Keras深度学习实战(37)——手写文字识别
Keras深度学习实战(37)——手写文字识别
-
- 0. 前言
- 1. 手写文字识别相关背景
-
- 1.1 Connectionist temporal classification (CTC)
- 1.2 解码 CTC
- 1.3 计算 CTC 损失值
- 2. 模型与数据集分析
-
- 2.1 数据集分析
- 2.2 模型分析
- 3. 实现手写文字识别模型
-
- 3.1 数据集加载与预处理
- 3.2 手写文字识别模型构建与训练
- 小结
- 系列链接
0. 前言
当前越来越多的场景需要将手写体的文字转换为电子格式,手写体识别成为人机交互最便捷的手段之一,拥有广泛的应用前景。在识别图像中手写文字(即转录手写文本图像)的问题中,我们需要同时处理图像数据和顺序数据,这是由于因为图像中的内容需要按顺序进行转录。在本节中,我们使用 Keras 库融合卷积神经网络 (Convolutional Neural Networks, CNN) 和循环神经网络 (Recurrent Neural Network, RNN) 实现深度学习手写识别模型。
1. 手写文字识别相关背景
在传统的手写文字识别方法中,设计的解决方案通常需要人工参与。例如:在图像上使用滑动窗口,窗口大小是字符的平均大小,以便可以检测每个字符,然后输出它检测到的具有较高置信度的字符。然而,窗口的大小或滑动窗口数量需要进行人工确认。因此,这本质上属于一个特征工程问题。
为了使用端到端的方法,降低人工时间成本,我们可以通过卷积神经网络 (Convolutional Neural Networks, CNN) 提取图像特征,然后将这些特征作为输入传递给循环神经网络 (Recurrent Neural Network, RNN) 的各个时间时间戳,以便在各个时间戳提取输出。因此,我们将组合使用 CNN 和 RNN,通过这种方式解决手写文字识别问题,我们不必人工构建特征,只需要优化模型得到 CNN 和 RNN 的最佳参数。
1.1 Connectionist temporal classification (CTC)
使用传统方法,执行手写文字识别或语音转录等监督学习任务时,我们必须提供图像的哪个部分包含某个字符的标签或音频的哪个子段包含某个音素(多个音素组合形成一个单词发音)。
但是,在构建数据集时,为图像中的每个字符或语音中的每个音素提供标签的成本过高,因为在数据集往往需要转录数万个单词或数千小时的语音。
当我们不能提供图像的不同部分与不同字符之间的映射时,使用 Connectionist temporal classification (CTC) 可以方便地解决此问题。接下来,我们将详细介绍 CTC 损失函数。
1.2 解码 CTC
假设我们正在转录包含文本 ab 的图像。示例图像如下,字符 a 和 b 之间的具有不同长度的空格,但输出标签均为 ab:

我们可以将这些图像样本分割为多个时间戳,如下所示,其中每个方框代表一个时间戳,因此可以看到共有六个时间戳:

预测每个时间戳的输出,其中每个时间戳的 softmax 输出是整个词汇表中每个字母的类别概率,则第一张关于 ab 图片的每个时间戳的输出如下:
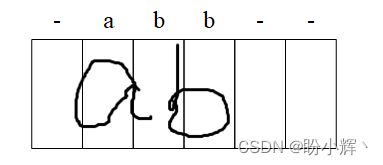
在上图中的 - 表示空白。此外,如果图像的特征通过双向长短时记忆网络 (Long Short-Term Memory, LSTM) 传递,第 3 和第 4 时间戳的输出可能均为 b,因为在执行双向 LSTM 时,下一个时间戳中的信息也会影响上一个时间戳的输出。在最后一步中,压缩所有在连续时间戳中具有相同值的 softmax 输出,因此此样本最终输出为:-a-b-。
如果图像的标签为 abb,则我们期望在两个 b 之间有一个 -,这样连续的 b 就不会被压缩为一个。
1.3 计算 CTC 损失值
如果要计算 CTC 损失值,我们考虑下图中的情形,图中的圆圈中提供了在给定时间戳内不同字符类别的概率,可以看到,在从 t0 到 t5 的每个时间戳内概率之和均为 1:

为了简单起见,我们考虑以下情况:图片标签为 a 而不是 ab,且输出只有 3 个时间戳而不是 6 个时间戳,输出结果如下所示:

下表列出了在每个时间戳中的经过 softmax 激活函数后的输出概率,我们都可以得到输出标签 a:
| 每个时间戳的输出 | 时间戳1中的字符概率 | 时间戳2中的字符概率 | 时间戳3中的字符概率 | 组合概率 | 最终概率 |
|---|---|---|---|---|---|
| –a | 0.8 | 0.1 | 0.1 | 0.8x0.1x0.1 | 0.008 |
| -aa | 0.8 | 0.9 | 0.1 | 0.8 x 0.9 x 0.1 | 0.072 |
| aaa | 0.2 | 0.9 | 0.1 | 0.2 x 0.9 x 0.1 | 0.018 |
| -a- | 0.8 | 0.9 | 0.8 | 0.8 x 0.9 x 0.8 | 0.576 |
| a-a | 0.8 | 0.9 | 0.1 | 0.8 x 0.9 x 0.1 | 0.072 |
| a– | 0.2 | 0.9 | 0.8 | 0.2 x 0.1 x 0.8 | 0.016 |
| aa- | 0.2 | 0.1 | 0.8 | 0.2 x 0.9 x 0.8 | 0.144 |
| 总概率 | - | - | - | - | 0.906 |
从前面的结果中,我们可以获得标签a的总概率为 0.906,·CTC·损失是总概率的负对数,即 − l o g ( 0.906 ) = 0.04 -log(0.906)= 0.04 −log(0.906)=0.04。由于在每个时间戳中具有最高概率的字符的组合预测了标签 a,因此 CTC 损失接近于零。
2. 模型与数据集分析
在本节中,我们将学习转录手写图像,以便提取图片中存在的文本。手写图片样本如下所示:

在上图中,手写字符的长宽尺寸并不相同,而图像的尺寸也是不同的,字符之间的间距也是不同的,且图像的清晰度也不尽相同。在本节中,我们将学习如何结合使用 CNN,RNN 和 CTC 损失函数来转录手写文本图片样本。
2.1 数据集分析
本文使用 IAM 手写数据集训练手写文字识别模型,IAM 手写数据集包含手写英文文本,可用于训练和测试手写文本识别模型。该数据集中包含不同类型的手写文本形式,这些文本是 300dpi 分辨率的扫描件,并保存为 256 级灰度 PNG 图像,下图是一些数据集 words.tgz 中的样本图片:

数据集中的字符是使用自动分割算法从扫描件中提取,并经过人工验证。同时,数据集 xml.tgz 中包含 XML 文件,每个 XML 文件都记录了一系列手写文本图片的相关信息,包括文件名、图片中的字符等。
该数据集可从以下链接下载:https://pan.baidu.com/s/1ZzwFs7FI-lcZk0pI0pjjKQ,提取码: 9e4x。
2.2 模型分析
在实现手写文字识别模型前,我们首先介绍用于转录手写文本图片的模型策略流程:
- 下载手写文字图像数据集:
- 获取上述手写文本图像数据集以及与图像相对应的文本标签
- 将所有图像调整为相同大小 ——
32 x 128 - 调整大小时,我们还应确保图片的纵横比:
- 这是为了确保图像看起来不会非常模糊,因为我们首先需要将原始图像的尺寸更改为
32 x 128 - 我们将在不改变纵横比的情况下调整图像大小,然后将其叠加在
32 x 128空白图像上
- 这是为了确保图像看起来不会非常模糊,因为我们首先需要将原始图像的尺寸更改为
- 反转图像的颜色,使背景变为黑色,手写文本内容转变为白色
- 缩放图像像素值,使像素值的区间在
0到1之间 - 对输出标签进行预处理:
- 提取输出中的不重复的字符
- 为每个字符分配一个索引
- 计算输出标签的最大长度,确保我们预测的时间戳数大于输出标签的最大长度
- 通过填充图像标签文本,确保所有输出的输出长度相同
- 将预处理后的图片传入
CNN网络,提取到的特征形状为32 x 256 - 将
CNN提取的特征输入到双向GRU层(其中GRU可以理解为简化版本的LSTM),以便可以提取相邻时间戳中的信息 32个时间戳中的256个特征中的每一个都是相应时间戳的输入- 输出通过一个全连接层,全连接层的输出值形状等于不同字符的总数,填充值-也是字符集之一,用于表示字符之间的空格或图片空白部分的填充
- 在
32个输出时间戳上提取softmax值及其对应的输出字符
3. 实现手写文字识别模型
接下来,我们使用 Keras 实现上一小节介绍的手写文字识别策略。
3.1 数据集加载与预处理
首先下载并解压文本图片和 XML 标注数据集,其中包含了手写文本的图像及其相应的标签数据。
(1) 创建用于调整图片大小而不会改变其宽高比的函数,由于我们将图像尺寸统一为 32 x 128,因此需要填充图片,以使所有图片都具有相同的形状:
import os, cv2, xmltodict
import matplotlib.pyplot as plt
import numpy as np
from copy import deepcopy
import collections
def extract_img(img):
target = np.ones((32,128))*255
new_shape1 = 32/img.shape[0]
new_shape2 = 128/img.shape[1]
final_shape = min(new_shape1, new_shape2)
new_x = int(img.shape[0]*final_shape)
new_y = int(img.shape[1]*final_shape)
img2 = cv2.resize(img, (new_y,new_x ))
target[:new_x,:new_y] = img2[:,:,0]
target[new_x:,new_y:]=255
return 255-target
在以上代码中,我们创建空白图片 target,然后对图片进行了调整以保持其宽高比。最后,我们将缩放后的图片置于空白图像 target 之上,并反转图像颜色,将背景转为黑色。
(2) 读取图片及其标签,并将其存储在列表中:
# 数据集目录
xmls_root ="xml/"
jpegs_root = "words/"
XMLs = os.listdir(xmls_root)
x_train = []
x_new = []
y_train = []
for i in XMLs:
xml_file = os.path.join(xmls_root, i)
with open(xml_file, 'rb') as f:
d = xmltodict.parse(f, xml_attribs=True)
for line in d['form']['handwritten-part']['line']:
for word in line['word']:
if type(word) == collections.OrderedDict:
try:
text = word['@text']
file_id = word['@id']
tmp = file_id.split('-')
tmp1 = tmp[0]
tmp2 = tmp[0] + '-' + tmp[1]
file_name = os.path.join(jpegs_root, tmp1, tmp2, file_id)
file_name = file_name + '.png'
img = cv2.imread(file_name)
img = extract_img(img)
x_new.append(img)
x_train.append(x_new)
y_train.append(text)
except:
continue
在以上代码中,我们读取每张图片,并根据我们定义的函数对其进行预处理,预处理后的图像样本示例如下:

(3) 计算输出标签中不重复的字符数量,打印计算结果,可以看到共有 79 个不同字符:
import itertools
list2d = y_train
charList = list(set(list(itertools.chain(*list2d))))
print(len(charList))
# 79
(4) 创建输出目标标签,将每个字符的索引存储在输出列表中,如果输出尺寸小于 32 个字符,则将其填充使用空白值 - 进行填充,由于不重复字符索引为 0-78,因此可以假设空白值索引为 79;同时,存储实际标签长度(文本标签的实际情况)以及输入长度(大小固定为 32):
y2 = []
input_lengths = np.ones((num_images,1))*32
label_lengths = np.zeros((num_images,1))
for i in range(num_images):
val = list(map(lambda x: charList.index(x), y_train[i]))
while len(val)<32:
val.append(79)
y2.append(val)
# 标签长度
label_lengths[i] = len(y_train[i])
# 输出长度
input_lengths[i] = 32
(5) 将输入和输出转换为 NumPy 数组:
x_train = np.asarray(x_new[:num_images])
y2 = np.asarray(y2)
x_train = x_train.reshape(x_train.shape[0],x_train.shape[1],x_train.shape[2],1)
3.2 手写文字识别模型构建与训练
(1) 定义目标值,首先初始化 32 维全 0 数组,32 为我们将要使用的批大小,我们期望批数据中的每个样本的损失值均为 0:
outputs = {'ctc': np.zeros([32])}
(2) 定义 CTC 损失函数,将预测值、标签、实际标签长度和输出长度作为输入,计算 CTC 损失:
import keras.backend as K
def ctc_loss(args):
y_pred, labels, input_length, label_length = args
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
(3) 定义模型,基于 CNN 将尺寸为 32 x 128 的图片转换尺寸为 32 x 256 特征图:
from keras.preprocessing.text import Tokenizer
from keras.layers import Dense, Input, Activation
from keras.layers import MaxPooling2D,Conv2D, Reshape, GRU, TimeDistributed, Lambda
from keras.models import Model
import random
from keras import backend as K
from keras.layers.merge import add, concatenate
input_data = Input(name='the_input', shape = (32, 128,1), dtype='float32')
inner = Conv2D(32, (3,3), padding='same')(input_data)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(2,2),name='max1')(inner)
inner = Conv2D(64, (3,3), padding='same')(inner)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(2,2),name='max2')(inner)
inner = Conv2D(128, (3,3), padding='same')(input_data)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(2,2),name='max3')(inner)
inner = Conv2D(128, (3,3), padding='same')(inner)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(2,2),name='max4')(inner)
inner = Conv2D(256, (3,3), padding='same')(inner)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(4,2),name='max5')(inner)
inner = Reshape(target_shape = ((32,256)), name='reshape')(inner)
(4) 接下来,继续定义模型体系结构,将从 CNN 提取的图像特征传递到 GRU:
gru_1 = GRU(256, return_sequences = True, name = 'gru_1')(inner)
gru_2 = GRU(256, return_sequences = True, go_backwards = True, name = 'gru_2')(inner)
mix_1 = add([gru_1, gru_2])
gru_3 = GRU(256, return_sequences = True, name = 'gru_3')(inner)
gru_4 = GRU(256, return_sequences = True, go_backwards = True, name = 'gru_4')(inner)
然后,我们将两个 GRU 的输出串联起来,以便我们同时考虑双向 GRU 和正常 GRU 提取到的特征:
merged = concatenate([gru_3, gru_4])
接下来,我们将 GRU 输出的特征通过一个全连接层传递,并应用 softmax 以获取 80 个可能的类别概率输出,其包含 79 个不重复的字符和 1 个空白填充词:
dense = TimeDistributed(Dense(80))(merged)
y_pred = TimeDistributed(Activation('softmax', name='softmax'))(dense)
在以上代码中,TimeDistributed 可以应用一个 layer 到每个时间戳,例如,上例将 Dense 层应用于每个时间戳上,数据形状由 (batch size, 32, 512) 变为 (batch size, 32, 80)。
(5) 初始化计算 CTC 损失所需的变量,包括预测字符、实际标签、输入长度和实际标签长度,作为 CTC 损失函数的输入:
from keras.optimizers import Adam
Optimizer = Adam()
# 实际标签
labels = Input(name = 'the_labels', shape=[32], dtype='float32')
# 输入长度
input_length = Input(name='input_length', shape=[1],dtype='int64')
# 实际标签长度
label_length = Input(name='label_length',shape=[1],dtype='int64')
# 预测标签
output = Lambda(ctc_loss, output_shape=(1,),name='ctc')([y_pred, labels, input_length, label_length])
(6) 利用以上初始化的输入(需要多个输入)、输出构建模型,并编译:
model = Model(inputs = [input_data, labels, input_length, label_length], outputs= output)
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer = Optimizer)
构建完成的模型架构如下所示:

(7) 创建输入和输出向量:
x_train = np.array(x_train[:num_images])/255
x_train = x_train.reshape(x_train.shape[0],x_train.shape[1],x_train.shape[2],1)
y2 = np.array(y2[:num_images])
y2 = np.asarray(y2)
input_lengths = input_lengths[:num_images]
label_lengths = label_lengths[:num_images]
(8) 在多个 epoch 中拟合模型。每次采样多张照片,将其转换为一个数组后,拟合模型以优化 CTC 损失为 0:
l_train = []
l_test = []
for i in range(5000):
samp=random.sample(range(x_train.shape[0]-1000),32)
x3=[x_train[i] for i in samp]
x3 = np.array(x3)
y3 = [y2[i] for i in samp]
y3 = np.array(y3)
input_lengths2 = [input_lengths[i] for i in samp]
label_lengths2 = [label_lengths[i] for i in samp]
input_lengths2 = np.array(input_lengths2)
label_lengths2 = np.array(label_lengths2)
inputs = {
'the_input': x3,
'the_labels': y3,
'input_length': input_lengths2,
'label_length': label_lengths2,
}
outputs = {'ctc': np.zeros([32])}
history1 = model.fit(inputs, outputs,
batch_size = 32,
epochs=1,
verbose=1,
validation_split=0.1)
if i%10 == 0:
l_train.append(history1.history['loss'][0])
l_test.append(history1.history['val_loss'][0])
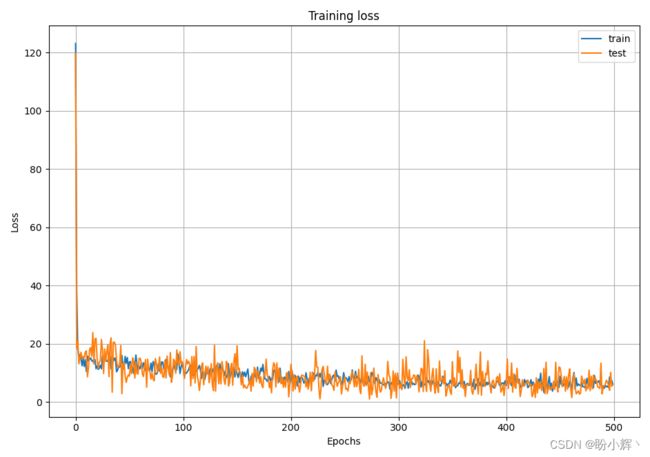
随着训练 epoch 的增加,训练和测试损失如下:
(9) 预测测试图片的输出,如果某个时间戳的预测字符索引为 79,则丢弃此输出:
model2 = Model(inputs = input_data, outputs = y_pred)
for k in range(-1,-20,-1):
pred= model2.predict(x_train[k].reshape(1,32,128,1))
pred2 = np.argmax(pred[0,:],axis=1)
out = ""
for i in pred2:
if(i==79):
continue
else:
out += charList[i]
#print(charList[i])
plt.imshow(x_train[k].reshape(32,128), cmap='gray')
plt.title('Predicted word: '+out)
plt.show()
测试样本及其相应的预测结果如下:

小结
手写文字识别是指计算机自动识别手写体汉字、数字、字母和符号等,随着计算机的发展和普及,手写文字识别作为一种高级的人机交互方式在近几十年来引起了人们的广泛关注。本节中,我们介绍了如何组合使用卷积神经网络 (Convolutional Neural Networks, CNN) 和循环神经网络 (Recurrent Neural Network, RNN) 模型解决手写文字识别问题,实现了一个实用的手写英文文字识别系统。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(8)——使用数据增强提高神经网络性能
Keras深度学习实战(9)——卷积神经网络的局限性
Keras深度学习实战(10)——迁移学习详解
Keras深度学习实战(11)——可视化神经网络中间层输出
Keras深度学习实战(12)——面部特征点检测
Keras深度学习实战(13)——目标检测基础详解
Keras深度学习实战(14)——从零开始实现R-CNN目标检测
Keras深度学习实战(15)——从零开始实现YOLO目标检测
Keras深度学习实战(16)——自编码器详解
Keras深度学习实战(17)——使用U-Net架构进行图像分割
Keras深度学习实战(18)——语义分割详解
Keras深度学习实战(19)——使用对抗攻击生成可欺骗神经网络的图像
Keras深度学习实战(20)——DeepDream模型详解
Keras深度学习实战(21)——神经风格迁移详解
Keras深度学习实战(22)——生成对抗网络详解与实现
Keras深度学习实战(23)——DCGAN详解与实现
Keras深度学习实战(24)——从零开始构建单词向量
Keras深度学习实战(25)——使用skip-gram和CBOW模型构建单词向量
Keras深度学习实战(26)——文档向量详解
Keras深度学习实战(27)——循环神经详解与实现
Keras深度学习实战(28)——利用单词向量构建情感分析模型
Keras深度学习实战(29)——长短时记忆网络详解与实现
Keras深度学习实战(30)——使用文本生成模型进行文学创作
Keras深度学习实战(31)——构建电影推荐系统
Keras深度学习实战(32)——基于LSTM预测股价
Keras深度学习实战(33)——基于LSTM的序列预测模型
Keras深度学习实战(34)——构建聊天机器人
Keras深度学习实战(35)——构建机器翻译模型
Keras深度学习实战(36)——基于编码器-解码器的机器翻译模型