基于SwinTransformer+UNet的遥感图像语义分割

目录
- 摘要
- 1.Introduction
- 2.Related Work
-
- 2.1.基于CNN的RS语义分割
- 2.2.自注意力机制
- 2.3.ViT
- 3.方法
-
- 3.1.网络结构
- 3.2.SwinTransformer block
- 3.3.Spatial Interaction Module
- 3.4.Feature Compression Module
- 3.5.Relational Aggregation Module
- 4.Experiments
-
- 4.1.Datasets
-
- 4.1.1.Vaihingen Dataset
- 4.1.2.Potsdam Dataset
- 4.2.实现细节
-
- 4.2.1.训练设置
- 4.2.2.损失函数
- 4.2.3.评价指标
- 4.3.实验结果
- 个人总结
摘要
全局上下文信息(context information)对于遥感图像的语义分割至关重要。然而,现有的大多数方法都依赖于卷积神经网络(CNN),由于卷积运算的局部性(locality),直接获取全局上下文信息充满了挑战性。受具有强大全局建模能力的Swin transformer的启发,我们提出了一种新的 Remote Sensing image 语义分割框架,称为ST-U网络,该框架将Swin transformer嵌入到基于CNN的经典UNet中。ST UNet构成了一种新型的SwinTransformer和CNN并行的双编码器(dual encoder)。首先,我们提出了一种空间交互模块(SIM,spatial interaction module),该模块通过建立像素级的相关性(pixel-level correlation)来对 SwinTransformer block 中的空间信息进行编码,以增强被遮挡对象的特征表示能力。其次,我们构造了一个特征压缩模块(FCM,feature compression module),以减少细节信息的丢失,并在SwinTransformer的patch token的下采样过程中浓缩更多的小尺度特征,从而提高了小尺度地物(ground object)的分割精度。最后,作为双编码器之间的桥梁,设计了一个关系聚合模块(RAM,relational aggregation module),将来自SwinTransformer的全局依赖项(global dependencies)层次化地集成到CNN的特征中。我们的ST-UNet分别在ISPRS Vaihingen和Potsdam数据集上实现了明显提升。
1.Introduction
随着航天技术和传感器技术的快速发展,研究者可以很容易地收集大量的高质量遥感图像,它反映了生态环境的状态和人类活动的痕迹。学习这些图像中包含的知识并有效地筛选感兴趣的信息已成为遥感图像智能解译(intelligent interpretation)的重点。语义分割作为一种可行的解决方案受到了广泛的关注。其核心目标是识别图像中每个像素的语义类别。目前,遥感图像语义分割被应用于许多现实场景,如城市规划、灾害评估和农业生产。
近年来,卷积神经网络(CNN)的快速发展为语义分割提供了技术支持。特别是,全卷积网络(FCN)起到了至关重要的作用。随后,研究者们提出了许多创新性的工作。在此过程中,编码器-解码器结构表现出优异的分割性能,并逐渐成为语义分割网络中的一种流行结构配置。编码器用于提取特征,解码器在融合高级语义和低级空间信息的同时,尽可能精细地恢复图像分辨率。例如,UNet利用解码器通过skip connections来学习相应编码过程中的空间相关性(spatial correlation)。Deeplab V3+引入了基于Deeplab V3的解码器,以集成空间特征,其显著提高了网络性能。
然而,地物的特殊性(小尺度small scale、高相似性high similarity和相互遮挡mutual occlusion)对遥感图像的语义分割提出了新的挑战,如图1所示。基于CNN的模型在特征提取过程中执行特征下采样,以减少计算量,这很容易导致小尺度特征被丢弃。不同语义类别的地物可能具有相似的大小、材质和光谱特征,难以区分。此外,遮挡问题通常会导致语义歧义(semantic ambiguity)。因此,需要更多的全局上下文信息和精细的空间特征作为语义推理的线索。

- 图1:RS图像示例,其中第一行图像取自ISPRS Vaihingen数据集,第二行取自ISPRS Potsdam数据集。
a:屋顶上的天窗外观类似于“汽车Car”和“不透水表面Impervious surface”;
b:“建筑Building”和“不透水表面”的材质(material)相同,“树木Tree”几乎在“低矮植被Low Vegetation”中看不见;
c:“汽车”的大部分被“树Tree”遮住了。
CNN在空间位置表示方面具有优势,但由于卷积运算的局部性,很难直接建模全局语义的相互作用信息和上下文信息。现有的方法采用注意力机制来解决这个问题。DANet用并行的通道注意力和位置注意力构造长范围依赖。此外,多尺度特征融合策略也是一种常用的方法。Zhao等人使用不同级别的特征来综合描述特征。PSPNet及其改进版SuperNet通过金字塔pooling模块利用上下文信息。这些方法从CNN获得的局部特征中聚合全局信息,而不是直接编码全局上下文。因此,很难从背景复杂的遥感图像中获得清晰的全局场景信息。
最近,transformer的成功为全局关系建模开辟了新的研究思路。Transformer是自然语言处理领域中一种流行的序列预测模型。Carion等人提出了DETR,它利用Transformer的编码器-解码器结构来模拟序列中元素之间的相互作用。与基于CNN的模型类似,Chen等人设计了一种双分支Transformer结构,以学习不同尺度的特征。事实证明,多尺度特征表示对ViT也是有效的。根据这种结构,构建了SwinTransformer,并在多个密集预测任务中显示出巨大的潜力。目前,基于Swin transformer的模型在医学图像分割方面取得了很大的进展,但其在RS图像上的分割潜力尚未得到证实。
在本文中,为了缓解CNN在全局建模方面的不足,我们提出了一种新的RS图像语义分割网络框架ST-UNet,该框架利用Swin transformer来辅助UNet。如前所述,UNet是基于CNN的U形解码器-编码器网络,通过skip-connection实现编码器和解码器之间的特征融合。我们将UNet中的编码器作为主编码器,Swin变压器作为辅助编码器,形成并行双编码器结构。具体地,我们通过关系聚合模块(RAM)构建了从辅助编码器到主编码器的单向信息流,RAM是ST-UNet的关键组件。此外,将SIM(空间交互模块)附加到SwinTransformer上,探索全局特征的空间相关性,并使用FCM(特征压缩模块)提高小尺度对象的分割精度。
本文贡献:
- 我们构建了空间交互模块(SIM)来关注空间维度上像素级的特征相关性,从而缓解地物遮挡引起的语义歧义。此外,SIM还补偿了Swin transformer受其窗口机制限制的全局建模能力。
- 我们在辅助编码器中提出了一个特征压缩模块(FCM),以缓解patch token下采样过程中小规模特征的遗漏。FCM可以收集小规模对象的更多特征,减少细致信息的丢失。
- 为了提取遥感图像中的判别特征,我们设计了RAM,它从辅助编码器(auxiliary encoder)中提取通道的关系信息,作为全局线索来引导主编码器。RAM能有效地识别相似性较高的地物。
2.Related Work
2.1.基于CNN的RS语义分割
由于一些数据集和竞赛的发布,例如IGARSS数据融合竞赛,SpaceNet竞赛、DeepGlobe竞赛、ISPRS benchmarks。基于CNN的遥感图像语义分割受到了广泛关注。Zhang等人采用HRNet中的多分支并行卷积结构来生成多尺度特征图,并设计了一个自适应空间pooling模块来聚合更多的局部上下文。Maggiori等人将MLP引入分割网络,以产生更好的分割结果。Qi等人提出了一种基于递归神经网络和三维卷积的空间信息推理结构,用于学习全局空间上下文和局部视觉特征,有效解决了道路检测中的遮挡问题。
此外,一些研究人员还关注小尺度特征的特征提取。Kammpfmeyer等人组合了基于patch的像素分类和像素到像素分割,这引入了不确定映射,以在小规模对象上实现高性能。受UNet的启发,Dong等人提出了DenseU网络,该网络通过密集融合策略实现小规模特征的聚合。FactSeg提出了一种由前景激活分支和语义修复分支组成的对称双分支解码器。这两个分支通过skip-connection进行多尺度特征融合,从而提高了小尺度对象分割的精度。Chen等人提出了一种自适应感受野的卷积网络,以实现大规模对象和小规模对象特征提取之间的折衷。
物体边界的预测也是一个值得注意的方面。Marmanis等人在语义分割网络中明确引入了边缘检测模块,以监督边界特征学习。ERN提出了两个简单的边缘损失强化模块,以加强物体边界的保护。
上述基于CNN的方法促进了遥感图像语义分割的发展。我们没有放弃CNN,而是致力于提出一个新的框架(例如最近基于Transformer的方法),以继承两者的优点。
2.2.自注意力机制
近年来,自注意机制在计算机视觉任务中得到了广泛的应用。Zhao等人和Li等人提出了视频字幕的区域级注意和帧级注意。Zhao等人探讨了成对自注意和局部自注意在图像识别中的有效性。SENet通过全局平均pooling层表示通道之间的关系,以自动了解不同通道的重要性。CBAM将通道级注意和空间级注意应用于自适应特征细化。Ding等人提出了patch注意模块,以突出特征图的焦点区域。Panboonyuen等人在GCN框架的每个阶段引入了通道注意块,以分层优化特征图。Su等人将注意力集中在一小批图像中的相似对象上,并通过自注意机制对它们之间的交互信息进行编码。与上述方法不同,我们考虑了垂直和水平像素级的自注意力,并结合多个pooling层来提取通道依赖。
2.3.ViT
Transformer首先被提出用于机器翻译任务,并超越了之前基于复杂递归或CNN的序列模型。随后,基于Transformer的模型在自然语言处理的各个领域得到了广泛的应用。标准transformer块由一个多头自注意(MSA)、一个多层感知器(MLP)和一个层规范化(LN)组成,如图2a所示。MSA在建立输入和输出序列之间的全局依赖关系方面发挥了关键作用。
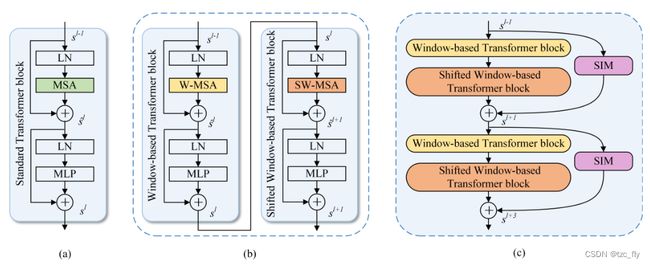
- 图2:a为标准的Transformer block,b为SwinTransformer block,c为本文提出的SIM。
最近的研究表明,Transformer也适用于计算机视觉任务。Dosovitskiy等人是第一个将transformer应用于图像分类的人,通过拆分和展平(splitting and flattening)将图像数据转换为一系列token。这样的ViT在大规模数据集的预训练下实现了最先进的性能。之后,Chen等人探索了一种基于通用Transformer的图像处理任务预训练方法。T2T-ViT递归地将相邻token聚合为一个token,以建模由周围token表示的局部结构特征,并减少token的数量。Touvron等人提出了一种新的基于token的蒸馏策略,以提高原始ViT在较小Imagenet-1k数据集上的训练效率。
尽管如此,ViT仍然需要为密集的预测任务付出巨大的训练成本。它只输出与预测目标不匹配的低分辨率特征(与输入图像的分辨率相同)。一些工作修改了ViT体系结构,以适应密集的预测任务,如语义分割和对象检测。SETR将Transformer视为编码器,在每一层中对全局上下文进行建模,并结合一个简单的解码器形成语义分割网络。PVT模仿CNN backbone的特性,将金字塔结构引入ViT,以获得多尺度特征图。具体来说,它通过patch embedding层灵活地控制Transformer的长度。虽然PVT减少了计算资源的消耗,但复杂度依然是图像大小的二次方。因此,Liu等人提出了基于移位窗口策略的SwinTransformer,该策略将MSA的计算限制在非重叠窗口,同时允许跨窗口信息交互。Swin transformer仅具有线性计算复杂度,在各种视觉任务中都取得了优异的性能,包括图像分类、目标检测和语义分割。放弃传统Transformer中的MSA,它利用基于窗口的MSA(W-MSA)和移位的W-MSA(SW-MSA),如图2b所示。
Cao等人和Lin等人以Swin transformer为主干,开发了用于医学图像语义分割的U形编解码器框架。特别是,Lin等人利用基于Swin transformer的双编码器和两个输入图像尺度来提取不同语义尺度的特征表示。
然而,TransUNet和TransFuse指出,纯Transformer分割网络产生的结果并不令人满意,因为Transformer只关注全局建模,缺乏定位能力。因此,他们创建了CNN和transformer的混合结构。TransUnet将CNN和transformer顺序堆叠,形成一个新的编码器结构,而TransFuse同时执行这两个功能,并试图融合这两个功能。此外,TransFuse在Transformer分支的解码器中使用了简单的渐进式上采样,以恢复空间分辨率。
受这些优秀作品的启发,我们采用了由Swin transformer块组成的辅助编码器,为基于CNN的主编码器提供全局上下文信息。据我们所知,本文提出的ST-UNet是第一个将SwinTransformer应用到遥感图像分割任务中的,它弥补了纯CNN的不足,提高了分割精度。
3.方法
3.1.网络结构
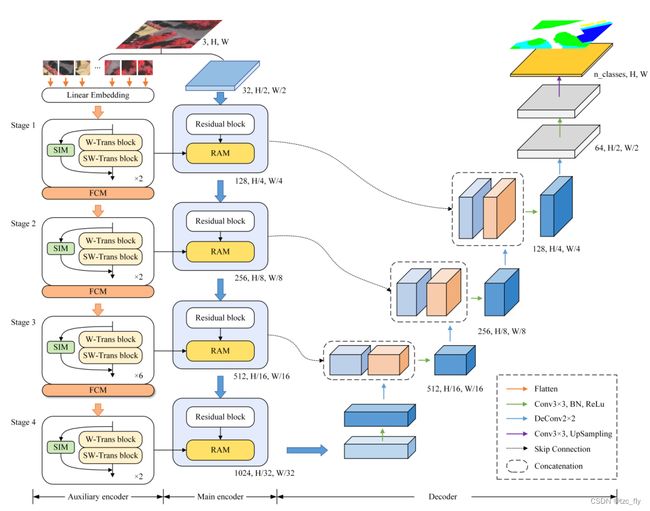
- 图3:ST-UNet的架构。ST-UNet包含三个重要的模块:RAM,SIM,FCM。
ST-UNet的整体架构如图3所示。作为SwinTransformer和UNet的混合体,我们的ST-UNet遵循UNet的优秀结构,其中kip-connection层连接编码器和解码器。特别地,ST-UNet构造了由基于CNN的残差网络和SwinTransformer组成的双编码器,该编码器通过RAM传输信息,以充分获得RS图像的判别特征。此外,我们还设计了SIM和FCM,以进一步提高SwinTransformer的性能。
对于给定的RS图像 X ∈ R H × W × 3 X\in R^{H\times W\times 3} X∈RH×W×3,ViT将图像划分为非重叠的patch,并用序列数据的"token"来比喻。图像的token之间是存在关联的。patch中同一对象的像素通常聚集在一起,具有很强的语义相关性。因此,为了避免在初始输入阶段失去语义信息的连续性,我们通过卷积从每个图像中获得存在重叠的patch token。在实验中,patch大小被设为 8 × 8 8\times 8 8×8,重叠率为 50 % 50\% 50%。然后,线性embedding层将这些patch展平并投影到 C 1 C_{1} C1维。这些patch token被放入由SwinTransformer block堆叠的辅助编码器中。辅助编码器有四个特征提取阶段,每个阶段的输出定义为 S n S_{n} Sn。标准SwinTransformer block包括两种类型,即window-based的transformer(W-Trans)和shifted的W-Trans(SW-Trans)。特别是,我们提出用SIM建立像素级信息交换(pixel-level information exchange),该信息连接到SwinTransformer block的输出。SIM可以有效地弥补基于窗口的自注意的局限性,缓解遮挡(occlusion)引起的语义歧义问题(semantic ambiguity)。此外,为了在与主编码器的特征分辨率匹配的同时获得多尺度特征,我们通过缩短patch token的长度来构建FCM,形成一个四阶段的分层特征编码结构。在此过程中,FCM可以减少对小尺度对象特征的遗漏。stage n n n 输出的分辨率为 ( H 2 n + 1 , W 2 n + 1 ) (\frac{H}{2^{n+1}},\frac{W}{2^{n+1}}) (2n+1H,2n+1W),维数是 2 n − 1 C 1 2^{n-1}C_{1} 2n−1C1。
原始RS图像 X X X首先以大小上一半的压缩量馈送至ResNet50,以获得主编码器中的深度特征。第 n n n个残差模块的输出特征图被表示为 A n ∈ R H 2 n + 1 × W 2 n + 1 × 2 n − 1 C 2 A_{n}\in R^{\frac{H}{2^{n+1}}\times\frac{W}{2^{n+1}}\times 2^{n-1}C_{2}} An∈R2n+1H×2n+1W×2n−1C2,这里 C 2 = 128 C_{2}=128 C2=128。然后, A n A_{n} An和 S n S_{n} Sn被输入到RAM,融合结果返回主编码器。RAM模块作为主编码器和辅助编码器之间的桥梁,通过可变形卷积和通道注意力机制建立连接。
经过以上编码阶段,我们得到特征 F ∈ R H 32 × W 32 × 1024 F\in R^{\frac{H}{32}\times\frac{W}{32}\times 1024} F∈R32H×32W×1024,该特征在卷积层之后被送入解码器。我们将其输入到 2 × 2 2\times 2 2×2反卷积层扩大分辨率。继UNet之后,ST-UNet利用skip-connection层来连接编码器和解码器,同时减少通过 3 × 3 3×3 3×3卷积层的通道数量。此处,每个卷积层都伴随一个batch normalization层和ReLU层。以上过程被执行4次,特征 F F F逐渐恢复到 F ′ ∈ R H 2 × W 2 × 64 F'\in R^{\frac{H}{2}\times\frac{W}{2}\times 64} F′∈R2H×2W×64。最后我们用 3 × 3 3\times 3 3×3卷积层和线性插值上采样获得分割结果。
3.2.SwinTransformer block
如前面所述,标准transformer block包含了MSA,MLP和LN(见图2a,LN为layer norm)。因此,我们将第 l l l层的输出 s l s^{l} sl表示为: s ^ l = M S A ( L N ( s l − 1 ) ) + s l − 1 \widehat{s}^{l}=MSA(LN(s^{l-1}))+s^{l-1} s l=MSA(LN(sl−1))+sl−1 s l = M L P ( L N ( s ^ l ) ) + s ^ l s^{l}=MLP(LN(\widehat{s}^{l}))+\widehat{s}^{l} sl=MLP(LN(s l))+s l标准transformer block使用MSA计算所有token之间的全局自注意力,这导致计算复杂度为token数量的二次方,这对于高分辨率遥感图像的特征提取是致命的。为了高效建模,Swin transformer提出了具有两种分区配置的W-MSA,以取代普通MSA,即常规窗口配置(W-MSA)和移位窗口配置(SW-MSA)。他们在窗口内进行自注意,但忽略了窗口外的token,每个窗口只覆盖 D × D D×D D×D patches。在实验中, D = 8 D=8 D=8。如图2b所示,在连续的Swin Transformer block中交替执行W-MSA和SW-MSA,以增强跨窗口的信息连接。为了便于区分,我们将两个Swin transformer block重命名为W-Trans block 和SW-Trans block。其表示如下: s ^ l = W − M S A ( L N ( s l − 1 ) ) + s l − 1 \widehat{s}^{l}=W-MSA(LN(s^{l-1}))+s^{l-1} s l=W−MSA(LN(sl−1))+sl−1 s l = M L P ( L N ( s ^ l ) ) + s ^ l s^{l}=MLP(LN(\widehat{s}^{l}))+\widehat{s}^{l} sl=MLP(LN(s l))+s l s ^ l + 1 = S W − M S A ( L N ( s l ) ) + s l \widehat{s}^{l+1}=SW-MSA(LN(s^{l}))+s^{l} s l+1=SW−MSA(LN(sl))+sl s l + 1 = M L P ( L N ( s ^ l + 1 ) ) + s ^ l + 1 s^{l+1}=MLP(LN(\widehat{s}^{l+1}))+\widehat{s}^{l+1} sl+1=MLP(LN(s l+1))+s l+1其中, s l s^{l} sl代表W-Trans block的输出, s l + 1 s^{l+1} sl+1代表SW-Trans block的输出。
3.3.Spatial Interaction Module
Swin transformer块在有限的窗口内建立patch token的关系,有效地减少了内存开销。然而,这种方法在一定程度上削弱了transformer的全局建模能力(即使它采用了规则窗口和移位窗口的交替执行策略)。此外,遥感图像中地物的遮挡会导致边界模糊,这需要一些空间信息来消除。因此,我们提出跨W-Trans block和SW-Trans block的SIM,以进一步增强信息交换,同时编码更精确的空间信息。SIM在两个空间维度引入了注意力,以考虑像素之间的关系,而不仅仅是patch token之间,使Transformer更适合图像分割任务。SIM的组件如图4所示。
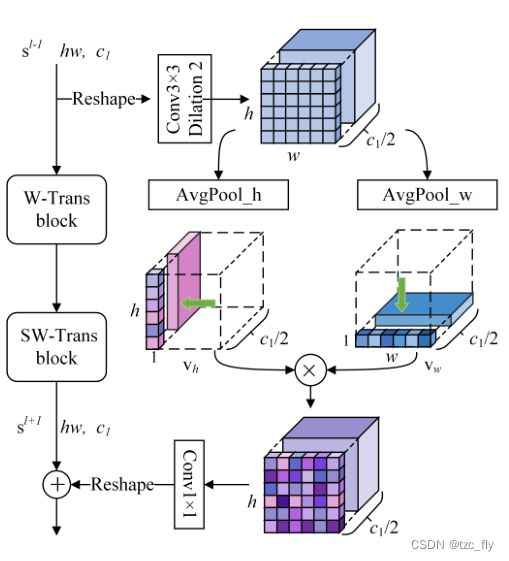
- 图4:SIM的结构。
给定stage n n n,我们首先reshape W-Trans block的输入特征 s l − 1 ∈ R ( h × w ) × c 1 s^{l-1}\in R^{(h\times w)\times c_{1}} sl−1∈R(h×w)×c1为 z ∈ R h × w × c 1 z\in R^{h\times w\times c_{1}} z∈Rh×w×c1,此处, c 1 = 2 n − 1 C 1 , h = H 2 n + 1 , w = W 2 n + 1 c_{1}=2^{n-1}C_{1},h=\frac{H}{2^{n+1}},w=\frac{W}{2^{n+1}} c1=2n−1C1,h=2n+1H,w=2n+1W。特征 z z z被输入到 3 × 3 3\times 3 3×3的空洞卷积(dilation rate=2),通过较大的感受野重构特征图的结构信息。此外,为了降低计算成本,通道数被缩减为 c 1 / 2 c_{1}/2 c1/2。然后,应用全局平均pooling运算来获取特征地图在空间方向(垂直和水平)上的统计信息。具体而言,各方向的计算公式如下所示: v h i k = 1 w ∑ j = 0 w − 1 z ^ k ( i , j ) v_{h_{i}}^{k}=\frac{1}{w}\sum_{j=0}^{w-1}\widehat{z}^{k}(i,j) vhik=w1j=0∑w−1z k(i,j) v w j k = 1 h ∑ i = 0 h − 1 z ^ k ( i , j ) v_{w_{j}}^{k}=\frac{1}{h}\sum_{i=0}^{h-1}\widehat{z}^{k}(i,j) vwjk=h1i=0∑h−1z k(i,j)其中, i , j , k i,j,k i,j,k分别是垂直方向、水平方向和通道的索引。这里, 0 ≤ i < h , 0 ≤ j < w , 0 ≤ k < c 1 2 0\leq i
SIM在内部编码了垂直方向和水平方向的对象存在权重,两者相乘即为空间上的 ( x , y ) (x,y) (x,y)的位置上的对象存在权重(通道代表对象或者对象的某个特征部件)。SIM是相比shifted-window更全局的对象存在注意力。
由于具体到 ( x , y ) (x,y) (x,y),所以是像素级的精确编码。
3.4.Feature Compression Module
先前关于transformer的工作通过 flattening+projecting 图像的patches或合并 2 × 2 2×2 2×2相邻patches的特征并执行线性变换形成一个层次网络。然而,这些方法容易导致许多细节和结构信息的丢失,不利于对具有密集小尺度对象的遥感图像进行语义分割。因此,我们在SwinTransformer的patch token下采样中设计了FCM,以避免上述问题,从而提高了小尺度对象的分割效果。
具体而言,FCM有两个分支,如图5所示。一种是具有空洞卷积的 bottleneck block,它通过扩展卷积的感受野来广泛收集小尺度物体的特征和结构信息。在 bottleneck block 中,第一个 1 × 1 1×1 1×1卷积层增加了维数,中间的 3 × 3 3×3 3×3空洞卷积层用于获取更广泛的结构信息,最后一个 1 × 1 1×1 1×1卷积层减小了特征尺度。给定stage n n n的输出 s s s,将其输入到FCM,FCM的该分支的输出是 F 1 ∈ R ( h / 2 ) × ( w / 2 ) × 2 c 1 F_{1}\in R^{(h/2)\times(w/2)\times 2c_{1}} F1∈R(h/2)×(w/2)×2c1
空洞卷积对小尺度对象的作用:空洞卷积扩大感受野,用周围环境的信息推理小尺度信息。
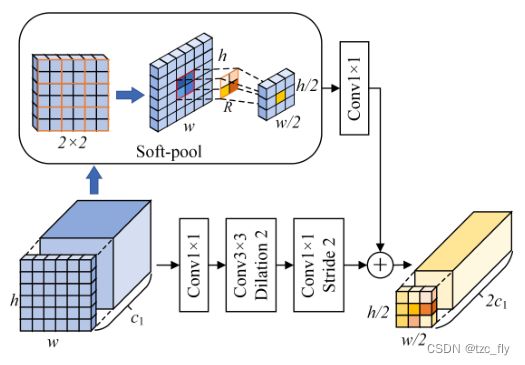
- 图5:FCM的结构。
另一个分支引入了Soft-pool操作,以获得更精细的下采样。Soft-pool 以指数加权的方式激活 pooling kernel 中的像素,以保留更详细的信息。对于特定 pooling kernel 邻域 R R R中的每个像素,Soft-pool的计算方法如下所示: s ~ = ∑ i ∈ R e s i ∗ s i ∑ j ∈ R e s j \tilde{s}=\sum_{i\in R}\frac{e^{s_{i}}*s_{i}}{\sum_{j\in R}e^{s_{j}}} s~=i∈R∑∑j∈Resjesi∗si然后,经过Soft-pool的特征被输入到卷积层(用于增加维数)得到输出 F 2 ∈ R ( h / 2 ) × ( w / 2 ) × 2 c 1 F_{2}\in R^{(h/2)\times(w/2)\times 2c_{1}} F2∈R(h/2)×(w/2)×2c1, F 2 F_{2} F2可以如下计算: F 2 = ϕ ( S o f t P o o l ( s ) ) F_{2}=\phi(SoftPool(s)) F2=ϕ(SoftPool(s))简言之,一个分支的功能是获取小规模的特征(空洞卷积的扩展感受野),另一个分支的功能是保留细节(Soft-pool的局部加权下采样),这两者都是同等重要和不可或缺的。因此,这两个分支合并为FCM的输出 L L L。该过程可表示为: L = F 1 ⊕ F 2 L=F_{1}\oplus F_{2} L=F1⊕F2
3.5.Relational Aggregation Module
基于CNN的主编码器在空间维度提取受卷积核限制的局部信息,但缺乏通道之间关系的明确建模,当对象共享相似的分布模式但不同的通道时,可能会导致混淆。一些方法已经证明,对通道的依赖性进行编码可以改善特征识别。因此,我们提出了RAM,其详细结构如图6所示。为了突出整个特征图中重要且更具代表性的通道,我们从辅助编码器的全局特征中提取通道相关性,然后将其嵌入到从主编码器获得的局部特征中。此外,RAM引入了可变形卷积来适应不同形状的对象区域,并进一步细化了主编码器的特征。通过RAM,我们可以对更多的全局判别特征进行编码,以提高RS图像中高相似度地物的分割精度。
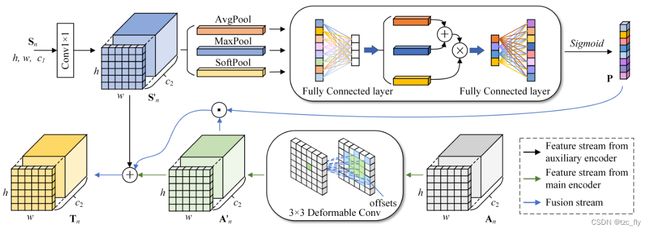
- 图6:RAM的结构。
正如前面提到的, A n A_{n} An和 S n S_{n} Sn分别表示stage n n n的主编码器和辅助编码器的输出。一方面,我们输入 A n A_{n} An到可变形卷积以适应RS对象的几何多样性。该过程可以被记为 A n ′ = δ ( A n ) A'_{n}=\delta(A_{n}) An′=δ(An),这里, δ \delta δ是 3 × 3 3\times 3 3×3的可变形卷积。另一方面, S n S_{n} Sn被传到卷积层以改变维数,得到 S n ′ = ϕ ( S n ) S'_{n}=\phi(S_{n}) Sn′=ϕ(Sn)。由于特征映射的每个通道都可以被视为特征检测器,因此通道依赖性集中于图像中的“有意义内容”。我们采用三种pooling策略来获得更全面的通道依赖性。首先,我们应用Average-pooling和Max-pooling来计算通道上特征映射的统计特征,并将它们传到共享的全连接层。然后, P A & M ∈ R 1 × 1 × ( c 1 / 2 ) P_{A\& M}\in R^{1\times 1\times(c_{1}/2)} PA&M∈R1×1×(c1/2)通过两者相加得到。同时,引入了一个指数权重的Soft-pool来计算全局权重描述符,并将其放入一个全连接层,用 P S P_{S} PS表示。 P A & M = σ ( F 1 ( A v g P o o l ( S n ′ ) ) ) + σ ( F 1 ( M a x P o o l ( S n ′ ) ) ) P_{A\& M}=\sigma(F_{1}(AvgPool(S'_{n})))+\sigma(F_{1}(MaxPool(S'_{n}))) PA&M=σ(F1(AvgPool(Sn′)))+σ(F1(MaxPool(Sn′))) P S = σ ( F 1 ( S o f t P o o l ( S n ′ ) ) ) P_{S}=\sigma(F_{1}(SoftPool(S'_{n}))) PS=σ(F1(SoftPool(Sn′)))其中, σ \sigma σ表示ReLU激活,考虑到计算量,将 F 1 F_{1} F1设置为大小减半的全连接层。然后,我们通过用 P A & M P_{A\& M} PA&M和 P S P_{S} PS相乘,优化每个通道的描述符,得到 P P P: P = δ ( F 2 ( P A & M ⊙ P S ) ) P=\delta(F_{2}(P_{A\& M}\odot P_{S})) P=δ(F2(PA&M⊙PS))这里的 δ \delta δ表示sigmoid激活, F 2 F_{2} F2为增加维数的全连接层, ⊙ \odot ⊙为element-wise的乘法。我们将通道相关性 P P P作为权重,并将可变形卷积运算的结果 A n ′ A'_{n} An′相乘,以获得细化的特征。最后,通过将细化后的特征与剩余结构连接起来,形成RAM的输出特征 T n T_{n} Tn,其可以表示为: T n = A n ′ ⊕ S n ′ ⊕ ( P ⊙ A n ′ ) T_{n}=A'_{n}\oplus S'_{n}\oplus(P\odot A'_{n}) Tn=An′⊕Sn′⊕(P⊙An′)
RAM用于聚合主编码器和辅助编码器的信息,包含两分支:可变形卷积分支用于处理主编码器的几何多样性特征,用三种pooling聚合来自Transformer的patch token全局关系信息,并输出一个基于通道的注意力向量,用于细化局部卷积的输出。
4.Experiments
4.1.Datasets
4.1.1.Vaihingen Dataset
Vaihingen数据集包含由先进机载传感器采集的33幅正射影像,覆盖了Vaihingen 1.38 km2的面积。地面采样距离(GSD)约为9厘米。每个顶部图像都有红外(IR)、红色(R)和绿色(G)通道。
这些图像被标记为sic类别以进行语义分割。我们选择了11幅图像进行训练(图像ID:1、3、5、7、13、17、21、23、26、32和37),选择了5幅图像进行测试(图像ID:11、15、28、30和34),并将其裁剪为256×256。
4.1.2.Potsdam Dataset
Potsdam数据集有38个大小相同的图像(6000×6000),都是从非常高分辨率的TOP mosaic 中提取的,GSD为5厘米。该数据集覆盖Potsdam 3.42 km2,建筑复杂,居民点密集。数据集被标注为六个类别,用于语义分割研究。每个图像有三种通道组合,即:IR-R-G、R-G-B和R-G-B-IR。在实验中,我们参考了之前的工作,利用14幅带有R-G-B的图像进行测试(图像ID:2_13、2_14、3_13、3_14、4_13、4_15、5_13、5_14、5_15、6_14、6_15和7_13),其余24幅R-G-B图像进行训练。同样,我们将这些原始图像剪切为256×256。
图7显示了上述两个数据集中每个语义标签的比例。在对这两个数据集进行定量评估时,我们忽略了“Clutter或者background”类别。
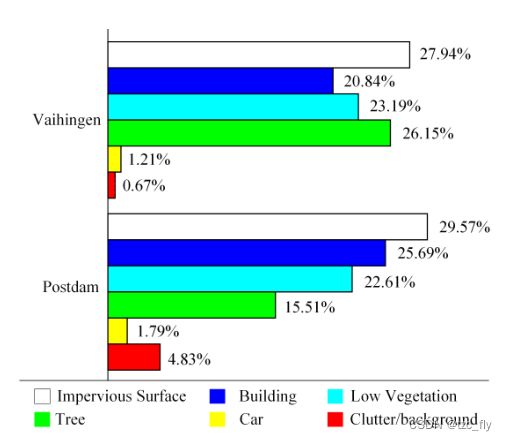
- 图7:Vaihingen和Potsdam数据集中每个语义标签的比例。
4.2.实现细节
4.2.1.训练设置
我们的网络是用Pytorch框架构建的。我们使用动量项为0.9、权重衰减为1e-4的SGD优化器训练模型。此外,我们将初始学习率设置为0.01,并采用“Poly”衰减策略。所有实验均在NVIDIA Geforce RTX 2080 Ti 11-GB GPU上实现。批量大小设置为8,最大epoch为100。
4.2.2.损失函数
如图7所示,Vaihingen和Potsdam数据集中的类别比例不平衡,这导致模型训练侧重于比例较大的类别,而“忽略”比例较小的类别。为了缓解这个问题,我们采用Dice loss L D i c e L_{Dice} LDice和交叉熵损失 L C E L_{CE} LCE联合训练: L = L C E + L D i c e L=L_{CE}+L_{Dice} L=LCE+LDice
Dice loss
Dice系数是一种集合相似度度量函数,通常用于计算两个样本点的相似度(值范围为[0, 1]) S = 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ S=\frac{2|X\cap Y|}{|X|+|Y|} S=∣X∣+∣Y∣2∣X∩Y∣其中, X ∩ Y X\cap Y X∩Y为X和Y之间的交集, ∣ X ∣ , ∣ Y ∣ |X|,|Y| ∣X∣,∣Y∣表示X和Y的元素个数。 D i c e L o s s = 1 − S DiceLoss=1-S DiceLoss=1−S如果Dice系数越大,表明集合越相似,Loss越小。注意, ∣ X ∩ Y ∣ |X\cap Y| ∣X∩Y∣表示两个集合对应元素点乘,然后逐个元素相乘的结果相加求和,比如:

4.2.3.评价指标
我们使用MIoU和平均F1(Ave.F1)分数来评估模型性能。这两个评估指标基于混淆矩阵,该矩阵包含四项:TP、FP、TN和FN。对于每个类别,IOU定义为预测值与真值的交集和并集的比率,计算如下: I o U = T P T P + F P + F N IoU=\frac{TP}{TP+FP+FN} IoU=TP+FP+FNTP对于每个类别的F1计算为: F 1 = 2 × p r e c i s i o n × r e c a l l p r e c i s i o n + r e c a l l F_{1}=2\times\frac{precision\times recall}{precision+recall} F1=2×precision+recallprecision×recall其中, p r e c i s i o n = T P / ( T P + F P ) precision=TP/(TP+FP) precision=TP/(TP+FP), r e c a l l = T P / ( T P + F N ) recall=TP/(TP+FN) recall=TP/(TP+FN),此外,MIoU代表所有类别IoU的平均值,Ave.F1分数是所有类别F1的平均值。
4.3.实验结果
注意, A d d L S , A d d E S Add_{LS},Add_{ES} AddLS,AddES分别表示主编码器和辅助编码器的特征在最后一层聚合和在每一层聚合。
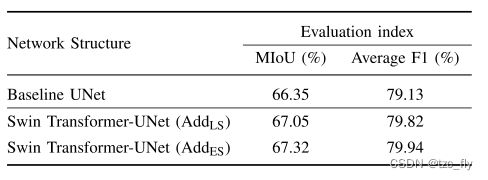
- 表1:Vaihingen数据上双编码器结构的Ablation study。
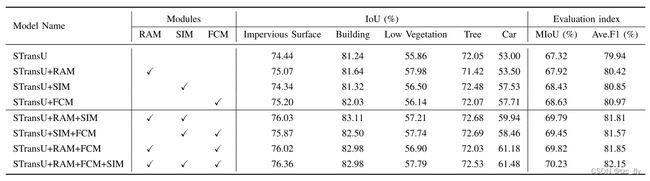
- 表2:所提出模块在Vaihingen数据上的Ablation study。
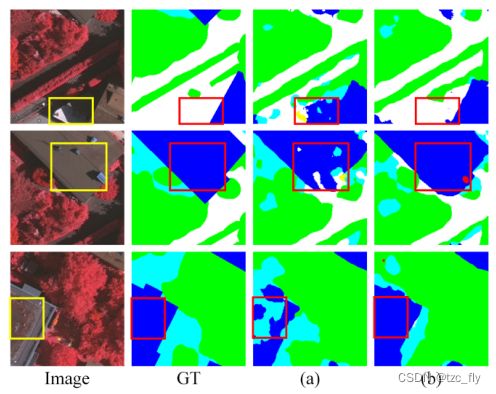
- 图8:在STrans-U框架中使用RAM前后的分割结果比较。a是 STransU A d d E S Add_{ES} AddES-RAM,b是STransU A d d E S Add_{ES} AddES+RAM。
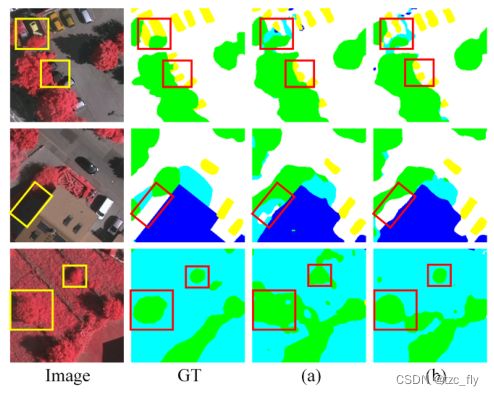
- 图9:在STransU框架中使用SIM前后分割结果的比较。类比图8。
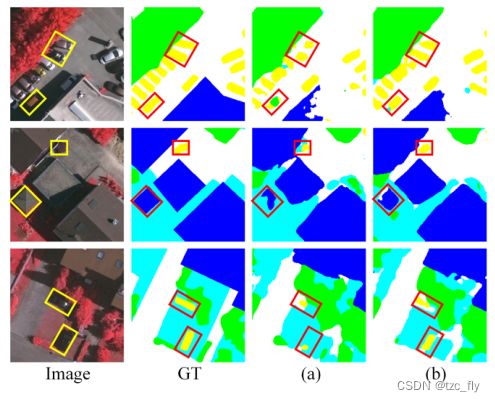
- 图10:在STransU框架中使用FCM前后分割结果的比较。
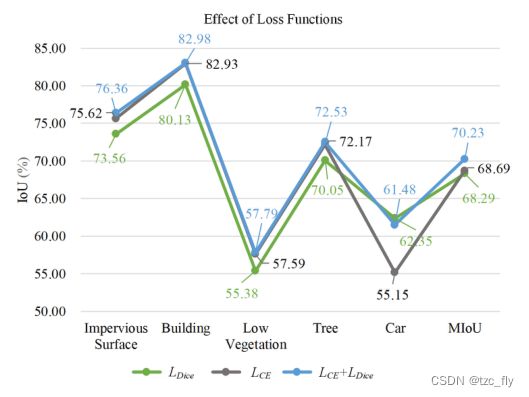
- 图11:Vaihingen数据集上损失函数的Ablation study。
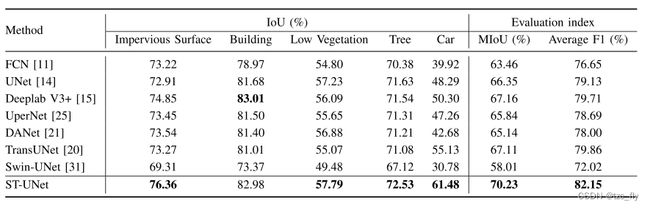
- 表3:Vaihingen数据的分割结果的比较。
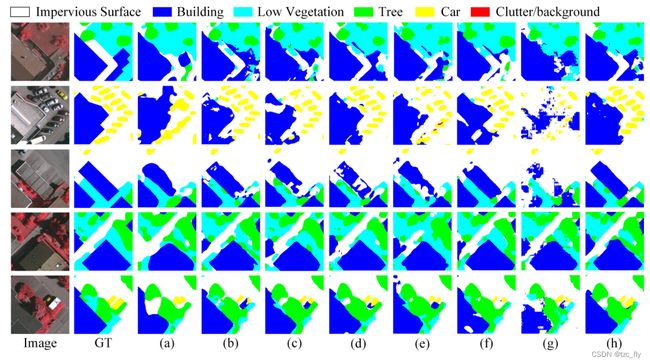
- 图12:Vaihingen数据集的语义分割结果示例。
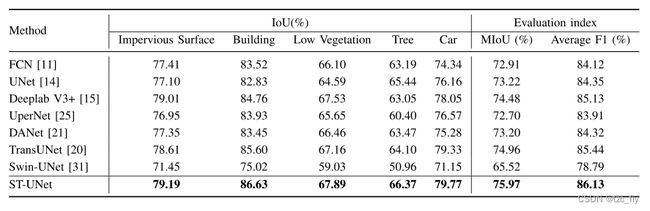
- 表4:Potsdam数据分割结果的比较。
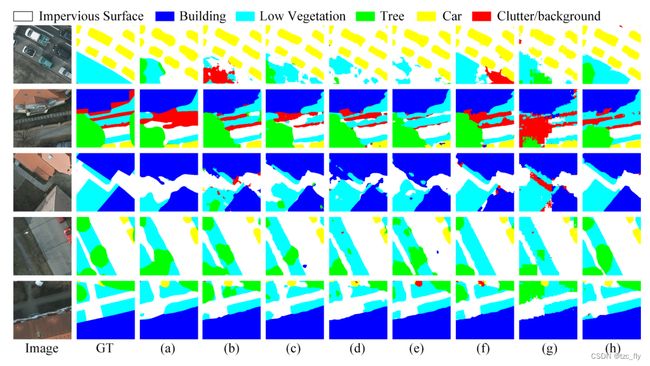
- 图13:Potsdam数据集的语义分割结果示例。
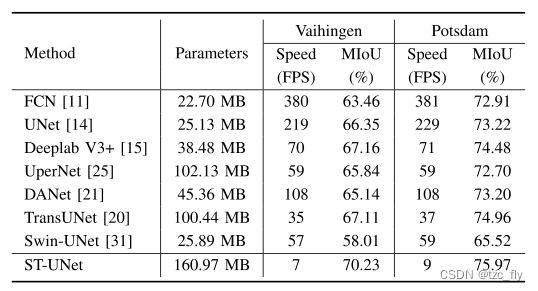
- 表5:模型参数、速度和精度的比较。
个人总结
- 动机:CNN下采样丢失小尺度特征,不同的地物具有相似大小,材质和光谱特征,导致语义歧义,我们需要更精细的空间特征和完整的全局上下文作为语义分割的推理线索。(Transformer正好有长序列建模能力)
- SIM在内部编码了垂直方向和水平方向的对象存在权重,两者相乘即为空间上的(x,y)的位置上的对象存在权重(通道代表对象或者对象的某个特征部件)。SIM是相比shifted-window更全局的对象存在注意力。由于具体到(x,y),所以是像素级的精确编码。
- FCM用于压缩特征,其包括两个分支:一个分支的功能是获取小规模的特征(空洞卷积的扩展感受野),另一个分支的功能是保留细节(Soft-pool的局部加权下采样)
- RAM用于聚合主编码器和辅助编码器的信息,包含两分支:可变形卷积分支用于处理主编码器的几何多样性特征,用三种pooling聚合来自Transformer的patch token全局关系信息,并输出一个基于通道的注意力向量,用于细化局部卷积的输出。