R语言train函数调参(caret包)
文章目录
- 一、步骤
- 二、演示
一、步骤
(1)确定最优参数的大致范围(粗调)。train函数中的方法刚一开始都有默认的参数,由于我们也都不知道最优的参数是什么,所以可以先直接使用默认的参数进行调参。
(2)确定参数范围之后,进一步缩小最优参数的范围(精调)。这一个过程可以无限重复,直到选出你认为最好的参数"_",过程有点粗暴。
二、演示
以一个简单的PM2.5数据来演示整个调参过程:
1、导入数据
rm(list = ls())
data<-read.csv("C:\\data\\PM2.5.csv",sep=",",head=TRUE)
len = length(data)
traindata <- data[,1:len-1] #x值
trainClass <- data[,len] #y值
2、使用xgblinear方法来进行回归分析(粗调)
#xgblinear
set.seed(1)
fit_xgblinear<- train(traindata,
trainClass,
method = "xgbLinear", #这里可以设置使用的模型
trControl = trainControl(method = "cv",number = 10,search = "grid"), #使用十折交叉验证
metric = "Rsquared")
summary(fit_xgblinear)
fit_xgblinear
fit_xgblinear$bestTune
# fit_xgblinear$finalModel
fit_xgblinear$results
plot(fit_xgblinear)
运行结果:


从运行结果来看,R方最高为0.7147,此时对应的参数是nrounds = 100, lambda = 0.1, alpha = 0 and eta = 0.3,我们将以这组参数为基础进行后续的精调。关于train函数中方法参数的具体情况,可以参阅网址:http://topepo.github.io/caret/train-models-by-tag.html。
3、进一步缩小参数范围(精调)。指定的参数范围尽可能在上面参数的附近(nrounds = 100, lambda = 0.1, alpha = 0 and eta = 0.3),因此这里我们将nrounds =100 , lambda = seq(0,2.0,0.2), alpha =seq(0,1.0,0.1) and eta =0.3 ,从中我们找到更为优秀的模型。
#xgblinear
tune_xgbLinear <- expand.grid(lambda = seq(0,2.0,0.2),
alpha = seq(0,1.0,0.1),
nrounds = 100,
eta = 0.3) #这里可以指定每一个参数的范围
set.seed(1)
fit_xgblinear<- train(traindata,
trainClass,
method = "xgbLinear", #这里可以设置使用的模型
trControl = trainControl(method = "cv",number = 10,search = "grid"),
metric = "Rsquared",
tuneGrid = tune_xgbLinear)
summary(fit_xgblinear)
fit_xgblinear
fit_xgblinear$bestTune
# fit_xgblinear$finalModel
fit_xgblinear$results
运行结果:

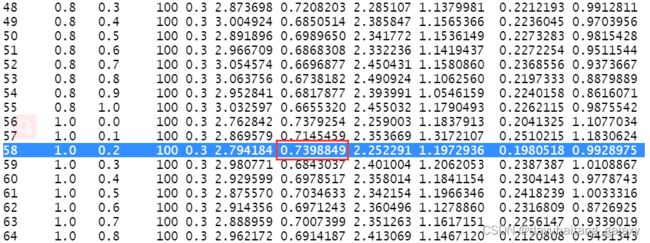
从精调的结果来看,此时的R方为0.7398,相较于上一套参数,模型要更为优秀。以此类推,精调的过程可以无限重复,通过不断缩小参数范围总会找到一套最优参数。我这里模型的判断标准为R-square,其中也可以使用RMSE等指标,这点根据个人需要进行设置即可。