台湾大学深度学习课程 学习笔记 Lecture 5-2: Sequence Generation
以下内容和图片均来自台湾大学深度学习课程。
课程地址:https://www.csie.ntu.edu.tw/~yvchen/f106-adl/syllabus.html
Generation
RNN的应用方法
sentences是由characters/word组成;- 使用RNN的方法每次生成一个
characters/word
X 是之前产生的一个word,用one-hot-encoding 表示。通过function f 处理后,生成distribution probility y 。


这部分其实之前课程中有讲过,这边重复一遍过程。举例说明,具体实践中每一步的实现方法。
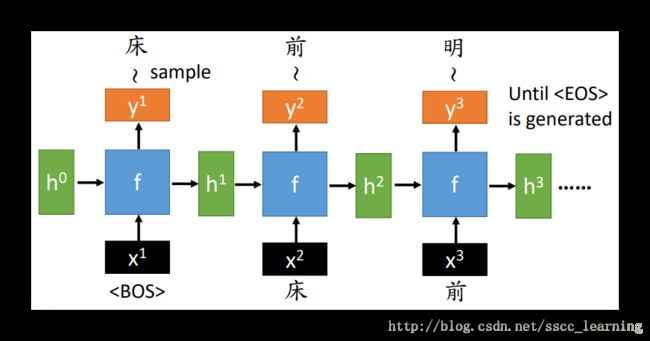
- 假设
Train的句子是“床前明月光”。 x1 为一句话的开始符,例如标识为begin of sentences。在这里,包括后面,不管是word还是标识符one-hot-encoding的方式表示; - x1 与 初始化的 h0 通过
functionf ,得到 y1 与 h1 。此时, y1 中的分布概率代表每个字出现在一句话首位的概率, P(w|<BOS>) 。 h1 则作为下一步的输入,向后传递信息; - 继续下一层。向 f 中输入x2 与 h1 ,这里 x2 即为
床的one-hot-encoding信息,得到 y2 与 h2 。 y2 表示为 P(w|<BOS>,床) ,是两个前提下每个字出现的分布概率。第一个前提是位置,第2位。另一个是前面出现过的字,目前为止只出现了床。 h2 则继续向后传递信息; - 继续同样的步骤,使用
前的one-hot-encoding当做 x3 与 h3 一起输入 f ,得到 y3 与 h3 。 y3 表示为 P(w|<BOS>,床,前) ,同样是两个前提下每个字出现的分布概率。第一个前提是位置,第3位。另一个是前面出现过的字床、前。 h3 则继续向后传递信息; - 以此类推,直到出现终止符
对上面每个 y 与对应的word的1 of N encoding 取交叉熵。对所有交叉熵求和后当做损失函数,最小化损失函数。
如果训练数据是“床前明月光”的话,经过优化之后,y1 中“床”对应的概率就会比较高, y2 中“前”对应的概率就会比较高……
PixelRNN
这里简单提一下,这个是RNN在图片上的一种用法。
把图片中的每个像素颜色用对应的word记录下来,组成sentences。然后用RNN去训练这些sentences。

另外,记录的顺序也需要注意一下。这里不深入讨论,感兴趣可以去查PixelRNN相关文献。
Conditional Sequence Generation 有条件的
很多情况下,会用到有条件的Generate sentences。比如给一张图片添加描述 Caption Generation,或者与机器进行对话 Chat-bot。
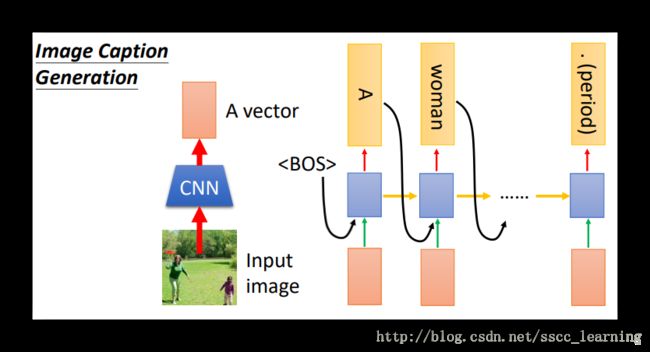
Image Caption Generation
- 通过
CNN把图片转化成vector; - 之后每一层RNN都要把这个
vector当做 x 进行输入; - 循环第一层还要添加一个起始符
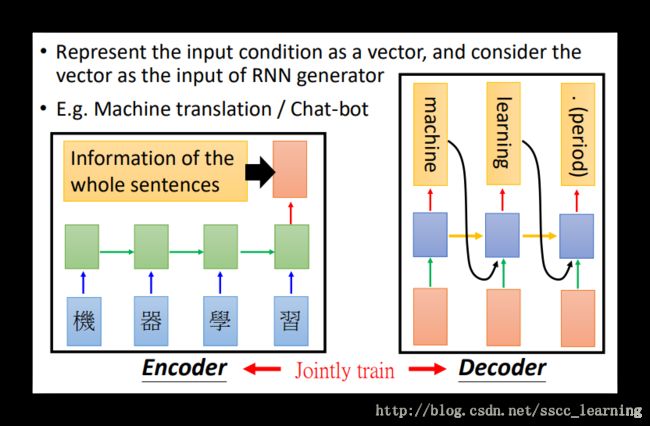
Machine translation
在机器翻译 Machine translation方面的应用,也是先要将待处理的数据转化成vector。文字转化成vector,就需要用到RNN。这个过程称为Encoder。
转化成功后,接下来的处理与上面Image Caption Generation 方法一致。这个过程称为Decoder。
Chat-bot
聊天机器人 Chat-bot 的原理与上面说的机器翻译基本一致。对机器说一句话“Hi”,机器经过 Encoder 与 Decoder 处理后,机器人回复你“Hi”。
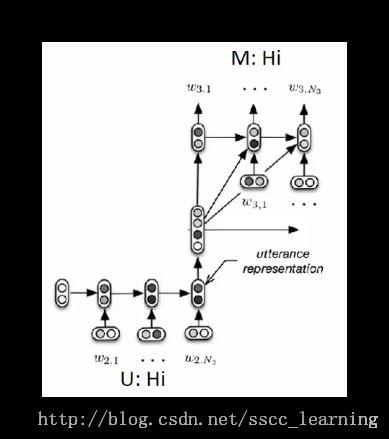
但是对话过程毕竟和翻译不一样,区别在于,对话是需要联系上下文的。假如之前机器已经说了“Hello”,你回复了句“Hi”,这时机器人再说“Hi”就显得不合理了。
Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models 这篇文章中介绍了一种方法“Hierarchical Recurrent Encoder-Decoder”,通过RNN把之前的对话都Encoder成dense vector。把这些信息作为Conditional Generation的输入进行Decoder。
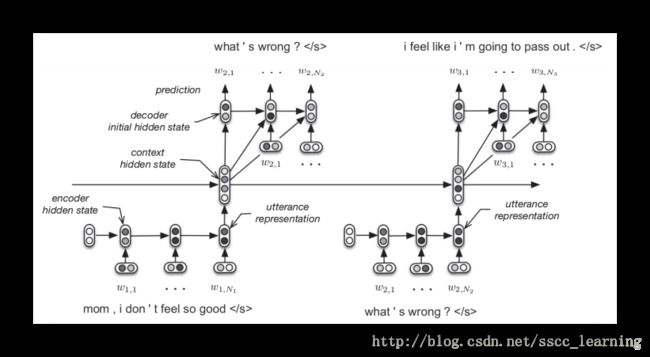
Dynamic Conditional Generation
在机器翻译中,之前讲的Encoder是把一句话转化成vector后,再进行Decoder 。但是在这个vector中,信息数据损失会比较严重。所以就需要一种方法,可以有效地减少这种数据损失。
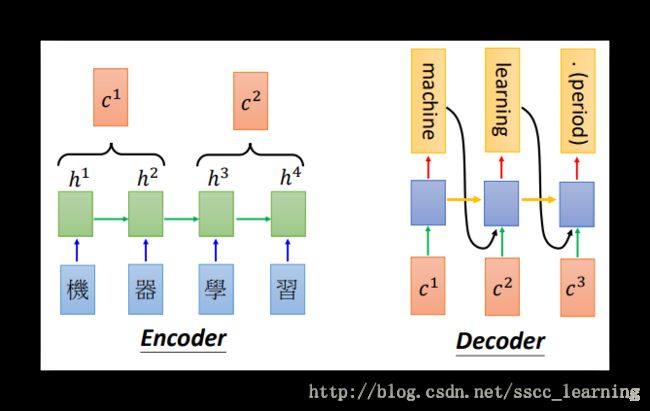
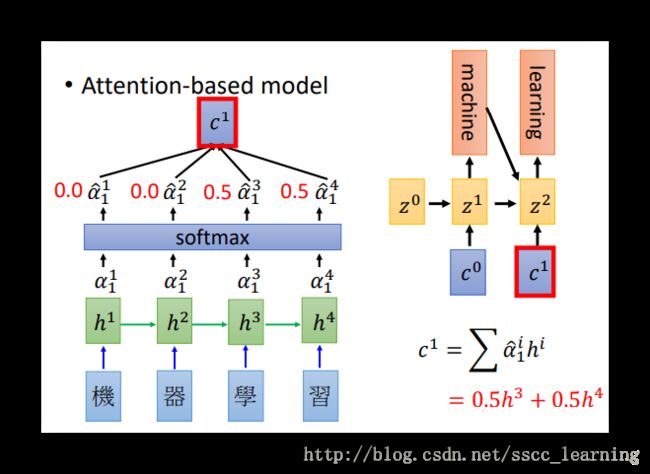
“Dynamic Conditional Generation”方法通过动态的对所需的数据进行索取,从而减少损失。举例来说,需要将“机器学习”翻译成“machine learning”,首先会读取“机”、“器”的数据 h1 、 h2 进行Encoder,生成向量 c1 ,对 c1 Decoder,得到结果“machine”;然后在读取后面的“学”、“习”,Encoder 生成向量 c2 ,对 c2 Decoder得到“learning”,其他步骤不变。
这里有一个问题,如果确定需要选取哪些部分数据呢?比如上面为什么要先选取“机、器”,再选取“学、习”?
还以机器翻译为例,说一下筛选方法。
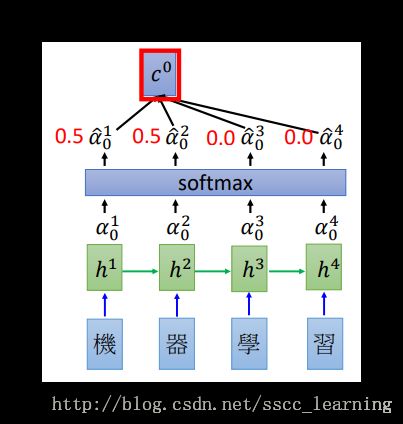
- 需要翻译的文字,这里是“机器学习”,经过RNN的处理,得到结果 h (这里的h 其实是之前RNN中讲的 y );
h1 与 z0 经过
match function得到结果 α10 。 z0 是可以被优化的初始化参数。match function由自己定义,可以是 z 和 h的“余弦相似度”,也可以是简单的神经网络,这里用的是公式 α=hTWz ;
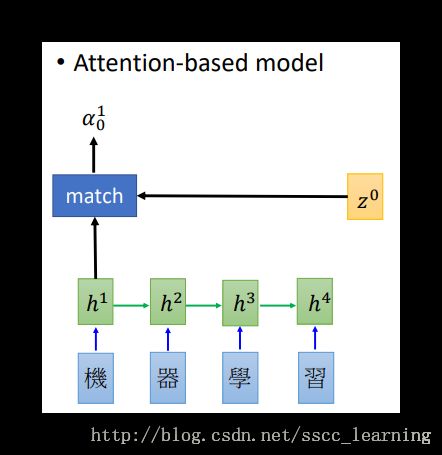

α 是经过
softmax处理后的结果,与对应的 h 相乘,再求和得到 c0,公式为 c0=∑α^i0hi 。通过这种方式,就确定了 c0 每个词的重要程度;
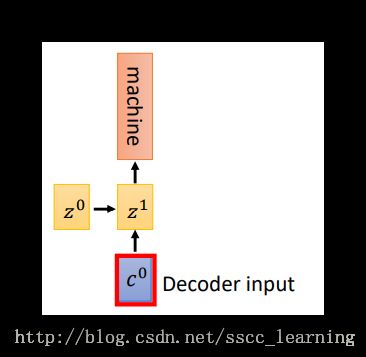
接下来是
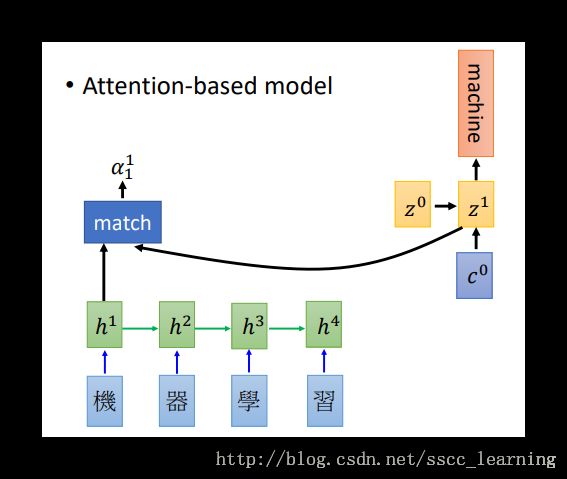
Decoder,将得到的 c0 与 z0 一起放入RNN中继续训练, 会得到结果“machine”和下一个循环的输入 z1 ;
将 z1 与 h 按照之前的方法重新计算,得到 α1 , α1 经过处理并计算得到 c1 。 c1 继续作为输入继续进行
Decoder;
经过不断的循环,直到出现终止符

通过上面的介绍可以看出, z 起到了“钥匙”的作用,通过匹配 h 得到“两者得分” α 。上面 z 的图示并不是特别准确,z 其实是RNN中的其中一个输出。
通过这种方式,后面每个翻译的word都是针对前面不同权重词。比如翻译后的“machine”与“learning”使用的输入的汉字的权重就不同,有效的保留了最初输入的信息。
由于每部分的输出对应到前面的“注意点”都不一样,所以模型又叫“Attention-based model”。
应用
通过上面的讲解,基本内容基本上就已经讲完了,下面开始讲一些应用。什么情况下可以应用这些呢?基本上input和output只要能转换成sequence ,基本上就能应用。下面讲了一些例子,比如语音识别,描述图片,描述视频等。
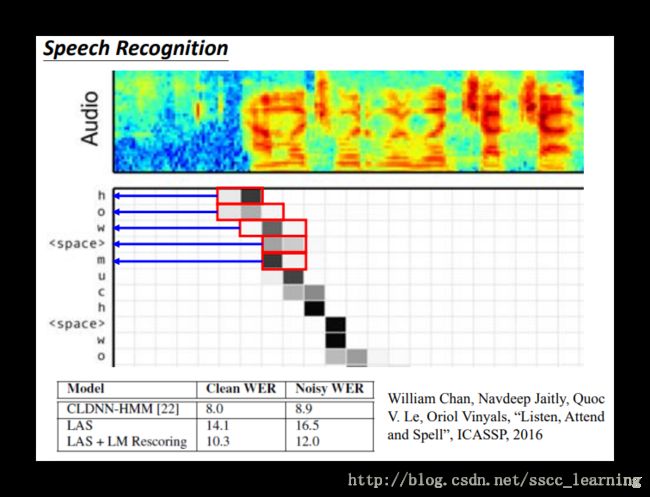


Tips for Generation 小技巧
Attention weight 权重差异
Attention-based model 中每次循环的“Attention”权重差异较大。比如下图“描述视频”的例子,“woman”出现的情况不一样,就会导致 weight 差异很大,这时候可以添加“正则项”。

Mismatch between Train and Test 不匹配
在training 中,RNN之间的传递使用的是真实值的传递,也就是用真实值当做下一层的输入。而在Test 时,由于没有真实值,只能依靠上一层的输出当做下一层的输入。两者之间的差异,有时会导致较大的误差,因为后面的预测都是基于之前的结果,所以会导致“一步错,步步错”。
那在training 的时候,也使用上一层的输出而不是用真实值可以吗?
答案是这样也不好。
首先这样会很难去训练,因为这样会导致整体都是一个动态变化非常大的过程,没有固定的结果很难有效的去训练。
还有一个原因。先举个例子,我们都知道“I”后面跟“am”,“you”跟“are”。假设现在首word已确定是“you”。如果使用真实值作为下一层的输入(下图左),可以直接确认“you”,并根据“you”进行优化,得到结果说后面再跟“are”是比较好的。但是如果使用训练结果当做下一层的输入,训练结果中是得到的各种word的概率值,“you”和“I”有可能具有相似的概率,把这个结果放到下一层中,接下来的“am或are”有可能无法有效地区分“I或you”,最终造成“I are ”这种错误的输出。
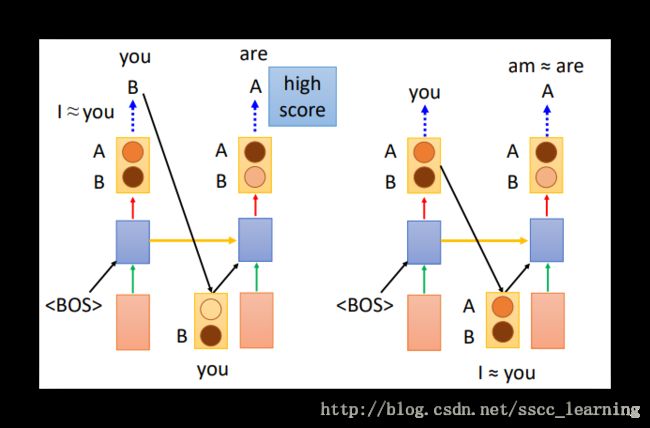
解决这个问题,使用的方法是 Scheduled Sampling 。方法是优先使用真实值去训练,当趋向稳定的时候,改成用上一层输出的结果训练。
下面是各种方法结果对比:

Beam Search
上面说了,在训练数据时(Training),我们是知道sentences 内容结构的,每一层的输入 x 都是确定的顺序,比如“床前明月光”,所以 x2 我选择“床”, x3 我选择“前”。但是模型训练完成,实际应用时(Test), y1 、 y2 … 这些都是模型跑出来的,是不确定的,那如何去确定 x2 、 x3 …?
有一种方法是argmax,就是每一步都使用本次概率最大的那个word当成结果,最后组成一句话。但是假如综合效果最好的sentences中有一个word出现的概率不是那个位置最高的,使用argmax非但无法得到这个sentences,还会导致这个word之后的words都会产生变化。又不太可能将所有可能的组合尝试后进行对比。具体解决方法,就是下面提到的“Beam Search”。
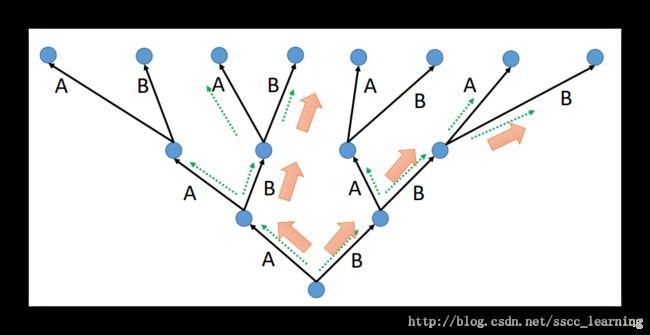
首先需要确定一个Beam Size,这里设置为2,意思是每个word后面的分支考虑概率最大的那两个words。比如下面的例子,首先分成A、B两个words,然后A、B往后传播,现在句子是AA/AB/BA/BB这四种情况(绿色虚线)。考虑到Beam Size=2,选择概率最大的两个,假设是AB/BA(橙色大箭头)。然后以选择的AB/BA继续向后传播,又出现了四种情况ABA/ABB/BAA/BBB,依然是选择综合概率最大的两个ABB/BBB。按照这种方法,只要可以调整好Beam Size,就能够使用最小的计算量,得到最优的结果。
Object level v.s. Component level
最小化各个word的Cross-entropy之和,会有一些局限性,因为这种优化方式是针对每个部分来的,而人看句子是一整句看的。有时候哪怕训练结果“The dog is is fast”与正确结果“The dog is running fast”只有一个word的差距,给人的感觉也会很奇怪。

所以就引出了object-level criterion R(y,y^) ; y : generated utterance , y^: ground truth 方法,但是这种方法不能微分,所以不能用一般梯度下降的方法去优化。更多详细方法请参见论文 Ranzato M A, et al. Sequence level training with recurrent neural networks 。