速通8-DNN神经网络学习笔记
一个模型先看效果再了解原理。不懂原理也可以得到效果。
深度学习原理不是非常清楚,解释性不够强,但是效果比较好。
1980高峰,起始
1995年,SVM/GBDT,深度学习进入低谷
2014-2015,爆发。数据量暴增,计算机性能更好。
二分类LR,大部分线性不可分,处理方式:
- 多项式来搞增加维度
- SVM核方法
- 非线性变换
- 线性变换(例如向量乘以一个矩阵),在空间中表现出来是对一个点进行平移。无法解决线性不可分问题。因为多次线性变换等于一次线性变换。
- 激活函数:如sigmoid函数。对WX进行非线性变换,可以解决线性不可分问题
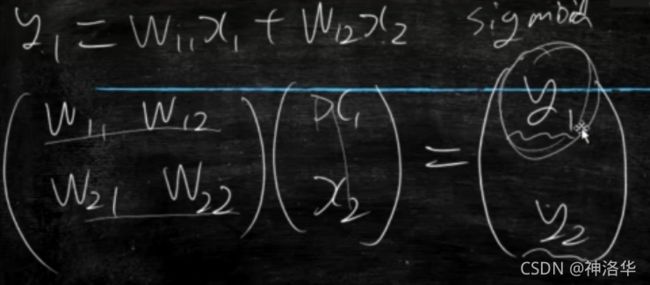
上面矩阵乘法可以改成下面的形式:
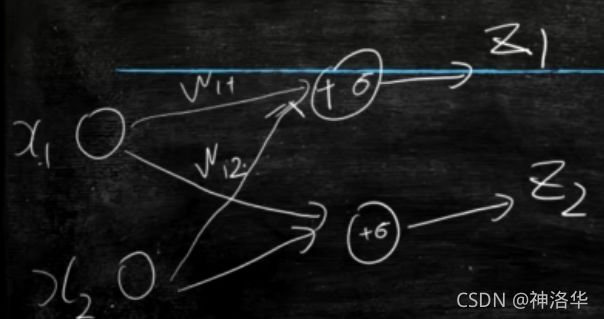
每个小圈将各种信号收集加和,给出反馈结果(比如买不买)。类似人的神经元。因为模型包含很多神经元,互相连接,所以叫神经元。
输出层之前不停地经过一层层神经元,可以理解为对数据不停地进行空间变换。经过这种变换将线性不可分的数据分布改成线性可分。
模型层数不是越多越好。
- 层数越多越容易过拟合
- 数据量少层数也不宜太多
- 层数越多,计算量越大,计算时间变长,对机器内存等要求越高。
一般老说,满足任务,够用就好。比如先设为5层看效果,不行就10层等等。
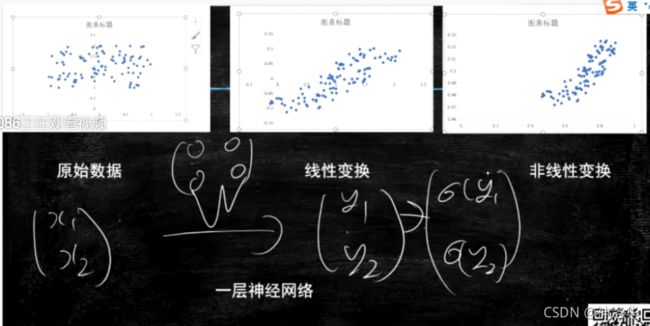
下图演示一层神经网络可以让原始数据进行变换。(破坏噪声,线性变为可分)
大学有特征值和特征向量的概念:(只有方阵有)
W V = λ V WV=\lambda V WV=λV
其中W和V是矩阵, λ \lambda λ是一个数。那么V是特征向量, λ \lambda λ是特征值。二者成对出现。V是几维,就有几对?
下图 λ \lambda λ和V是W的特征值和特征向量,其几何意义是往两个方向将数据增大3倍和缩小到0.6倍。
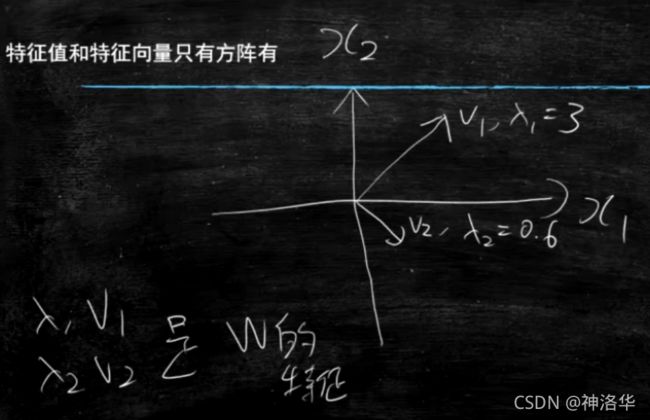

比如两类数据挨得很近,希望在竖直方向可以放大更好分类,平直方向不影响分类可以缩小。
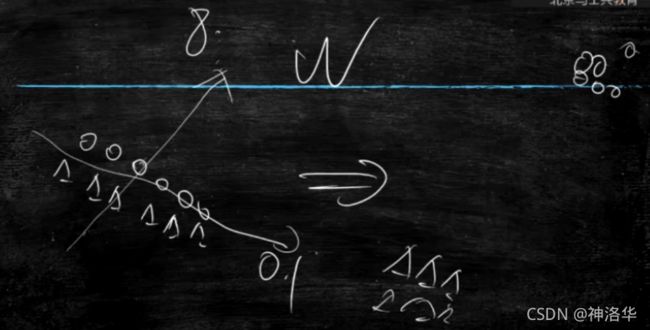
这个是方阵才有特征值和特征向量,及其几何意义。矩阵的话更复杂,不再深究。
多分类不能用sigmoid函数。因为sigmoid只是求一个的概率P,另一类概率自动为1-P。此时要用softmax函数。

参考帖子:《二分类问题,应该选择sigmoid还是softmax函数》。
《详解sigmoid与softmax, 多分类及多标签分类》后面附代码

- softmax等于分别学习w1和w2,而sigmoid等于学这两个的差值就行了。sigmoid是softmax在二分类上的特例。二分类时sigmoid更好。因为我们只关注w1和w2的差值,但是不关心其具体的值。
- softmax的运算量很大,因为要考虑别的概率值。一般只在神经网络最后一层用(多分类时)。中间层神经元各算各的,不需要考虑别的w数值,所以中间层不需要softmax函数。
- CPU:相当于大学教授,可以处理复杂逻辑,但是算术没有明显优势
- GPU:一堆小学生,处理不了复杂逻辑,就会算术。可用在AI、图像(游戏)。挖矿
二、DNN2:编程工具keras讲解和深度学习为什么会有效
2.1为啥训练时样本要shuffle:
- 因为采样可能包含了某种顺序。比如batch_size=8时,不shuffle可能连续8个都是一个人的数据。或者鸢尾花识别时,前面50个都是一种花。这样在一个batch_size梯度会往一个方向走。到下个batch_size是另一类数据,往另一个方向走,梯度震荡,w更新不稳定
- 可能会学习到采样顺序特征,而这个顺序是不需要学习的
2.2 batch_size为啥都是2的n次方?
GPU有基本运算单元,不同型号GPU的基本运算单元数目不一样,但是都是2的n次幂。
假如GPU基本运算单元数=8,batch_size=128时,一次计算可以塞满16个单元。如果不是2的n次幂,就会有一个单元没有塞满,浪费算力。
2.3 代码举例
序贯模型:必须是顺序结构,输入是上一层输出,不能有并列、乱序输入等。
2.3.1 keras序贯模型
# -*- encoding:utf-8 -*-
import keras
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
import random
from keras.models import load_model
def read_data(path):
train_x=[]
train_y=[]
with open(path) as f:
lines=f.readlines()
lines=[eval(line.strip()) for line in lines]
random.shuffle(lines)
d=int(0.95*len(lines))
train_x=[s[0] for s in lines[0:d]]
train_y=[s[1] for s in lines[0:d]]
test_x=[s[0] for s in lines[d:]]
test_y=[s[1] for s in lines[d:]]
return np.array(train_x),np.array(train_y),np.array(test_x),np.array(test_y)
train_x,train_y,test_x,test_y=read_data("data")
model = Sequential()#训练一个序贯模型
model.add(Dense(units=5,input_dim=4,activation='sigmoid'))#input输入层数应该跟x维度一样,激活函数sigmoid
model.add(Dense(units=10,input_dim=4,activation='sigmoid'))#第二层输入数应该等于第一层输出数,也可以不写
model.add(Dense(units=3, activation='softmax'))#最后一层输出数应该等于分类数
model.compile(loss='categorical_crossentropy', optimizer="adam",metrics=['accuracy'])
#定义损失函数和学习方法
print("Starting training ")
h=model.fit(train_x, train_y, batch_size=8, epochs=500, shuffle=True)#开始训练,迭代次数100,每次训练8个样本
#h记录了训练过程中的一些数据,history记录每次迭代误差、精确度准确度等。
score = model.evaluate(test_x, test_y)#score默认只保存loss,写入metrics=['accuracy']表示还保存精确度,score就是二维数据
print(score)
print('Test score:', score[0])#测试集loss函数
print('Test accuracy:', score[1])#准确度
path="model_seq.h5"
model.save(path)#自带save函数保存模型,真正企业里要用的就是这个。
model=None
model=load_model(path)#加载保存的模型
result=model.predict(test_x)#要处理的数据导入模型存入result
print(result)
2.3.2 keras函数式编程
把每一层dense当做一个函数,对输入进行变换。比如feature_input、第一层输出m11等等。最后指定模型的输入和输出。
import keras
import numpy as np
from keras.models import Model
from keras.layers import Dense,Input
from keras import regularizers
def read_data(path):
train_x=[]
train_y=[]
with open(path) as f:
lines=f.readlines()
lines=[eval(line.strip()) for line in lines]
train_x=[s[0] for s in lines]
train_y=[s[1] for s in lines]
#return train_x,train_y
return np.array(train_x),np.array(train_y)
feature_input = Input(shape=(4,))#指定输入为4维数组
m11=Dense(units=5,input_dim=4,activation='relu')(feature_input)#first model,相当于一个函数,对输入进行变换
m12=Dense(units=6, activation='relu')(m11)
m21=Dense(units=5,input_dim=4,activation='relu')(feature_input)#second model,每层相当于一个函数
m22=Dense(units=6, activation='relu')(m21)
m= keras.layers.Concatenate(axis= 1)([m21,m22])#将m21,m22两个模型串联起来,就是两个输出都是6维向量,最终结果是6+6=12维拼接的向量。
output=Dense(units=3, activation='softmax')(m)
model = Model(inputs=feature_input, outputs=output)#指定模型输入输出
model.compile(optimizer='adam', loss='categorical_crossentropy',metrics=["accuracy"])
train_x,train_y=read_data("data")
H=model.fit(train_x, train_y, batch_size=8, epochs=100, shuffle=True)#H表示history,会记录模型训练中的数据,比如每轮迭代的误差和精确度等等
score = model.evaluate(train_x, train_y)#score默认只保存loss,写入metrics=['accuracy']表示还保存精确度,score就是二维数据。写入几个就是几维数组
print(score)
print('Test score:', score[0])#测试集loss函数
print('Test accuracy:', score[1])#准确度
"""path="model_seq.h5"
model.save(path)#自带save函数保存模型,真正企业里要用的就是这个。
model=None
model=load_model(path)#加载保存的模型
result=model.predict(test_x)#要处理的数据导入模型存入result
print(result)"""
模型输出为:
5/5 [==============================] - 0s 2ms/step - loss: 0.2266 - accuracy: 0.9733
[0.22659426927566528, 0.9733333587646484]
Test score: 0.22659426927566528
Test accuracy: 0.9733333587646484
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#read_data函数同上
m1=Dense(units=5,input_dim=4,activation='sigmoid',name="layer1")(feature_input)
m1=Dropout(0.2)(m1)
m2=Dense(units=6, activation='sigmoid',name="layer2",kernel_regularizer=regularizers.l1(0.01))(m1)
#每层用一个L1正则,强度系数λ=0.01。默认自带L2正则,有需求时可以自己写,比如强烈要求此处加强正则。本层取名layer2,方便查找引用。默认也会取个名字
m2=Dropout(0.2)(m2)
output=Dense(units=3, activation='softmax')(m2)
model = Model(inputs=feature_input, outputs=output)
model.compile(optimizer='adam', loss='categorical_crossentropy')
train_x,train_y=read_data("data")
model.fit(train_x, train_y, batch_size=8, epochs=100, shuffle=True)
print(model.get_layer("layer2").get_weights()[0])
保存的模型文件就是模型结构和权重。