双目立体匹配入门【一】(理论)
文章目录
-
- 参考文章
- 1 专有名词
- 2 双目视觉基础
-
- 1 针孔摄像机模型
- 2 双目交会
- 3 立体测量的基本原理:三角化
- 4 极线约束
- 5 极线校正/立体校正
- 6 立体匹配难点
- 7 立体匹配方法分类
- 8 立体匹配流程
-
- 1 匹配代价计算
-
- 1 代价函数
- 2 代价空间 cost volume
- 2 代价聚合
-
- 1 Box filtering(实际上是一种均值滤波)
- 2 Bilateral filter双边滤波
- 3 Cross-based local stereo matching自适应形状
- 4 Semi-Global Matching(SGM)
- 3 视差计算
- 4 视差优化/后处理
-
- 1 左右一致性检测(LRC)
- 2 Speckle Filter
- 3 亚像素插值
- 9 端到端视差计算网络
- 10 立体视觉方法评测网站
- 11 立体匹配算法的应用
参考文章
1.双目视觉简介
2.学习笔记-双目立体视觉简介
3.立体匹配算法原理与应用-奥比中光
4.双目立体匹配-江佩视觉
5.立体匹配理论与实战(答疑版)(12:00正片~)
6.双目立体匹配之匹配代价计算
7.Birchfield和Tomasi方法(BT方法)小结
8.窗口代价计算视差及NCC视差匹配实现
9.立体匹配 之 代价聚合 滤波器篇
10.【算法理论】经典AD-Census: (2)十字交叉域代价聚合
11.立体匹配的后续处理:左右检测+遮挡填充+中值滤波
12.入门 | Stereo Vision(四)立体匹配的代价计算和聚合_爱吃糖的小北的博客-CSDN博客_立体匹配代价聚合
本文github下载地址(网页在该文件基础上又增加了一些内容,建议看网页):lijyhh/Study-notes/Machine vision/
原视频PPT网盘下载地址:
链接:https://pan.baidu.com/s/1xJth7ZzTITdsaLbzu4EQbA
提取码:kypa
建议刚入门的先观看参考资料3,讲的很详细,也通俗易懂,本文也主要是依照该课程做的笔记,但额外补充了一些东西。参考资料4的视频讲的很简单,但是有很多概括性的东西,内容我基本都总结进本文里面了。
参考资料5的内容和资料3基本相似,但侧重点不同,有些地方我都补充进来了。参考资料5虽然写着实战,但还是理论相关,建议3和5只看一种即可。
其他资料都是参考的博文资料。
版权声明:本文只用作学习用途,如有侵权,请联系。
注: 本文内容只是总结了网上一些学习资料,如有疑问,请讨论指正。
1 专有名词
双目立体视觉:Binocular Stereo Vision
对极(极线)几何:Epipolar geometry
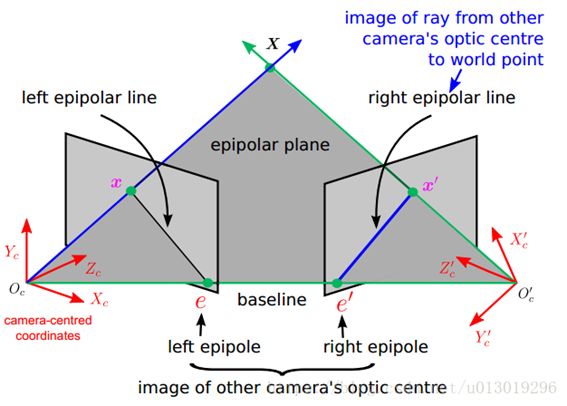
基线(baseline):直线Oc-Oc’为基线。
对极平面束(epipolar pencil):以基线为轴的平面束。
对极平面(epipolar plane):任何包含基线的平面都称为对极平面。
对极点(epipole):摄像机的基线与每幅图像的交点。比如,上图中的点e和e’。
对极线(epipolar line):对极平面与图像的交线。比如,上图中的直线l和l’。
5点共面:点x,x’,摄像机中心Oc Oc’,空间点X是5点共面的。
极线约束:两极线上点的对应关系。
说明:直线l是对应于点x’的极线,直线l’是对应于点x的极线。极线约束是指点x’一定在对应于x的极线l’上,点x一定在对应于x’的极线l上。
立体匹配:校正做完后,就到了correspondence,这一步也叫做stereo matching立体匹配。
直观来说,就是找到左右两幅图中,对应于现实中同一点的点,这样之后,再通过两点间的视差,就可以得到现实中这个点的深度信息。
匹配代价:既然是找两幅图中的相同点,必然要判断两个点之间的相似性,所以要有一个相似性的描述,这个描述我们叫做matching cost匹配代价;然而只从一个点出发是不合理的,因为在图中的像素之间肯定是有联系的,所以需要考虑像素之间的相关性,来优化之前的cost。
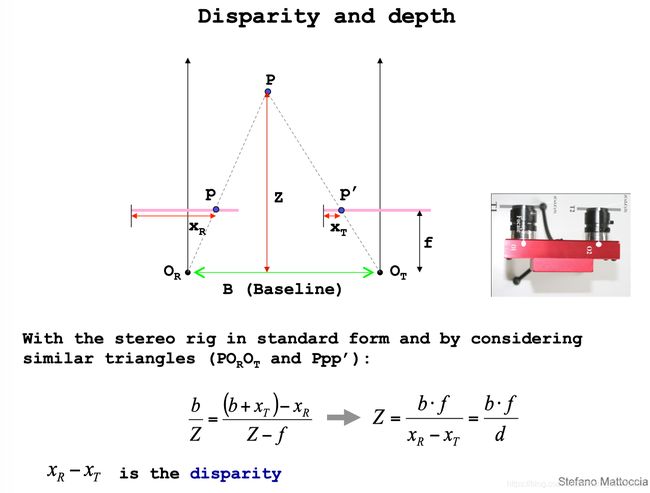
视差:就是求下图中的|XR - XT|
运动恢复结构:Structure from Motion, SfM
DTOF与ITOF的区别
DTOF:直接测量光脉冲的发射与反射时间,得到光的飞行时间;远距离测距精度高,受光线干扰少;成本高,分辨率较差
ITOF:发射调制过的光,发射与接收调制光之间的相位差,计算出距离和深度信息;成本低,近距离精度高,准确度与测量范围不能兼得
SLAM是Simultaneous localization and mapping缩写,意为“同步定位与建图”,主要用于解决机器人在未知环境运动时的定位与地图构建问题。
2 双目视觉基础
概论: 立体匹配是通过已知外参的相机,根据极线约束寻找真实空间中的同名点,然后再对这个空间上的点进行深度估计。
对于双目相机,我们一般通过立体校正,把两个不共面的相机调整成共面行对准,即把两个相机的成像平面调整到同一个平面上,保证两辅助像的每一行是相对应的。这样就会把二维搜索问题变成一维搜索问题,所以在寻找匹配关系时,只需要在两幅图像的同一行进行搜索就可以,同时也可把求解深度的问题转化成求解视差的问题。然后通过求解同一个点在两幅图像上横坐标的差值,来确定这个点在真实空间的深度。
1 针孔摄像机模型
从3D到2D的投影是确定的。
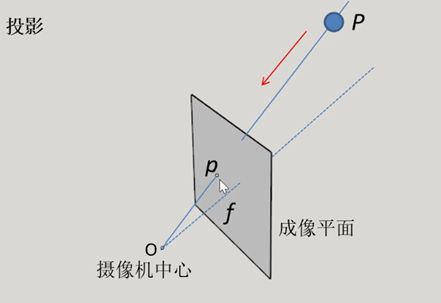
根据一幅图像中的2D像素坐标,只能确定一条射线。所以通过一张图片实现不了一般的三维重建。

2 双目交会
根据2幅图像中的一对同名点,可以确定2条射线。由它们的交点,可确定目标点的三维坐标。

3 立体测量的基本原理:三角化
视差:Disparity,极线纠正后,同名点位于同一行内,行坐标相同,只存在列坐标偏差,叫做视差。通过任一视图的像素坐标以及视差,即可计算其在另一视图的同名点。d=XR-XT。XR为左视图横坐标,XT为右视图横坐标,即视差=左视图-右视图横坐标。
存储每个像素视差值的图像叫做视差图(disparity map)。以像素为单位
视差图可结合基线和相机内参计算深度图(depth map)。是空间单位
视差(disparity)和深度(depth)是一一对应的关系。


d为视差,Z为深度,T为机械长度。
所以只需要在一个双目系统中给定一个像素点,如果能找到在另一幅图像中的坐标,根据视差值就可以恢复三维场景的结构。找对应点的过程即立体匹配。

图为离散化的视差与深度平面,视差之间的间隔为1个像素
深度值越大,视差值越小
深度值越大,同样的视差范围,对应的深度范围越大
所以某些算法离相机越远,深度偏离就越远,误差就越大,空间精度就越差
4 极线约束

并不是漫无目的的在整幅图像上寻找对应点(即不是2D查找),而是通过极线约束,在其对应的极线上进行一维搜索即可。
具体极线约束请看上面解释。
5 极线校正/立体校正
为了在匹配的时候方便进行搜索,需要先进行极线校正(原本极线不是水平的,给他较成水平的,搜索时只需在水平线上搜索,Y方向是不动的)。
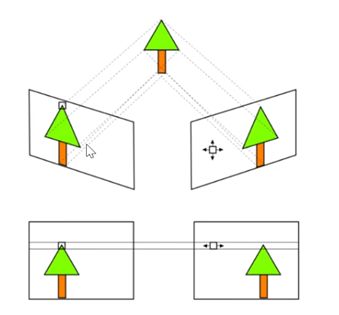
- 使左右相机的X轴与基线平行
- 相机光轴与基线垂直
- 使左右相机具有相同的焦距
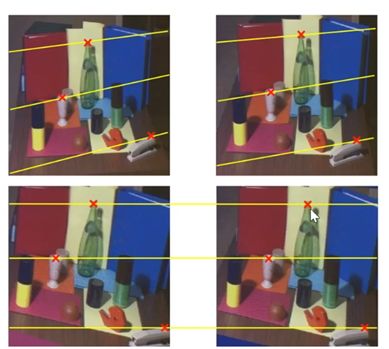
6 立体匹配难点


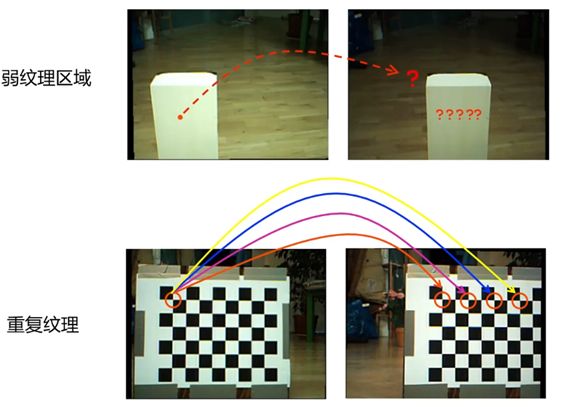

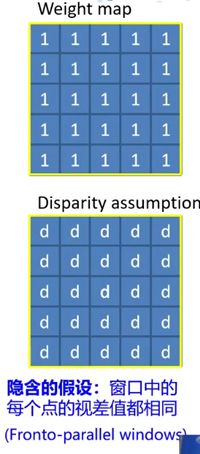
经典假设:
(1)窗口内像素视差相同

(2)像素p的视差只和其邻域像素有关(马尔可夫性)

(3)相近颜色像素具有相近视差

(4)视差非连续边界具有色差或亮度差

7 立体匹配方法分类

直接块匹配的问题:存在冗余计算

8 立体匹配流程
四个步骤

代价聚合是在一个3D的代价空间来做的。
- 代价计算是衡量两个同名点的不相关性,两个像素点越不相关,代价就越大,反之则越小,代价计算的目的就是找到最小的代价对应的同名点。代价计算一般会提出一些与亮度相互比较相关的函数,如AD等。不需要太准,只要能反映一定的相关性即可。
- 全局算法只有三步,没有代价聚合。

- 代价聚合:把领域像素的代价做一个考虑,然后以某种方式聚合到中间(给中间做个贡献),最后算出中间像素聚合代价值。即不单单只考虑这个像素的代价,而是要考虑周围像素的代价,使其变得更加鲁棒。
- 赢家通吃:统计一个最小匹配代价值,然后把最小匹配代价值所对应的视差值当做真值输出出来。
- BP/GC/DP/CO等都是全局算法,没有第二步代价聚合。如果做了代价聚合,一般通过赢家通吃就可以把真实代价定位出来。

图分别为初始代价计算结果、代价聚合结果、视差优化结果
学习时从经典文章入局:
Semi-global Matching [1] ,最经典应用最广泛的算法
AD-Census [2] ,效果好,速度快,Intel RealSense D400
PatchMatch [3] ,倾斜窗口模型的经典之作
MC-CNN [4] ,基于学习的开山之作
[1] Heiko Hirschmüller. Stereo Processing by Semiglobal Matching and Mutual Information[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 30.
[2] Mei X , Sun X , Zhou M , et al. On building an accurate stereo matching system on graphics hardware[C]// IEEE International Conference on Computer Vision Workshops. IEEE, 2012.
[3] Bleyer M , Rhemann C , Rother C . PatchMatch Stereo - Stereo Matching with Slanted Support Windows[C]// British Machine Vision Conference 2011. 2011.
[4] Žbontar, Jure, Lecun Y . Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches[J]. 2015.
1 匹配代价计算
立体匹配的第一步———匹配代价计算,如AD、AD-cencus等等。这一步是要描述两个像素点的相似性,朴素的想法就是直接计算两个点像素值的差异,但是这种简单的算法因为只从一个点考虑,往往容易受到噪声的影响,于是有优化方法是放一个window,计算其中的点的像素差值之和。但是这种基于像素值的算法,会对光线和畸变十分敏感,产生一定误差。于是有一些不基于像素值的算法,如census算法和Rank变换等。因为不是基于像素值,而是基于点之间的关系,所以census方法有抗光畸变,效率高稳定等优点。
通过这些方法我们可以得到一个代价矩阵C(DSI,Disparity Space Image,暂且翻译为视差空间图像,是一种保存左、右立体视图在视差空间中匹配代价的辅助图像),矩阵C中存储了每个像素在视差范围内每个视差下的匹配代价值。
传统方法一般使用图像的灰度信息来进行判断,同时也有用卷积神经网络的方法来进行图像块之间相似度的计算,即对输入左右视图的图像块,经过一个全值共享的特征提取的网络,再把这两个图像块的特征拼接在一起,最后输出相似度。

代价函数用于计算左、右图中两个像素之间的匹配代价(cost,也即相似性、匹配度)。
cost越大,表示这两个像素为对应点的可能性越低。
1 代价函数
- AD(Absolute Difference)代价:两个像素值相减。
AD算法是匹配代价计算中最简单的算法之一,其主要思想是不断比较左右相机中两点的灰度值大小,首先固定左相机中的一点,然后遍历右相机中的点,不断比较它们之前的灰度之差,灰度之差即为匹配代价。其数学公式为:
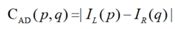
其中,p、q分别为左右图像中的两点,IL()表示左图像中的灰度值,同理IR()表示右图像中的灰度值。上式为灰度图像的匹配代价;若为彩色图像,则AD算法计算代价的公式为:
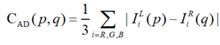
即左右视图像素点的三个颜色分量之差的绝对值取平均。
AD算法是基于单个像素点计算的匹配代价,受光照不均、图像噪声影响较大,但对纹理丰富区域有较好的匹配效果。

BT的代价(Birchfield和Tomasi的方法)也是像素灰度值差值的绝对值,不同之处在于BT利用了亚像素的灰度信息。
BT代价:考虑了像素点采样误差,比AD更可靠一点。

上图所示的是一段图片的匹配序列,可以看到中间的一段序列是连续的,而左右两边则与中间是不连续的。如果我们利用采样方法对图片中的像素计算代价时,可以推测中间一段的采样代价会较低且平稳,而与左右两边不连续的像素点采样时,会出现较大的代价。
但是在图示情况下,不连续的像素也仅仅是相差几个像素点,而不是差的特别多。因此如果在处理这种不连续情况下,仍能保持较低的代价值,是我们所要提升的。
图示像素情况经常在物体实际上连续或具有坡度时出现。
具体原理查看:Birchfield和Tomasi方法(BT方法)小结
-
AD+梯度,在下面论文中出现。



-
Census
优点:计算简单;对灰度变化具有鲁棒性。
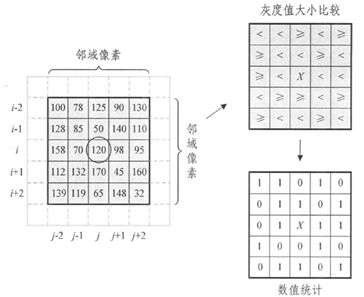
Census变换以像素灰度的相对值作为匹配的相似性测度,整个变换只是简单的数据比较、累加、异或等,不需要乘法和开方等复杂运算。Census变换首先在匹配窗口内以某一个像素为中心取一个Census矩形变换窗口,然后矩形变换窗口内各邻域像素的灰度值分别与中心像素的灰度值进行比较,如果该像素的灰度值比中心像素的灰度值小,则比特串相应位置的值记为1,反之记为0。其具体定义如下:
假设以匹配窗口(i, j)处的像素为中心像素,取一个大小为n * n的Census变换窗口,则相应的Census变换IC(i, j)用比特串的形式可以表示为:
![]()
![]()
参数bk的值可以用下式表示为:

其中,I(i, j)为图像第i行第j列像素的灰度值,[k/n]表示k整除n;k mod n表示取k除n的模。
如图2-3所示,匹配窗口的大小为7 * 7像素,在其区域内取一个大小为5 * 5像素的矩形变换窗口,中心像素的灰度值为120,各邻域像素的灰度值如图所示。Census变换后的比特串为110100110101111001001101。

若Census变换后还要进行立体匹配,则在视差搜索范围内,对于每一个视差值,通常还需要根据下式计算参考图像Census变换窗口与匹配图像Census变换窗口的Hamming距离(实际通过异或就可得到汉明距离),即两个Census比特串的不同的比特数。对于每一个匹配窗口,计算该窗口的Hamming距离和,那么在视差搜索范围内,Hamming距离和最小的匹配窗口的索引号即为该匹配点的视差。
![]()
其中I1(i, j)、I2(i+d, j)分别表示参考图像Census变换窗口与匹配图像Census变换窗口的比特串;d为视差搜索范围,dmin ≤ d ≤ dmax(dmin为最小视差,dmax为最大视差)。i、j分别为参考图像Census变换窗口中心像素的图像横坐标和纵坐标。

-
NCC(互相关归一化,Normalized Cross-correlation)
常用的代价函数,先把33图像块转成19向量,对该向量求均值,然后求模归一化,再点积。
特性:对图像亮度的线性变化具有不变性
物理意义:两个向量的夹角的余弦值

对于原始的图像内任意一个像素点(px, py)构建一个n×n的邻域作为匹配窗口。然后对于目标相素位置(px+d, py)同样构建一个n×n大小的匹配窗口,对两个窗口进行相似度度量,注意这里的d有一个取值范围。对于两幅图像来说,在进行NCC计算之前要对图像处理,也就是将两帧图像校正到水平位置,即光心处于同一水平线上,此时极线是水平的,否则匹配过程只能在倾斜的极线方向上完成,这将消耗更多的计算资源。

与上面那个式子一样的,只是形式不同。
其中NCC(p, d)得到的值得范围将在[−1,1]之间。
Wp为匹配窗口,I1(x, y)为原始图像的像素值,I1¯(px, py)为原始窗口内像素的均值,I2(x+d, y)为原始图像在目标图像上对应点位置在x方向上偏移d后的像素值,I2¯(px+d, py)为目标图像匹配窗口像素均值。
若NCC=−1,则表示两个匹配窗口完全不相关,相反,若NCC=1时,表示两个匹配窗口相关程度非常高。 -
AD+Census

AD代价函数容易实现,但是它容易受亮度差异的影响。
而在Census变换中,不要求像对之间的颜色一致性。因此,它对于辐射差异更加鲁棒。
AD-Cencus是将AD和Census结合,这样就能对两种方式起到一个互补作用。Cencus算法对重复纹理的效果不好,而AD算法是基于单像素的,可以在一定程度上缓解Cencus算法对重复纹理处理棘手的问题。但是将两种算法结合存在算法结果尺度不一致的问题,需要进行归一化处理。AD的结果是亮度差,范围是[0,255],而Census是比特串对应位值不相同的个数,范围为[0,N](N等于比特串的位数)。因此,需要通过归一化,将两者的结果归一化到相同的范围区间,AD-Census所采用的方法是一个值区间在[0,1]的自然指数函数:

其中c是代价值,λ是控制参数,当c和λ都为正值时,这个函数的值区间在[0,1]的。并且c即代价值越大,函数值越大。因此可以通过该函数将任意代价值归一化到[0,1]的范围。
最终,AD-Census的代价计算公式为:
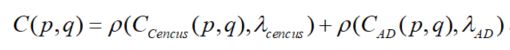
两个结果进行归一化后,最终的结果范围为[0,2]。
6. CNN

![]()

代价空间是通过CNN来算的,但聚合采用的都是传统方法,所以不是端到端的方法。

- Rank变换
Rank变换是在匹配窗口中以某一个像素为中心取一个Rank矩形变换窗口,并统计Rank矩形变换窗口中像素的灰度值比中心像素的灰度值小的像素个数R§。其具体定义如下:
设I(x, y)表示像素P(x,y)的灰度值,N§表示匹配窗口中以像素P(x, y)为中心的矩形变换窗口内像素的集合,R§表示矩形变换窗口N§中含有像素灰度值小于I(x, y)的元素的个数。则像素P(x, y)的Rank变换可以用下式表示。

如所示为Rank变换的一个具体实例,匹配窗口的大小为77像素,在其区域内取一个大小为55像素的矩形变换窗口,中心像素的灰度值为120,各邻域像素的灰度值如图所示。矩形变换窗口内各邻域像素的灰度值与中心像素的灰度值进行比较,然后统计灰度值比中心像素灰度值小的像素个数为14,所以Rank变换的值R§=14。若还要进行立体匹配,则在视差搜索范围内,针对每一个视差值,需要求出除待匹配点外的匹配窗口内所有像素Rank变换后的值,然后再进行基于局部的互相关立体匹配,求出视差值。
综上所述,无论是Rank变换,还是Census变换,它们只依赖于变换窗口内邻域像素的欠度值和中心像素的灰度值的大小比较关系,即使像素的灰度值因为噪声而发生很大变朴上,Rank变换和Census变换的相应值也只变化1。因此,非参数变换在图像有很强的噪声扰和光照条件不理想时进行立体匹配非常有效。而且,Rank变换和Census变换易于用硬件实现,在工程技术领域得到了广泛的应用。
2 代价空间 cost volume
以AD为例,建立一个代价空间

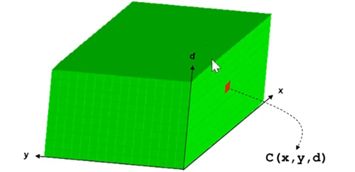
代价空间和sliding-window之间的关系


在代价空间里面设计一些算法,可以减少冗余计算。
2 代价聚合
由于代价计算步骤只考虑了局部的相关性,对噪声非常敏感,无法直接用来计算最优视差,所以SGM算法通过代价聚合步骤,使聚合后的代价值能够更准确的反应像素之间的相关性,如图1所示。只有局部匹配算法和半全局匹配算法(SGM)需要进行代价聚合,全局匹配算法是不需要的。每个像素在某个视差下的新代价值都会根据其相邻像素在同一视差值或者附近视差值下的代价值来重新计算,得到新的DSI,用矩阵S来表示。这是基于同一深度的像素有相同的视差值的先验知识。
代价聚合也可以理解为视差的传播,让信噪比高的区域的视差传播到信噪比低的区域,使所有点的代价都能较好地表示真实的相关性。聚合后的新的代价值保存在与匹配代价空间C同样大小的聚合代价空间S中,且元素位置一一对应。

常用的方法:扫描线法、动态规划法、SGM算法中的路径聚合法。
1 Box filtering(实际上是一种均值滤波)
上述方法代价空间噪声很重,需要对代价空间在视差平面上进行滤波,

Box Filtering主要功能是在给定的滑动窗口大小下,对每个窗口内的像素值进行相加求和,均值滤波的快速算法。初始化过程如下:
- 给定一张图像,宽高为(M, N),确定待求矩形模板的宽高(m, n),如图紫色矩形。图中每个黑色方块代表一个像素,红色方块是假想像素。
- 开辟一段大小为M的数组,记为buff, 用来存储计算过程的中间变量,用红色方块表示。
- 将矩形模板(紫色)从左上角(0, 0)开始,逐像素向右滑动,到达行末时,矩形移动到下一行的开头(0, 1),如此反复,每移动到一个新位置时,计算矩形内的像素和,保存在数组A中。以(0, 0)位置为例进行说明:首先将绿色矩形内的每一列像素求和,结果放在buff内(红色方块),再对蓝色矩形内的像素求和,结果即为紫色特征矩形内的像素和,把它存放到数组A中,如此便完成了第一次求和运算。
- 每次紫色矩形向右移动时,实际上就是求对应的蓝色矩形的像素和,此时只要把上一次的求和结果减去蓝色矩形内的第一个红色块,再加上它右面的一个红色块,就是当前位置的和了,用公式表示 sum[i]=sum[i−1]−buff[x−1]+buff[x+m−1]sum[i]=sum[i−1]−buff[x−1]+buff[x+m−1]
- 当紫色矩形移动到行末时,需要对buff进行更新。因为整个绿色矩形下移了一个像素,所以对于每个buff[i], 需要加上一个新进来的像素,再减去一个出去的像素,然后便开始新的一行的计算了。

2 Bilateral filter双边滤波


具有保持边缘的特性窗口可以开的更大,匹配更稳定

双边滤波器(Bilateral filter)就是对窗口内像素进行距离加权和亮度加权。双边滤波是一种可以保边去噪的滤波器,之所以可以达到此去噪效果,是因为滤波器是由两个函数构成。一个函数是由几何空间距离决定滤波器系数,另一个由像素差值决定滤波器系数。
双边滤波器中输出(i, j)位置的像素值g依赖依赖于邻域内像素值f的加权组合(k, l表示邻域像素位置):
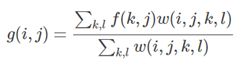
权重系数w(i, j, k, l)取决于定义域核d与值域核r的乘积:

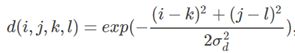
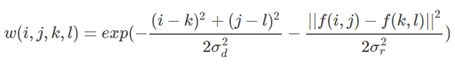
3 Cross-based local stereo matching自适应形状
基于十字叉的局部滤波

十字交叉域代价聚合(Cross-Based Cost Aggregation,CBCA)基于一个假设:相邻的颜色相近的像素有相近的视差值。如果参与聚合的像素和被聚合的像素具有相同的视差值,那么聚合的可靠性会更高。基于此,CBCA的目标是找到像素p周围和其颜色相近的像素,并以某种规则将它们的代价值聚合到p的代价上。
十字的含义是每个像素都会有一个十字臂,臂上的所有像素颜色(亮度)值和该像素的颜色(亮度)值相近,如图所示。

从图中可以看到十字臂构造的两个规则:
- 像素的十字臂以像素为中心往左右及上下延伸,碰到颜色(亮度)和该像素差别较大时停止延伸。
- 十字臂也不能无限制延伸,它必须限制一个最大长度。
即颜色和长度是两个限制臂长的因素,以左臂延伸为例: - Dc(pl, p) < τ,Dc(pl, p)是pl和p的颜色差异,τ是设定的阈值。颜色差异的定义是

即三个分量差值的最大值。 - Ds(pl, p) < L,Ds(pl, p)是pl和p的空间长度,L是设定的阈值。空间长度的定义是Ds(pl, p) = |pl - p|,以像素为单位。
右臂、上臂、下臂的延伸规则和左臂一样。当每个像素的十字臂构造成功,就可以构造像素的支持区域(Support Region),构造方法如下:
像素p的支持区域是合并其垂直臂上的所有像素的水平臂,如图所示:
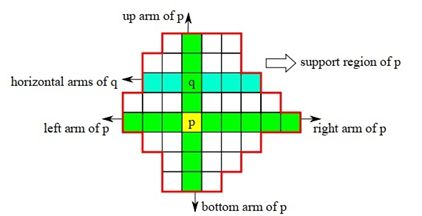
q是p的垂直臂上的某个像素,p的支持区域就是所有q(包括p自身)的水平臂的并集。
4 Semi-Global Matching(SGM)

Cp,Dp是代价空间中的某一个点。P1,P2是外部输入常量,T是指示函数。

只考虑某个方向(例如从左到右),有一个路径代价Lr。
3 视差计算
在有了匹配代价之后,可以通过寻找匹配代价最小的视差位置来确定当前视差,但这种一般会受到图像噪声影响。因此前面需要代价聚合来调整初始匹配代价。
-
Winner-Take-All(WTA)

-
Disparity Propagation(PatchMatch)
不会构建完整的代价空间。

4 视差优化/后处理
- 左右一致性检测(LRC)
- the minimum / the second minimum cost
- Speckle Filter
- 亚像素插值
- 中值滤波
- 空洞填充
- 加权中值滤波
1 左右一致性检测(LRC)
从左匹配到右,再从右匹配到左,看是否重叠,或者在阈值内。
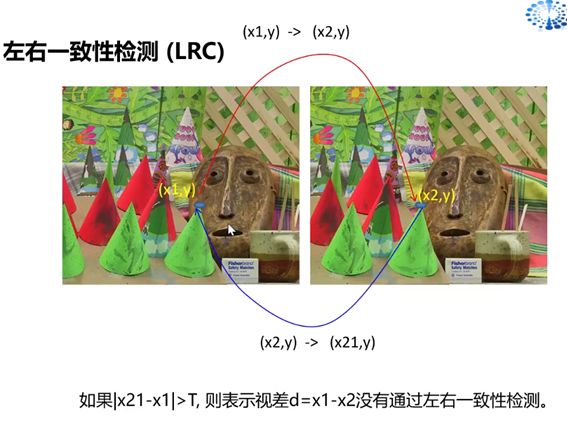
LRC check(左右一致性检查)的作用是实现遮挡检测(Occlusion Detection),得到左图对应的遮挡图像。遮挡(Occlusion),顾名思义是只出现在一幅图像,而在另一幅图中看不到的那些点。在立体匹配算法中如果不针对遮挡区域做一些特殊处理是不可能通过单幅图提供的有限信息得到遮挡点的正确视差的。遮挡点通常是一块连续的区域,记作occluded region/area。
LRC具体做法:根据左右两幅输入图像,分别得到左右两幅视差图。对于左图中的一个点p,求得的视差值是d1,那么p在右图里的对应点应该是(p-d1),(p-d1)的视差值记作d2。若|d1-d2|>threshold,p标记为遮挡点(occluded point)。
如图依次是,左图的视差图,右图的视差图,teddy左图,左图对应的二值遮挡图。

得到了二值的遮挡图像,之后是为所有黑色的遮挡点赋予合理的视差值。对于左图而言,遮挡点一般存在于背景区域和前景区域接触的地方。遮挡的产生正是因为前景比背景的偏移量更大,从而将背景遮盖。
具体赋值方法是:对于一个遮挡点p,分别水平往左和往右找到第一个非遮挡点,记作pl、pr。点p的视差值赋成pl和pr的视差值中较小的那一个。d§= min (d(pl),d(pr)) (Occluded pixels have the depth of the background)。
图依次是左图的视差图,进行occlusion filling后的视差图。

这种简单的Occlusion Filling方法在遮挡区域赋值方面效果显著,但是对初始视差的合理性和精度依赖较高。而且会出现类似于动态规划算法的水平条纹,所以其后常常跟着一个中值滤波步骤以消除条纹。图是中值滤波的结果。

通过LRC check检测出遮挡点,对其进行视差估计,再对整幅图做中值滤波,得到的结果就好多了。
2 Speckle Filter
为了移除噪声点,对视差图做一个连通区域提取(如果某相邻的2个像素的视差值之差小于某个预先设定的阈值,就可以认为这两个像素属于同一个区域)。

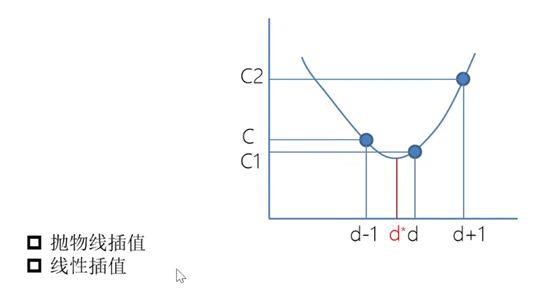
3 亚像素插值
9 端到端视差计算网络
由于立体匹配存在许多挑战,如弱纹理、遮挡等,因此才有端到端立体匹配网络。目的主要是从立体图像对中直接生成视差,避免了人为设计函数,相当于立体匹配的整个流程都是通过学习得到的。主要分为两类:基于二维卷积的方法和基于三维卷积的方法。
二维:DispNet(2016) 、CRL(2017)、FADNet(2020)
三维:GCNet(2017)、PSMNet(2018)、GANet(2019)
在这些网络中有个通用策略:对于视差估计要尽可能结合多尺度信息,如果是弱纹理区域,则需要把搜索的窗口扩大,就可以通过周围一些非纹理的信息进行推断。如果图像框选的比较小,则对于一些细小结构会有比较强的重现能力。
与之相应,在深度学习中经常使用的一种结构就是编码解码结构(Encoder-Decoder),即先通过对图像进行卷积来降采样,然后再用反卷积进行上采样,在上采样时把开始的结果和上采样之前的结果拼接到一起来进行处理,相当于对信息进行一种补充,以避免上采样过程中造成的信息丢失。

![]()
- Disp-Net(2016)
复用了15年光流的一个网络(flow-net),光流要估计x和y两个方向的偏移,而立体匹配只需要估计一个方向的,因为做了立体校正,只需估计x方向的,没有代价空间。


也是从图像恢复出视差,但用了一个相关操作把右视图和左视图的匹配信息融合进去了,这个操作也即特征向量的点积(把特征向量按对应元素相乘再求和)。

实现过程:先假定一个左视图某个像素在右视图的视差范围,然后把右视图上这一范围内所有的特征向量拿过来和左视图上该像素的特征向量点积。如果范围是0-40,则得到40个标量,然后将这40个标量当成一个通道拼接到左视图特征上,然后用卷积处理恢复出视差图。
![]()

- CRL
采用了两个编码解码结构(DispFulNet)来恢复视差,第一个DispFulNet用来估计初始的视差图,后面的DispFulNet用来估计误差。然后把初始视差图和误差相加得到最终的视差。


● FADNet

![]()
- GC-Net(2017)
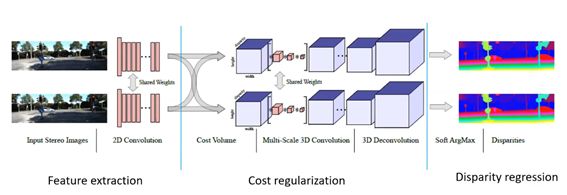
将整个网络结构分成了三部分:特征提取,代价聚合和视差回归。
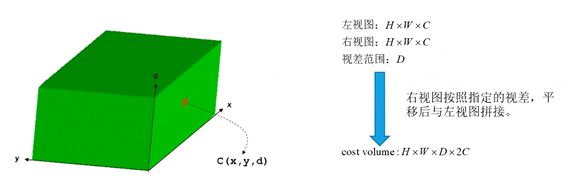
会生成一个四维的代价空间,把代价空间用网络来实现,里面设计了一个可微取最小值的函数。
将左右视图的特征图按照当前假设的视差把右视图进行平移与左视图进行拼接得到。即如果左右视图提取出的特征通道数都是C的话,则到了代价空间就会变成2C的通道,然后根据选定的视差范围就会多一个视差上的维度。
为了对视差进行分配,传统的寻找视差最小值的方法是不可导的,所以它把代价空间从64个通道用三维卷积降成1个通道,就变成长×宽×视差,认为是最终的匹配代价。再把这些匹配代价转化成概率,然后在视差范围上求期望,通过求期望来得到最终的视差值。解决了不可导的问题(即网络不能训练),也可以估计出亚像素精度的视差。

- iRestNet(2018)
把后处理加到了网络里面来。 - PSM-Net(2018)
是GC-Net的改进:特征提取部分加了SPP Module,即通过选取不同尺寸的池化层来得到多个尺度下的信息,然后拼接起来作为输出特征。
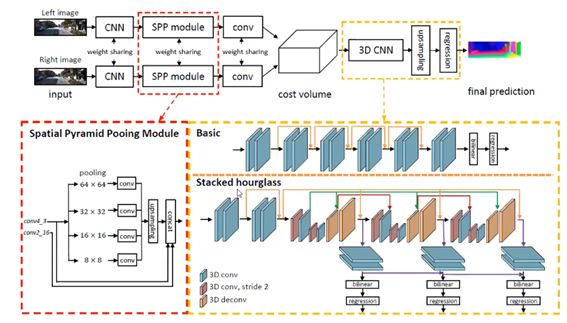
此外,在三维卷积处理代价空间时使用了stacked hourglass的结构。是通过多个编码解码结构堆叠而成的,通过残差连接的方式从前到后传递信息。


该方法的好处就是每一个hourglass的输出就是每个想要的结果,通过堆叠hourglass的结构相当于在已有的结果上进一步优化。训练时可以采用中继监督的策略,即对每一个子网络的输出都计算一遍损失函数,然后加到一起作为最终损失。这种方式可以加速模型收敛与剪枝(剪枝意思是只能在训练之后删掉后面的某一部分,不能在训练时删掉)。
![]()
-Stereo-Net(2018)
-
GA-Net(2019)
在三维卷积代价聚合过程中引入了两个新的结构,都是基于传统方法的改进:半全局代价聚合和局部代价聚合。这两个层的参数都是通过上端的子网络由特征提取出来的。 -
EdgeStereo(2020)
10 立体视觉方法评测网站
● Middlebury Stereo 3.0 高分辨率一些图片
● Kitti 2012/2015 自动驾驶,室外场景
● SceneFlow合成数据集,不是真实的
● ISPRS航空航天
● ETH3D
● Robust Vision Challenge
11 立体匹配算法的应用

![]()
