传感器融合sensor fusion
自动控制系统中的传感器融合
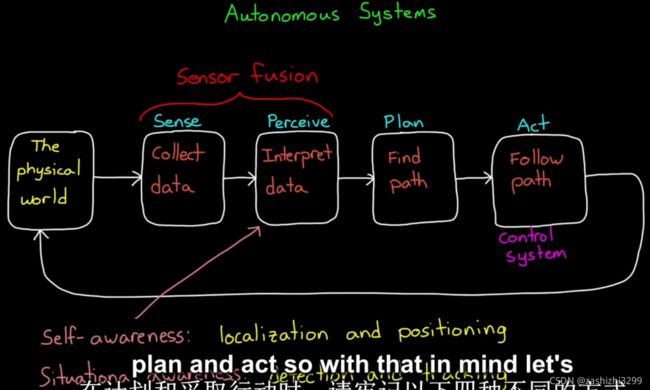
传感器融合的4个作用:
- 1、增加数据质量。比如减少噪声;
- 2、增加可靠性。多传感器互为备份;
- 3、估计预测状态;
- 4、可增加被测范围。相对于单个传感器来说,多传感器产生一个相关系统coherent system。
例1:测量加速度。将加速度传感器放在桌上,因为存在噪声,度数在9.8m/s2附近波动。多个传感器取平均值可将噪声降低。另外,多个传感器还能增加可靠性。

例2:用两种不同的传感器,减少噪声。手机中两种用于测量方向的功能,磁体mag和带有角速度传感器陀螺仪的磁力计gyro。
磁体测量结果通过低通滤波器LPF可减少噪声。两个不同传感器通过传感器融合减少噪声。

例3:测量飞机速度。飞机上有两种测量速度的传感器方案,多个皮托管和GPS大气风速模型估算空速。当一个皮托管不工作时依靠其他皮托管,所有皮托管都失效时,依靠GPS测速。

例4:雷达测量船只速度。当有其他物体挡住被测船只时,可通过之前测量数据建立模型,估算船速和距离。

例5:相机测距。一个相机无法测距,远处的大物体和近处的小物体有相同的像素。

例6:利用惯性传感器融合的方向估计,传感器融合算法实例。将惯性测量单元mpu9250(包含三个传感器,加速度计accelerometer、磁力计magnetometer、陀螺仪gyro),通过I2C总线连接到开源硬件arduion平台,arduion通过usb连接到电脑matlab。
使用单个acc惯性传感器存在的问题:
1、acc不止测量重力加速度,还对线性加速度敏感。对此问题的解决方法如图,当线性加速度是系统已知动作时,可用系统模型估计方法消除偏差;
2、当acc没有安装在物体的重心处,还会受到离心力,影响数据。

使用单个mag传感器存在的问题:
1、地球上不同地区的磁力线分布不同,磁针指示的位置不一定朝北;
2、mag会受到周围磁体的干扰,分为硬磁体和软磁体。硬磁体能够产生磁场,如磁铁和通电线圈,如图蓝色箭头表示地球磁场方向、绿色箭头表示硬磁体方向,他们的合成磁场为红色箭头,红圆代表没有硬磁体影响的磁场,随着绿色箭头的大小方向改变,实际测量结果轨迹为圆中心沿着绿色箭头偏移的大小相同的圆;软磁体是扭曲磁场分布的物体,比如任何金属,当磁力计旋转时,软磁体对于测量结果的影响是让正圆扭曲成了椭圆。

mag calibration校准系统的作用就是校准这些软硬磁体的影响。绿圆表示完美系统磁场,红圆表示在软硬磁体共同影响下的实际测量磁场。测量实际磁场,再结合系统原磁场数据,通过矩阵反变换,得到矫正过的mag,这样矫正过的mag测量的数据即为实际数据。

使用单个gyro惯性传感器存在的问题:gyro工作原理如图。
1、需要知道初始角度;2、误差随着积分不断扩大。

两种方向估计的方案:acc+mag 和 gyro,优缺点如图
acc+mag:优点提供绝对测量值,缺点容易受到扰动;
gyro:优点提供相对测量值,缺点需要初始状态和随时间累计误差。
两种方案结合的算法:互补、卡尔曼滤波、其他滤波。原理都是,设置滤波器初始值,在过程中根据磁场和地球引力不断纠正误差漂移。

例7:融合GPS+IMU定位/测速/方向估计方案。matlab传感器融合实例《pose estimation from asynchronous sensors》,比较不同传感器组合测量下的位置估计。

IMU和GPS的传感器融合算法使用EKF扩展卡尔曼滤波器。EKF适用于目标跟踪。

例8:使用IMM滤波器跟踪单个对象interacting multiple model filter。matlab传感器融合实例《pose estimation from asynchronous sensors》。如图是物体运动轨迹,分为3段共100s,200m/s直线匀速运动、10deg/s匀速转弯、3m/s^2之线加速度运动。本例证明多(本例3个)传感器滤波器IMM目标估计强于单个传感器滤波器。

滤波器性能评价指标:(3个方向的)归一化距离normalized distance。多滤波器模型比单个滤波器噪声更低(归一化距离越接近零表示跟踪性能越好)。

多滤波器模型原理,对不同的运动状态用不同的滤波器。
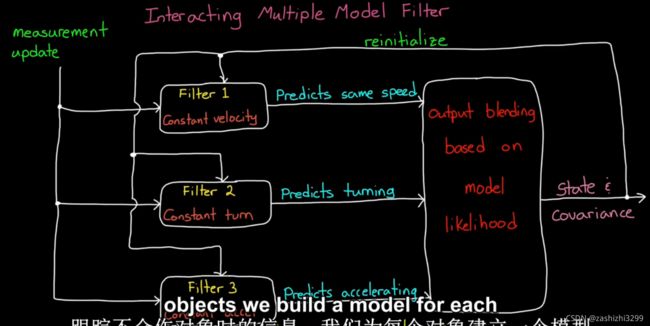
单个滤波器的问题在于噪声对于估计的影响。下图是某单个滤波器(constant velocity)在不同噪声设置下的归一化距离,当噪声设置低时,在匀速阶段的误差很小,在圆周和加速阶段误差大;当噪声设置高时,在圆周和加速阶段误差减小,但匀速阶段的误差提高。这样就失去了这个滤波器的特点(匀速时估计状态准确),所以对于不同阶段设置不同滤波器很有必要。

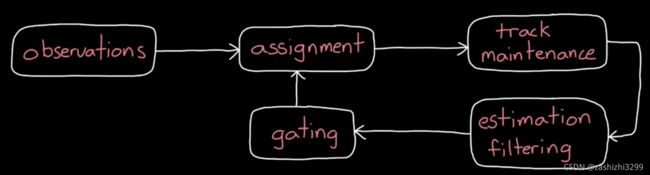
例9:如何一次跟踪多个对象。实质是data association数据关联问题和track maintenance跟踪轨迹维护问题。困难:多个对象无法区分、对象活动重叠、对象数量一直变化。
原理如图:首先观察observations物体各种属性,然后assignment将观察数据分配给某个或多个轨道,分配算法比如GNN全局最近邻global nearest neighbor和JPDA联合概率数据互联Joint Probability Distribution Adaptation,GNN适用于稀疏分布对象sparely distributed objects,JPDA适用于杂散分布对象cluttered objects。然后track maintenance判断所有轨道是否存在,增加或删除轨道。然后运行滤波器,与例8相同对每一个轨道使用组合滤波器IMM,跟踪目标。gating选通与轨道极不相关的数据抛弃。
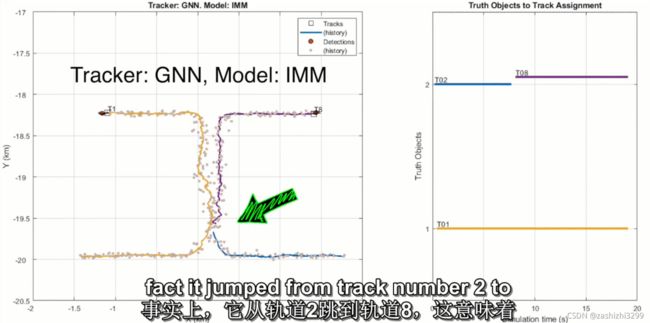
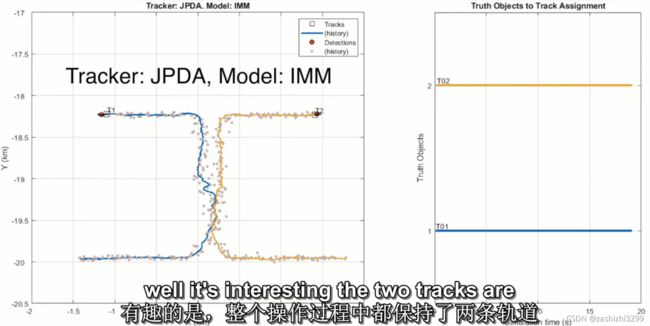
举例,两个独立物体分别移动,方向如图从下往上沿直线移动,中间路程很接近,。GNN算法表现:在稀疏时表现良好,当两物体接近时,GNN跟踪的轨道2丢失,并创建到轨道8才确认轨道。JPDA算法表现:一直维持两个独立轨道,虽然在两个物体接近时轨道有错误,且算法消耗大。
例10:轨道级融合track-level fusion。
例11:IMU在自动驾驶中的应用。
百度Apollo自动驾驶定位方案

例12:无人机目标跟踪
tukfiui


《汽车传感器融合与非线性滤波器》课程安排
《Sensor Fusion and Non-linear Filtering for Automotive Systems》
你会学到什么
- 贝叶斯统计和递归估计理论基础
- 描述和建模常见传感器及其测量值
- 比较用于定位的典型运动模型,以了解在实际问题中何时使用它们
- 描述卡尔曼滤波器(KF)的基本特性,并将其应用于线性状态空间模型
- 在Matlab中实现关键的非线性滤波器,以解决非线性运动和/或传感器模型的问题
- 通过分析应用程序中的特性和要求,选择合适的过滤方法
教学大纲
- 第1节-统计学导论和入门
- 第2节-贝叶斯统计(第1周)
- 第3节-状态空间模型和最佳过滤器(第1周)
- 第4节-卡尔曼滤波器及其特性(第2-3周)
- 第5节-运动和测量模型(第2-3周)
- 第6节-非线性滤波(第4周)
- 第7节-粒子过滤器(第5周)
传感器信息融合方向
New material involves extensions into service-oriented networks and data mining to expand applicability to the dynamic growing field of information technology; automated detection fusion that adapts decision thresholds based on the variable performance of multiple sensors; an introduction of particle filtering, which provides a look into the background theories that gave rise to this important direction in target tracking; random set theory, which has been completely rewritten to provide an extensive development of this generalization of Bayesian and non-Bayesian approaches; situation and impact assessment theory and concepts, which have been significantly extended to build on research directions that have been previously glossed over; new techniques in visualization that have been developed; and finally, a new chapter in commercial off-the-shelf (COTS) software tools, which provides the reader with a wealth of fusion research tools and techniques.
面向服务的网络和数据挖掘的扩展,以扩大信息技术动态增长领域的适用性;自动检测融合,根据多个传感器的可变性能调整决策阈值;粒子滤波提供了一个背景理论,提供目标跟踪这一重要方向的研究;改写的随机集理论,以提供这种贝叶斯和非贝叶斯方法的推广的广泛发展;形势和影响评估理论和概念大大扩展;新可视化技术;新的软件为读者提供了融合研究的工具。
传感器信息融合三个等级
可用于多传感器数据的三种基本方案:(1)传感器数据的直接融合;(2) 通过特征向量表示传感器数据,随后融合特征向量;或(3)对每个传感器进行处理,以实现随后组合的高级推断或决策。
如果多传感器数据相称(即,如果传感器测量相同的物理现象,如两个视觉图像传感器或两个声学传感器),则可以直接组合原始传感器数据。原始数据融合技术通常涉及经典的估计方法如卡尔曼滤波。该领域的挑战涉及密集目标环境、快速机动目标或复杂信号传播环境(例如,涉及多径传播、同信道干扰或杂波)的情况。然而,对于动态性能良好(即动态可预测)的目标,在良好的信噪比环境中进行单目标跟踪是一个简单、易于解决的问题。
特征级融合涉及从传感器数据中提取具有代表性的特征。特征提取的一个例子是漫画家使用关键面部特征来表示人脸。这种在政治讽刺作家中流行的技巧利用关键特征唤起对著名人物的认可。有证据证实,人类利用基于特征的认知功能来识别物体。在多传感器特征级融合的情况下,从多个传感器观测值中提取特征,并将其组合成单个串联特征向量,作为模式识别技术(如神经网络、聚类算法或模板方法)的输入。迄今为止,目标识别一直由基于特征的方法主导,其中特征向量(传感器数据的表示)被映射到特征空间,希望基于特征向量相对于先验确定的决策边界的位置来识别目标。流行的模式识别技术包括神经网络、统计分类器和向量机方法。尽管有许多技术可用,但这些方法的最终成功取决于良好特性的选择。好的特征在特征空间中提供了极好的类可分性,而坏的特征则导致多类目标的特征空间区域严重重叠。需要在这一领域进行更多的研究,以指导特征的选择,并结合关于目标类的显式知识。
决策级融合在每个传感器初步确定实体的位置、属性和身份后,结合传感器信息。决策级融合方法的示例包括加权决策方法(投票技术)、经典推理、贝叶斯推理和Dempster–Shafer方法。这些领域相对不成熟,有许多原型,但很少有稳健的操作系统。该领域的主要挑战是建立一个可行的规则、框架、脚本或其他方法知识库,以表示态势评估或威胁评估方面的知识。不幸的是,只有原始的认知模型可以复制这些功能的人类表现。在开发用于自动态势评估和威胁评估的可靠和大规模的基于知识的系统之前,需要进行大量的研究。提供希望的新方法是使用模糊逻辑和混合架构,将黑板系统的概念扩展到分层和多时间尺度方向。
对于单传感器操作,运筹学和控制理论的技术已被应用于开发有效的系统,即使对于复杂的单传感器,如相控阵雷达。相比之下,涉及多个传感器、外部任务约束、动态观测环境和多个目标的情况更具挑战性。迄今为止,在尝试建模和合并任务目标和约束以平衡优化性能与有限资源(如计算能力和通信带宽(如传感器和处理器之间))以及其他影响方面遇到了相当大的困难。效用理论的方法正被应用于制定系统性能和有效性的衡量标准。正在为基于上下文的近似推理开发基于知识的系统。智能、自校准传感器的出现将带来重大改进,这些传感器可以准确、动态地评估自身的性能。分布式网络中心环境的出现,其中传感资源、通信能力和信息请求非常动态,给4级融合带来了严重挑战。在这样的环境中很难(或可能不可能)优化资源利用率。在最近的一项研究中,Mullen等人5应用了基于市场的拍卖的概念来动态分配资源,将传感器和通信系统视为服务供应商,将用户和算法视为消费者,以快速评估如何分配系统资源以满足信息消费者的需求
多目标跟踪
跟踪大量目标的任务异常困难,难度与物体数量的平方成正比;因此,10个对象需要100倍的努力,10000个对象会增加1亿倍的难度。这种组合爆炸是解决多目标跟踪问题的第一个障碍。
基于雷达系统等传感器的一系列位置报告,可以跟踪单个物体的运动。要重建对象的轨迹,按顺序绘制连续位置,然后画一条线穿过它们,延伸这条线可以预测物体的未来位置。假设同时跟踪10个目标,定期收到10份新位置报告,但这些报告没有指示其对应目标的标签。绘制10个新位置时,原则上,每个报告可以与10条现有轨迹中的任何一条相关联。需要考虑每个可能的报告和轨道组合,使得所有n个目标问题的难度成正比于或按n^2的顺序,这被表示为O(n^2)。
多年来,人们一直试图设计一种性能优于O(n^2)的多目标跟踪算法。一些方案在特殊情况下或在多目标跟踪问题的某些情况下提供了显著的改进,但它们保留了O(n^2)最坏情况下的行为。然而,空间数据结构理论spatial data structures的最新结果使得一类新的算法成为可能,用于将位置报告与跟踪算法关联,在大多数现实环境中,这种算法的伸缩性优于二次伸缩。在退化情况下,所有目标都密集聚集,无法单独解析,因此无法避免将每个报告与每个轨迹进行比较。当每个报告平均只能与恒定数量的轨迹相关联时,可以实现次二次缩放。
即使是单目标跟踪也存在与位置测量固有的不确定性相关的某些挑战。第一个问题涉及决定如何表示这种不确定性。粗略的方法是定义位置估计周围的误差半径。这种做法意味着发现目标的概率均匀分布在三维球体的整个体积内。不幸的是,这种简单的方法远远不是最优的。与许多传感器相关的误差区域是高度非球形的;例如,雷达倾向于提供精确的距离信息,但径向分辨率相对较差。此外,人们期望目标的实际位置平均更接近平均位置估计值,而不是误差体积的周长,这反过来表明,靠近中心的概率密度应该更大。处理不确定性的第二个困难是确定如何从多个测量值中插值目标的实际轨迹,每个测量值都有自己的误差余量。对于已知具有恒定速度的目标(例如以恒定速度沿直线移动),有一些方法可用于计算射弹直线路径,通过某种测量,这些方法最适合过去位置序列。这种方法的一个可取特性是,随着报告数量的增加,它应始终收敛于正确的路径,估计速度和实际速度之间的差值应接近零。但是,保留目标的所有过去报告并在每次新报告到达时重新计算整个轨迹是不切实际的。这种方法最终将超过计算时间和存储空间的所有限制。
1960年,Kalman提出了一种解决一大类跟踪问题的近似最优方法。他的方法被称为卡尔曼滤波,涉及到噪声测量的递归融合,以产生对感兴趣系统状态的准确估计。卡尔曼滤波器的一个关键特征是其状态估计的平均向量和误差协方差矩阵表示,其中协方差矩阵提供了与平均估计相关的误差分布二阶矩的估计(通常是保守的高估)。估计协方差的平方根给出了标准偏差的估计值。如果测量误差序列在统计上是独立的,则卡尔曼滤波器产生一系列保守的融合估计值,误差协方差减小。
到目前为止,跟踪过程中最重要的误差来源是现有传感器的分辨率有限。这一事实强化了人们的普遍看法,即有效跟踪的主要障碍是传感器报告的质量相对较差。大量目标的影响似乎是可控的,只需建造更大、更快的计算机。尽管研究界的许多人不这么认为
卡尔曼滤波
卡尔曼滤波(Kalman filtering)一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。一句话概括卡尔曼滤波的思想:根据上一时刻的状态,预测当前时刻的状态,将预测的状态与当前时刻的传感器测量值(由于存在传感器噪声其值并不可信)进行加权更新,更新后的结果为最终的追踪结果。简单来说,卡尔曼滤波器是一个“optimal recursive data processing algorithm(最优化自回归数据处理算法)”。对于解决很大部分的问题,它是最优,效率最高甚至是最有用的。Kalman滤波在测量方差已知的情况下能够从一系列存在测量噪声的数据中,估计动态系统的状态。由于,它便于计算机编程实现,并能够对现场采集的数据进行实时的更新和处理, Kalman滤波是目前应用最为广泛的滤波方法,在通信、导航、制导与控制等多领域得到了较好的应用。
卡尔曼滤波是多源传感数据融合应用的重要手段之一,为了扼要地介绍卡尔曼滤波的原理,此处形象地用毫米波雷达与视觉感知模块融合目标位置的过程描述。举一个简单的例子,目前高级辅助驾驶系统(Advanced Driver Assistance System,ADAS)上,搭载有毫米波雷达和超声波雷达模块,两者均能对障碍物车辆进行有效的位置估计判别。雷达利用主动传感原理,发射毫米波,接收障碍物回波,根据波传播时间计算角度距离。两者均能识别出车辆位置,那么我们该如何融合信息,如何取舍,计算出具体的车辆位置呢?卡尔曼正是解决这个问题的方法之一。我们获取的车辆位置在任何时刻都是有噪声的,卡尔曼滤波利用目标的动态信息,设法去掉噪声的影响,得到一个关于目标位置的好的估计。这个估计可以是对当前目标位置的估计(滤波),也可以是对于将来位置的估计(预测),还可以是对过去位置的估计(插值或平滑)。卡尔曼滤波就是这样一个根据当前时刻目标的检测状态,预测估计目标下一时刻目标检测状态的一个动态迭代循环过程。
激光雷达可直接使用线性卡尔曼来进行障碍物跟踪;而毫米波雷达则需要使用非线性卡尔曼来进行物体跟踪。举例:动手学无人驾驶(5):多传感器数据融合_10点43的博客-CSDN博客_无人驾驶多传感器融合 https://blog.csdn.net/cg129054036/article/details/108038376
扩展的卡尔曼滤波
(1)在只有IMU数据时(此时GPS还未有输出产生),IMU数据经过运动模型,得到预测状态;然后预测状态传送回运动模型,继续下一步预测;
(2)当有GPS数据产生时,上一时刻产生的预测状态将会和接收到的GPS位置信息进行数据融合,得到修正后的状态。然后再传回运动模型,进行下一周期的运算。
举例:动手学无人驾驶(6):基于IMU和GPS数据融合的自车定位_10点43的博客-CSDN博客_gps和imu数据融合 https://blog.csdn.net/cg129054036/article/details/109964103

误差卡尔曼滤波
误差卡尔曼滤波数学基础:四元数
论文:《Quaternion kinematics for the error-state Kalman filter》2017
使用误差卡尔曼滤波的原因:
- 方向误差状态极小(和自由度有相同的参数数量),能够避免过度参数化以及由此产生的协方差矩阵奇异的风险。
- 误差状态系统始终在接近原点的位置运行,因此远离可能的参数奇异性,万向节锁定问题等,从而保证了线性化有效性始终不变。
- 误差状态量始终很小,这意味着所有二阶项都可以忽略不计。 这使得Jacobian的计算非常容易和快速。
- 误差状态量动态变化缓慢,因为所有的 large-signal 动态变化已经被包含在名义状态里了。因此,在卡尔曼滤波过程中,相较于预测过程,可以以更低的频率来执行更新过程。
在文中作者对误差状态卡尔曼滤波还做了如下解释:
- 在误差状态卡尔曼滤波中,会讨论到三种状态量:真值状态,名义状态和误差状态,真值状态由名义状态和误差状态组合表示(如线性组合,四元数乘积或矩阵乘积方式等)。其思想是将名义状态视为 large-signal(以非线性方式可积分),将误差状态视为 small-signal(线性可积分并适用于线性高斯滤波)。
- 在使用IMU进行定位时,高频IMU数据被积分到名义状态中。名义状态未考虑噪声,结果它会积累误差。误差状态通过误差状态卡尔曼滤波进行估计,包含了所有的噪声和扰动。误差状态由小幅度的信号组成,其更新函数由线性动态系统定义,其动态、控制和测量矩阵均由名义状态的值计算得出。误差状态卡尔曼修正是在其它传感器信息(例如GPS,视觉等)到达时执行的。
相机和激光雷达数据融合
激光雷达和摄像头的数据融合,实际是激光雷达点云投影在摄像头图像平面形成的深度和图像估计的深度进行结合,理论上可以将图像估计的深度反投到3-D空间形成点云和激光雷达的点云融合,但很少人用。原因是,深度图的误差在3-D空间会放大,另外是3-D空间的点云分析手段不如图像的深度图成熟,毕竟2.5-D还是研究的历史长,比如以前的RGB-D传感器,Kinect或者RealSense。两种传感器优缺点:图像传感器成本低,分辨率高(可以轻松达到2K-4K);激光雷达成本高,分辨率低,深度探测距离短。可是,激光雷达点云测距精确度非常高,测距远远大于那些Infrared/TOF depth sensor,对室外环境的抗干扰能力也强,同时图像作为被动视觉系统的主要传感器,深度估计精度差,更麻烦的是稳定性和鲁棒性差。所以,把激光雷达的稀疏深度数据和致密的图像深度数据结合形成互补。
稀疏的深度图如何upsample变得致密,这也是一个已经进行的研究题目,类似image-based depth upsampling之类的工作。还有,激光雷达得到的点云投到摄像头的图像平面会发现,有一些不反射激光的物体表面造成“黑洞”,还有远距离的街道或者天空区域基本上是没有数据显示,这样就牵涉到另一个研究题目,image-based depth inpainting / completion。
解决这个问题的前提是,激光雷达和摄像头的标定和同步是完成的,所以激光雷达的点云可以校准投影到摄像头的图像平面,形成相对稀疏的深度图。
传感器融合层次:数据层和任务层。数据层直接将雷达3d云转换为2d图像,做图像融合;任务层根据任务(障碍物检测、定位等)将不同传感器的检测结果融合。不同传感器获取的数据类型:
- 摄像头是RGB图像的像素阵列;
- 激光雷达是3-D点云距离信息(有可能带反射值的灰度值);
- GPS-IMU给的是车身位置姿态信息;
- 雷达是2-D反射图。
数据层融合思路
- 先是坐标对齐,将雷达坐标转换到相机坐标。由相机捕获的图像数据由(U,V)表示,激光雷达捕获的3维点阵云用(X,Y,Z)表示,建立一个转化矩阵M,将3维点(x,y,z)映射到2维点(u,v)
- 然后将激光点往像平面投影,得到投影到像平面的点云。
- 借助图像检测的框图(前面提到的YOLOv3检测)对点云实现过滤聚类。
- 对聚类点后处理。
激光雷达和摄像头的数据融合,实际是激光雷达点云投影在摄像头图像平面形成的深度和图像估计的深度进行结合,理论上可以将图像估计的深度反投到3-D空间形成点云和激光雷达的点云融合,但很少人用。原因是,深度图的误差在3-D空间会放大,另外是3-D空间的点云分析手段不如图像的深度图成熟,毕竟2.5-D还是研究的历史长,比如以前的RGB-D传感器,Kinect或者RealSense。
其他深度学习方法:
- “Propagating Confidences through CNNs for Sparse Data Regression“, 提出normalized convolution (NConv)layer的改进思路,训练的时候NConv layer通过估计的confidence score最大化地融合 multi scale 的 feature map
- ICRA的论文High-precision Depth Estimation with the 3D LiDAR and Stereo Fusion,只是在合并RGB image和depth map之前先通过几个convolution layer提取feature map
- 法国INRIA的工作,“Sparse and Dense Data with CNNs: Depth Completion and Semantic Segmentation”作者发现CNN方法在早期层将RGB和深度图直接合并输入性能不如晚一些合并(这个和任务层的融合比还是early fusion),这也是它的第二个发现,这一点和上个论文观点一致。
归纳深度学习的工作:都是从暴力训练的模型开始,慢慢加入几何约束,联合训练。拖延RGB和depth合并的时机是共识,分别训练feature map。
传统方法
把任务看成一个深度图内插问题,方法类似SR和upsampling,只是需要RGB图像的引导image-guided。实现这种图像和深度之间的结合,需要的是图像特征和深度图特征之间的相关性,这个假设条件在激光雷达和摄像头传感器标定和校准的时候已经提到过,这里就是要把它应用在pixel(像素)/depel(深度素)/surfel(表面素)/voxel(体素)这个层次。基本上,技术上可以分成两种途径:局部法和全局法。这样归纳,和其他几个经典的计算机视觉问题,如光流计算,立体视觉匹配和图像分割类似。图像滤波的历史:均值滤波-》高斯滤波-》中值滤波-》Anisotropic Diffusion -》Bilateral滤波(等价于前者)-》Non Local Means滤波-》BM3D,这些都是局部法。Joint Bilateral Filtering,还有著名的Guided image filtering,在这里都可以发挥作用。全局法就是MRF,CRF,TV(Total variation),dictionary learning 和 Sparse Coding之类。
激光雷达的深度图是稀疏的
目的是从输入的稀疏深度图生成密集的深度图。深度完整(depth completion)的目标是从稀疏、不规则、映射到2D平面的点云生成密集的深度预测。通常,卷积神经网络(CNN)可在规则网格上处理数据,即普通相机数据。设计用于稀疏和不规则间隔输入激光雷达数据的CNN仍然是一个开放的研究问题。
“HMS-Net: Hierarchical Multi-scale Sparsity-invariant Network for Sparse Depth Completion ”2018
常规做法稀疏不变卷积的CNN只能逐渐对特征采样后失去大量分辨率;提出的稀疏不变编码器-解码器网络可以有效地融合来自不同层的多尺度特征做深度完整。有效利用多尺度特征,提出3种稀疏性不变(sparsity-invariant)操作。可以合并其他RGB特征,进一步提高深度完整系统的性能。
“Sparse and noisy LiDAR completion with RGB guidance and uncertainty”2019
提出新方法,可以精确地完整化RGB图像引导的稀疏激光雷达深度图。一方面,单目深度预测方法无法生成绝对且精确的深度图。另一方面,基于激光雷达的方法仍然明显优于立体视觉方法。
提出框架,同时提取全局和局部信息生成适当的深度图。简单的深度完整并不需要深度网络。但是,该文提出一种融合方法,由单目相机提供RGB指导,利用目标信息并纠正稀疏输入数据的错误,这样大大提高了准确性。此外,利用置信度掩码考虑来自每种模态深度预测的不确定性。
“3D LiDAR and Stereo Fusion using Stereo Matching Network with Conditional Cost Volume Normalization”2019
主动和被动深度测量技术的互补特性促使激光雷达传感器和立体双目相机融合,以改善深度感知。作者不直接融合激光雷达和立体视觉模块来估计深度,而是利用带两种增强技术的立体匹配网络:激光雷达信息的输入融合和条件成本容积归一化(Conditional Cost Volume Normalization,CCVNorm)。 所提出的框架是通用的,并且紧密地与立体匹配神经网络中成本容积组件集成。
《Scalable Primitives for Generalized Sensor Fusion in Autonomous Vehicles》
在自动驾驶领域,深度神经网络在感知、预测和规划任务中得到应用。随着自动驾驶汽车(AVs)越来越接近生产水平,多模式传感器输入和不同传感器平台得异构车队在行业中变得越来越普遍。然而,神经网络结构通常针对特定的传感器平台,对输入的变化不具有鲁棒性,这使得规模化和模型部署问题特别困难。此外,大多数玩家仍然将优化软件和硬件的问题视为完全独立的问题。
这里作者提出了一种端到端架构,即广义传感器融合(GSF),其设计方式是传感器输入和目标任务均是模块化和可修改。这使AV系统设计人员能够轻松试验不同的传感器配置和方法,并把大型工程组织共享的相同模型在异构车队上部署。其实验结果展示了昂贵的高密度(HD)激光雷达传感器与廉价的低密度(LD)激光雷达加摄像机装置在3D目标检测任务中的近似等价性。这为业界共同设计硬件和软件架构以及建立异构配置的大型车队铺平了道路。
多传感器标定
另外在自动驾驶研发中,GPS/IMU和摄像头或者激光雷达的标定,雷达和摄像头之间的标定也是常见的。不同传感器之间标定最大的问题是如何衡量最佳,因为获取的数据类型不一样。这样的话,实现标定误差最小化的目标函数会因为不同传感器配对而不同。
另外,标定方法分targetless和target两种,前者在自然环境中进行,约束条件少,不需要用专门的target;后者则需要专门的控制场,有ground truth的target,比如典型的棋盘格平面板。
targetless方法的若干算法:
1、手-眼标定(Hand-Eye Calibration)。
这是一个被标定方法普遍研究的,一定约束条件下的问题:可以广义的理解,一个“手”(比如GPS/IMU)和一个“眼”(激光雷达/摄像头)都固定在一个机器上,那么当机器运动之后,“手”和“眼”发生的姿态变化一定满足一定的约束关系,这样求解一个方程就可以得到“手”-“眼”之间的坐标转换关系,一般是AX=XB形式的方程。手眼系统分两种:eye in hand和eye to hand,自动驾驶是前者,即手-眼都在动的情况。手眼标定分两步法和单步法,后者最有名的论文是“hand eye calibration using dual quaternion"。一般认为,单步法精度高于两步法,前者估计旋转之后再估计平移。
东京大学的论文《LiDAR and Camera Calibration using Motion Estimated by Sensor Fusion Odometry》来看看激光雷达和摄像头的标定算法。求解激光雷达的姿态变化采用ICP,而摄像头的运动采用特征匹配。后者有一个单目SFM的scale问题。SFM(Structure From Motion)从运动摄像机拍摄的多幅二维图像中估计摄像机运动和重建场景结构,是计算机视觉领域中的一个核心问题,被称为从运动恢复结构问题。论文提出了一个基于传感器融合的解法:初始估计来自于无尺度的摄像头运动和有尺度的激光雷达运动;之后有scale的摄像头运动会在加上激光雷达点云数据被重新估计。最后二者的外参数就能通过手-眼标定得到。这个方法无法在室外自然环境中使用,因为点云投影的图像点很难确定。
关于如何优化激光雷达-摄像头标定的论文,不是通过3-D点云和图像点的匹配误差来估计标定参数,而是直接计算点云在图像平面形成的深度图,其和摄像头获取的图像存在全局匹配的测度。不过这些方法,需要大量迭代,最好的做法是根据手眼标定产生初始值为好。
2、IMU-摄像头标定
德国Fraunhofer论文“INS-Camera Calibration without Ground Control Points“。虽然是给无人机的标定,对车辆也适合。IMU-摄像头标定和激光雷达-摄像头标定都是类似的,先解决一个手眼标定,然后优化结果。只是IMU没有反馈信息可用,只有姿态数据,所以就做pose graph optimization。其中摄像头还是用SFM估计姿态。
3、激光雷达系统标定
牛津大学论文“Automatic self-calibration of a full field-of-view 3D n-laser scanner".本文定义点云的“crispness” 作为质量测度,通过一个熵函数Rényi Quadratic Entropy (RQE)最小化作为在线标定激光雷达的优化目标。作者还讨论了激光雷达的时钟偏差问题解决方案。
4、基于深度学习的多传感器标定
以深度学习的方法训练CNN模型去回归坐标系转换的参数。主要是两个CNN模型:RegNet和CalibNet。
RegNet应该是第一个深度卷积神经网络(CNN)推断多传感器的6自由度(DOF)外参数标定,即激光雷达(LiDAR)和单目摄像头。RegNet将标定的三个步骤(特征提取、特征匹配和全局回归)映射到单个实时CNN模型中。在训练期间,随机对系统进行重新调整,以便训练RegNet推断出激光雷达投影到摄像头的深度测量与RGB图像之间的对应关系,并最终回归标定外参数。此外,通过迭代执行多个CNN,在不同程度失标定数据上进行训练。
CalibNet是一个自监督的深度网络,能够实时自动估计激光雷达和2D摄像头之间的6-自由度刚体转换关系。在训练时,不进行直接监督(例如不直接回归标定参数);相反,可以训练网络去预测标定参数,以最大化输入图像和点云的几何和光度一致性。CalibNet的流程:(a)来自标定摄像头的RGB图像;(b)原始激光雷达点云作为输入,并输出最佳对齐两个输入的6-自由度刚体变换T;(c)显示错误标定设置的彩色点云输出;(d)显示使用CalibNet网络标定后的输出。
融合算法PointPainting: Sequential Fusion for 3D Object Detection
数据级融合。在融合网络结构设计上并非end-to-end训练方式,分成了2个阶段
- 第一阶段,对camera数据做语义分割
- 第二阶段,将激光雷达点云与语义信息相结合做3D目标检测。通过特征投影将两个阶段联系起来,也就是图中的第二步:Point Painting。
这个投影过程也分为两步,首先在源数据上建立点云与图像像素间的对应关系,这个对应关系可以通过多传感器的标定参数计算得到:P(camera)=K*T*P(lidar),其中K为相机的内参,T为lidar到camera的标定参数,如下式,由于不同传感器获得数据是有一些时间差,通过自车的定位信息做出补偿即可。第二步则在此对应关系的基础上,将语义分割网络的输出与点云特征concatenate,得到3D目标检测网络的输入。
融合算法LaserNet++:Sensor Fusion for Joint 3D Object Detection and Semantic Segmentation
数据级融合。LaserNet++设计了一个end-to-end的融合网络,分别用两个网络来提取camera数据与lidar点云的特征,然后通过特征投影,将两种特征通过相加的方式组合成新的特征,再使用laserne完成3D目标检测。
投影过程也是分为两步,首先在源数据上建立camera/range view图像与图像像素的对应关系,然后再利用对应关系得到两种传感器相对应的特征。Lasernet++在做点云特征提取时,使用了camera/rang view的表达方式,因此,建立点云与图像像素对应关系也分为两步:
- 计算点云与range view图像的对应关系
- 计算点云与图像像素的对应关系,如下式,其中(u,v)为图像坐标,p为点云坐标,K为相机内参,R和t为从lidar坐标到camera坐标变换的旋转矩阵和平移矩阵。
融合算法ContFusion:Deep Continuous Fusion for Multi-Sensor 3D Object Detection
是一个end-to-end网络,分成了4个部分:camera特征提取、特征融合、lidar特征提取、检测输出。这种设计的好处就是可以dense的融合两种信息,但是问题也很明显,效率不怎么高。
特征投影关系的建立整体上来说分成2大步:建立源数据投影关系、提取融合特征。分成了5步:
- 作者在lidar特征提取时使用了bev表达,我们知道bev上的像素点与点云并不是一一对应的,bev图是很稀疏的,因此作者使用了KNN的方式,获得bev图上每一个像素对应的K个点云
- 将bev图下得到的k个最近邻的点反投影回点云坐标
- 建立点云点与图像像素的对应关系,建立方式和单阶段融合的方式相同
- 由于lidar点投影到图像素坐标为浮点数,因此需要通过插值得到投影点的特征向量
- 通过mlp得到图像特征与几何特征的融合特征,计算方式如下式所示,其中fj为j点的图像特征,x为点云3D坐标,xj-xi为j点与目标点i点距离差。最后hi与lidar点云特征相加得到最终的融合特征。
ContFusion融合方式中KNN的参数选取很关键,k值和d值对最终结果影响较大,k和d都不易太大,太大会融合远处点云点的信息,干扰当前点的特征表达,模型效果变差。
融合技术中的两个核心问题
以上针对融合阶段这种分类方式对多传感器融合技术做了简单的分析,重点分析了多传感器融合技术中的两个核心问题:数据/特征投影,融合网络设计。
- 投影方式决定了融合算法能否end-to-end训练,而end-to-end训练能使模型得到更好的结果,如在PointPainting方法中,作者认为由于PointPainting没有使用end-to-end训练,会造成该方法无法得到最好的结果。
- 对于融合网络设计,主要考虑融合特征的提取,或融合方式的设计,是数据/单层特征融合,还是多层特征融合,还是目标级特征融合?正如MV3D中讨论的early fusion、deep fusion、late fusion:deep fusion相对另外两种融合方式在精度上可以提高0.5个百分点,但是在实际应用时,还需要考虑speed vs accuracy平衡的问题。
参考文献:
1、[Matlab官方]了解传感器融合和跟踪_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1fi4y1F7rU/?spm_id_from=333.788.recommend_more_video.0
2、传感器融合的数学基础 [完结] Sensor Fusion 2020 (挪威科技大学)_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1JA411J7XS?p=15
3、P14小迈步之人工智能(四):实战传感器融合与目标限踪 https://www.bilibili.com/medialist/play/ml1238052723/BV1xf4y1i73L?s_eid=PEP_webinarfromILM
4、Sensor Fusion and Non-linear Filtering for Automotive Systems | edX https://www.edx.org/course/sensor-fusion-and-non-linear-filtering-for-automot?index=product&queryID=1dd0f6fa07927ff922a70bef647ce15b&position=1
5、《Handbook of multisensor data fusion _ theory and practice》
6、多传感器信息融合(标定, 数据融合, 任务融合)_ChenGuiGan的博客-CSDN博客_多传感器信息融合 https://blog.csdn.net/ChenGuiGan/article/details/104960658?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.no_search_link
7、无人驾驶传感器融合系列(十)—— 目标追踪之相机与激光雷达数据融合_默_存的博客-CSDN博客 https://blog.csdn.net/weixin_40215443/article/details/96456408
8、多传感器信息融合(标定, 数据融合, 任务融合)_ChenGuiGan的博客-CSDN博客_多传感器信息融合 https://blog.csdn.net/ChenGuiGan/article/details/104960658?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.no_search_link
9、自动驾驶系统的传感器标定方法 - 知乎 https://zhuanlan.zhihu.com/p/57028341
10、重读经典《Quaternion kinematics for the error-state Kalman filter》_10点43的博客-CSDN博客 https://blog.csdn.net/cg129054036/article/details/119703694
11、用于自动驾驶中广义传感器融合的可规模化设计 - https://zhuanlan.zhihu.com/p/443153723
12、自动驾驶系统的传感器标定方法 - 知乎 https://zhuanlan.zhihu.com/p/57028341
13、基于深度学习的多传感器标定 - 知乎 https://zhuanlan.zhihu.com/p/73073753
14、头条 | 自动驾驶多传感器融合技术浅析 https://mp.weixin.qq.com/s?__biz=MzAwNTMzODc4OA==&mid=2456142764&idx=1&sn=8ebba7511bb63dc0b227f976629e07c7&chksm=8c8f4067bbf8c9712238ff3f53bfdc421380dadea18ade13e40c3d9a9e53c924271616d998c8&token=1575724551&lang=zh_CN#rd
15、多传感器数据深度图的融合:最近基于深度学习的方法 - 知乎 https://zhuanlan.zhihu.com/p/90773462
16、传感器融合-数据篇 - 知乎 https://zhuanlan.zhihu.com/p/109895639
17、传感器融合-任务篇 - 知乎 https://zhuanlan.zhihu.com/p/109900137
18、几个摄像头和雷达融合的目标检测方法 - 知乎 https://zhuanlan.zhihu.com/p/371258127
19、
20、