cs224w(图机器学习)2021冬季课程学习笔记20 Advanced Topics on GNNs
诸神缄默不语-个人CSDN博文目录
cs224w(图机器学习)2021冬季课程学习笔记集合
文章目录
- 1. Advanced Topics on GNNs
- 2. Limitations of Graph Neural Networks
- 3. Position-aware Graph Neural Networks[^3]
- 4. Identity-aware Graph Neural Networks[^4]
- 5. Robustness of Graph Neural Networks
YouTube视频观看地址1 视频观看地址2 视频观看地址3 视频观看地址4
本章主要内容:
本章首先介绍了在此之前学习的message passing系GNN模型的限制,然后介绍了position-aware GNN1 和 identity-aware GNN (IDGNN)2 来解决相应的问题。
最后介绍了GNN模型的鲁棒性问题。
1. Advanced Topics on GNNs
- 我们首先可以回忆一下图神经网络:输入图结构数据,经神经网络,输出节点或更大的网络结构(如子图或图)的嵌入。
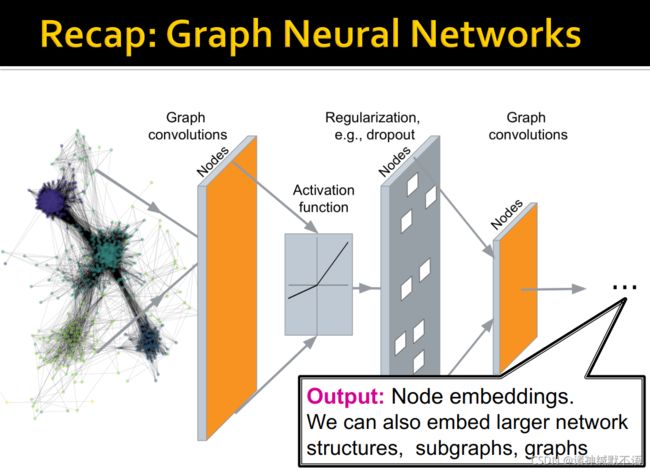
- 此外还可以回忆一下 general GNN framework 和 GNN training pipeline 的相关内容3
2. Limitations of Graph Neural Networks
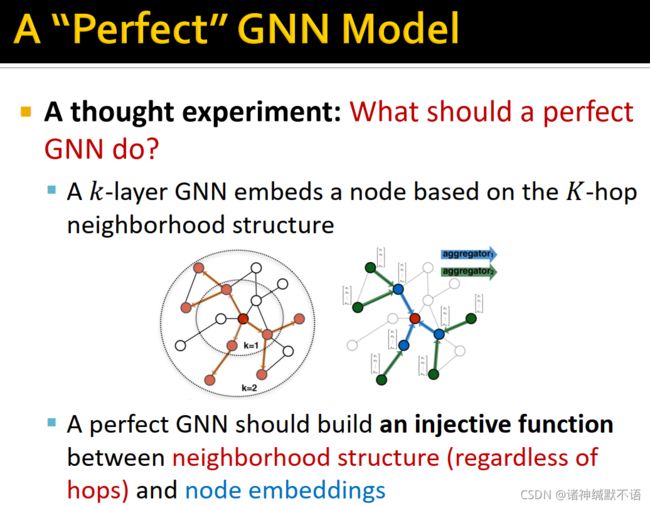
- 完美的GNN模型
在这里我们提出一个思想实验:完美的GNN应该做什么?
k层GNN基于K跳邻居结构嵌入一个节点,完美的GNN应该在邻居结构(无论多少跳)和节点嵌入之间建立单射4 函数。
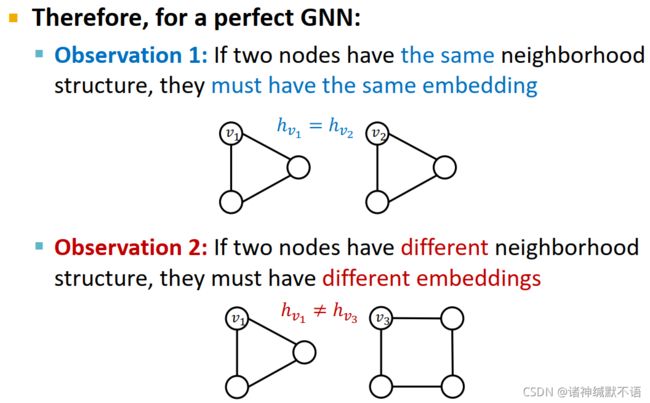
因此,对于完美GNN,假设节点特征完全一样,所以节点嵌入的区别完全在于结构。在这种情况下,①有相同邻居结构的节点应该有相同的嵌入,②有不同邻居结构的节点应该有不同的嵌入。
- 现有GNN的不完美之处
即使是符合上述条件的“完美GNN”也不完美。
①即使有相同邻居结构的节点,我们也可能想对它们分配不同的嵌入,因为它们出现在图中的不同位置positions。这种任务就是position-aware tasks。
比如即使是完美GNN,在图示任务上也会失效(左图比较显然,就是左下角点和右上角点虽然有完全一样的邻居结构,但是由于其位置不同,我们仍然希望它们有不同的嵌入。右图我没搞懂,它节点标哪儿了我都没看到)

②在lecture 94 中,我们讨论了message passing系GNN的表现能力上限为WL test。所以举例来说,图中的 v 1 v_1 v1 和 v 2 v_2 v2 在cycle length(就是节点所处环的节点数)上的结构差别就无法被捕获,因为虽然它们结构不同,但计算图是相同的:

- 本节lecture就要通过构建更有表现力的GNN模型来解决上述两个问题:
对①问题:通过图中节点的位置来生成节点嵌入,方法举例:position-aware GNNs1
对②问题:构建比WL test更有表现力的message passing系GNN,方法举例:identity-aware GNNs2

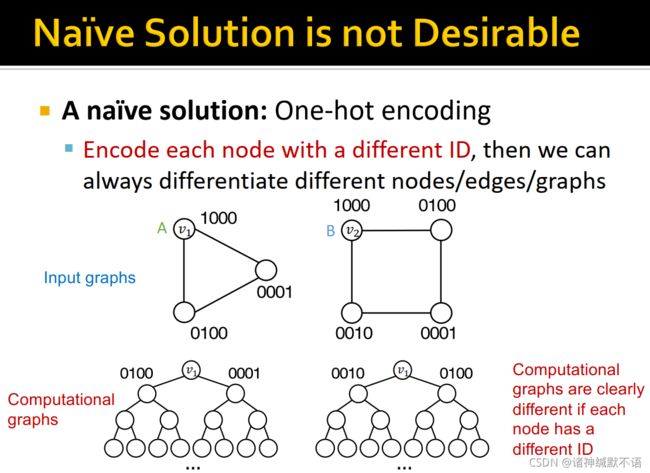
- 我们希望不同的输入(节点、边或图)被标注为不同的标签。而嵌入是通过GNN计算图得到的,如图所示:
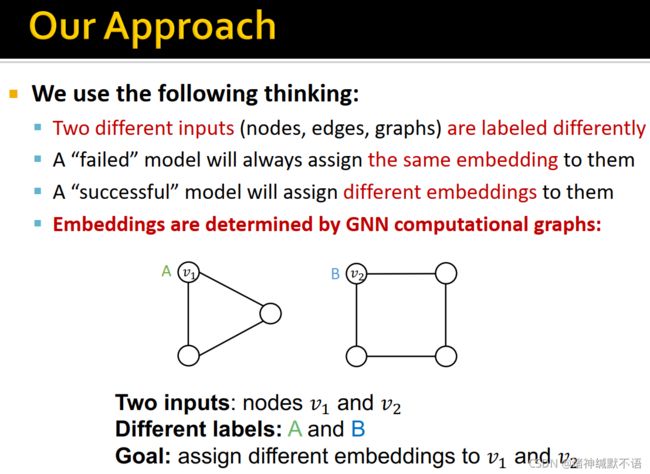
- 直接通过独热编码的方式来试图区分计算图是不行的,如图所示:
给每个节点以一个独热编码表示的唯一ID的话,我们就能区分不同的节点/边/图,计算图显然是会不同的(就算个别层出现相同的情况,因为节点不一样,所以后面几层、最终的整条计算树总是会不同的),所以可以实现。
问题是这样不scalable(需要 O ( N ) O(N) O(N) 维特征),也不inductive(显然无法泛化到新节点/新图上:这个很依赖于节点顺序,一换图就不行了)。
但是这种通过增加节点特征使得通过计算图可以更好地进行节点分类的思路是可行的。

3. Position-aware Graph Neural Networks1
-
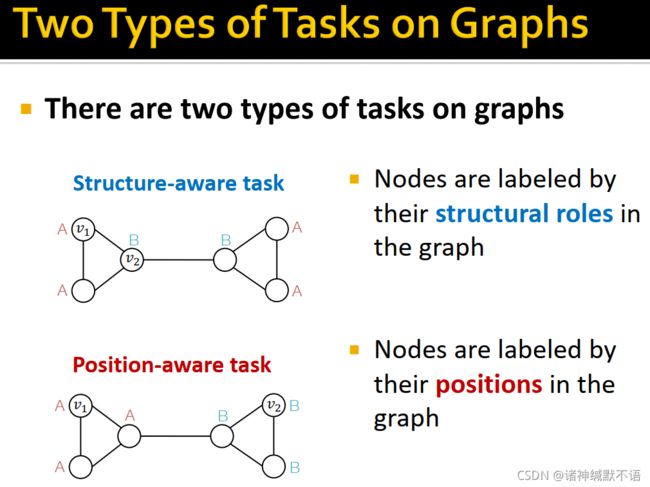
如图所示,图上有两种任务:一种是structure-aware task(节点因在图上的结构不同而有不同的标签),一种是position-aware task(节点因在图上的位置不同而有不同的标签)。真实任务往往结合了structure-aware和position-aware,所以我们需要能够同时解决这两种任务的方法。
-
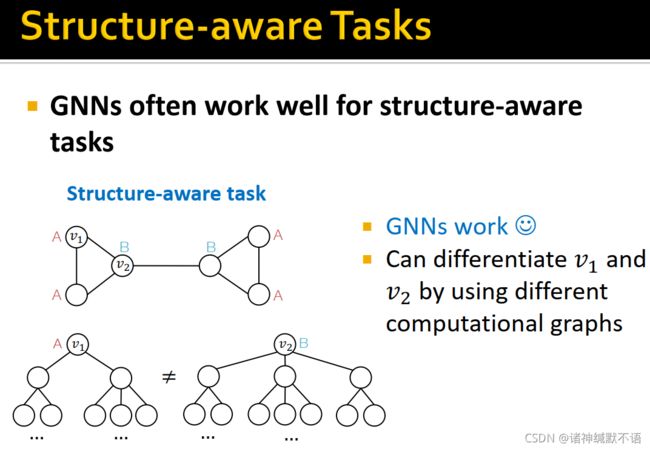
GNN往往对structure-aware tasks表现很好,如图所示,GNN可以通过不同的计算图来区分 v 1 v_1 v1 和 v 2 v_2 v2 这两个局部结构不同的节点。
-
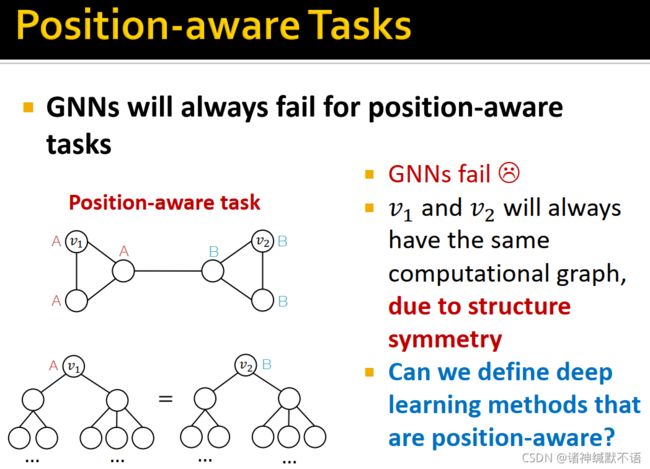
但GNN对position-aware tasks表现较差,如图所示,因为结构对称性, v 1 v_1 v1 和 v 2 v_2 v2 会有相同的计算图,所以他们的嵌入也会相同。因此我们想要定义position-aware的深度学习方法来解决这一问题。
-
anchor
解决方法就是使用anchor作为reference points:
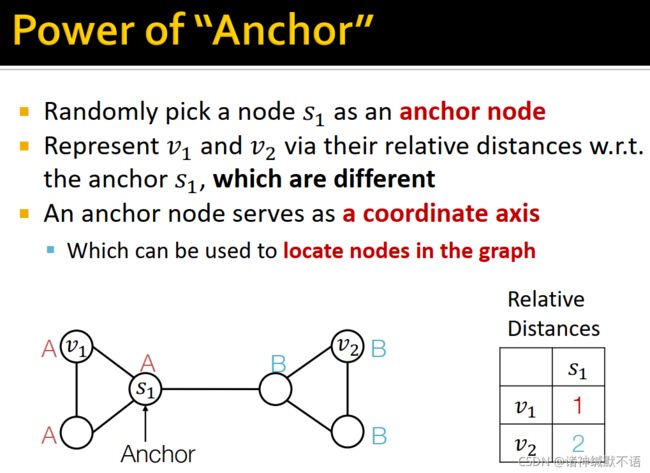
如图所示,随机选取节点 s 1 s_1 s1 作为anchor node,用对 s 1 s_1 s1 的相对距离来表示 v 1 v_1 v1 和 v 2 v_2 v2,这样两个节点就不同了( v 1 v_1 v1 是1, v 2 v_2 v2 是0)。
anchor node相当于坐标轴,可以用于定位图中的节点。
-
anchors
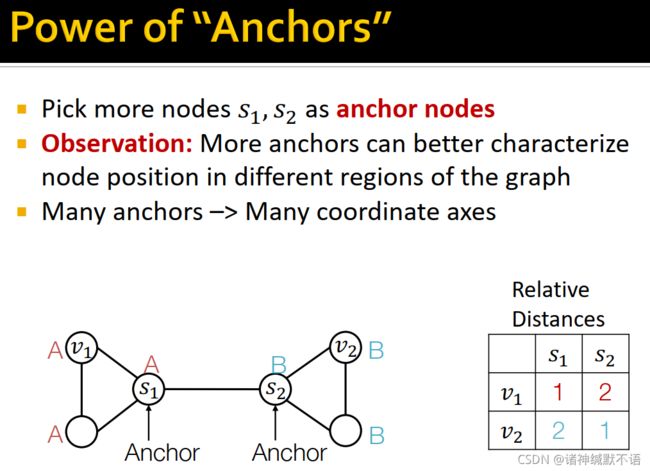
如图所示随机选取 s 1 , s 2 s_1,s_2 s1,s2 作为anchor nodes,用相对它们的距离来表示节点。这样就可以更好地描述图中不同区域的节点位置。更多anchors相当于更多的坐标轴。
-
anchor-sets
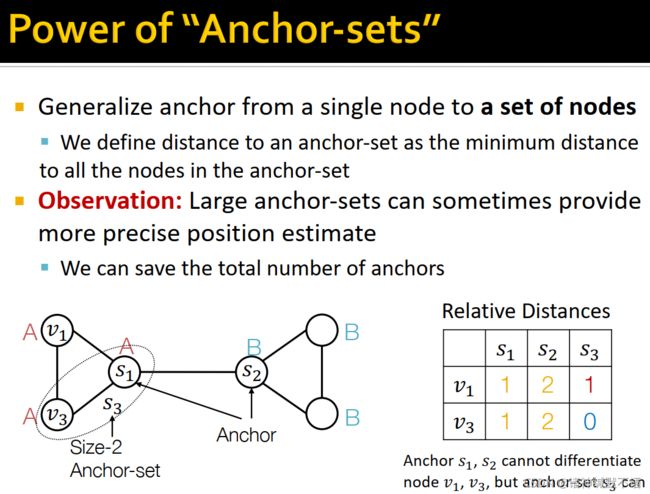
将anchor从一个节点泛化到一堆节点,定义某节点到一个anchor-set的距离是该节点距anchor-set中任一节点的最短距离(即到最短距离最短的节点的最短距离)。如图所示, s 3 s_3 s3 这个大小为2的anchor-set可以区分 s 1 s_1 s1 和 s 2 s_2 s2 这两个anchor区分不了的 v 1 v_1 v1 和 v 3 v_3 v3 节点。
有时大的anchor-set能提供更精确的位置估计。5 而且这种方法还能保持anchor总数较小,要不然计算代价太高。
-
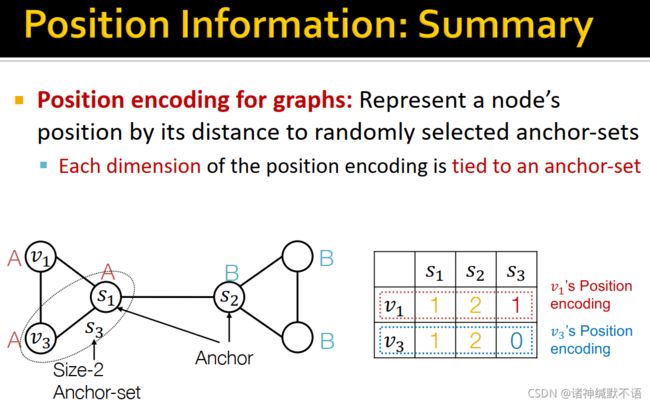
总结:节点的位置信息可以通过到随机选取anchor-sets的距离来编码,每一维对应一个anchor-set。
如图所示,每个节点都有了一个position encoding(图中的一行)。
具体在实践中,可以对anchor-set中的节点数指数级增长、同节点数的anchor-set数量指数级减小,如设置n个1个节点的anchor-set、n/2个2个节点的anchor-set……
-
如何使用position information(即上图中这个position encoding)
- 简单方法:直接把position encoding当作增强的节点特征来用。这样做的实践效果很好。
这样做的问题在于,因为position encoding的每一维对应一个随机anchor,所以position encoding本身可以被随机打乱而不影响其实际意义,但在普通神经网络中如果打乱输入维度,输出肯定会发生变化。
我对这个问题的理解就是:它是permutation invariant的,但是普通神经网络不是。这个问题本来就是GNN比欧式数据难的原因之一,结果GNN里面又出了这个问题真是微妙啊。 - 严谨方法:设计一个能保持position encoding的permutation invariant性质的特殊神经网络。
由于打乱输入特征维度只会打乱输出维度,因此具体维的数据不用改变。
然后就此处省略一万字让去看论文了。反正我还没看,以后有缘在看。如果读者您看懂了可以告诉我!


- 简单方法:直接把position encoding当作增强的节点特征来用。这样做的实践效果很好。
4. Identity-aware Graph Neural Networks2
- GNN还有更多的失败案例:除了上述的position-aware tasks之外,GNN在structure-aware tasks上也是不完美的。以下展示节点、边、图三种层面上的GNN在structure-aware tasks上的失败案例,都是结构不同但计算图相同的情况:

- 节点级别的失败案例:处在节点数不同的环上
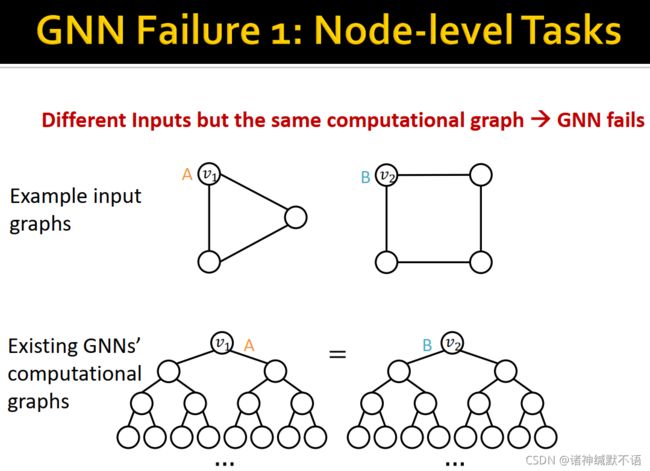
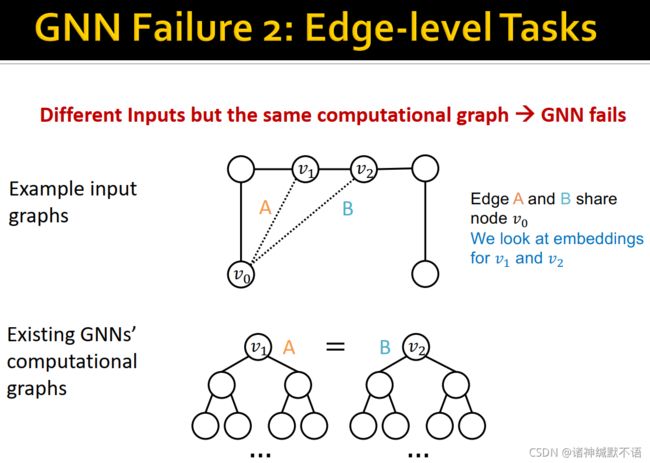
- 边级别的失败案例:如图中的边A和B,由于 v 1 v_1 v1 和 v 2 v_2 v2 计算图相同,因此A和B的嵌入也会相同:
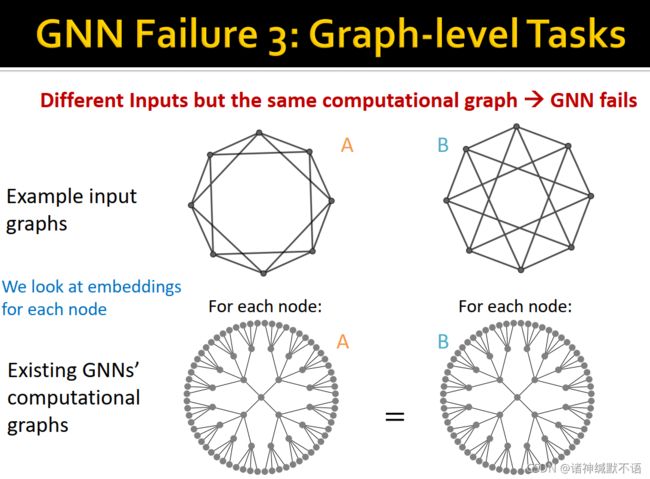
- 图级别的失败案例:如图所示,每个图有8个节点,每个节点与另外的四个节点相连,左图与相邻节点和隔一个节点的节点相连,右图与相邻节点和隔两个节点的节点相连。这两个图是不同构的,但是它们的每个节点的嵌入都相同:WL test无法区分它们,因此GNN也无法区分它们。
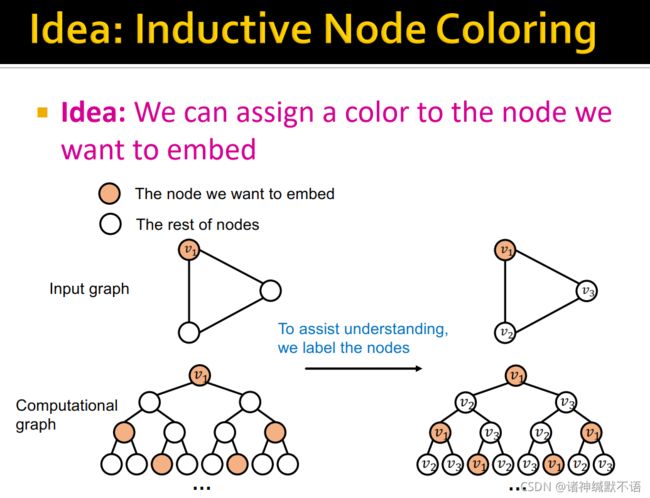
- idea: inductive node coloring6
核心思想:对我们想要嵌入的节点分配一个颜色(作为augmented identity),如图所示:
这个coloring是inductive的,与node ordering或identities7无关。如图所示,打乱 v 2 v_2 v2 和 v 3 v_3 v3 的顺序之后,计算图不变:
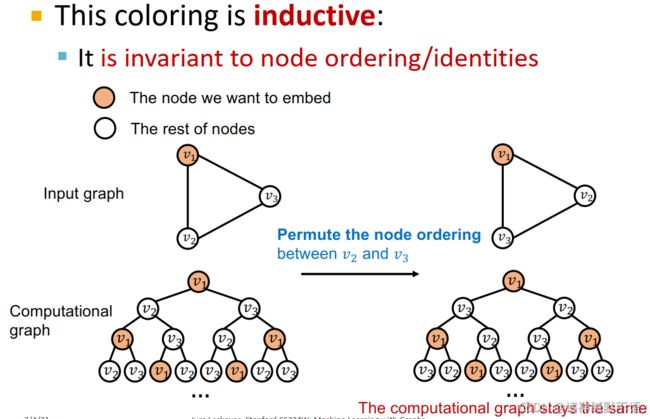
但其实这跟它本身的inductive有什么关系,我也没搞懂。 - inductive node coloring在各个级别上,都能帮助对应的图数据的计算图变得可区分。
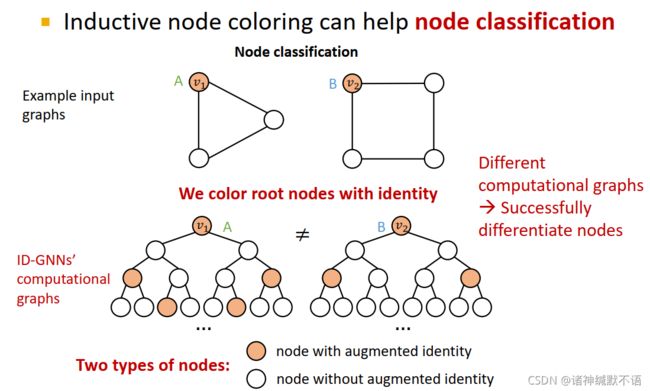
- node level
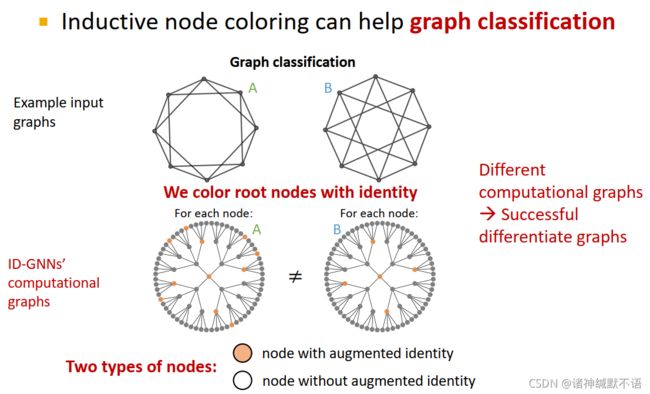
- graph level
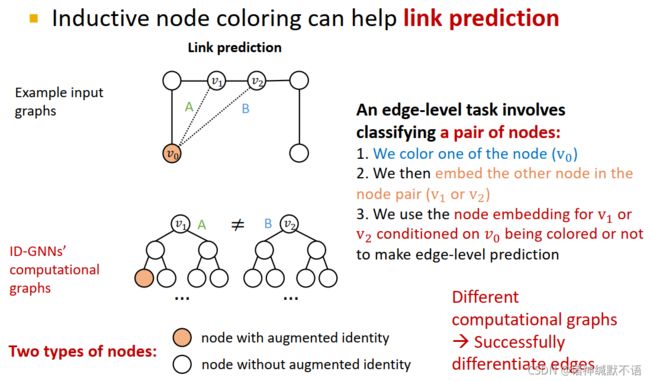
- edge level:需要嵌入两个节点,我们选择其中一个节点进行上色
- node level
- 那么我们应该如何在GNN中应用node coloring呢?这样就提出了ID-GNN (Identity-aware GNN)
整体思路:像异质图中使用的heterogenous message passing那样。传统GNN在每一层上对所有节点应用相同的message/aggregation操作,而heterogenous message passing是对不同的节点应用不同的message passing操作,ID-GNN就是在不同coloring的节点上应用不同的message/aggregation操作。
RGCN相关知识可参考我之前写过的笔记cs224w(图机器学习)2021冬季课程学习笔记12 Knowledge Graph Embeddings_诸神缄默不语的博客-CSDN博客。
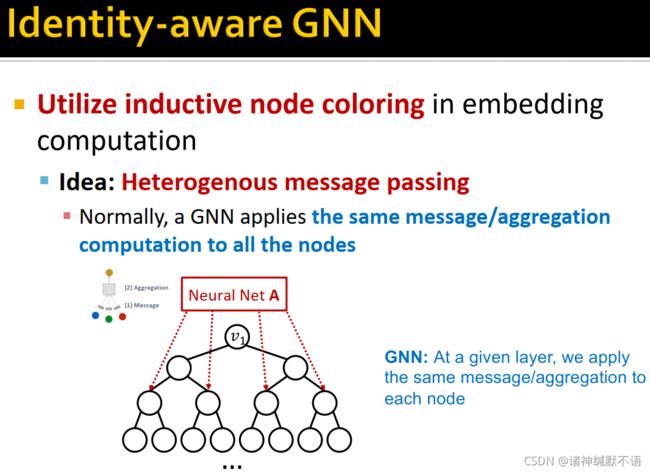
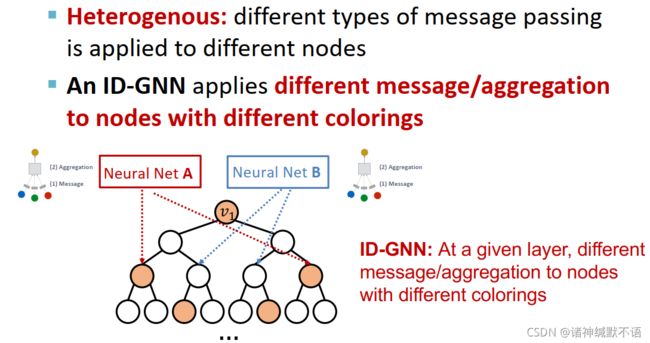
heterogenous massage passing可以通过在嵌入计算过程中应用不同的神经网络,使这种计算图结构相同、node coloring不同的节点得到不同的嵌入。
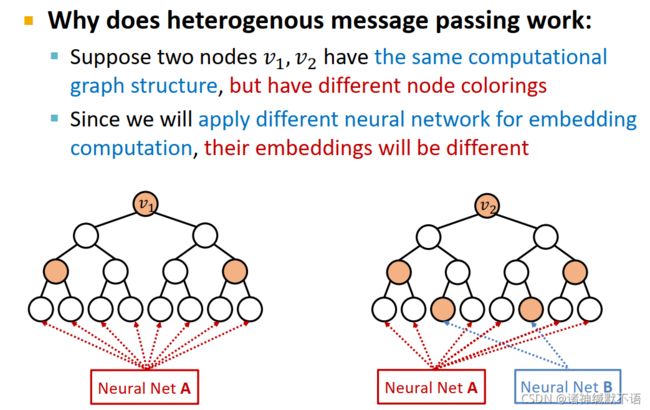
- GNN vs ID-GNN
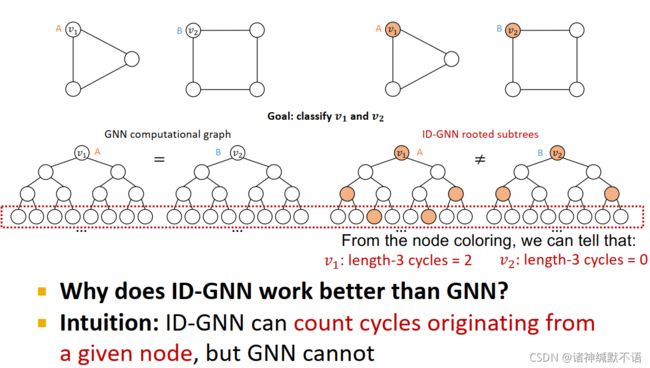
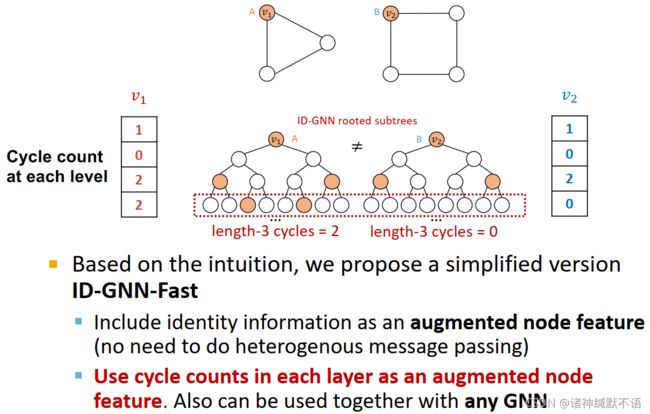
ID-GNN可以计算一个节点所属环的节点数,而GNN不能。
如图所示,根据计算图中与根节点同色的节点所在层数,可以数出这个节点数。但这里我不理解的是这个cycle指的是什么,直接看来就是这一层与根节点同色的节点数,也可以明白是这个计算树绕回去的次数。用这个应该可以数节点所属环的节点数。但是这个也不能说是圈数?就我觉得这玩意有点奇怪,我觉得可能需要看原论文才能更深入了解这东西?
- simplified version: ID-GNN-Fast
根据上一条的直觉,我们可以设计一个简化版本ID-GNN-Fast:将identity information作为augmented node feature(这样就不用进行heterogenous message passing操作了)(我不知道heterogenous message passing是不是代价比较大啊,看起来既然需要这么做,那应该就是有这个原因吧)
我们就用每一层的cycle counts作为augmented node feature,这样就可以应用于任意GNN了。
- Identity-aware GNN
ID-GNN是一个对GNN框架通用的强大扩展,可以应用在任何message passing GNNs上(如GCN,GraphSAGE,GIN等),在节点/边/图级别的任务上都给出了一致的效果提升。
ID-GNN比别的GNN表现力更好,是第一个比1-WL test8 更有表现力的message passing GNN。
我们可以通过流行的GNN工具包(如PyG,DGL等)来应用ID-GNN。

5. Robustness of Graph Neural Networks
- 近年来,深度学习在各领域都体现出了令人印象深刻的表现效果,如在计算机视觉领域,深度卷积网络在ImageNet(图像分类任务)上达到了人类级别的效果。那么,这些模型可以应用于实践了吗?

- 对抗样本
深度卷积网络对对抗攻击很脆弱,如图所示,只需要几乎肉眼无法察觉的噪音扰动,就会对预测结果产生巨大的改变。在自然语言处理和音频处理领域也报道过类似的对抗样本。

图中论文:
熊猫配图的来源:Explaining and Harnessing Adversarial Examples
[Jia & Liang et al. EMNLP 2017] Adversarial Examples for Evaluating Reading Comprehension Systems
[Carlini et al. 2018] Audio Adversarial Examples: Targeted Attacks on Speech-to-Text - 对抗样本的启示:
由于对抗样本的存在,深度学习模型部署到现实世界就不够可靠,对抗者可能会积极积极攻击深度学习模型,模型表现可能会比我们所期望的差很多。
深度学习往往不够鲁棒,事实上,使深度学习模型对对抗样本鲁棒仍然是个活跃的研究领域。

- GNNs的鲁棒性9
本节lecture将介绍GNN是否对对抗样本鲁棒。本节课介绍的基础是GNNs的广泛应用关乎于公开平台和经济利益,包括推荐系统、社交网络、搜索引擎等,对抗者有动机来操纵输入图和攻击GNN预测结果。

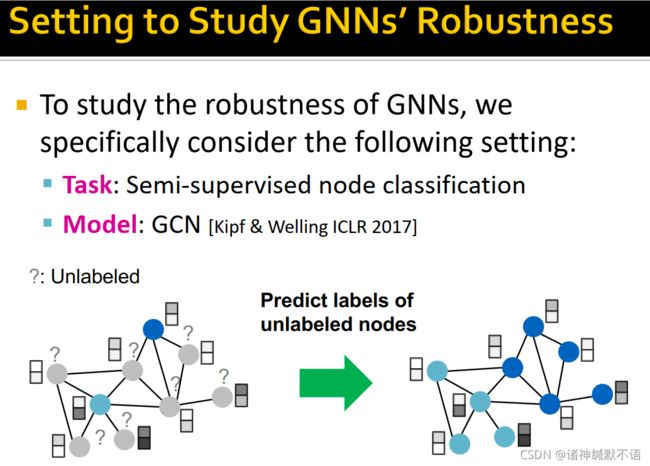
- 研究GNN鲁棒性的基础设置
任务:半监督学习节点分类任务
模型:GCN10
- 问题研究路径:
- 描述几种现实世界中的adversarial attack possibilities11。
- 我们再研究一下我们要攻击的GCN模型(了解对象)。
- 我们将攻击问题用数学方法构建为优化问题。
- 通过实验来检验GCN的预测结果对对抗攻击有多脆弱。

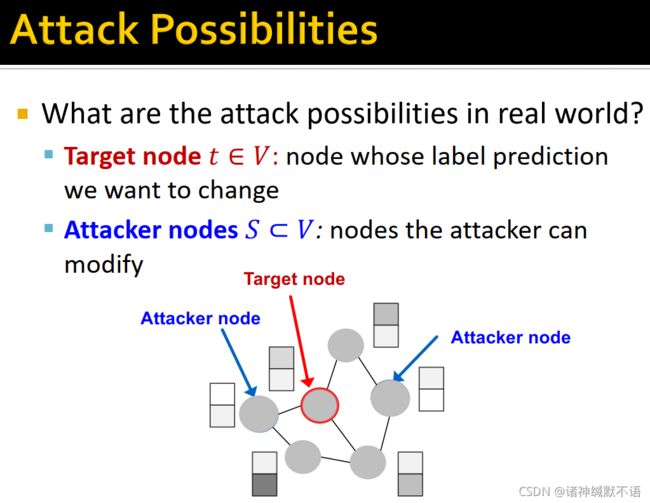
- attack possibilities
这个应该是指对对抗攻击任务类型的介绍。
target nodes t ∈ V t\in V t∈V:我们想要改变其标签预测结果。
attacker nodes S ⊂ V S\subset V S⊂V:攻击者可以改变的节点。
如图所示:
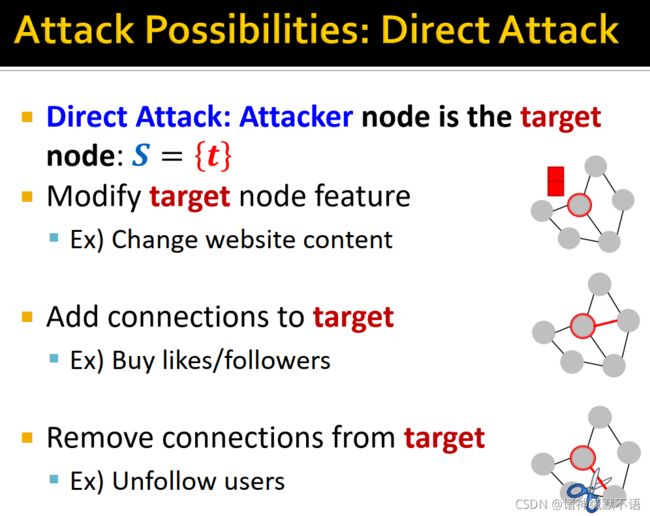
- direct attack
attacker nodes就是traget node: S = { t } S=\{t\} S={t},其分类如图所示:
1. 调整target node特征:如改变网站内容
2. 对target node增加边(连接):如买粉/买赞
3. 对target node删除边(连接):如对某些用户取消关注
- indirect attack
attacker nodes不是target node: t ∉ S t\not\in S t∈S,其分类如图所示:
1. 调整attacker node特征:如hijack12 target nodes的好友。
2. 对attackers增加边(连接):如创建新链接,如link farm13。
3. 删除attackers的边(连接):如删除不想要的链接。
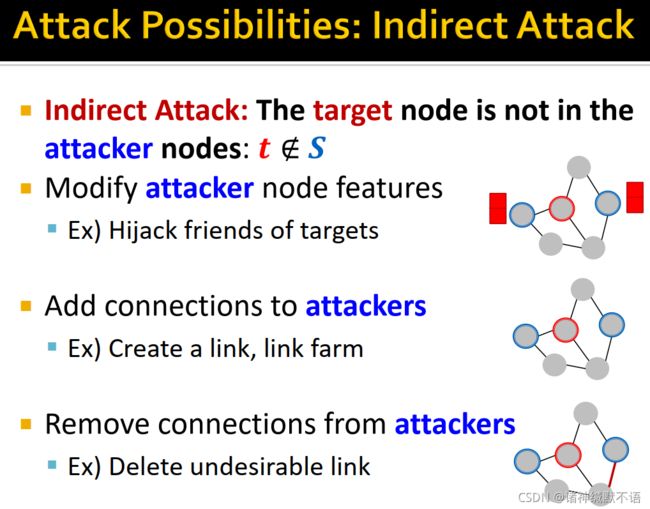
- direct attack
- 将对抗攻击构建为优化问题:
attacker的目标:最大化target node标签预测结果的改变程度
subject to 图上的改变很小(如果对图的改变过大,将很容易被检测到。成功的攻击应该在对图的改变“小到无法察觉”时改变target的预测结果)
如图所示,在图上做很小的改变(改变两个节点的特征),学习GCN模型后,预测标签就得到了改变:
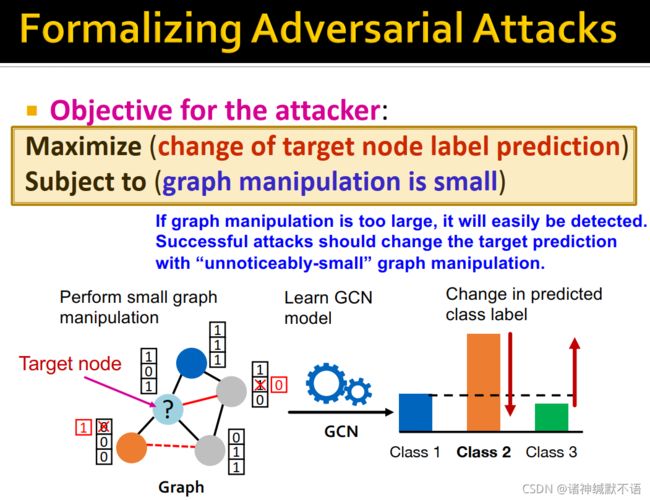
- 数学形式:
原图: A A A 邻接矩阵, X X X 特征矩阵
操作后的图(已添加噪音): A ′ A' A′ 邻接矩阵, X ′ X' X′ 特征矩阵
假设: ( A ′ , X ′ ) ≈ ( A , X ) (A',X')\approx(A,X) (A′,X′)≈(A,X)(对图的操作足够小,以至于无法被察觉,如保留基本的图统计指标(如度数分布)和特征统计指标等)
对图的操作可以是direct(改变target nodes的特征或连接)或indirect的。

target node: v ∈ V v\in V v∈V
GCN学习原图: θ ∗ = arg min θ L t r a i n ( θ ; A , X ) \theta^*=\argmin_\theta\mathcal{L}_{train}(\theta;A,X) θ∗=argminθLtrain(θ;A,X)
GCN对target node的原始预测结果: c v ∗ = arg max c f θ ∗ ( A , X ) v , c c_v^*=\argmax_cf_{\theta^*}(A,X)_{v,c} cv∗=argmaxcfθ∗(A,X)v,c(节点 v v v 预测概率最高的类)

GCN学习被修改后的图: θ ∗ ′ = arg min θ L t r a i n ( θ ; A ′ , X ′ ) \theta^{*'}=\argmin_\theta\mathcal{L}_{train}(\theta;A',X') θ∗′=argminθLtrain(θ;A′,X′)
注意这里的 θ \theta θ 也可以不变,即指模型已经部署好了,参数不变
GCN对target node的预测结果: c v ∗ ′ = arg max c f θ ∗ ′ ( A ′ , X ′ ) v , c c_v^{*'}=\argmax_cf_{\theta^{*'}}(A',X')_{v,c} cv∗′=argmaxcfθ∗′(A′,X′)v,c
我们希望这个预测结果在图修改后产生变化: c v ∗ ′ ≠ c v ∗ c_v^{*'}\neq c_v^* cv∗′=cv∗

target node v v v 预测结果的改变量: Δ ( v ′ ; A ′ , X ′ ) = log f θ ∗ ′ ( A ′ , X ′ ) v , c v ∗ ′ − log f θ ∗ ′ ( A ′ , X ′ ) v , c v ∗ \Delta(v';A',X')=\log{f_{\theta^{*'}}(A',X')_{v,c_v^{*'}}}-\log{f_{\theta^{*'}}(A',X')_{v,c_v^*}} Δ(v′;A′,X′)=logfθ∗′(A′,X′)v,cv∗′−logfθ∗′(A′,X′)v,cv∗
即新预测类被预测的概率取对数(我们想要提升的项)减原预测类被预测的概率取对数(我们想要减少的项)。

最终的优化目标公式就是:
arg max A ′ , X ′ Δ ( v ′ ; A ′ , X ′ ) subject to ( A ′ , X ′ ) ≈ ( A , X ) \argmax_{A',X'}\Delta(v';A',X') \\ \text{subject to }(A',X')\approx(A,X) A′,X′argmaxΔ(v′;A′,X′)subject to (A′,X′)≈(A,X)
优化目标中存在的挑战:
1. 邻接矩阵 A ′ A' A′ 是一个离散对象,无法使用基于梯度的优化方法。
2. 对每个经调整后的图 A ′ A' A′ 和 X ′ X' X′,GCN需要重新训练,这样做的计算代价很高。
θ ∗ ′ = arg min θ L t r a i n ( θ ; A ′ , X ′ ) \theta^{*'}=\argmin_\theta\mathcal{L}_{train}(\theta;A',X') θ∗′=argminθLtrain(θ;A′,X′)
[Zügner et al. KDD2018]9 中提出了一些使优化过程tractable的近似技巧。

- 实验:对抗攻击
在文献引用网络(有2800个节点,8000条边)上用GCN模型运行半监督节点分类任务。在原图上重复运行5次,对target node属于各类的预测概率如图所示:

证明GCN模型可以很好地使原图上的target node被分到正确的类中。
在连接到target node上的5个边被修改(direct adversarial attack)后,GCN的预测结果如图所示:
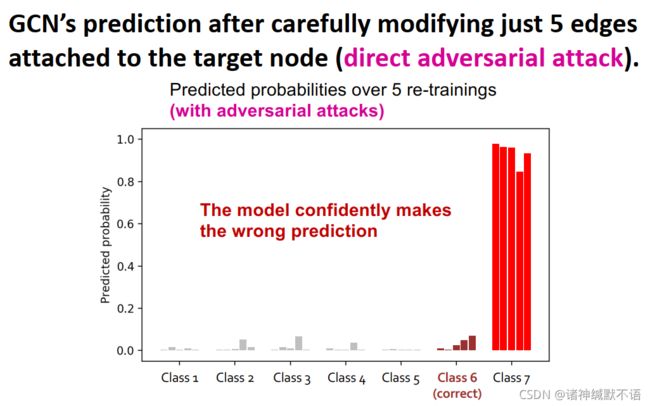
可以看出其结果被改变了。 - 实验:attack comparison
经实验发现:
adversarial direct attack是最强的攻击,可以有效降低GCN的表现效果(与无攻击相比)。
random attack比对抗攻击弱很多。
indirect attack比direct attack更难。
实验结果如图所示,每个点代表一次攻击实验,classfication越低证明误分类越严重(即攻击效果越好):
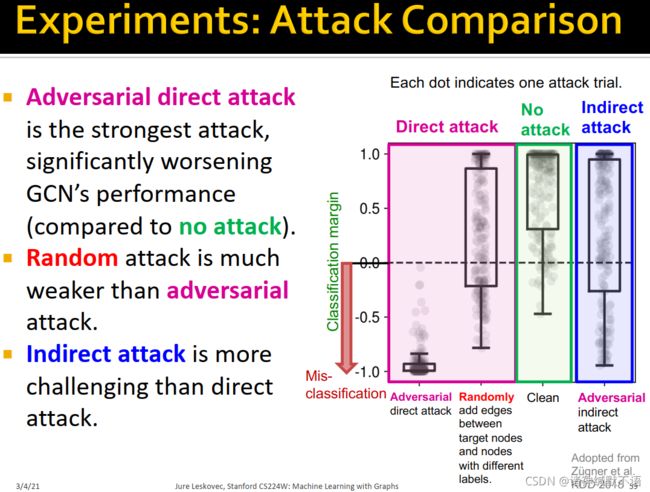
- 总结
- 我们研究了应用于半监督节点分类任务的GCN模型的adversarial robustness。
- 我们考虑了对图结构数据的不同attack possibilities。
- 我们用数学方法将对抗攻击构建为优化问题。
- 我们实证地证明了GCN的预测效果可能会因对抗攻击而被严重损害。
- GCN对对抗攻击不鲁棒,但对indirect attacks和随机噪音还是有一些鲁棒性的。

J. You, R. Ying, J. Leskovec. Postion-aware Graph Neural Networks, ICML 2019 ↩︎ ↩︎ ↩︎
J. You, J. Gomes-Selman, R. Ying, J. Leskovec. Identity-aware Graph Neural Networks, AAAI 2021
Code
Webpage
(上面这两个链接是从尤佳轩官网上复制下来的) ↩︎ ↩︎ ↩︎可参考我之前写的笔记 cs224w(图机器学习)2021冬季课程学习笔记9 Graph Neural Networks 2: Design Space_诸神缄默不语的博客-CSDN博客 和 cs224w(图机器学习)2021冬季课程学习笔记10 Applications of Graph Neural Networks_诸神缄默不语的博客-CSDN博客 ↩︎
可参考我之前写的笔记 cs224w(图机器学习)2021冬季课程学习笔记11 Theory of Graph Neural Networks_诸神缄默不语的博客-CSDN博客 ↩︎ ↩︎
话虽如此我并没有看出来说为什么,虽然图上这个 s 3 s_3 s3 是比 s 1 s_1 s1 更能区分出 v 1 v_1 v1 和 v 3 v_3 v3 来,但是仅凭这个吗?这么直觉是不是有点流氓了?有没有什么严谨些的证明啊? ↩︎
color refinement和WL test相关的介绍可见我之前写的博文:cs224w(图机器学习)2021冬季课程学习笔记2: Traditional Methods for ML on Graphs_诸神缄默不语的博客-CSDN博客 和 cs224w(图机器学习)2021冬季课程学习笔记11 Theory of Graph Neural Networks_诸神缄默不语的博客-CSDN博客 ↩︎
node identity是个什么东西?我谷歌了以后发现好像是个编程名词啊?那搁这儿应该是啥意思啊? ↩︎
我谷歌了一下,1-WL test好像就是WL test。 ↩︎
Zügner et al. Adversarial Attacks on Neural Networks for Graph Data, KDD 2018 ↩︎ ↩︎
Kipf, T., & Welling, M. (2017). Semi-Supervised Classification with Graph Convolutional Networks. ArXiv, abs/1609.02907. ↩︎
我谷歌了attack possibility这个名词,但是感觉好像不是什么专有名词。看底下意思应该是指对对抗攻击任务类型的意思?
感觉这个不重要,就模糊处理吧。 ↩︎hijack 劫持(交通工具,尤指飞机); 操纵(会议等,以推销自己的意图);
其实我是没搞懂这个词搁这里是什么意思……但是总之就是操纵、修改的意思吧,影响不大。 ↩︎link farm一个SEO领域的概念:百度百科
Link Farm,中文可翻译为链接工厂,链接养殖场,属于SEO垃圾和搜索引擎优化作弊。
所谓Link Farm,就是通过创建一个堆砌大量链接而没有实质内容的网页,这些链接彼此互链,或指向特定网站,以增加被链接网站外部链接数量,由此欺骗搜索引擎蜘蛛程序,为目标网站获得更高的链接广度,最终提升搜索引擎排名。目前搜索引擎对Link Farm的识别能力很强,一经发现网站被链接到Link Farm,将有被永久删除的危险。 ↩︎