Numpy库基础知识与常用方法
文章目录
-
- 开胃小菜 np.tile(A, reps)、np.c_[nd1, nd2]
- 1、数据创建
-
- 1)数组属性
- 2)文件IO操作
-
- 保存数据
- 读取数据
- 读写csv、txt⽂件
- 2、数组运算
-
- 1)四则运算:加 减 乘 除
- 2)逻辑运算
- 3、视图与复制
-
- 1)完全没有复制
- 2)查看或者叫浅拷贝
- 3)深拷贝
- 4、索引、切片和迭代
-
- 1)什么是可迭代对象
- 2)索引与切片 array[start : end : step]
- 3)花式索引和索引技巧
- 4)boolean值索引
- 5、形状操作
-
- 1)数组变形
- 2)数组转置
- 3)数据堆叠合并
- 4)split数组拆分
- 6、广播机制
-
- 1)一维数组广播
- 2)二维数组广播
- 3)三维数组广播
- 7、通用函数
-
- 1)元素级数字级别的方法
- 2)三元运算,where函数 np.where(cond, X, Y)
- 3)排序方法
- 4)集合运算函数
- 数学和统计函数
- 8、线性代数计算
-
- 向量计算
- 矩阵运算
- 9、实战-用NumPy分析鸢尾花花萼属性各项指标
NumPy(Numerical Python)是Python的⼀种开源的数值计算扩展。提供多维数组对象,各种派⽣对象(如掩码数组和矩阵),这种⼯具可⽤来存储和处理⼤型矩阵,⽐Python⾃身的嵌套列表(nested
list structure)结构要⾼效的多(该结构也可以⽤来表示矩阵(matrix)),⽀持⼤量的维度数组与矩阵运算,此外也针对数组运算提供⼤量的数学函数库,包括数学、逻辑、形状操作、排序、选择、输⼊输出、离散傅⽴叶变换、基本线性代数,基本统计运算和随机模拟等等。
开胃小菜 np.tile(A, reps)、np.c_[nd1, nd2]
np.tile(A, reps),将A数组,按照轴方向,复制多少次。
- A : array_like The input array.
- reps : array_like The number of repetitions of
Aalong each axis.
默认在左右方向复制,(left, right)
a = np.array([0, 1, 2])
display(a, 2)
np.tile(a, (2,2))

- np.r_(nd1, nd2) 是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等。
np.r_[a,b]

- np.c_(nd1, nd2) 是按行连接两个矩阵,就是把两矩阵上下相加,要求列数相等。
np.c_[a,b]
![]()
1、数据创建
创建数组(ndarray)的最简单的⽅法就是使⽤array函数,将Python下的list转换为ndarray,或者直接手动输入,一个中括号表示某一个维度下,一条数据。
import numpy as np
a = [i for i in range(6)]
a1 = np.array(a)
a2 = np.array([[1,2], [2,3]])
display(a1, a2)

- np.ones(shape),生成全1的数字,shape表示形状,单个数字表示一维度,多个数字表示多维度。
- np.zeros(shape),生成全0的数字,shape表示形状,单个数字表示一维度,多个数字表示多维度。
- np.full(shape, fill_value),形状和填充值,Return a new array of given shape and type, filled with
fill_value. - ndarray.reshape(shape) 改变数组形状,形状数相乘必须得等于总元素个数。
one = np.ones((2))
one1 = np.ones((2,2))
full = np.full(3,[1,2,3])
display(one, one1)
# 数组类型转换
display(one.reshape(2, 1), full)

1)数组属性
- ndarray.dtype数组内部元素类型
- ndarray.ndim 数组的轴数、维度
- ndarray.shape 数组尺⼨形状
- ndarray.size 数组元素的总数
- ndarray.itemsize 数组中每个元素的⼤⼩(以字节为单位)
arr = np.random.randint(0,100,size = (3,4,5))
arr.dtype
# 输出 dtype('int64')
arr = np.random.randint(0,100,size = (3,4,5))
arr.ndim
# 输出 3
arr = np.random.randint(0,100,size = (3,4,5))
arr.shape
# 输出 (3,4,5)
arr = np.random.randint(0,100,size = (3,4,5))
arr.dtype
# 输出 dtype('int64')
arr = np.random.randint(0,100,size = (3,4,5))
arr.itemsize
#输出是 8 ,因为数据类型是int64,64位,⼀个字节是8位,所以64/8 = 8
2)文件IO操作
保存数据
- save⽅法保存ndarray到⼀个npy⽂件,也可以使⽤savez将多个array保存到⼀个.npz⽂件中
x = np.random.randn(5)
y = np.arange(0,10,1)
# save⽅法可以存⼀个ndarray
np.save("x_arr",x)
# 如果要存多个数组,要是⽤savez⽅法,保存时以key-value形式保存,key任意(xarr、yarr)
np.savez("some_array.npz",xarr = x,yarr=y)
读取数据
- load⽅法来读取存储的数组,如果是.npz⽂件的话,读取之后相当于形成了⼀个key-value类型的变量,
通过保存时定义的key来获取相应的array
np.load('x_arr.npy') # 直接加载
# 通过key获取保存的数组数据
np.load('some_array.npz')['yarr']
读写csv、txt⽂件
arr = np.random.randint(0,10,size = (3,4))
#储存数组到txt⽂件
np.savetxt("arr.csv",arr,delimiter=',') # ⽂件后缀是txt也是⼀样的
#读取txt⽂件,delimiter为分隔符,dtype为数据类型
np.loadtxt("arr.csv",delimiter=',',dtype=np.int32)
2、数组运算
生成指定维度的随机数据,方便后面模拟计算,这里加上了随机种子np.random.seed(),因为生成的随机数据是伪随机,所有利用seed可以记住该次生成的数据,后续可复原实验。
np.random.seed(1)
nd1 = np.random.randint(0,10,size=5)
nd2 = np.random.randint(0,10,size=5)
display(nd1, nd2)

1)四则运算:加 减 乘 除
- 当数组形状完全对应时,数组的四则运算就是对应位置元素一一运算。记住一点,在numpy中分母可以为0,结果是inf,表示无穷大,类型是浮点型。没有 a /= a的写法
- 累加 +=,这类运算是在一个变量的前提下,对该变量进行一列操作,它就是var = var + number 的一个缩写,功能完全一样。
- 累减 -+
- 累乘 *=
- 注意:没有累除 /=
print('加法:', nd1 + nd2,
'\n减法:', nd1 - nd2,
'\n乘法:', nd1 * nd2,
'\n除法:', np.round(nd1/nd2,2),
'\n分母带有0:',np.round(nd2/nd1,2))

2)逻辑运算
nd1 > nd2
print(nd1 == nd2)
nd1 > nd2

3、视图与复制
在操作数组时,有时会将其数据复制到新数组中,有时不复制。对于初学者来说,这通常会引起混乱。有以下三种情况
1)完全没有复制
a = np.random.randint(0,100,size = (4,5))
b = a
b[0,0] = 1024 # 命运共同体
display(id(a), id(b))
a is b # 返回True a和b是两个不同名字对应同⼀个内存对象

2)查看或者叫浅拷贝
不同的数组对象可以共享相同的数据。该view⽅法创建⼀个查看相同数据的新数组对象,无论在哪个对象上操作,都会将数据改变。
a = np.random.randint(0,100,size = (2,2))
b = a.view() # 使⽤a中的数据创建⼀个新数组对象
print(a is b, id(a), id(b))
# 返回False a和b是两个不同名字对应同⼀个内存对象
b.base is a # 返回True,b视图的根数据和a⼀样
b.flags.owndata # 返回False b中的数据不是其⾃⼰的
a.flags.owndata # 返回True a中的数据是其⾃⼰的
b[0,0] = 1024 # a和b的数据都发⽣改变
display(a,b)

3)深拷贝
深拷贝后,拷贝对象与原对象无论做什么操作,二者都不会有任何关联,因为都拥有自己的数据,相当于内存多占一倍。
a = np.random.randint(0,100,size = (2,2))
b = a.copy()
b is a # 返回False
b.base is a # 返回False
b.flags.owndata # 返回True
a.flags.owndata # 返回True
b[0,0] = 1024 # b改变,a不变,分道扬镳
display(a,b)

4、索引、切片和迭代
1)什么是可迭代对象
Python中可迭代对象(Iterable)并不是指某种具体的数据类型,它是指存储了元素的一个容器对象,且容器中的元素可以通过 iter( )方法或 getitem( )方法访问。
from collections import Iterable
print(isinstance(range(100),Iterable))
print(isinstance(list(range(100)), Iterable))
isinstance('Say YOLO Again.', Iterable)
2)索引与切片 array[start : end : step]
numpy中数组切⽚是原始数组的视图,这意味着数据不会被复制,视图上任何数据的修改都会反映到原数组上。
start: 切片开始的位置,默认0
end: 切片结束的位置,默认结尾
step:步长,默认为1, 可以为负数,表示倒叙切片\n
# 正序切片
a = np.arange(10)
display(a)
print(a[:]) # 参数默认
print(a[1:3]) # [start, end)
print(a[::3]) # 三个取数
# 逆序切片
print(a[-9:-3]) # -1代表最后一个元素的index
print(a[-2:-8:-2])
print(a[::-1]) # 每隔一个逆序取数
print(a[::-2]) # 每隔两个逆序取数
[1 2 3 4 5 6]
[8 6 4]
[9 8 7 6 5 4 3 2 1 0]
[9 7 5 3 1]
对于⼆维数组或者⾼维数组,我们可以按照之前的知识来索引,当然也可以传⼊⼀个以逗号隔开的索引列表来选区单个或多个元素
nd1[0,0] # 表示第一行,第一列对应的元素
nd1[0:2,0] # 表示第一和第二行与第一列对应的元素
3)花式索引和索引技巧
整数数组进⾏索引即花式索引,其和切⽚不⼀样,它总是将数据复制到新数组中
a = np.arange(20)
b = a[3:7] # 切片时,b接收返回的数据,不是深拷贝
display(b)
b[0] = 555
b, a
array([3, 4, 5, 6])
(array([555, 4, 5, 6]),
array([ 0, 1, 2, 555, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19]))
a = np.arange(20)
# 花式索引返回的深拷贝的数据
b = a[np.array([3,4,5,6])] # 花式索引:就是在索引是可迭代对象时,得到的数据是深拷贝
display(a,b)
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19])
array([3, 4, 5, 6])
b[0] = 1024
display(a,b)
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19])
array([1024, 4, 5, 6])
a = np.random.randint(0,150,size=(50,3)) # 高中三门主科目的分数
cond = a >= 110 # 逻辑运算
# 根据条件,筛选数据,只要大于120,返回,一门大于120,就会返回这一门
print(a[cond])
b = a[cond]
# 找出三科都大于120的颁发奖状
a[cond.all(axis=1)] # 表示跨列查找
[143 133 134 139 135 116 136 149 145 121 136 138 136 120 121 141 148 146
110 136 137 135 121 118 141 145 124 123 133 112 149 143 131 125 111 110
114 116 142 125 116]
array([[139, 135, 116],
[118, 141, 145]])
4)boolean值索引
names =
np.array(['softpo','Brandon','Will','Michael','Will','Ella','Daniel','softpo','
Will','Brandon'])
cond1 = names == 'Will'
cond1
# 输出array([False, False, True, False, True, False, False, False, True,
False])
names[cond1] # array(['Will', 'Will', 'Will'], dtype='
arr = np.random.randint(0,100,size = (10,8)) # 0~100随机数
cond2 = arr > 90
# 找到所有⼤于90的索引,返回boolean类型的数组 shape(10,8),⼤于返回True,否则False
arr[cond2] # 返回数据全部是⼤于90的
5、形状操作
1)数组变形
a = np.random.randint(0,10,size = (3,5))
print(a)
a.reshape(5,3) # 只是改变形状,不是就地修改
[[3 7 6 6 8]
[2 3 8 1 7]
[1 3 8 3 0]]
array([[3, 7, 6],
[6, 8, 2],
[3, 8, 1],
[7, 1, 3],
[8, 3, 0]])
a.reshape(-1,3) # -1表示数据,3自动计算-1 = 5
# 形状有负数的,优先满足不是负数的形状,然后根据元素的个数确定负数的形状
array([[3, 7, 6],
[6, 8, 2],
[3, 8, 1],
[7, 1, 3],
[8, 3, 0]])
2)数组转置
a.T
array([[3, 2, 1],
[7, 3, 3],
[6, 8, 8],
[6, 1, 3],
[8, 7, 0]])
np.transpose(a, (1,0))
array([[3, 2, 1],
[7, 3, 3],
[6, 8, 8],
[6, 1, 3],
[8, 7, 0]])
b = np.random.randint(0,10,size = (3,5,7)) # shape = (0,1,2)
print(b.shape, '\n', b,'\n')
c = np.transpose(b, axes=(2,1,0))
print(c.size, c.shape)
(3, 5, 7)
[[[3 5 1 9 3 3 8]
[0 9 9 6 8 2 5]
[0 1 1 0 3 9 3]
[3 9 5 7 4 0 0]
[6 0 8 1 9 7 5]]
[[7 2 6 6 5 6 7]
[9 4 1 5 9 4 1]
[0 2 1 7 9 4 5]
[3 5 1 5 5 0 8]
[9 4 7 4 4 1 9]]
[[5 8 2 0 7 9 1]
[2 7 0 9 0 5 6]
[3 8 1 3 2 7 5]
[1 1 0 8 6 8 4]
[1 5 8 6 3 2 5]]]
105 (7, 5, 3)
3)数据堆叠合并
- np.vstack(nd1,nd2) 上下方向合并,要求形状一致
- np.hstack(nd1,nd2) 左右方向合并,要求形状一致
- np.concatenate(nd1, nd2, axis) 可以左右合并也可以上下合并,通过axis来控制
nd1 = np.random.randint(0,10,size = (2,3))
nd2 = np.random.randint(0,10,size = (2,3))
display(nd1,nd2)
array([[5, 4, 5],
[5, 5, 4]])
array([[0, 4, 3],
[6, 8, 0]])
# 在行上堆叠, 也就是在竖直方向堆积
v1 = np.vstack([nd1, nd2])
v2 = np.concatenate([nd1, nd2], axis=0) # axis=0,在竖直方向堆叠,跨行操作
display(v1, v2)
# 在行上堆叠, 也就是在水平方向堆积
h1 = np.hstack([nd1,nd2])
h2 = np.concatenate([nd1, nd2], axis=1) # axis=1,在水平方向堆叠,跨列操作
h1, h2
array([[5, 4, 5],
[5, 5, 4],
[0, 4, 3],
[6, 8, 0]])
array([[5, 4, 5],
[5, 5, 4],
[0, 4, 3],
[6, 8, 0]])
(array([[5, 4, 5, 0, 4, 3],
[5, 5, 4, 6, 8, 0]]),
array([[5, 4, 5, 0, 4, 3],
[5, 5, 4, 6, 8, 0]]))
4)split数组拆分
display(v1)
c = np.split(v1, indices_or_sections=2)
# ary: 输入对象,
# indices_or_sections: 表示平均分成多少分
# axis=0/1 按照什么方向切分, 默认为0,表示在水平方向划线切分
print(c[1])
c
array([[5, 4, 5],
[5, 5, 4],
[0, 4, 3],
[6, 8, 0]])
[[0 4 3]
[6 8 0]]
[array([[5, 4, 5],
[5, 5, 4]]),
array([[0, 4, 3],
[6, 8, 0]])]
# 参数给列表,根据列表中的索引,进行切片
np.split(v1,indices_or_sections=[1,2,3]) # 0~1,1~2,2~3,3~
[array([[5, 4, 5]]),
array([[5, 5, 4]]),
array([[0, 4, 3]]),
array([[6, 8, 0]])]
6、广播机制
当数组与数组的形状不是完全一致,但又有一个维度的长度是相同的,这时候便会广播,类似简单填充其他存在的位置, 多维时会更严格一些。
1)一维数组广播
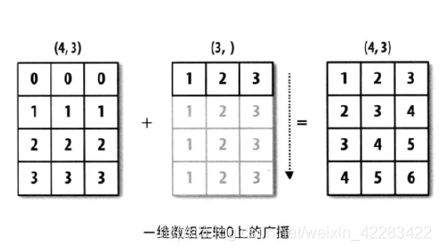
- 当数组形状不完全对应时,数组与标量运算会通过广播机制,把标量扩充成数组的形状,像rarray[1,2,3]+2=array[1,2,3]+array[2,2,2]
a = np.array([1,2,3])
print('等价于每个数字加3', a + 3)
![]()
2)二维数组广播

arr1 = np.sort(np.array([0,1]*3)).reshape(3,2)
arr2 = np.array([[1], [2], [3]])
arr3 = arr1 + arr2 # arr2 进⾏⼴播复制3份 shape(3,2)
display(arr1,arr2,arr3)

3)三维数组广播
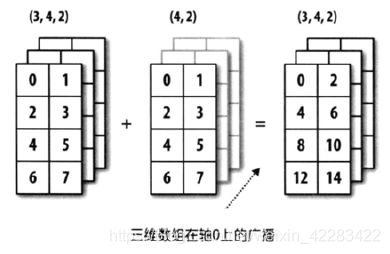
arr1 = np.array([0,1,2,3,4,5,6,7]*3).reshape(3,4,2) #shape(3,4,2)
arr2 = np.array([0,1,2,3,4,5,6,7]).reshape(4,2) #shape(4,2)
arr3 = arr1 + arr2 # arr2数组在0维上复制3份 shape(3,4,2)
arr3

总结一下广播原理,一个数组必须在某一个维度上与另一个数组对应维度的形状大小相同,否则无法广播。例如对于二维说,确定了一个维度的形状,你才能广播出另一个

7、通用函数
# abs、sqrt、square、exp、log、sin、cos、tan,maxinmum、minimum、
# all、any、inner、clip、round、trace、ceil、floor
1)元素级数字级别的方法
abs、sqrt、square、exp、log、sin、cos、tan,maxinmum、minimum、all、any、inner、clip、round、trace、ceil、floor
a = np.array([-1,-3,-5,1,5,8,9])
c = np.random.randint(-5,10,size = 7)
display(a,c)
array([-1, -3, -5, 1, 5, 8, 9])
array([-3, 3, 9, 9, 0, 9, 0])
np.abs(a) # 求绝对值
np.sqrt(b) # 开平方
np.square(b) # 平方
np.exp(3) # 自然底数e的多少次幂
np.log(20.085536) # 自然底数e对数求解
np.sin(np.pi/2) # 度sin正弦值
np.cos(0) # 余弦值
np.tan(np.pi/6) # 正切,30度正切值
# 给两个数组,从中选取大的,或者选取小的
np.maximum(a,c) # 从a和c中选取最大的值,二者取其一,最后形状不变
np.minimum(a,c) # 选取最小的值
array([-3, -3, -5, 1, 0, 8, 0])
np.any([True, False]) # 只要有一个T,返回T
np.all([True, False]) # 必须全部为T,才能返回T
True
nd1 = np.random.randint(0,100,10)
print(nd1)
np.clip(nd1,1,8) # 数据裁剪,将小于10变成1,将大于80的变成8
[ 6 2 17 49 36 34 31 56 20 34]
array([6, 2, 8, 8, 8, 8, 8, 8, 8, 8])
a = np.random.randint(0,10,size = (3,3))
print(a)
np.trace(a) # 对角线的和
[[9 9 9]
[1 8 1]
[8 1 7]]
24
2)三元运算,where函数 np.where(cond, X, Y)
满足条件,则X,否则Y
a = np.arange(6)
condition = a > 2
np.where(condition, 11, 99) # 这个是有返回值,所以会直接显示,因此不是就地修改
array([99, 99, 99, 11, 11, 11])
a
array([0, 1, 2, 3, 4, 5])
3)排序方法
np中还提供了排序⽅法,排序⽅法是就地排序,即直接改变原数组arr.sort()、np.sort()、arr.argsort()
import random
print('初始a:', a)
random.shuffle(a)
# 就地修改,没有返回值的
print('乱序a:', a)
array([0, 5, 4, 3, 1, 2])
np.sort(a) # 有返回值,不是就地修改
array([0, 1, 2, 3, 4, 5])
a # 值未变化
array([0, 5, 4, 3, 1, 2])
a.sort() # No return
a
4)集合运算函数
A = np.array([2,4,6,8])
B = np.array([3,4,5,6])
np.intersect1d(A,B) # 交集 array([4, 6])
np.union1d(A,B) # 并集 array([2, 3, 4, 5, 6, 8])
np.setdiff1d(A,B) #差集,A中有,B中没有 array([2, 8])
数学和统计函数
min、max、mean、median、sum、std、var、cumsum、cumprod、argmin、argmax、argwhere、cov、corrcoef
np.mean(a)
np.median(a)
np.std(a)
np.var(a)
np.corrcoef(a,a)
# 相关性系数,0-1(正相关) -1-0 (负相关)
# 0 表示,没有线性关系
np.cov(b)
# cov 协方差(属性之间进行计算),方差概念类似(数据内部,属性内部计算)
# 举例子:一个男生受女生欢迎程度,和这名男生萎缩程度,是否成正比,什么关系
array([[0.5, 2. , 1. ],
[2. , 8. , 4. ],
[1. , 4. , 2. ]])
8、线性代数计算
向量计算
a = np.arange(3)
b = np.arange(3)
a * b # 对应元素相乘, 保持原来的形状
array([0, 1, 4])
print(np.inner(a,b)) # 1*1+2*2+0*0
a@b
5
5
矩阵运算
a = np.arange(1,5).reshape(2 ,2)
a.dot(a)
array([[ 7, 10],
[15, 22]])
np.dot(a,a)
array([[ 1, 4],
[ 9, 16]])
9、实战-用NumPy分析鸢尾花花萼属性各项指标
案列:读取iris数据集中的花萼⻓度数据(已保存为csv格式)
并对其进⾏排序、去重,并求出和、累积和、均值、标准差、⽅差、最⼩值、最⼤值。
data = np.loadtxt('./iris.csv',delimiter = ',') # 读取数据⽂件,data是⼆维的数组
data.sort(axis = -1) # 简单排序
print('简单排序后:', data)
print('数据去重后:', np.unique(data)) # 去除重复数据
print('数据求和:', np.sum(data)) # 数组求和
print('元素求累加和', np.cumsum(data)) # 元素求累加和
print('数据的均值:', np.mean(data)) # 均值
print('数据的标准差:', np.std(data)) # 标准差
print('数据的⽅差:', np.var(data)) # ⽅差
print('数据的最⼩值:', np.min(data)) # 最⼩值
print('数据的最⼤值:', np.max(data)) # 最⼤值