Self-Attention原理、Multi-head Self-Attention原理及Pytorch实现
一、Self-Attention原理
下图虚线框内为Self-Attention模块基本功能,输入 a 1 , a 2 , a 3 , a 4 a_1,a_2,a_3,a_4 a1,a2,a3,a4,输出 b 1 , b 2 , b 3 , b 4 b_1,b_2,b_3,b_4 b1,b2,b3,b4。输入序列与输出序列长度相同,内部实际上做的是加权求和的运算。
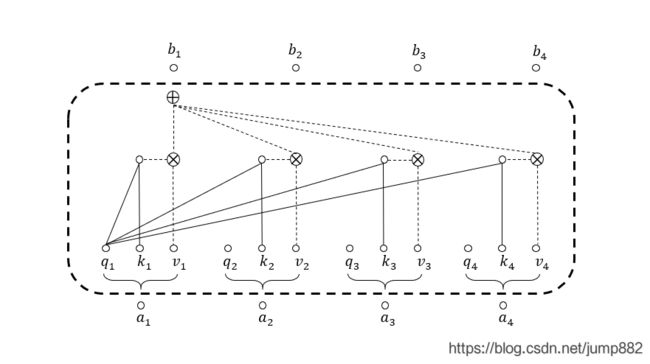
1、计算 a 1 a_1 a1与所有向量(包括自己)的attention-score
使用 q 1 q_1 q1与 k 1 , k 2 , k 3 , k 4 k_1,k_2,k_3,k_4 k1,k2,k3,k4相乘得到 α 1 , 1 , α 1 , 2 , α 1 , 3 , α 1 , 4 \alpha_{1,1},\alpha_{1,2},\alpha_{1,3},\alpha_{1,4} α1,1,α1,2,α1,3,α1,4: α 1 , 1 = q 1 ⋅ k 1 \alpha_{1,1}=q_1\cdot k_1 α1,1=q1⋅k1 α 1 , 2 = q 1 ⋅ k 2 \alpha_{1,2}=q_1\cdot k_2 α1,2=q1⋅k2 α 1 , 3 = q 1 ⋅ k 3 \alpha_{1,3}=q_1\cdot k_3 α1,3=q1⋅k3 α 1 , 4 = q 1 ⋅ k 4 \alpha_{1,4}=q_1\cdot k_4 α1,4=q1⋅k4
2、将 α 1 , i \alpha_{1,i} α1,i与对应的 v i v_i vi相乘再相加得到 b 1 b_1 b1
b 1 = α 1 , 1 ⋅ v 1 + α 1 , 2 ⋅ v 2 + α 1 , 3 ⋅ v 3 + α 1 , 4 ⋅ v 4 b_1=\alpha_{1,1}\cdot v_1 +\alpha_{1,2}\cdot v_2 +\alpha_{1,3}\cdot v_3 +\alpha_{1,4}\cdot v_4 b1=α1,1⋅v1+α1,2⋅v2+α1,3⋅v3+α1,4⋅v4
3、矩阵化运算
1)仅权重矩阵 W q , W k , W v W^q,W^k,W^v Wq,Wk,Wv为模型需要学习的参数。得到 Q , K , V Q,K,V Q,K,V矩阵。

2)计算Attention-Score α i , j \alpha_{i,j} αi,j
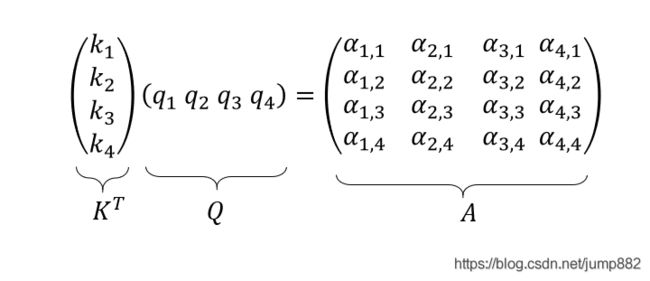
3)softmax操作以及除 d \sqrt d d
为了使注意力分数在[0,1]之间且求和为1,使用softmax函数(softmax回归解释)。

4)计算Self-Attention输出
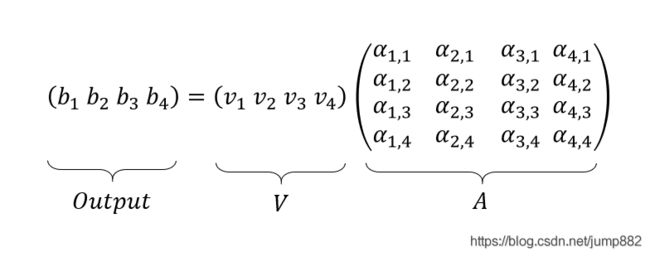
4、Self-Attention pytorch实现
class SelfAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(SelfAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# `queries` 的形状:(`batch_size`, 查询的个数, `d`)
# `keys` 的形状:(`batch_size`, “键-值”对的个数, `d`)
# `values` 的形状:(`batch_size`, “键-值”对的个数, 值的维度)
# `valid_lens` 的形状: (`batch_size`,) 或者 (`batch_size`, 查询的个数)
def forward(self, queries, keys, values):
d = queries.shape[-1]
# 设置 `transpose_b=True` 为了交换 `keys` 的最后两个维度
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = torch.softmax(scores, dim=2)
return torch.bmm(self.dropout(self.attention_weights), values)
attention = SelfAttention(dropout=0.5)
batch_size, num_queries, num_hiddens = 2, 4, 10
X = torch.ones((batch_size, num_queries, num_hiddens))
ans = attention(X, X, X)
print(ans)
torch.Size([2, 4, 10])
二、Multi-head Self-Attention原理
1、Multi-head原理
假设head=2,计算时每个head之间的数据独立,不产生交叉。最终 b i b_i bi的输出需要一个权重矩阵 W O W^O WO模型学习得到。
 当head=h时,最终Output由h个head产生的 O u t p u t i Output_i Outputi与权重矩阵相乘得到:
当head=h时,最终Output由h个head产生的 O u t p u t i Output_i Outputi与权重矩阵相乘得到:
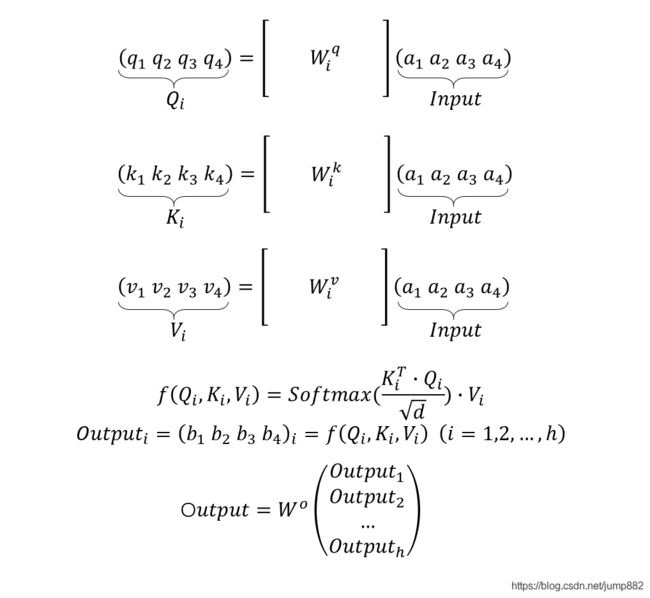
2、Multi-head Self-Attention pytorch实现
未引入Multi-head机制前:X[batch_size,seq_len,feature_dim]
引入head后:X[batch_size*head_num,seq_len,feature_dim/head_num]
定义 transpose_qkv(),tanspose_output() 函数实现上述转换:
def transpose_qkv(X, num_heads):
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
X = X.permute(0, 2, 1, 3)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X, num_heads):
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
class MultiHeadAttention(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = SelfAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values):
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
output = self.attention(queries, keys, values)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
batch_size, num_queries, num_hiddens, num_heads = 2, 4, 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens, num_hiddens, num_heads, 0.5)
X = torch.ones((batch_size, num_queries, num_hiddens))
ans = attention(X, X, X)
print(ans.shape)
torch.Size([2, 4, 100])
三、参考资料
[1]:https://www.bilibili.com/video/av972327299/.
[2]:https://zh-v2.d2l.ai/