关于特征工程方法和应用的总结
目录
- 特征工程
-
- 1.1 数据
-
- 结构化数据
- 非结构化数据
- 1.2 常用特征处理方法
-
- 1.2.1 类别特征
-
- 独热编码
- 哈希编码
- 标签编码
- 频数编码
- Label-count编码
- 目标编码
- 嵌套法
- NaN编码
- 多项式编码
- 扩展编码
- 合并编码
- 1.2.2 数值特征
-
- 四舍五入
- 数据分箱
- 取对数
- 特征缩放
- 归一化
- 错误数据和缺失数据的处理
- 交叉特征
- 线性算法的非线性编码
- 行统计
- 1.2.3 时间特征
-
- 映射
- 趋势线
- 事件贴近
- 时间差
- 时间分箱
- 1.2.4 空间特征
-
- 位置
- 位置关系
- 异常位置行为
- 1.2.5 自然语言处理
- 1.3 特征选择
-
- 1.3.1 Filter方法
-
- 方差法
- Pearson系数
- 卡方检验
- 互信息法
- 1.3.2 Wrapper方法
-
- 递归特征消除法
- 1.3.3 Embedded
-
- 基于惩罚项的特征选择法
- 基于树模型的特征选择法
- 深度学习特征选择方法
- 1.3.4 其他
特征工程
根据事物所具有的共性,所抽象出来的能代表这个事物的概念,就叫特征。而特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展现数据的过程,在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,设计更高效的特征以刻画求解的问题与预测模型之间的关系。数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
1.1 数据
结构化数据
结构化数据类型可以看作是关系型数据库的一张表每一列都有清晰的定义,包含了数值型、类别型两种基本类型,每一行数据表示一个样本的信息。
非结构化数据
主要包括文本、图像、音频、视频数据,其包含的信息无法用一个简单的数值表示,也没有清晰的类别定义,并且每条数据的大小各不相同。
1.2 常用特征处理方法
1.2.1 类别特征
独热编码
独热编码是一种数据预处理技巧,它可以把类别数据变成长度相同的特征,常用语特征间不存在内在顺序的场景,并且类别数量最好不要大于4。例如,人的性别分成男女,每一个人的记录只有男或者女,那么我们可以创建一个维度为2的特征,如果是男,则用(1,0)表示,如果是女,则用(0,1)。即创建一个维度为类别总数的向量,把某个记录的值对应的维度记为1,其他记为0即可。对于类别不多的分类变量,可以采用独热编码。
哈希编码
对于类别数量很多的分类变量可以采用哈希编码,其目标就是将一个数据点转换成一个向量。利用的是哈希函数将原始数据转换成指定范围内的散列值,相比较独热模型具有很多优点,如支持在线学习,维度减小等。
标签编码
标签编码直接将类别转换为数字,常用于类别间存在内在顺序的场景。例如成绩以分为低、中、高三挡 并且存在“高>中>低”的排序关系 标签编码会按照大小关系对类别型特征赋予一个数值 ID ,例如高表示为3,中表示为2、低表示为1,转换后依然保留了大小关系。
频数编码
频数编码使用频次替换类别,频次根据训练集计算。这个方法对离群值很敏感,所以结果可以归一化或者转换一下(例如使用对数变换)。未知类别可以替换为1。但这种编码一个明显的缺点就是容易导致类别碰撞,即两个类别编码的值相等。
例如下图中,左侧是老师的ID,右侧表示对应的ID在数据集中出现的频数。
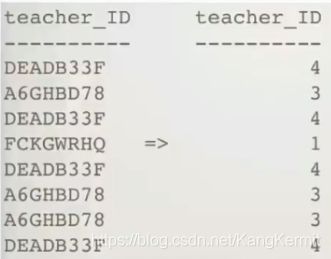
Label-count编码
根据类别在训练集中的频次排序类别(升序或降序)。相比标准的频次编码,LabelCount具有特定的优势——对离群值不敏感,也不会对不同的值给出同样的编码。
目标编码
它使用目标变量的均值编码类别变量,适用于特征间不存在内部的顺序关系,并且类别数量一般大于4时使用。我们为训练集中的每个分组计算目标变量的统计量(这里是均值),之后会合并验证集、测试集以捕捉分组和目标之间的关系。例如在某一网站某一栏目发布帖子,可以通过计算每个栏目的回答评分的均值,从而得到在特定栏目发帖可以期望得到多少赞,这样有一个大概的估计。
嵌套法
嵌套法是使用神经网络的方法来将原始输入数据转换成新特征,嵌入实际上是根据想要实现的任务将特征投影到更高维度的空间,因此在嵌入空间中,或多或少相似的特征在它们之间具有小的距离。 这允许分类器更好地以更全面的方式学习表示。例如,word embedding就是将单个单词映射成维度是几百维甚至几千维的向量,再进行文档分类,原本具有语义相似性的单词映射之后的向量之间的距离也比较小,进而可以帮助我们进一步进行机器学习的应用,这一点比独热模型好很多。
目前比较常用的嵌入模型是word2Vec,它主要由两个网络结构组成,分别是CBOW和Skip-gram,下图为两种网络的结构图。其中CBOW是根据上下文出现的词语来预测当前词的生成概率;而Skip-gram则是根据当前词来预测上下文中各词生成的概率。
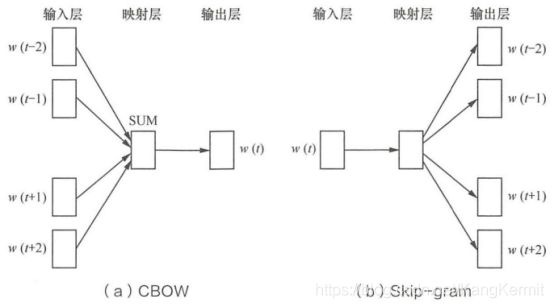
NaN编码
NaN值就是缺失值,通常会的做法是直接忽略或利用其它缺失值填充方法进行处理,实际上NaN值在某些具体的业务中也是可以保存信息的,NaN编码方法就是为NaN值提供显式编码而不是忽略。
多项式编码
想要丰富特征,特别是对于线性模型而言,除了分箱外,另一种方法是添加原始数据的交互特征和多项式特征。对于给定的特征x,我们可以考虑x,x2、x3等。
扩展编码
就是一个变量扩充为多个变量,如一个数值特征,除了这个特征本身还可扩展为平均值、方差等。
合并编码
有时在类别够多时,数据集极有可能会发生各个类别样本数量差别很大的情况,有些类别样本数量很多,有些类别样本数量很少,甚至几个或几十个。这种情况如果不扩充对应样本数量或组合相似类别的样本到单独的类别,就很容易出现过拟合。可以通过样本聚类的方式样本较少的并且相似的样本聚成一类,并给定一个统一的类别。
1.2.2 数值特征
四舍五入
即取向上或向下取整。
数据分箱
数据分箱是一种数据预处理技术,用于减少轻微观察错误的影响。落入给定小间隔bin的原始数据值由代表该间隔的值(通常是中心值)代替。这是一种量化形式。 统计数据分箱是一种将多个或多或少连续值分组为较少数量的“分箱”的方法。例如,如果有关于一组人的数据,您可能希望将他们的年龄安排到较小的年龄间隔。对于一些时间数据可以进行分箱操作,例如一天24小时可以分成早晨[5,8),上午[8,11),中午[11,14),下午[14,19),夜晚[10,22),深夜[19,24)和临晨[24,5)。因为比如中午11点和12点其实没有很大区别,可以使用分箱技巧处理之后可以减少这些“误差”。可以对比目前系统的risklevel到风险等级的映射关系,其中risklevel的取值范围为 [ 0 , + ∞ ) [0,+\infty) [0,+∞)。
取对数
取对数就是指对数值做log转换,可以将范围很大的数值转换成范围较小的区间中。Log转换对分布的形状有很大的影响,它通常用于减少右偏度,使得最终的分布形状更加对称一些。它不能应用于零值或负值。对数刻度上的一个单位表示乘以所用对数的乘数。另外,在某些机器学习的模型中,对特征做对数转换可以将某些连乘变成求和,更加简单。
如前所述,log转换可以将范围很大的值缩小在一定范围内,这对某些异常值的处理也很有效,例如用户查看的网页数量是一个长尾分布,一个用户在短时间内查看了500个和1000个页面都可能属于异常值,其行为可能差别也没那么大,那么使用log转换也能体现这种结果。

特征缩放
特征缩放是一种用于标准化独立变量或数据特征范围的方法。在数据处理中,它也称为数据标准化,并且通常在数据预处理步骤期间执行。特征缩放可以将很大范围的数据限定在指定范围内。由于原始数据的值范围变化很大,在一些机器学习算法中,如果没有标准化,目标函数将无法正常工作。 例如,大多数分类器按欧几里德距离计算两点之间的距离。 如果其中一个要素具有宽范围的值,则距离将受此特定要素的控制。 因此,应对所有特征的范围进行归一化,以使每个特征大致与最终距离成比例。应用特征缩放的另一个原因是梯度下降与特征缩放比没有它时收敛得快得多。
特征缩放主要包括最大最小缩放(Min-max Scaling)和标准化缩放(Standard(Z) Scaling)两种方式。
归一化
在最简单的情况下,归一化化意味着将在不同尺度上测量的值调整到概念上的共同尺度。在更复杂的情况下,归一化可以指更复杂的调整,其目的是使调整值的整个概率分布对齐。在一般情况下会与正态分布对齐。
在统计学的另一种用法中,归一化将不同单位的数值转换到可以互相比较的范围内,避免总量大小的影响。归一化后的数据对于某些优化算法如梯度下降等也很重要。常用的归一化方法包括线性归一化和零均值归一化。
错误数据和缺失数据的处理
错误数据可以矫正,如格式错误,如时间2020-05-11统一格式为20200511
对于缺失数据的处理,有以下方法:
①去掉所在的行/列
②均值填充
③中位数填充
④众数填充
⑤算法预测填充
交叉特征
在特征工程中,挖掘交叉特征是至关重要的。交叉特征指的是两个或多个原始特征之间的交叉组合。例如,在新闻推荐场景中,一个三阶交叉特征为AND(user_organization=msra,item_category=deeplearning,time=monday_morning),它表示当前用户的工作单位为微软亚洲研究院,当前文章的类别是与深度学习相关的,并且推送时间是周一上午。
传统的交叉特征是由工程师手动设计的,这有很大的局限性,成本很高,并且不能拓展到未曾出现过的交叉模式中。为此利用神经网络自动的去学习高阶的特征交互模式,弥补人工特征工程带来的局限性,这些模型包括:Wide&Deep、PNN、DeepFM、DCN以及近期提出的xDeepFM。这类模型在推荐系统中应用较多。
线性算法的非线性编码
硬编码非线性以改进线性算法、多项式核、叶编码、遗传算法
行统计
Null的个数、0的个数、负数的个数、均值、最大值、最小值等
1.2.3 时间特征
映射
将数值某一个数值映射成圆上的两个坐标,适用于一周的第几天,一个月的第几天,一天中的第几个小时这种关系。也可以转换为具体的数字,如第几个月,第一天,第几个小时,第几秒,以及其他的一些扩展,如节日之类的。
趋势线
使用趋势量而不是总量来编码,例如使用上个星期花销,上个月花销,去年的花销,而不是总花销。两个总花销相同的客户可能在消费行为上有很大差别。
事件贴近
每个月的第几天,每周的周末,某政治事件前后,这种重要事件节点附近的值可能会更有意义。
时间差
如上次用户交互到这次用户交互的时间间隔,看时间间隔有没有什么规律,如心跳等。
时间分箱
如工作时间段和非工作时间段,如果在非工作时间段出现了大量的交互记录,需要重点关注。
1.2.4 空间特征
GPS坐标、国家、城市、地址、非境外等
位置
GPS的经纬度、将城市名称映射成经纬度、将地址添加上邮编、特征聚类等
位置关系
位置与附近主要枢纽间的联系紧密程度、城市所属省份、电话/IP映射成地理位置或附近机构等。
异常位置行为
一些关于位置数据可能会指示可疑行为,如异常的速度,同一用户不同国家几乎同时交互等。
1.2.5 自然语言处理
| 处理方法 | 描述 |
|---|---|
| 小写或大写 | 统一改为小写或者大写的格式 |
| 删除非字母数字字符 | 仅处理字母和数字 |
| 拼写矫正 | 矫正明显的拼写错误,如多空格,提前换行等 |
| 符号编码 | 直接对符号进行硬编码,将其与字母数字一视同仁 |
| 分词 | 将句子切分为一个个单词 |
| N-grams | N-grams模型处理文本 |
| Skipgrams | 与ngrams差不多,就是中间要跳过一个单词。如I like the Beatles,则转换为[“I the”, “like Beatles”] |
| chargrams | 字符级别的ngrams |
| 去除停用词 | |
| 去除罕见词和常用词 | 去除及其罕见以及不在停用词列表中的及其常见的单词 |
| 词干提取 | 找词根,如dogs,那么就转换为dog |
| 词形还原 | 词形还原,如never be late转换为never are late |
| 文档特征 | 空格数量、tab数量、空行数量、字符数量等 |
| 采样 | |
| Word2Vec、GloVe和Doc2Vec | |
| 字符串相似性 | 计算同时出现在两个文档中的词的数量;计算二者之间的汉明距离、jaccard距离和Levenshtein距离;计算二者之间的word2vec或Glove向量距离。 |
| 最近邻 | |
| TF-IDF | TF-IDF建模 |
| PCA、SVD、LDA、LSA | 降维 |
1.3 特征选择
首先,从特征开始说起,假设现在有一个标准的Excel表格数据,它的每一行表示的是一个观测样本数据,表格数据中的每一列就是一个特征。在这些特征中,有的特征携带的信息量丰富,有的(或许很少)则属于无关数据(irrelevant data),我们可以通过特征项和类别项之间的相关性(特征重要性)来衡量。比如,在实际应用中,常用的方法就是使用一些评价指标单独地计算出单个特征跟类别变量之间的关系。如Pearson相关系数,Gini-index(基尼指数),IG(信息增益)等。
1.3.1 Filter方法
按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。在进行特征选择时常使用sklearn的SelectKBest方法,它的第一个参数是函数,第二个参数是选择的特征个数。score_func可以是自行构造的,也可以是系统推荐的,其中推荐的包括:f_classif(方差分析)、chi2(卡方验证)、f_regression、SelectPercentile、SelectFpr、SelectFdr、mutual_info_classif、SelectFwe和GenericUnivariateSelect。
方差法
首先计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。使用feature_selection库的VarianceThreshold类来选择特征的代码如下:
from sklearn.datasets import load_iris
from sklearn.feature_selection import VarianceThreshold
#方差选择法,返回值为特征选择后的数据
#参数threshold为方差的阈值
iris = load_iris()
print(iris.data[0])
print(iris.target[0])
Var = VarianceThreshold(threshold=3) # 创建对象
New_feature = Var.fit_transform(iris.data) # 筛选除新的特征
print(New_feature[0])
输出:
[ 5.1 3.5 1.4 0.2]
0
[ 1.4]
从输出结果看,只有data的第三列满足该条件。
Pearson系数
Pearson系数的计算方式如下:
r x y 2 = c o n ( x , y ) v a r ( x ) v a r ( y ) r_{xy}^2=\frac{con(x,y)}{\sqrt{var(x)var(y)}} rxy2=var(x)var(y)con(x,y)
其中,属于 x x x表示一个特征的观测值, X X X表一个特征的多个观测值, y y y表示这个特征观测值对应的类别列表。
Pearson相关系数的取值在0到1之间,Sklearn实现pearson系数的特征选择:
from sklearn.feature_selection import SelectKBest, f_classif
from scipy.stats import pearsonr
from sklearn.datasets import load_iris
import numpy as np
iris=load_iris()
# 函数输入特征矩阵和目标向量,输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
def multivariate_pearsonr(X, y):
scores, pvalues = [], []
for ret in map(lambda x:pearsonr(x, y), X.T):
scores.append(abs(ret[0]))
pvalues.append(ret[1])
return (np.array(scores), np.array(pvalues))
# pearson函数
# 输入:x为特征,y为目标变量
# 输出:r: 相关系数 [-1,1]之间,p-value: p值
# 注: p值越小,表示相关系数越显著,一般p值在500个样本以上时有较高的可靠性。
# SelectKBest的第一个参数是计算评估特征是否好的函数,第二个参数k为选择的特征个数
transformer = SelectKBest(score_func=multivariate_pearsonr, k=2)
Xt_pearson = transformer.fit_transform(iris.data, iris.target)
print(Xt_pearson)
当然也有其他利用该系数的方式,如果使用这个评价指标来计算所有特征和类别标号的相关性,那么得到这些相关性之后,可以将它们从高到低进行排名,然后选择一个子集作为特征子集(比如top 10%),接着用这些特征进行训练,看看性能如何。此外,还可以画出不同子集的一个精度图,根据绘制的图形来找出性能最好的一组特征。
卡方检验
卡方检验只能用于二分类任务,就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小;若两个值完全相等时,卡方值就为0,表明理论值完全符合。
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有种取值,因变量有种取值,考虑自变量等于且因变量等于的样本频数的观察值与期望的差距,构建统计量:
χ 2 = ∑ ( A − E ) 2 E = ∑ i = 1 k ( A i − E i ) 2 E i = ∑ i = 1 k ( A i − n p i ) 2 n p i \chi^2=\sum\frac{(A-E)^2}{E}=\sum_{i=1}^k\frac{(A_i-E_i)^2}{E_i}=\sum_{i=1}^k\frac{(A_i-np_i)^2}{np_i} χ2=∑E(A−E)2=i=1∑kEi(Ai−Ei)2=i=1∑knpi(Ai−npi)2
在实际运用中使用sklearn的chi2和SelectKBest的组合就可完成基于卡方检验的特征选择。
互信息法
经典的互信息也是评价定性自变量对定性因变量的相关性的。相关系数、卡方检验、互信息法选择特征的原理是相似的,但相关系数通常只适合于连续特征的选择。互信息计算公式如下:
I ( X ; Y ) = ∑ x ∈ X ∑ y ∈ Y p ( x , y ) l o g p ( x , y ) p ( x ) p ( y ) I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x,y)}{p(x)p(y)} I(X;Y)=x∈X∑y∈Y∑p(x,y)logp(x)p(y)p(x,y)
在实际运用中使用sklearn的mutual_info_classif和SelectKBest的组合就可完成基于互信息法的特征选择。
1.3.2 Wrapper方法
封装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
递归特征消除法
递归特征消除的主要思想是,反复构建模型,然后选出其中贡献最差的特征,把选出的特征剔除,然后在剩余特征上继续重复这个过程,直到所有特征都已遍历。这是一种后向搜索方法,采用了贪心法则。而特征被剔除的顺序,即是它的重要性排序。为了增强稳定性,这里模型评估常采用交叉验证的方法。具体实现如下:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
#递归特征消除法,返回特征选择后的数据
#参数estimator为基模型
#参数n_features_to_select为选择的特征个数
# 函数RFE即返回已经选择好的特征
RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(iris.data,iris.target)
1.3.3 Embedded
集成法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。实现代码:
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
# 带L1惩罚项的逻辑回归作为基模型的特征选择
SelectFromModel(LogisticRegression(penalty="l1",C=0.1)).fit_transform(iris.data, iris.target)
基于树模型的特征选择法
树模型在学习时,是以纯度为评价基准,选择最好的分裂属性进行分裂,这本身也可以看作一个特征选择的过程。这里选择随机森林算法为选择算法,在实现上,有平均不纯度减少和平均精确度减少两种。
1.3.3.2.1.平均不纯度减少
树模型的训练过程,总在选择最优的属性将数据分裂,属性的优劣是通过计算每个特征对树的不纯度的减少程度。而对于随机森林,可以计算每课树减少的不纯度的平均值,作为特征的重要性系数。
但不纯度方法存在一定的缺陷。不论哪种度量手段,都存在着一定的偏好。例如信息增益偏好取值多的属性、信息增益率偏好取值少的属性。且对于存在关联的一组强特征,率先被选择的属性重要性远远高于后被选择的属性,因为某属性一旦备选意味着数据集不纯度会迅速下降,而其他属性无法再做到这一点,容易对特征的理解产生歧义。
1.3.3.2.2.平均精确度减少
平均精确度减少是直接度量每个特征对模型精确率的影响。主要思路是打乱特征的特征值顺序,度量顺序变动对于模型精确率的影响。很明显,对于不重要的变量,打乱顺序对精确率影响不会太大,但重要的特征,就会对精确率产生明显的影响。
Sklearn实现代码:
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
#GBDT作为基模型的特征选择
SelectFromModel(RandomForestClassifier()).fit_transform(iris.data, iris.target)
深度学习特征选择方法
可以从深度学习模型中选择某一层神经层的特征,这些特征就可以用来进行最终目标模型的训练。
1.3.4 其他
如通过绘制特征的分布图,有时可以指导特征工程,如数据分箱范围等。
感谢阅读。
如果觉得文章对你有所帮助,欢迎打赏哦~

