深度学习实战01:搭建神经网络五部法
1 步骤
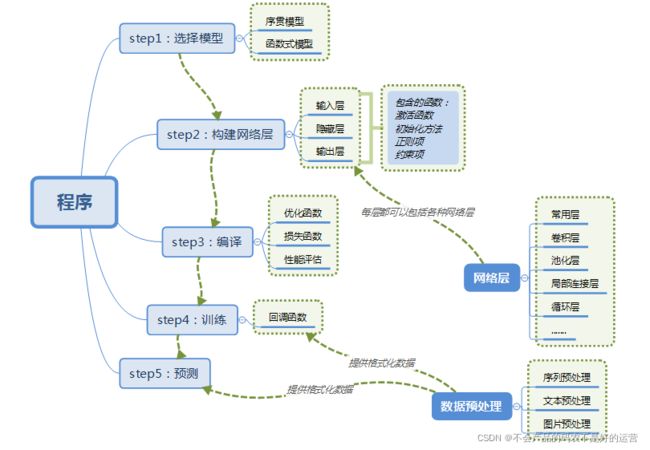
1.1 选择模型
Keras有两种类型的模型,序贯模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。
a)序贯模型(Sequential):单输入单输出,一条路通到底,层与层之间只有相邻关系,没有跨层连接。这种模型编译速度快,操作也比较简单
b)函数式模型(Model):多输入多输出,层与层之间任意连接。这种模型编译速度慢。
1.2 搭建网络
- 拉直层:tf.keras.layers.Flatten()
拉直层可以变换张量的尺寸,把输入特征拉直为一维数组,是不含计算参数的层。 - 全连接层:tf.keras.layers.Dense( 神经元个数,activation=”激活函数”,kernel_regularizer=”正则化方式”)
其中:
– activation(字符串给出)可选 relu、softmax、sigmoid、tanh 等
– kernel_regularizer 可选 tf.keras.regularizers.l1()、tf.keras.regularizers.l2() - 卷积层:tf.keras.layers.Conv2D( filter = 卷积核个数,kernel_size = 卷积核尺寸,
strides = 卷积步长,padding = “valid” or “same”) - LSTM 层:tf.keras.layers.LSTM()。
1.3 编译
Model.compile( optimizer = 优化器, loss = 损失函数, metrics = [“准确率”])。
- optimizer 可以是字符串形式给出的优化器名字,也可以是函数形式,使用函数
形式可以设置学习率、动量和超参数。
可选项包括:
– ‘sgd’ or tf.optimizers.SGD( lr=学习率,decay=学习率衰减率,momentum=动量参数)
– ‘adagrad’ or tf.keras.optimizers.Adagrad(lr=学习率,decay=学习率衰减率)
– ‘adadelta’ or tf.keras.optimizers.Adadelta(lr=学习率,decay=学习率衰减率)
– ‘adam’ or tf.keras.optimizers.Adam (lr=学习率,decay=学习率衰减率) - Loss 可以是字符串形式给出的损失函数的名字,也可以是函数形式。
可选项包括:
– ‘mse’ or tf.keras.losses.MeanSquaredError()
– ‘sparse_categorical_crossentropy’ or tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False)
损失函数常需要经过 softmax 等函数将输出转化为概率分布的形式。from_logits 则用来标注该损失函数是否需要转换为概率的形式,取 False 时表示转化为概率分布,取 True 时表示没有转化为概率分布,直接输出。 - Metrics 标注网络评测指标。
可选项包括:
– ‘accuracy’:y_和 y 都是数值,如 y_=[1] y=[1]。
– ‘categorical_accuracy’:y_和 y 都是以独热码和概率分布表示。如 y_=[0, 1, 0], y=[0.256, 0.695, 0.048]。
– ‘sparse_ categorical_accuracy’:y_是以数值形式给出,y 是以独热码形式给出。 如 y_=[1],y=[0.256, 0.695, 0.048]。
1.4 训练
model.fit(训练集的输入特征
,训练集的标签
, batch_size
, epochs
, validation_data = (测试集的输入特征,测试集的标签)
, validataion_split = 从测试集划分多少比例给训练集
, validation_freq = 测试的 epoch 间隔次数)
断点续训
借助 tensorflow 给出的回调函数,直接保存参数和网络
tf.keras.callbacks.ModelCheckpoint(filepath=路径文件名,
save_weights_only=True,
monitor='val_loss', # val_loss or loss
save_best_only=True)
history = model.fit(x_train, y_train
, batch_size=32
, epochs=5
, validation_data=(x_test, y_test)
, validation_freq=1
, callbacks=[cp_callback])
monitor 配合 save_best_only 可以保存最优模型,包括:训练损失最小模型、测试损失最小模型、训练准确率最高模型、测试准确率最高模型等。
import tensorflow as tf
import os
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
])
model.compile(optimizer='adam',
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics='sparse_categorical_accuracy')
checkpoint_save_path = "./checkpoint/mnist.ckpt"
if os.path.exists(checkpoint_save_path+'.index'):#如果保存过模型,会有.index后缀的文件
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path
,save_weights_only=True
,save_best_only=True)
history = model.fit(x_train, y_train
,batch_size=32
,epochs=5
,validation_data=(x_test, y_test)
,validation_freq=1 #指使用验证集实施验证的频率。当等于1时代表每个epoch结束都验证一次
,callbacks=[cp_callback])
1.5 summary
1.5.1 输出权重
1、打印权重
提取可训练参数
model.trainable_variables 模型中可训练的参数
2、设置 print 输出格式
np.set_printoptions(precision=小数点后按四舍五入保留几位
,threshold=数组元素数量少于或等于门槛值,打印全部元素;
否则打印门槛值+1 个元素,中间用省略号补充)
np.set_printoptions(precision=5)
print(np.array([1.123456789])) # [1.12346]
np.set_printoptions(threshold=5)
print(np.arange(10)) #[0 1 2 … , 7 8 9]
注:precision=np.inf 打印完整小数位;threshold=np.nan 打印全部数组元素
import tensorflow as tf
import os
import numpy as np
np.set_printoptions(threshold=np.inf)
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/mnist.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
1.5.2 acc/loss 可视化,查看效果
#调用history属性
acc = history.history['sparse_categorical_accuracy'] 有5个epoch,又因为validation_freq=1,所以总共有5个值
[0.9888166785240173,
0.9910833239555359,
0.9925000071525574,
0.9941166639328003,
0.9950666427612305]
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss'] 也是5个值
val_loss = history.history['val_loss']
1.5.3 predict
predict(输入数据, batch_size=整数) 返回前向传播计算结果
(1)x:输入数据,Numpy 数组(或者 Numpy 数组的列表,如果模型有多个输出)
(2)batch_size:整数,由于 GPU 的特性,batch_size最好选用 8,16,32,64……,如果未指定,默认为 32
(3)verbose: 日志显示模式,0 或 1
(4)steps: 声明预测结束之前的总步数(批次样本),默认值 None
(5)返回:预测的 Numpy 数组(或数组列表)
1.6 预测
2.1 Class类封装网络结构模板
因为Sequential()比较简单,这边采用class类封装网络结构,如下所示是一个 class 模板,MyModel 表示声明的神经网络的名字。括号中的 Model 表示创建的类需要继承 tensorflow 库中的 Model 类。类中需要定义两个函数,init()函数为类的构造函数用于初始化类的参数,spuer(MyModel,self).init()这行表示初始化父类的参数。之后便可初始化网络结构,搭建出神经网络所需的各种网络结构块。call()函数中调用__init__()函数中完成初始化的网络块,实现前向传播并返回推理值。
class MyModel (Model):
def __init__(self):
super(MyModel ,self).__init__()
#初始化模型结构
def call(self,x):
y = self.dl(x)
return y
2.2 iris 数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
data = iris.data
target= iris.target
train_x,test_x,train_y,test_y=train_test_split(data,target,test_size=0.25)
class IrisModel(Model):
def __init__(self):
super(IrisModel,self).__init__()
self.d1 = Dense(3 #d1表示这层的名字
,activation='softmax'
,kernel_regularizer=tf.keras.regularizers.l2())
def call(self,x):
y = self.d1(x)
return y
model = IrisModel()
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(train_x
, train_y
, batch_size=32
, epochs=500
, validation_split=0.2
, validation_freq=20)
选择SparseCategoricalCrossentrop 作为损失函数。由于神经网络输出使用了softmax 激活函数,使得输出是概率分布,而不是原始输出,所以需要将from_logits 参数设置为 False。鸢尾花数据集给的标签是 0,1,2 这样的数值,而网络前向传播的输出为 概率分布,所以 metrics 需要设置未sparse_categorical_accuracy。
2.3 使用 class 实现手写数字识别
class MnistModel(Model):
def __init__(self):
super(MnistModel,self).__init__()
self.flat = Flatten()
self.d1 = Dense(128
,activation='relu')
self.d2 = Dense(10
,activation='softmax')
def call(self,x):
x = self.flat(x)
x = self.d1(x)
y = self.d2(x)
return y
model = MnistModel()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()