TensorFlow实战(4):经典卷积神经网络
这一章讲解了几个经典的卷积神经网络,包括AlexNet,VGGNet,GoogleInceptionNet,ResNet,并用TensorFlow实现他们。关于这一章的介绍方式,我还是挺纠结的。原先想的是按照书上的,每个网络架构讲解一下,各写一个博客,像先前一样,重点还是在tensorflow的实现上。但是后来还是觉得,整体写一个综述可能对自己对大家的帮助更大。代码的实现可以就不一一尝试了,有兴趣的可以看看书,理解代码就好,毕竟现在轮子太多,不需要我们从头实现这些网络。
卷积网络的发展历程
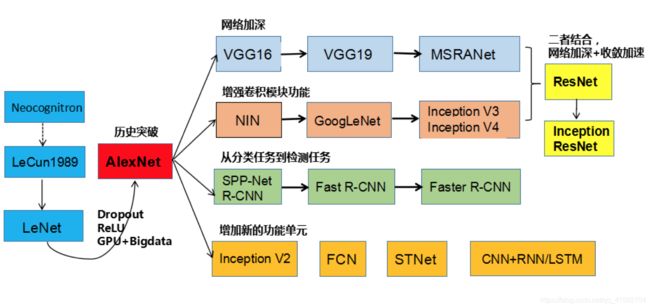
《TensorFlow实战》本章主要重点在前两种发展趋势,一种是网络加深,一种是增强卷积块功能。本文的重点也是介绍这两条线的相关网络。
LeNet5
论文:Gradient-Based Learning Applied to Document Recognition
时间:1998
网络结构:

LeNet5是整个CNN的开山鼻祖,书上是在第5章的79页介绍的。该网络是用于手写体字符识别的非常高效的卷积神经网络。其一共有七层,分别为卷积层,池化层,卷积层,池化层,卷积层,全连接层,全连接层。卷积核大小均为5*5,池化层的采样区域均为2*2,。
突破:
(1)使用双曲正切或Sigmoid激活函数
(2)定义了卷积神经网络的基本架构:卷积层+池化层+全连接层
(3)定义了卷积层。
相关资料:LeNet5详解
AlexNet
论文:ImageNet Classification with Deep Convolutional Neural Networks
时间:2012
网络结构:
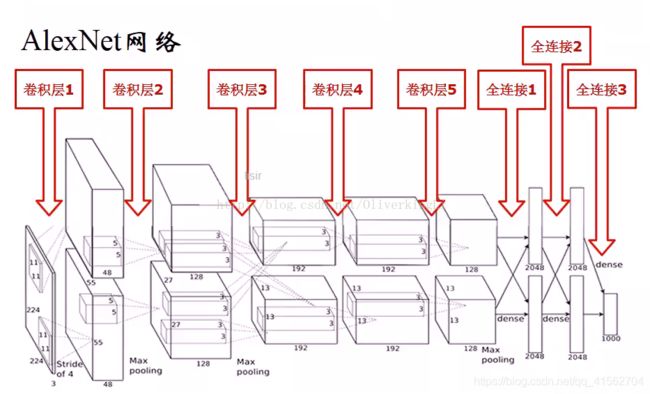
AlexNet网络当时提出是用于ILSVRC任务中,即ImageNet数据集(1000类图片)检测。ALexNet把CNN的基本原理应用到了很深很宽的网络中,其出现后,卷积神经网络才开始爆炸性发展。AlexNet一共有8层(不含池化层和LRN层),拥有5个卷积层。
这里放个小彩蛋,AlexNet在图片预处理中把图片裁剪为224*224并进行数据增强。为什么是这个尺寸呢?
答:最后一个卷积特征feature map的大小,可以是3*3,5*5,7*7等等在这些尺寸中,如果尺寸太小,那么信息就丢失太严重,如果尺寸太大,信息的抽象层次不够高,计算量也更大,所以7*7的大小是一个最好的平衡。因此找一个7*2的指数次方,并且在300左右的,其中7*2的4次方=7*16=112,7*2的5次方等于7*32=224,7*2的6次方=448,而ImageNet中图片长款多为300左右,与300最接近的就是224了。
突破:
(1):使用Relu代替双曲正切激活函数
(2):在最后几个全连接层使用Dropout,随机忽略一部分神经元。
(3):使用最大池化层代替平均池化层。
(4):提出LRN层,对局部神经元的活动创建竞争机制。
(5):采用双 GPU 网络结构,从而可以设计出更“大”、更“深”的网络。
(6):数据预处理:使用数据增强扩充数据集,对训练图像做PCA,利用服从 (0,0.1) 的高斯分布的随机变量对主成分进行扰动。
相关资料:AlexNet详解
VGGNet
论文地址:Very Deep Convolutional Networks for Large-Scale Image Recognition
时间:2014
网络结构:
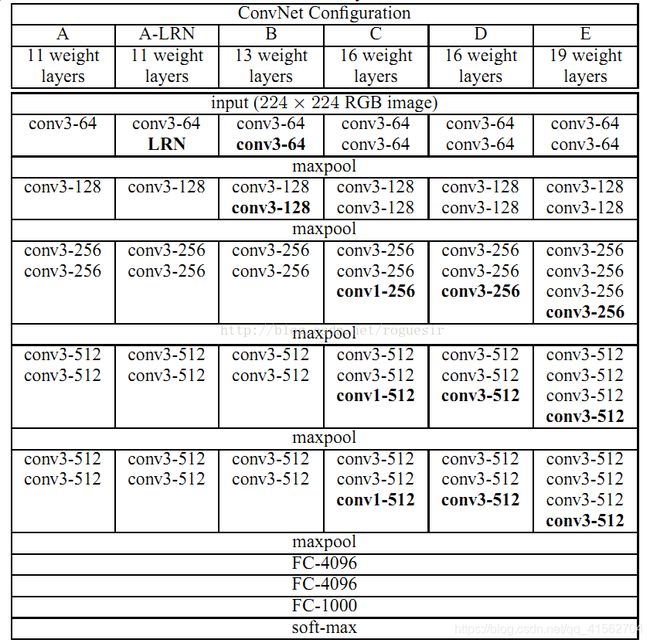
VGG网络同样也是用于ILSVRC比赛中,在2014年取得了第二名的成绩。利用多个小卷积核可以代替高维卷积核进行卷及操作,达到减少计算量的效果。网络结构中,卷积层步长都为1,池化层步长都为2。从VGG-A到VGG-E的参数量没有发生太大的改变,其中D、E就是常说的VGG16和VGG19。
突破:
(1)取消LRN层,LRN的作用不大,且增加训练时间
(2)先训练简单网络,再复用该网络权值来初始化后面的几个复杂模型。
(3)在数据增强中,先做宽高等比缩放(原文用的词是 isotropically rescaled,即同质化缩放),使其最短边长度达到 S,接着再做随机裁剪。
(4)证明了越深的网络效果越好。
(5)整个网络全部使用了3*3的卷积核和2*2的池化核。一方面可以减少运算量,另一方面可以进行更多地非线性变换,可以增强特征的学习能力。
NIN
论文:Network in Network
时间:2013
网络结构:

NIN改进了传统的CNN,采用了少量参数就取得了超过AlexNet的性能,AlexNet网络参数大小是230M,NIN只需要29M。
突破:
(1)将传统卷积层替换为非线性卷积层以提升特征抽象能力
(2)使用新的pooling层(全局平均池化层)代替传统全连接层
相关资料:NIN论文笔记(含TensorFlow实现)
Google Inception Net
Inception V1
论文地址:Going Deeper with Convolutions
时间:2014
网络结构:

其中提出的Inception Module的结构如下:
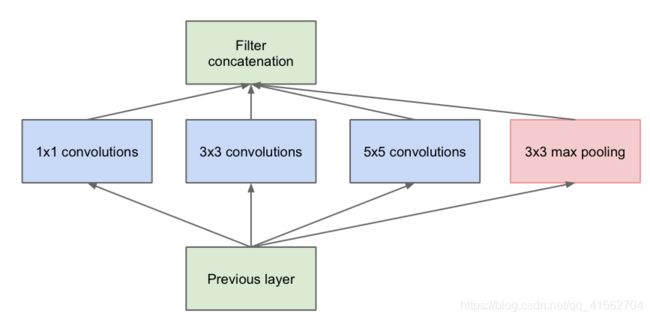
它一共包含了4个 分支。第一个分支是一个1×1的卷积,1×1的卷积是一个非常优秀的结构,它可以跨通道组织信息,来提高网络的表达能力,同时还可以对输出通道进行升维和降维,1×1的卷积还可以进行低成本的跨通道特征变换,在Google Inception Net中大量使用了1×1的卷积。第二个分支,先使用了一个1×1的卷积,然后再连接了一个3×3的卷积,相当于进行了两次特征变换。第三个分支的结构与第二个分类相类似,只是将3×3的卷积换成了更大的5×5的卷积。最后一个分支,是先进行3×3的最大池化,然后再使用1×1的卷积。最后通过聚合操作在输出通道上将四个分支的结果进行合并。Inception Module中包含了1×1、3×3、5×5三种不同大小的卷积和一个3×3的最大池化,来增加网络对于不同尺度的适应性。
GoogleNet是ILSVRC 2014的冠军。Inception的最大特点是:通过精心设计,使得网络在计算量不变的前提下,深度和宽度得到了增加,Inception V1一共有22层,比VGGNet更深。从而提高了深度网络对于计算资源的利用。14年用于ILSVRC的GoogleNet是他的一个特例。Inception V1的特点就是控制了计算量和参数量,Inception V1只有500万 的参数量,而AlexNet有6000万。
突破:
(1)精心设计了Inception Module来提高参数的利用率。
(2)使用辅助分类节点(auxiliary classifiers),将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终的分类结果中。相当于做了模型融合,同时还给网络增加了方向传播的梯度信号。
(3)借鉴了NIN中全局平均池化层代替最后一层全连接层
Inception V2
论文地址:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
时间:2015
新的Inception module:

InceptionV2在ImageNet上的识别打败了GoogleNet。
突破:
(1)Inception Module 中卷积核大小为 5 × 5 的卷积层用两个相连的卷积核大小为 3 × 3 的卷积层进行替换。
(2)使用BN算法,对每一个batch数据进行内部的标准化处理(均值为0,方差为1),使得输出规范化到N(0,1)的正态分布,减少Internal Covariate Shift(内部神经元分布的改变)。
Inception V3
论文地址:Rethinking the Inception Architecture for Computer Vision
时间:2015
突破:
(1)优化算法使用RMSProp替代SGD。
(2)使用Label Smoothing Regularization(LSR)方法
Inception V4(Inception ResNet)
论文地址:Inception-v4,Inception-ResNet and the Impact of Residual Connections on Learning
时间:2016
Inception V4相对于Inception V3主要是结合了微软的ResNet。
ResNet
论文地址:Deep Residual Learning for lmage Recognition
时间:2015
2015 年,Kaiming He 提出了 ResNet(拿到了 2016 年 CVPR Best Paper Award),不仅解决了神经网络中的退化问题(Degrade Problem,即相较于浅层神经网络,深层神经网络的深度到达一定深度后,拟合能力反而更差,训练/测试误差更高),还在同年的 ILSVRC 和 COCO 竞赛横扫竞争对手,分别拿下分类、定位、检测、分割任务的第一名。
Xception
论文地址:Xception:Deep Learning with Depthwise Separable Convolutions
时间:2016
参考资料
CNN入门
CNN发展史
《TensorFlow实战》第6章
机器学习与人工智能技术的分享(推荐!)