Multi-target detection method based on YOLOv4convolutional neural network(基于YOLOv4卷积神经网络的多目标检测方法)
链接:Multi-target detection method based on YOLOv4 convolutional neural network
Multi-target detection method based on YOLOv4 convolutional neural network
基于YOLOv4卷积神经网络的多目标检测方法
Jinhui Liu1* 1 Department of Information, Beijing University of Technology, 100124, Beijing, China * Corresponding author’s e-mail: [email protected]
Abstract. In order to solve the problems of low detection accuracy, false detection and high miss detection rate of small targets in target detection tasks, this paper is a multi-target detection method based on YOLOv4 convolutional neural network. The proposed method is based on YOLOv4. The semantic information of high-level features is first propagated to the low-level network through FPN sampling, and then it is fused with the high-resolution information of the underlying features to improve the detection effect of small target detection objects. The information transmission path from the bottom to the top is enhanced by downsampling the feature pyramid, and finally the feature maps of different layers are fused to achieve relevant predictions. Experiments prove that the method proposed in this paper has good results.
摘要:为了解决在目标检测任务中的低正确率、错误检测和小目标的高忽略率,这篇文章是一个基于YOLOv4卷积神经网络的多目标检测方法。所提出的方法基于YOLOv4。高级特征的语义信息首先通过FPN采样来被传播到低级网络,然后和底层特征的高解析度信息融合来提高小目标检测对象的检测效果。信息从底层到顶端的传输路径通过对特征金字塔的下采样而增强,最后不同层的特征图被融合,以实现相关预测。实验证明这篇文章提出的方法有好的结果。
1.引言
As an important research direction in the field of target detection, multi-target detection has always received widespread attention from researchers. At present, in-depth research has been produced in the fields of intelligent transportation, intelligent assisted driving and video surveillance [1]. Traditional pedestrian detection methods, such as HOG (histogram of oriented gradient) [2], DPM (deformable parts model) [3], and ACF (aggregate channel feature) [4], all use manual design or feature aggregation to obtain pedestrian features. With the major breakthrough of AlexNet [5] in image classification tasks in 2012, the use of convolutional neural networks (convolutional neural networks) to automatically learn the feature extraction process instead of traditional manual design is the current main research direction [6]. Target detection methods based on convolutional neural networks are mainly divided into two categories, one is a two-stage method, and the other is a single-stage method. The main idea of the first method is to use the cascade method [7] to further judge the category and position of the bounding box on the basis of generating the candidate target area.The other is a singlestage method. Take YOLO (youonly look once)[8] and SSD (single shot multibox detector)[9] as examples. The idea is to use a convolutional neural network to directly return the position and category. The introduction of convolutional neural networks as soon as possible has improved the performance of pedestrian detection algorithms, but the occlusion problem is still a major difficulty in pedestrian detection. Literature [10] uses a joint learning method to model different pedestrian occlusion patterns, but its detection framework is complex and cannot exhaust all situations. Literature [11] designed a new loss function to make the prediction frame keep close to the target real frame while keeping away from other real frames. This method is more flexible in processing occlusion and easier to implement. Literature [12] combines the aforementioned two ideas, and proposes a component occlusion sensing unit and an aggregation loss function to deal with the pedestrian occlusion problem. Literature [13] deals with occlusion by introducing new supervision information (bounding box of pedestrian visible area). The idea is to use two branch networks to return to the pedestrian's whole body frame and the bounding box of the visible area respectively, and finally merge the results of the two branches. Improve detection performance. At present, target detection tasks mainly choose appropriate detection algorithms for different application scenarios: the single-stage algorithm has the fastest detection speed, but the accuracy is lower; the two-stage and multi-stage detection algorithms can obtain higher detection accuracy, but at the expense of detection speed.
作为一个在目标检测领域的重要研究方向,多目标检测总是受到了研究者的广泛关注。目前,智能交通、智能辅助驾驶,视频监控【1】领域已经产生了深入的研究,传统的行人检测方法,例如HOG(方向梯度直方图)【2】,DPM(可变形部件模型)【3】和ACF(聚合通道特征)【4】,全使用手工设计或特征聚合来获得行人特征。随着AlexNet【5】在2012年在图像分类任务上的重大突破,使用卷积神经网络来自动学习特征的提取而不是传统的手工设计成了现在的主要研究方向【6】。基于卷积神经网络的目标检测方法主要被分为两个类别,一类是两阶段方法,另一类是单阶段方法。第一种方法的主要思想是使用级联法【7】进一步判断类别和在生成候选目标区域的基础上确定包围框的位置。另一个是一个单阶段法。以YOLO【8】和SSD【9】为例,它们的想法是使用一个卷积神经网络来直接返回方位和类别。卷积神经网络的尽早引入已经提高了行人检测算法的表现,但遮挡问题仍然是在行人检测中的主要难题。文献【10】使用联合学习方法来建模不同的行人遮挡模式,然而它的检测架构复杂,并且不能穷尽所有的情况。文献【12】结合了前述的两种想法,并且提出了一个构成的遮挡感知单元和一个聚合损失函数来处理行人遮挡问题。文献【13】通过引入新的监督信息(行人可见区域边界框)来处理遮挡。这个想法旨在使用两个分支网络去分别返回行人的整个身体框架和可见区域的边界框,最后将两个分支的结果合并在一起。提高检测表现。现在,目标检测任务主要是为了不同的应用场景选择适当的算法:单阶段算法有最快的检测速度,但是准确率较低;两阶段和多阶段检测算法可以获得更高的检测准确度,但是以损失检测时间作为代价。
This paper proposes a multi-target detection method based on YOLOv4 convolutional neural network. Based on the current best single-stage target detection algorithm YOLOv4, the semantic information of high-level features is first propagated to the low-level network through FPN sampling, and then it is combined with the bottom-level features. This method increases the information transmission path from the bottom to the top, and uses feature maps of different layers to fuse to achieve relevant predictions. This method is an end-to-end technology that effectively solves the problem of multi-target detection of static images, videos, and real-time videos.
本文提出了一个基于YOLOv4卷积神经网络的多目标检测方法。以当下最好的单阶段目标检测算法YOLOv4为基础,高级特征的语义信息首先通过FPN采样来被传播到低级网络,然后和底层特征的高解析度信息融合来提高小目标检测对象的检测效果。信息从底层到顶端的传输路径通过对特征金字塔的下采样而增强,最后不同层的特征图被融合,以实现相关预测。本方法是一种端到端技术,有效解决了静态图像,视频和实时视频的多目标检测问题。
2.方法

图1 模型结构
Our model architecture is shown in Figure 1. It consists of three parts: a front-end network for feature extraction, a feature fusion module, and a detection module for classification and regression operations. Adjust the size of the input image to 416×416 at the input, and input it to the network for training and detection. Our basic convolution block is a convolution layer that incorporates Batch Normalization (BN) and uses Mish and leakyRelu activation functions.
我们的模型结构展示在图1中。它包含三部分:一个用来实现特征提取的前端网络,一个融合特征网络和一个用来做分类和回归操作的检测模型。在输入端将输入的图片尺寸调整到416*416,然后将其输入到网络里以训练和检测。我们的基础卷积块是一个卷积层,它包含了批处理归一化(BN),并使用Mish和leakyRelu激活函数。
The front end of the model uses the backbone network composed of the CSPDarknet module stacked by the convolutional layer and the residual module, which effectively prevents the disappearance or explosion of the gradient on the basis of deepening the number of network layers to obtain a richer semantic information feature map, and In the backbone network, the dimensionality reduction of the feature map is achieved by 5 times of downsampling of the convolutional layer with a step size of 2 and a kernel size of 3; 2 times of upsampling are performed on the network neck and the shallow layer is realized with the PAN+SPP model structure The fusion of features and high-level semantic features and the fusion of multi-scale receptive fields make full use of the detailed features of the shallow network and improve the problem of feature loss of small targets; the detection head uses the idea of regression + classification to divide the input image separately It is 76×76, 38×38, and 19×19 grid images of three different sizes, which respectively realize the detection of small targets, medium targets and large targets.
模型前端使用了由卷积层和残差模块堆叠的CSPDarknet模型组成的主干网络,可以在加深网络层数的基础上有效阻止梯度的消失或爆炸,以获得一个更丰富的语义信息特征图,并且在主干网络中,特征图的降维是通过对卷积层进行步长为2,核大小为3的5次下采样来实现的;2次上采样表现在网络的颈部,浅层采用PAN+SPP模型结构实现,特征和高级语义特征的融合以及多尺度接受字段的融合充分利用了浅层网络的细节特征,改善了小目标的特征丢失问题;检测体头部使用回归+分类的想法以将输入的图片分开。它是76*76,38*38和19*19三种不同尺寸的网格图片,分别实现对小型目标,中等目标和大型目标的检测。
The model adds the SPP module behind the backbone network, as shown in Figure 2. After the input feature map passes through a convolutional layer, it goes through three kernels of 5×5, 9×9, and 13×13 for maximum pooling, and then concat the obtained feature maps for channel splicing, and output The number of channels becomes 4 times the original number of channels, and the feature map size remains unchanged. The output feature map size is:
这个模型在主干网络的后面增加了SPP模块,正如图2所示。在输入的特征图通过一个卷积层传递后,它穿过三个分别是5*5,9*9,13*13的以最大池化的内核,然后将得到的特征映射进行拼接,最后输出。通道数变成了原来通道数的四倍,特征图的大小保持不变。输出的特征图大小是:
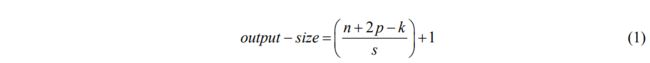
Where n is the size of the input feature map, p is the padding, and s is the step size, which means rounding down. The SPP module obtains the receptive field information of the local area of the feature map and the receptive field close to the global by using the Maxpool layer with different sizes of kernels, and performs feature fusion. This operation of fusing different scales of receptive fields can effectively enrich the expression ability of feature maps, enhance the acceptance range of the output features of the backbone network, and separate important context information.
在这里,n是输入的特征图的大小,p是填充,s是步长,意味着四舍五入了。SPP模块利用不同核大小的最大池化层获取特征图的局部区域和全局附近的感受野信息,并进行特征融合。融合不同尺度的感受野的操作可以有效地丰富特征图的表达能力,增强主干网络输出的特征的可接受范围,并且分离重要的上下文信息。

图2 SPP模块
3.实验和结果分析
The experimental model training uses the hardware platform of Intel(R) Xeon(R) Gold 521 8 CPU, GeForce RTX 2080 Ti 11G GPU. The software uses windows system, python 3.7, PyTorch1.5.0 deep learning framework. The experiment set the input image size to 416×416, the initial learning rate of the stage is 0.0001, the attenuation coefficient is 0.0005, the Adam gradient optimization algorithm is used, the batchsize is set to 4, and the training Epochs is set to 50 times. This experiment uses the data set COCO-2017. The data set contains 12 major categories and 80 minor categories. There are a total of 118287 images in the training set and 5000 images in the test set. Figure 3 is an example. This experiment uses mAP (Mean Average Precision) to evaluate network performance . The mAP index is used to evaluate multi-label image classification tasks and is an important index to measure the overall detection accuracy of the model in multi-category target detection.
实验模型的训练使用了Intel(R) Xeon(R) Gold 521 8 CPU的硬件平台和GeForce RTX 2080 Ti 11G GPU。软件使用的是windows系统,python3.7,PyTorch1.5.0深度学习框架。实验设置输入图片的大小为416*416,该阶段的初始学习率是0.0001,衰减系数为0.0005,使用了Adam梯度优化算法,Batch大小设置为4,Epoch设置为50倍。本实验使用了COCO-2017数据集。该数据集包含了12个主要类别和80个次要类别。在训练集中共有118287张图片,在验证集中有5000张图片。图3是一个例子。本实验使用了mAP来评估网络表现。mAP指标用于评价多标签图像分类任务,是衡量模型在多类别目标检测中整体检测精度的重要指标。

It can be seen from Figure 4 that our model can well detect multiple targets in the picture, and at the same time gives the corresponding identification indicators. In addition, the position and size of the identification frame are determined from a visual angle, and the effect is just right. As shown in Table 1, in terms of indicators, our method achieves a 70.2% mAP effect compared with the other two methods.
在图4中可以看出,我们的模型可以很好地检测图片中的多目标,并且同时给出相应的识别指标。另外,识别框的位置和大小从一个视角确定,效果正好。如表1所示,在指标方面,相较于其他两种方法,我们的方法达到了70.2%的mAP效果。
表1 和其他方法比较


图3 COCO-2017中的一些图片

图4 结果的一些图片
4.结论
This paper proposes a multi-target detection method based on YOLOv4 convolutional neural network. We train convolutional network based on YOLOv4 on COCO2017 data set. Through experiments, we found that our proposed method has achieved good detection results on multi-target detection tasks, indicating that the method has certain practical value. The next step can be optimized to further improve the network and improve detection accuracy.
本文提出了一个基于YOLOv4卷积神经网络的多目标检测方法。我们基于YOLOv4在COCO2017数据集上训练卷积网络。通过实验,我们发现我们的方法在多目标检测任务上实现了好的效果,表明该方法有一定的实际价值。下一步可以进行优化,进一步改进网络,提高检测精度。
参考
[1] Chen Y, Guo S, Zhang B, et al. A Pedestrian Detection and Tracking System Based on Video Processing Technology[C]// 2013 Fourth Global Congress on Intelligent Systems (GCIS). IEEE, 2014.
[2] Dalal N. Histograms of oriented gradients for human detection[J]. Proc of Cvpr, 2005.
[3] Felzenszwalb, Pedro F, Girshick, et al. Object Detection with Discriminatively Trained PartBased Models.[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2010.
[4] Dollar P, Appel R, Belongie S, et al. Fast Feature Pyramids for Object Detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(8):1532-1545.
[5] Krizhevsky A, Sutskever I, Hinton G. ImageNet Classification with Deep Convolutional Neural Networks[C]// NIPS. Curran Associates Inc. 2012.
[6] Hashimoto J, Fukutomi M, Yamauchi H, et al. Pulse Radar Image Simulation with Ray-tracing Model for Underground Objection Detection[J]. IEICE technical report. Communication systems, 1998, 97.
[7] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149.
[8] Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[J]. 2015.
[9] Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox Detector[J]. 2016.
[10] Tian Y, Luo P, Wang X, et al. Deep learning strong parts for pedestrian detection[J]. 2015:1904-1912.
[11] Wang X, Xiao T, Jiang Y, et al. Repulsion Loss: Detecting Pedestrians in a Crowd[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
[12] Zhang S, Wen L, Bian X, et al. Occlusion-aware R-CNN: Detecting Pedestrians in a Crowd[J]. 2018.
[13] Zhou C, Yuan J. Bi-box Regression for Pedestrian Detection and Occlusion Estimation[J]. 2018.