卷积神经网络(CNN)系列介绍之一 (LeNet-5 / AlexNet / GoogLeNet / VGGNet / BNInception / Inceptionv3)
文末有福利。
目录
1-绪论
2-引子
3-正文
3.1-Params和FLOPs计算
3.1.1-Params参数计算
3.1.2-Connes神经元连接数计算
3.1.3-Multi-add(FLOPs)
Reference:
3.2-LeNet-5(1998)
3.2.1-前言
3.2.2-LeNet-5网络结构明细
3.3-AlexNet(2012)
3.3.1-前言
3.3.2-AlexNet创新点
3.3.3-AlexNet网络结构明细
Reference:
3.4-Inception-v1(GoogLeNet)(2014)
3.4.1-前言
3.4.2-GoogLeNet创新点
3.4.3-GoogLeNet整体网络
3.4.4-GoogLeNet网络结构明细
3.5-VGGNet(2015)
3.5.1-前言
3.5.2-VGGNet创新点
3.5.3-VGGNet网络结构明细
3.6-Inception-v2(BN)(2015)
3.6.1-前言(BN)
3.6.2-算法流程
3.6.3-Inception-v2网络结构明细
Reference:
3.7-Inception-v3(2015)
3.7.1-前言
3.7.2-Inception-v3创新点
3.7.3-论文要点
3.7.4-Inception-v3网络结构明细
4-总结
Reference:
1-绪论
互联网行业是如此光鲜亮丽,无论是985211还是普通院校,无论是科班专业人才还是生化环材劝退专业,涌入这个财富深藏的行业人才都不计其数。计算机应届毕业生的薪酬显著高于其他专业一个等级的现象,让无数高材生们舍弃了自己的专业而转身投向这个多金的行业,在这个房价高涨的社会中,只能靠个人奋斗才能在大城市立足的青年学子只好艰难地挤进这片红海并希冀能够有一番作为。
而深度学习无疑是互联网行业的皇冠,也是这几年互联网红海中厮杀搏斗最激烈的场区之一,人工智能毕业年薪五十万甚至百万的各种新闻和推文都在挑动着青年们的神经,深度学习也确实在很多行业产生了革命性的进展,从人脸识别到推荐搜索,从自动驾驶到人机对话,几乎都在行业内掀起了革命性的风波,促进了行业的大跃进。
近两年,各种编程、机器学习、深度学习的公众号和个人号开始如雨后春笋般的冒出来,诚然有自媒体时代风口的影响,但是也的确说明了这个行业的火热和需求。
2-引子
深度学习领域内有众多的任务和问题有待解决和改进,比如图像分类,目标检测,目标分割,实例分割,图像超分,图像去噪,图像生成,增强学习,系统风险预测等等,但是这些任务虽然多种多样,都离不开一个关键的问题,那就是这些任务基本上都是围绕基础网络进行改进和创新的。深度学习基础网络的更迭和变迁是推动深度学习其他领域任务得以进步和提升的原动力。
因深度学习基础网络非常之多,不同的任务会涉及到不同的骨干网络,主要有CV中的CNN,NLP中的RNN。笔者能力有限,现主要对流行的CNN(卷积神经网络)进行梳理和介绍,涉及到网络的提出背景、如何改进的、网络结构的具体明细以及网络效果等。
即便只是CNN,网络也非常之多,所以将CNN做成一个系列。
本篇是CNN系列之一。
关键词:CNN,LeNet-5,AlexNet,GoogLeNet,VGGNet,BNInception,Inceptionv3
3-正文
在介绍CNN网络之前,我们介绍一下网络层Params以及FLOPs的计算,因为后续网络介绍会用到这些知识
3.1-Params和FLOPs计算
Params(网络参数)和feature map的输入输出尺寸没有关系,只和kernel的size、是否具有bias以及输出的channels数量有关系。
Connes(神经元连接)和影响Params的因素有关,同时还和输出feature map的尺寸有关系。Connes是LeNet-5原始论文中提出的,后来的网络一般不提这个概念,而提的更多的是FLOPs概念。
FLOPs(浮点运算数):有的是将乘(Multi)和加(Add)作为一次计算,有的则是将乘和加作为两次,就是所谓的Multi-Add。定义不同,计算的结果也不同,两种计算一般具有约等于两倍的关系。在《PRUNING CONVOLUTIONAL NEURAL NETWORKS FOR RESOURCE EFFICIENT INFERENCE, ICLR2017》这篇论文中(NVIDIA出品),指出乘(Multi)和加(Add)应当作为两次运算(如图1-1)。

图1-1 FLOPs
3.1.1-Params参数计算
Ps:以下计算均考虑bias(偏置)
Conv(卷积层):
trainable parammeters = (ke_size * ke_size * in_cha+1) * out_cha
Pooling(池化层):
#这里的计算是因为LeNet-5中再pooling层输出后加入了可学习的参数#一般认为池化层没有训练参数,而且池化层输入输出的通道数保持不变
trainable parammeters = (ke_size)* out_cha(in_cha)
FC(全连接层):
trainable parammeters = (in_cha + 1) * out_cha
3.1.2-Connes神经元连接数计算
Conv(卷积层):
connections = (ke_size * ke_size* in_cha + 1) * out_cha * out_size * out_size= trainable parameters * out_size * out_size
Pooling(池化层):
connections = (ke_size * ke_size * in_cha + 1) * out_cha * out_size * out_size
FC(全连接层):
connections = (in_cha + 1) * out_cha
3.1.3-Multi-add(FLOPs)
乘法运算数(Multi)计算:
按照一个卷积窗口为ke_size * ke_size,Multi = ke_size * ke_size * in_cha;
加法运算数(Add)计算:
按照一个卷积窗口为ke_size * ke_size,对于n个数,有n-1次加法,所以
Add = ke_size * ke_size * in_cha – 1
Multi-Add(FLOPs)计算:
一个窗口中是Multi+Add = 2 * ke_size * ke_size * in_cha – 1,如果加上bias,是Multi+Add = 2 * ke_size * ke_size * in_cha。
因此:
Conv(卷积层):
Multi-Add(FLOPs)= 2 * ke_size * ke_size * in_cha * out_cha * out_size * out_size
Pooling(池化层):
无学习参数
FC(全连接层):
Multi-Add(FLOPs)=(2 * in_cha) * out_cha (有bias)
Notes:我们接下来的计算FLOPs都是按照一次运算来计算的,即将Multi和Add看作一次运算,也因为在计算的时候Multi是主要耗时部分,所以主要考虑Multi,因此如果在接下来的网络层FLOPs计算结果中,你发现和我们计算的结果不一致,请将Multi-Add认为是一次运算,即按照计算Connes神经元连接数的公式(不包括Pooling层)去计算。如果还是不一致,那非常有可能是我们计算错了,还请赐教。
在这里,希望大家注意两个概念:
FLOPS:全大写,是FLoating Point Operations Per Second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs:注意s小写,是FLoating Point Operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
Reference:
PRUNING CONVOLUTIONAL NEURAL NETWORKS FOR RESOURCE EFFICIENT INFERENCE, ICLR2017
3.2-LeNet-5(1998)
论文:《Gradient-Based Learning Applied to Document Recognition》
3.2.1-前言
LeNet-5是1998年由深度学习的三位顶级大牛LeCun提出,是第一代比较完整的卷积神经网络,首次将反向传播梯度更新等操作用在了CNN上,并且在实际应用也就是手写字体识别上具有非常好的效果。基本构成包括基本的Conv(卷积层)、Pooling(下采样层/池化层)以及FC(全连接层),这三种基本网络层至今依然是卷积神经网络网络结构的基础层,因其当时主要用于手写数字的识别,所以也被称为手写字体识别模型,当时用的数据集就是MINIST。LeNet-5主要包括三个卷积层、两个池化层以及两个全连接层,在后来的发展实现中,可能会有一定的出入。
卷积层和全连接层的区别在于局部感受野和权值共享,所以卷积层相比全连接层可以显著的降低训练参数,而且局部感受野也符合人的视觉基本规则,我们往往关注于眼前整个视野的某个局部部分。
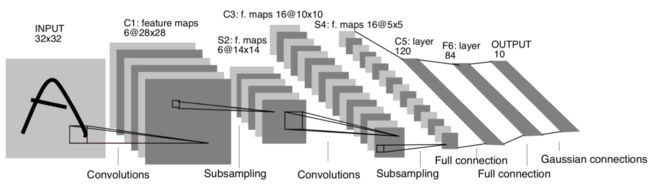
图2-1 LeNe-5整体网络
3.2.2-LeNet-5网络结构明细
Input:
32*32*1大小的手写字体图像;
Layer C1:
卷积层
5*5kernel
(5*5+1)*1*6=156Params
(5*5+1)*1*6*28*28
=122304 Connes
输出是6*28*28大小的feature map;
Layer S2:
池化层
2*2kernel
2*6=12 Params
(2*2+1)*6*14*14=5880 Connes
输出是6*14*14大小的fm,一般认为池化层是没有训练参数,因为无论是最大池化还是平均池化,其下采样的规则已经被人为制定,没有需要学习的参数,但是在LeNet原文中,作者提到池化层输出的fm还会有一个可训练的weight和bias,之后还会通过一个sigmoid激活函数,所以这里就是2*6(输出通道)=12 Params;
Layer C3:
卷积层,输出是16*10*10大小的feature map;
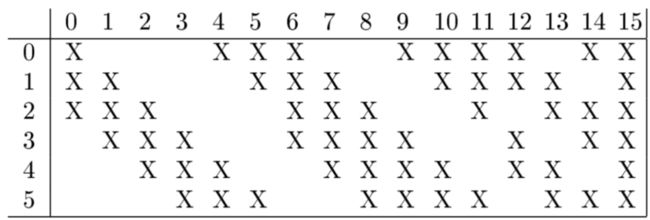
图2-2 C3和S2对应表
C3卷积层输入输出不是完全相连的,也就是说,不是一个输出kernel对应全部的输入fm,所以C3 Params和Connes计算不可以直接按照公式去计算。
如图2-2所示,横轴为输出fm的通道(16),纵轴为输入fm的通道(6),所以输出的第0个通道对应输入的012三个通道,输出的第1个通道对应输入的123三个通道,剩下的14个通道和输入通道对应情况按照表对应即可。
Params=(5*5*3+1)*6 +(5*5*4+1)*9+(5*5*6+1)*1=1516
Connes = Params*10*10=151600
关于为什么这么做,而不是将S2的每个fm与C3的每个fm相连,原因有两方面,一是不完全的连接数可以使得连接数保持在一个合理的范围内,也就是不会使得参数量和连接数过于大,二是这对于网络的非对称性有一定的好处,因为不同的fm连接的是不同的输入fm,所以不同的输出fm致力于提取不同的特征信息;
Layer S4:
池化层
输出是16*5*5大小的fm
2*16=32 Params
(2*2*1)*16*5*5=2000 Connes
基本和S2构造相似;
Layer C5:
卷积层
输出是120*1*1大小的fm
(5*5*16+1)*120=48120 params
因为fm的size为1*1,所以Connes和Params一致为48120,关于C5要说明一点,虽然单纯看网络结构图的输出fm的size是1*1,但是C5并不是全连接层,作者专门提到这一点,当input图像更大的时候,这个时候C5的输出fm就不再是1*1的了;
Layer F6:
全连接层,输出是84*1*1大小的特征向量,(120+1)*84=10164;
Layer F7:
全连接层(输出层),由径向基函数单元(RBF)单元组成,和全连接的概念类似。因为手写字体的类别有10个,所以有10个RBF单元,每个单元都和F6层的84个输入连接。每个输出的RBF单元计算的是输出特征向量和其权重向量之间的欧式距离,如果两者的距离越远,那么RBF的输出就会越大。从概率性上来讲,RBF的输出可以被解释为在F6层的高斯分布上的未归一化的负的log似然值。当作全连接层计算训练参数和连接数为(84+1)*10=850。
LeNet-5网络每层的具体参数设置、输入输出尺寸以及Params和Connes如表2-1所示。
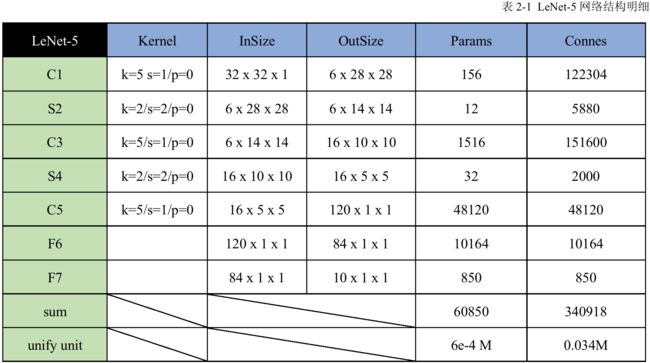
总的来说,LeNet在当时的手写字体识别任务取得了非常好的效果,基本上全面领先于传统的机器学习方法
3.3-AlexNet(2012)
论文:《ImageNet Classification with Deep Convolutional Neural Networks 》
3.3.1-前言
2006年被认为是深度学习的元年,因为Hinton提出了对权值进行初始化+有监督训练微调的策略,这在一定程度上解决了深层网络训练中梯度消失的问题(没有被完全解决,也很难被完全解决)。
2011年,ReLU非线性非饱和激活函数被提出,相比sigmoid,tanh等饱和激活函数可以有效的抑制梯度消失问题。
2012年,是深度学习卷积神经网络在视觉任务上大放光彩的一年,Hinton的学生Alex Krizhevsky 等提出了AlexNet。该网络在2010年将CNN首次用在ImageNet上的比赛,并且取得ImageNet LSVRC-2010比赛的冠军,top-1和top-5 error rates分别为37.5%和17.0%,碾压了第二名的机器学习方法SIFT+FVs,error rates是45.7%和25.7%。作者拿该模型又参加了ILSVRC-2012的比赛,在ImageNet Fall 2011数据集上训练并在ILSVRC-2012数据集上进行finetune,综合多模型平均精度可以将2012测试集top-5的错误率降到15.3%,也是全面碾压2012年的SIFT+FVs方法。正是因为AlexNet在视觉任务具有如此卓越的效果,带火了后续一系列的深度学习相关研究。
3.3.2-AlexNet创新点
1、LeNet-5已经具备了CNN大部分该有的结构,但是由于网络设计的过于简单,对于特别的复杂的视觉任务就很难胜任了,手写字体识别是10分类,ILSVRC比赛是1000分类。而AlexNet除了使用这些基本的网络结构,网络深度和宽度都有所提升,而且加入了2011年出现的ReLU激活函数,同时进行了精心的设计,其参数量更大,性能也更好。
2、由于当时硬件条件的限制,为提升训练速度,将网络放在了两张GPU上进行训练,并且为了使得两张GPU信息流通,在第二个max-pooling层进行了GPU信息交换。这可能也是后续Group Conv的前身。作者提到该模型(60百万参数以及650000神经元)在两张GTX 380 3GB的显卡上训练了五六天,这可能也是从LeNet-5到AlexNet这十几年间,深度学习进展不大的缘故吧。
3、网络含有五个卷积层,三个全连接层,其中有三个卷积层后跟着最大池化层,五个卷积层后都有ReLU激活函数。
4、为了降低过拟合,加入了Dropout层,按照一定概率使得该层的神经元随机失活。
5、还有加入LRN局部响应归一化操作可以提升网络的泛化性,在AlexNet上可以降低top-1和top-5错误率1.4%和1.2%,不过LRN被认为是一种正则化手段,后续有了BN等操作后就不怎么用了。
6、还有交叠池化(overlapping pooling),步长设置以及kernel大小设置,这可以使得网络更不容易过拟合。
3.3.3-AlexNet网络结构明细

图3-1AlexNet整体网络
下图为Pytorch版本的AlexNet的网络结构定义。
其中Linear就是全连接层。

图3-2 Pytorch实现AlexNet
AlexNet网络每层的具体参数设置、输入输出尺寸以及Params和Connes如表3-1所示。

Ps:1.1B和我看到别人计算的有点不一样,但是参数量还是比较一致的,所以这个地方存疑。
AlexNet在ImageNet上的错误率。

AlexNet算是深度学习碾压传统方法的代表,后续在网络结构设计上出现了诸多变革,有的是使用模块化以及跳跃连接操作使得网络变得很深,有的是使用多支路使得网络变得很宽,有的则是在不特别损失精度的情况下尽可能减少网络的参数量和计算量(轻量化网络),到后来发展为分辨率和网络深度以及网络宽度的自动搜索网络(NAS),总之后续的卷积神经网络的发展还是非常值得学习和探究的,也在逐步彰显深度学习的魅力和精彩。
Reference:
Deep Sparse Rectifier Neural Networks
3.4-Inception-v1(GoogLeNet)(2014)
论文:《Going deeper with convolutions》
3.4.1-前言
Inception系列是谷歌出品的网络结构,主要经历了v1、v2、v3以及v4阶段的发展。Inception-v1(GoogLeNet)主要的motivation是如何在不大幅增加网络参数和计算量的同时使得网络变得更宽和层级更深,主要是设计一种最优的稀疏卷积架构并去不断的重复这种卷积架构以加深网络层级,同时在稀疏卷积架构模块中加入多支路来使得每一层级变宽。这篇文章用到1x1卷积和全局平均池化(Global Average Pooling)主要参考自2014年《Network in Network》,这篇文章对此后网络设计有着深远影响。
提升网络性能一般有两种方式:
(1) 提升网络模型的大小,一般包括深度(层级的数量)、宽度(每一层级神经元的大小);
(2) 提升训练数据的大小;
弊端:
(1) 提升了模型的大小,也意味着参数量的增加,那么网络也更容易过拟合,网络层级深度的加深甚至还会导致梯度消失等问题,同时更大的模型意味着会提升计算资源的使用,这往往是深度学习从业者的瓶颈。
(2) 高质量的数据集的制作是成本昂贵和棘手的,特别是在数据集的标签被严格限制的情况下。
3.4.2-GoogLeNet创新点
1、 通过设计最优的局部结构(Inception模块)并在其基础上扩展以加深网络深度,使得网络达到22层,模块化的结构同样方便他人进行修改和增删;
2、 最优的局部结构(Inception模块),目的在于设计一种稀疏的卷积架构,设计不同卷积核大小的多支路使得网络每一层级变得更宽,但是同时又不像直接提升神经元大小那样会带来参数量的巨大提升;
3、 AlexNet中使用了3个高达上千维的全连接网络,这是其网络模型参数高达60 M的核心原因,因此GoogLeNet取消了全连接层,并使用全局平均池化(Global Average Pooling)来代替,这种设计表现的效果同样不俗,但是在网络最后面还是添加了一个全连接层,主要是为了方便大家进行finetune迁移学习;
4、 在主体网络中的两个阶段加入辅助监督子网络,子网络主要由GAP、Conv和两个FC层组成,以减轻梯度消失的问题。因为22层的网络在当时已经很深了,梯度消失问题会存在,在网络的中间阶段进行监督,有助于减轻这种问题;
5、 保留了AlexNet中的Dropout层和ReLU激活函数;
6、 在网络的前面使用的还是和AlexNet一致的conv+lrn+max网络(但是层的具体设置不一样),因为作者发现只有在网络的中后期使用Inception模块效果才比较好,不过作者也说了,这不是必要的操作,可能是基础设施的训练低效的原因;
7、 使用了1x1的卷积核来进行维度降低,这种设计同样也是SqueezeNet参数量如此小的主要原因。
8、 测试阶段使用不同尺度和裁剪后的图像进行测试以及使用多模型进行预测,最高可以降低top-5 error rate 6.67%。
3.4.2.1-Inception模块
1、 使用1x1、3x3、5x5大小的卷积核去分别提取具有不同感受野特征信息,提升了网络了宽度,同时多尺度信息的提取也增加了网络对不同尺度特征的适应性,有助于下一层提取不同尺度的特征信息;
2、 加入一个max-pooling支路,论文中没有特别提这种方式的意义,我觉得可能是因为max-pooling可以提取当前特征图的显著信息,并且在不怎么增加参数量的同时增大了感受野;
3、 考虑到3x3和5x5的卷积核对上一层的输出feature map直接进行卷积操作,参数量过于大,所以在其之前加入了1x1 filter进行维度降低;除此之外还在max-pooling之后加入了1x1 filter,也是为了降低维度以及更好的整合max-pooling输出的特征图信息。
4、 不同支路的feature map使用concat操作进行通道叠加。
下图(a)是不加1x1进行维度降低Inception模块
下图(b)是加入1x1进行维度降低Inception模块

图4-1 Inception module
3.4.3-GoogLeNet整体网络
架构还是非常明确的,每一个inception模块内基本不改变feature map的尺寸大小,有的inception会进行维度升高,有的则是保持维度不变。
在inception(4a)和(4b)输出处另外接了两个子网络来作为辅助分类器。

图4-2 GoogLeNet整体网络
3.4.4-GoogLeNet网络结构明细
Pytorch的max-pooling操作可以将ceil_mode=True来代表padding=1。
Kernel列中Inception维度数据对应含义为:
1x1/3x3reduce/3x3/5x5reduce/5x5/pool1x1reduce/
GoogLeNet网络每层的具体参数设置、输入输出尺寸以及Params和Connes如表4-1所示。

表4-2是Inception module模块明细

不知道GoogLeNet原始论文对于网络的参数量是如何计算的,但是基于我的理解和一些论文的参考,我有点怀疑论文中给出的表格params一列参数结果是错误的(或者说GoogLeNet作者计算params不是我所理解的params)。其中在2015年的FaceNet中其使用的backbone就是GoogLeNet,虽然只有inception(3a)网络结构具体参数设置才一致,但是我计算出的该层参数和FLOPS是和FaceNet保持一致,和GoogLeNet则完全不一样。我写了个脚本去计算FaceNet某几个inception模块的params和FLOPS,结果是保持一致的,至少大概按照我上述定义的Params和FLOPS,计算出的结构在一定程度上是保持正确的。

图4-3 GoogLeNet原始论文

图4-4 FaceNet原始论文
Ps:个人感觉这张表里FLOPS应该改为FLOPs
GoogLeNet的网络效果如下:

图4-5 GoogLeNet网络效果
3.5-VGGNet(2015)
论文:《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION 》
3.5.1-前言
文章于2015年由牛津大学视觉几何组(Visual Geometry Group)发表在ICLR上,VGGNet名字由此而来,和GoogLeNet一起参加了ILSVRC 2014的比赛,GoogLeNet第一,VGGNet第二。两者的设计思路区别很大,GoogLeNet通过模块化操作以及多支路使得网络加宽和变深,而VGGNet则是逐步缩小特征图分辨率和逐步升高特征图维度使得网络可以变得很深,而且也证明网络的深度其实是卷积网络模型性能优良的关键性因素之一。
VGGNet比较流行的有VGG-16和VGG-19两个。
VGGNet的设计主要还是参考的AlexNet,只不过网络的设计更为优雅和具有逻辑,而且相比AlexNet和GoogLeNet没有繁琐的参数的设置,可以使得网络层数从11层逐步提升至19层,网络的性能也逐渐提升。
3.5.2-VGGNet创新点
输入还是保持为224x224,预处理就是减去均值。
卷积核使用的主要是3x3,用于提取特征图信息。
其VGG-16有两种形式,一种是加入额外的1x1 filter,一种是加入额外的3x3 filter。
额外的1x1用于输入通道的线性变化,不会改变特征图的感受野,一般后面还会跟着一个ReLU非线性激活函数,卷积的步长基本都是1。
额外的3x3和另外两个3x3 filter可以实现7x7filter大卷积核的特征提取效果。
现在主流的VGG-16都是加入额外的3x3 filter。
在VGGNet中卷积操作的步长都是1,意味着卷积操作不会改变特征图的分辨率,只有max-pooling操作才会减小特征图的分辨率,设置为stride=2,filter=2x2,VGGNet-16中有5个max-pooling层负责减小特征图分辨率和提高特征图的感受野。
去掉了AlexNet中的LRN层,因为在VGGNet中,LRN不会提高精度,而且增大了显存。
基本设计思路是:
输入层以及前三个max-pooling层后的第一个conv用来维度升高,维度变化为【3,64,128,256,512】,其余的卷积操作既不改变特征图分辨率也不改变维度。设计的真的是非常优雅了。
为什么第四个maxpooling后的卷积不继续提升维度至1024,猜想是512的维度已经非常高,带来的精度提升效果远小于参数量增加,性价比很低。
小卷积核的优越性:
关于为什么不用一个7x7而使用3个3x3(3个3x3卷积核的感受野和一个7x7是一致的),主要有两点,最重要的一点是可以显著降低参数量,7x7/(3x3x3)=1.81,可以减小81%的参数量,第二点就是如果使用3个3x3,那么可以有3个ReLU激活函数,可以提高网络判别能力。

图5-1 VGGNet整体网络
3.5.3-VGGNet网络结构明细

图5-2 VGGNet原始论文
VGGNet网络每层的具体参数设置、输入输出尺寸以及Params和Connes如表5-1所示。

不同深度的VGGNet的网络效果

图5-3 VGGNet网络效果
3.6-Inception-v2(BN)(2015)
论文:《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 》
3.6.1-前言(BN)
最主要的贡献就是提出了Batch Normalization操作,BN操作在MLP和CNN是非常有效的,但是RNN上效果不明显,Layer Normalization在RNN网络上比较有效。
提出背景:
(1) 一般进行深度网络的训练,使用的是mini-batch数据进行训练,即从训练集中每次提取batchsize大小的数据放入网络中进行梯度更新,梯度更新一次称为一步(或一次迭代)iteration,遍历一次完整的数据集称为一个epoch。自然而然,每一个batch里数据分布都不同,每一层网络都要重新适应输入数据分布的变化,这使得网络难以训练;
(2) 在深层网络中,每一层网络接收的上一层的输出分布差别都很大,同时激活函数还会改变这种分布,而且随着网络的加深,这种Internal Covariate Shift现象会更加严重,那么网络的收敛速度就会变得很慢,甚至出现梯度消失等问题。
BN优点:
(1) 将网络每一层的输出标准化到一个稳定的分布,提高了网络对于输入分布变化的适应性,即网络不需要再费劲的去适应不同的数据分布。
(2) BN的存在可以使用较大的学习率去训练网络,可以加速网络训练,因为之前由于每一层的输入分布尺度差别很大,每一层需要的学习率差别也很大,所以需要使用一个较小的学习率来保证每一层的梯度都能较好的更新。但是BN将分布标准到一个稳定的分布,就避免了这种现象。
(3) BN相当于一种正则化手段,可以降低过拟合现象。正因为BN的正则化作用,意味着Dropout这种降低过拟合手段可以在网络中取消,L2权重衰减系数也可以降低。同时AlexNet、GoogLeNet中含有的LRN层也可以取消了。
(4) 可以更彻底的打乱样本,阻止相同的样本出现一个mini-batch内。对于BN来说,当模型每一次看到的样本不同时,也没什么影响,而且随机训练更有利于网络训练。
(5) 可以减少图像扭曲。因为BN训练的更快,而且观察到每一个训练样本的次数更少,所以希望模型看到的都是更加真实的图像。
3.6.2-算法流程

图6-1 BN算法流程
(1)计算每一个mini-batch的均值(mean)和方差(variance),在实际测试中,BN层中需要的均值和方差应该是整个训练集的均值和方差,整个训练集的均值和防止使用的是滑动均值和滑动方差,在训练的时候使用滑动平均法来计算。
(2)计算输入标准化后的结果,分母中常量为了避免除0以及增加训练稳定性。
(3)加入两个可学习因子gamma和beta,因为normalization有可能降低网络的非线性表达能力,所以使用两个可学习的因子来微调结果输出,增强网络的表达能力。
(4)将经过BN后的输出再放入ReLU激活函数中。
(5)一般说来,在网络框架里,会对滑动平均法方法要求提供一个decay值,decay控制模型更新的速度,越大模型越稳定,一般设置为0.99或0.999。滑动平均法计算具体如下图。

图6-2 滑动平均法
3.6.3-Inception-v2网络结构明细
BN加入在卷积之后,非线性激活函数之前,有些研究也考虑在非线性激活函数之后加入BN操作,并证明这种设计对于提升网络性能的效果更好,暂且不表。
Inception-v2不仅仅在卷积层后加入BN,网络的具体设计也进行了了很大改变。

图6-3 Inception-v2原始论文
(1) 这里的表格没有展示BN层,其实凡是有卷积层的位置都加入了BN层;
(2) 对之前的GoogLeNet也就Inception-v1的inception模块中的维度变化值进行了调整;
(3) 模块内使用的不再完全只是max-pooling,还使用了很多avg-pooling池化操作;
(4) 将inception(3b)后的max-pooling改为inception(3c)模块(步长设置为2)来降低特征图分辨率,将inception(4e)的步长设置为2以再次降低特征图分辨率,所以图中inception(3c)和(4e)的output size有点问题,应当是红色部分字体所示。
(5) 将所有5x5的卷积核改为两个3x3叠加(应该是参考的VGGNet),可以有效降低参数量。
Inception-v2网络每层的具体参数设置、输入输出尺寸以及Params和Connes如表6-1所示。

网络效果:
GoogLeNet在ensemble的情况下,可以将top-5 error降低到6.67%,Inception-v2(BN-Inception)可以降低到4.9%,提升还是非常明显的,将错误率降低到了5%以内。而在文章《ImageNet Large Scale Visual Recognition Challenge》中提到过,人眼的错误率大概是5.1%,这也是网络算法首次 在ImageNet上超越人类。

图6-4 Inception-v2实验效果
Reference:
ImageNet Large Scale Visual Recognition Challenge
3.7-Inception-v3(2015)
论文:《Rethinking the Inception Architecture for Computer Vision》
3.7.1-前言
该论文提出了一些网络设计的普遍原则
原则1:要防止出现特征描述的瓶颈。所谓特征描述的瓶颈就是中间某层出现对特征比较大比例的压缩(比如使用pooling操作),这种操作会造成特征空间信息的损失,导致特征的丢失。虽然pooling在CNN中操作很重要,但是可以使用一些方法来尽量避免这种损失(笔者记:后来的空洞卷积操作)。
原则2:特征的维度越高训练收敛的速度越快。即特征的独立性和模型收敛的速度有很大关系,独立的特征越多,输入的特征信息就被分解的越彻底,子特征之间的相关性低,子特征内部的相关性高,把相关性强的放在一起更容易收敛,Hebbin原理:fire together, wire together。
原则3:通过维度降低减少计算量。v1中先通过1x1卷积降维再进行特征提取。不同的维度之间有一定的相关性,降维可以理解为一种无损或者低损压缩,即便是维度降低了,依然可以利用其相关性恢复其原有的信息。
原则4:要平衡网络的深度和宽度。只有同比例的提升网络的深度和宽度,才能最大限度提升模型的性能。个人感觉这点原则和后来的EfficientNet设计原则很相似 。
3.7.2-Inception-v3创新点
(1) 认为Inception-v1中对于辅助分类器可以提高对低级特征的获取的理论是不合理的。相反论文里认为辅助分类器是一种正则化的手段,当将辅助分支换成BN层或者直接加入一个dropout层,主分类器的性能是更好的,不仅证明了辅助分类器是一种正则化的手段,而且辅助证明了BN也是一种正则化的手段。
(2) 个人感觉Inception-v3主要是引入了非对称卷积(一维卷积/空间可分离卷积)来对Inception module进一步设计和优化;
(1) 针对VGGNet中提到的小卷积核代替大卷积核这种网络设计思想进行了一定探讨(Inception-v2中有使用);
(2) 引入了label-smoothing正则化方法
(3) 对pooling层会造成空间信息损失尝试了一些补救方法。
3.7.3-论文要点
三种inception module、label-smoothing
3.7.3.1-三种inception module
Figure 5是将最原始的inception module中的5x5替换为两个3x3;
Figure 6是将卷积直接串联替换为深度可分离卷积;
Figure 7是将卷积并联替换为深度可分离卷积;
图7-1 三种inception module
下图左侧为先Pooling再inception,右侧则相反,左侧可以显著的降低参数,但是pooling损失了空间信息,不利于后续的inception模块提取特征信息。
设计两条并行的conv和pooling操作,并将两者concat再一起,可以在一定程度上弥补这种损失,又不会特别提高参数量。
在inception-v1中直接使用的是max-pooling,而在inception-v2中将max-pooling替换了步长为2的inception module,该module中就是右图中的这种并行操作,感觉有点旧事重提的感觉。
图7-2 Pooling补救方法
3.7.3.2-Label-smoothing
这里不详解,主要就是让样本的label不再严格限制为原来的label,而是采取一个公式,重新为样本分配一个newlabel,newlabel距离label有一定距离,这样的机制鼓励模型对其预测值不会太过自信,作为一种有效的正则化手段,可以在一定程度上避免过拟合现象的出现,使得网络更具有泛化能力。
3.7.4-Inception-v3网络结构明细
图7-3是Inception-v3的整体网络结构图。
图7-3 Inception-v3整体网络
图7-4为原始论文中定义的网络结构,过于简单,所以我参考了Pytorch下的源码实现,给出了具体的网络结构明细,表7-1所示。

图7-4 Inception-v3原始论文

在Pytorch的源码实现时,Inception具体结构和原始论文稍稍有些区别,下面两张图是表7-1中所涉及到的Inception具体结构图。
其中图7-5中展示的inception module主要是多层次多尺度的提取特征。

图7-5 Inception module keep grid size
图7-6展示的inception module则是采用并行的结构来实现特征图分辨率的下采样,这种并行的结构在前面也提到过,可以在一定程度上补救单独使用pooling所造成的空间信息损失问题。

图7-6 Inception module grid size reduction
网络效果
Inception-v3可以将top-5 error降低到3.58%。

图7-7 Inception-v3网络效果
4-总结
本次CNN系列之一介绍了六个主流模型,简单总结如表8-1。

***因作者能力及时间有限,文中可能存在某些错误或疏漏,希望读者可以不吝赐教。***
CNN系列之一论文已打包好.
链接: 百度网盘 请输入提取码 提取码: 9d4w
Reference:
FLOPs:PRUNING CONVOLUTIONAL NEURAL NETWORKS FOR RESOURCE EFFICIENT INFERENCE, ICLR2017
LeNet-5:Gradient-Based Learning Applied to Document Recognition
ReLU:Deep Sparse Rectifier Neural Networks
NIN:Network in Network
FaceNet: A Unified Embedding for Face Recognition and Clustering
AlexNet:ImageNet Classification with Deep Convolutional Neural Networks
Inception-v1(GoogLeNet):Going deeper with convolutions
VGGNet:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
Inception-v2(BN-Inception):Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception-v3:Rethinking the Inception Architecture for Computer Vision
ImageNet Large Scale Visual Recognition Challenge
愿做一名普普通通的知识传播者。