合。三个分支的哥哥模块输出和输入互相融合之后,每个分支的enc2输出和fc attention输出都跳跃连接到Decoder结构。
在Decoder结构中,主要接受了每个分支的enc2模块输出和fc attention模块输出,其中,三个enc2模块输出相加后经过一个卷积再和三个fc attention模块的输出相加,经过上采样后得到输出。
这种层级之间的特征融合,能够将低级的特征和空间信息传递到最后的语义理解中,通过多层次的特征融合和通道注意力机制,帮助各个阶段的特征完善,以提升分割精度。
代码复现
DFANet
import torch
import torch.nn as nn
import torch.nn.functional as F
class depthwise_separable_conv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1,padding=1, dilation=1):
super(depthwise_separable_conv, self).__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size, stride, padding, dilation, groups=in_channels,bias=False)
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
def forward(self, x):
out = self.depthwise(x)
out = self.pointwise(out)
return out
class XceptionABlock(nn.Module):
"""
Base Block for XceptionA mentioned in DFANet paper.
"""
def __init__(self, in_channels, out_channels, stride=1):
super(XceptionABlock, self).__init__()
self.conv1 = nn.Sequential(
depthwise_separable_conv(in_channels, out_channels //4, stride=stride),
nn.BatchNorm2d(out_channels // 4),
nn.ReLU(),
)
self.conv2 = nn.Sequential(
depthwise_separable_conv(out_channels //4, out_channels //4),
nn.BatchNorm2d(out_channels // 4),
nn.ReLU(),
)
self.conv3 = nn.Sequential(
depthwise_separable_conv(out_channels //4, out_channels),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
self.skip = nn.Conv2d(in_channels, out_channels, 1, stride=stride, bias=False)
def forward(self, x):
residual = self.conv1(x)
residual = self.conv2(residual)
residual = self.conv3(residual)
identity = self.skip(x)
return residual + identity
class enc(nn.Module):
"""
encoder block
"""
def __init__(self, in_channels, out_channels, stride=2, num_repeat=3):
super(enc, self).__init__()
stacks = [XceptionABlock(in_channels, out_channels, stride=2)]
for x in range(num_repeat - 1):
stacks.append(XceptionABlock(out_channels, out_channels))
self.build = nn.Sequential(*stacks)
def forward(self, x):
x = self.build(x)
return x
class ChannelAttention(nn.Module):
"""
channel attention module
"""
def __init__(self, in_channels, out_channels):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, 1000, bias=False),
nn.ReLU(),
nn.Linear(1000, out_channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b,c,_,_ = x.size()
y = self.avg_pool(x).view(b,c)
y = self.fc(y).view(b,c,1,1)
return x*y.expand_as(x)
class SubBranch(nn.Module):
"""
create 3 Sub Branches in DFANet
channel_cfg: the chnnels of each enc stage
branch_index: the index of each sub branch
"""
def __init__(self, channel_cfg, branch_index):
super(SubBranch, self).__init__()
self.enc2 = enc(channel_cfg[0], 48, num_repeat=3)
self.enc3 = enc(channel_cfg[1],96,num_repeat=6)
self.enc4 = enc(channel_cfg[2],192,num_repeat=3)
self.fc_atten = ChannelAttention(192, 192)
self.branch_index = branch_index
def forward(self,x0,*args):
out0=self.enc2(x0)
if self.branch_index in [1,2]:
out1 = self.enc3(torch.cat([out0,args[0]],1))
out2 = self.enc4(torch.cat([out1,args[1]],1))
else:
out1 = self.enc3(out0)
out2 = self.enc4(out1)
out3 = self.fc_atten(out2)
return [out0, out1, out2, out3]
class XceptionA(nn.Module):
"""
channel_cfg: the all channels in each enc blocks
"""
def __init__(self, channel_cfg, num_classes=33):
super(XceptionA, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(8),
nn.ReLU()
)
self.branch = SubBranch(channel_cfg, branch_index=0)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Sequential(
nn.Linear(192, 1000),
nn.ReLU(),
nn.Linear(1000, num_classes)
)
def forward(self, x):
b,c,_,_ = x.szie()
x = self.conv1(x)
_,_,_,x = self.branch(x)
x = self.avg_pool(x).view(b,-1)
x = self.classifier(x)
return x
class DFA_Encoder(nn.Module):
def __init__(self, channel_cfg):
super(DFA_Encoder, self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=8,kernel_size=3,stride=2,padding=1,bias=False),
nn.BatchNorm2d(num_features=8),
nn.ReLU()
)
self.branch0=SubBranch(channel_cfg[0],branch_index=0)
self.branch1=SubBranch(channel_cfg[1],branch_index=1)
self.branch2=SubBranch(channel_cfg[2],branch_index=2)
def forward(self, x):
x = self.conv1(x)
x0,x1,x2,x5=self.branch0(x)
x3=F.interpolate(x5,x0.size()[2:],mode='bilinear',align_corners=True)
x1,x2,x3,x6=self.branch1(torch.cat([x0,x3],1),x1,x2)
x4=F.interpolate(x6,x1.size()[2:],mode='bilinear',align_corners=True)
x2,x3,x4,x7=self.branch2(torch.cat([x1,x4],1),x2,x3)
return [x0,x1,x2,x5,x6,x7]
class DFA_Decoder(nn.Module):
"""
the DFA decoder
"""
def __init__(self, decode_channels, num_classes):
super(DFA_Decoder, self).__init__()
self.conv0 = nn.Sequential(
nn.Conv2d(in_channels=48, out_channels=decode_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(decode_channels),
nn.ReLU()
)
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=48, out_channels=decode_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(decode_channels),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=48, out_channels=decode_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(decode_channels),
nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=192, out_channels=decode_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(decode_channels),
nn.ReLU()
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=192, out_channels=decode_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(decode_channels),
nn.ReLU()
)
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=192, out_channels=decode_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(decode_channels),
nn.ReLU()
)
self.conv_add = nn.Sequential(
nn.Conv2d(in_channels=decode_channels, out_channels=decode_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(decode_channels),
nn.ReLU()
)
self.conv_cls = nn.Conv2d(in_channels=decode_channels, out_channels=num_classes, kernel_size=3, padding=1, bias=False)
def forward(self, x0, x1, x2, x3, x4, x5):
x0 = self.conv0(x0)
x1 = F.interpolate(self.conv1(x1),x0.size()[2:],mode='bilinear',align_corners=True)
x2 = F.interpolate(self.conv2(x2),x0.size()[2:],mode='bilinear',align_corners=True)
x3 = F.interpolate(self.conv3(x3),x0.size()[2:],mode='bilinear',align_corners=True)
x4 = F.interpolate(self.conv5(x4),x0.size()[2:],mode='bilinear',align_corners=True)
x5 = F.interpolate(self.conv5(x5),x0.size()[2:],mode='bilinear',align_corners=True)
x_shallow = self.conv_add(x0+x1+x2)
x = self.conv_cls(x_shallow+x3+x4+x5)
x=F.interpolate(x,scale_factor=4,mode='bilinear',align_corners=True)
return x
class DFANet(nn.Module):
def __init__(self,channel_cfg,decoder_channel,num_classes):
super(DFANet,self).__init__()
self.encoder=DFA_Encoder(channel_cfg)
self.decoder=DFA_Decoder(decoder_channel,num_classes)
def forward(self,x):
x0,x1,x2,x3,x4,x5=self.encoder(x)
x=self.decoder(x0,x1,x2,x3,x4,x5)
return x#可以用以下代码进行测试
import torch
ch_cfg=[[8,48,96],
[240,144,288],
[240,144,288]]
device = torch.device("cpu")
model = DFANet(ch_cfg,64,33)
model = model.to(device)
a = torch.ones([16, 3, 224, 224])
a = a.to(device)
out = model(a)
print(out.shape)数据集Camvid
数据集构建方法: 语义分割数据集:CamVid数据集的创建和使用
按照论文中所说,这里图像的大小Resize为960x720。
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
import os.path as osp
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CamVidDataset(torch.utils.data.Dataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
def __init__(self, images_dir, masks_dir):
self.transform = A.Compose([
A.Resize(960, 720),
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(),
ToTensorV2(),
])
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
def __getitem__(self, i):
# read data
image = np.array(Image.open(self.images_fps[i]).convert('RGB'))
mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))
image = self.transform(image=image,mask=mask)
return image['image'], image['mask'][:,:,0]
def __len__(self):
return len(self.ids)
# 设置数据集路径
DATA_DIR = r'dataset\camvid' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train_images')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'valid_images')
y_valid_dir = os.path.join(DATA_DIR, 'valid_labels')
train_dataset = CamVidDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CamVidDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True,drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=True,drop_last=True)模型训练
#model.load_state_dict(torch.load(r"checkpoints/resnet50-11ad3fa6.pth"),strict=False)
ch_cfg=[[8,48,96],
[240,144,288],
[240,144,288]]
device = torch.device("cuda")
model = DFANet(ch_cfg,64,33)
model = model.to(device)
from d2l import torch as d2l
from tqdm import tqdm
import pandas as pd
#损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)
#选用adam优化器来训练
optimizer = optim.SGD(model.parameters(),lr=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=150, gamma=0.1, last_epoch=-1)
#训练50轮
epochs_num = 150
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,scheduler,
devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
loss_list = []
train_acc_list = []
test_acc_list = []
epochs_list = []
time_list = []
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(
net, features, labels.long(), loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
scheduler.step()
print(f"epoch {epoch+1} --- loss {metric[0] / metric[2]:.3f} --- train acc {metric[1] / metric[3]:.3f} --- test acc {test_acc:.3f} --- cost time {timer.sum()}")
#---------保存训练数据---------------
df = pd.DataFrame()
loss_list.append(metric[0] / metric[2])
train_acc_list.append(metric[1] / metric[3])
test_acc_list.append(test_acc)
epochs_list.append(epoch+1)
time_list.append(timer.sum())
df['epoch'] = epochs_list
df['loss'] = loss_list
df['train_acc'] = train_acc_list
df['test_acc'] = test_acc_list
df['time'] = time_list
df.to_excel("savefile/DFAnet_camvid.xlsx")
#----------------保存模型-------------------
if np.mod(epoch+1, 5) == 0:
torch.save(model.state_dict(), f'checkpoints/DFAnet_{epoch+1}.pth')
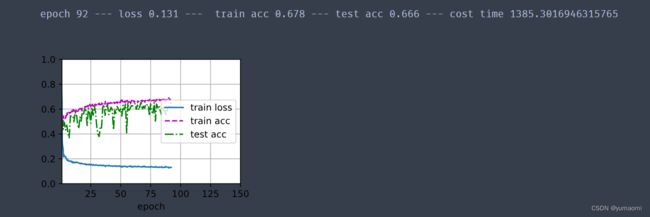
开始训练
train_ch13(model, train_loader, val_loader, lossf, optimizer, epochs_num,scheduler)训练结果