【深度学习实战:利用墨尔本十年的温度数据,基于keras框架用循环神经网络LSTM做时间序列预测】
学习笔记,仅供参考!
介绍
RNN是基于序列数据(如语言、语音、时间序列)的递归性质而设计的,是一种反馈类型的神经网络,其结构包含环和自重复,因此被称为“循环”。它专门用于处理序列数据,这里使用的是many to one 的结构类型,输入序列,输出为单个值,类似于之前的文本分类和文本生成或预测时间序列数据。
本文使用的是目前常用的LSTM长短时记忆网络,相对于传统的循环神经网络,信息是通过多个隐含层逐层传递到输出层的。直观上,这会导致信息的损失,更本质地,这会使得网络参数难以优化,LSTM可以很好的解决这问题,对于时间序列预测也有一定的参考价值。
数据集
给出墨尔本近十年的温度数据集,以温度作为输入,利用lstm神经网络模型来做时间序列预测,根据提供的温度数据集来预测未来一天的温度,数据集如下图示例:
参数解释,其中的window_size:将温度每15个作为一组输入,第16个元素作为输出,也就是预测值,依次滑动窗口
“epochs”: 2,
“batch_size”: 10,
“window_size”: 15, 窗口,每15个数据作为一组,依次滑动
“train_test_split”: 0.8, 切分训练集
“validation_split”: 0.1,
“dropout_keep_prob”: 0.2,抑制参数传递,在全连接层,0.2的参数不做更新,更新速度变快,泛化能力更好,防止过拟合
“hidden_unit”: 100 隐藏层单元
代码
处理时间序列数据集,其中index_col=0:将第0列数据日期作为index,输入的values值只有温度,每16个元素作为一组数据,index:0-14为输入x,index:15为输出y,在对数据切分,0.8为训练集,0.2为测试集
# 处理时间序列数据集
def load_timeseries(filename, params):
# 加载时间序列数据集
series = pd.read_csv(filename, sep=',', header=0, index_col=0, squeeze=True)
data = series.values
adjusted_window = params['window_size'] + 1 # window_size+1,’+1‘作为预测值
# Split data into windows
raw = [] # 原始数据
for index in range(len(data) - adjusted_window):
raw.append(data[index:index + adjusted_window])
# Normalize data
result = normalize_window(raw)
raw = np.array(raw)
# 原始数据假设最开始有N行,通过窗口滑动形成[N-16,16]的二维数据
result = np.array(result)
# Split the input dataset into train and test
split_train_index = int(round(params['train_test_split'] * result.shape[0]))
train = result[:split_train_index, :]
np.random.shuffle(train) # 滑动窗口后的数据相关性太高,按行做重新排序,洗牌
x_train = train[:, :-1]
y_train = train[:, -1]
x_test = result[split_train_index:, :-1]
y_test = result[split_train_index:, -1]
# 对数据升维度,每一个X作为一个向量,作为一个输入
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
# 处理原始数据
# order = y_train.argsort(axis=0)
x_test_raw = raw[split_train_index:, :-1]
y_test_raw = raw[split_train_index:, -1]
# Last window, for next time stamp prediction
last_raw = [data[-params['window_size']:]] # 取出最后一组数据
last = normalize_window(last_raw)
last = np.array(last)
last = np.reshape(last, (last.shape[0], last.shape[1], 1))
return [x_train, y_train, x_test, y_test, x_test_raw, y_test_raw, last_raw, last]
规范化数据,正则化
def normalize_window(window_data):
normalize_data = []
for window in window_data:
normalize_window = [((float(p) / float(window[0])) - 1) for p in window]
normalize_data.append(normalize_window)
return normalize_data
建立模型,这里使用的是keras框架的Sequential 模型,在数据处理时对数据进行了升维,一组数据0-15中的每一个元素x作为一个输入,输出为某个值,也就是温度的预测值,这里使用LSTM模型,layer[2]是hidden_unit隐藏层,输入层->隐藏层->全连接层->输出
def rnn_lstm(layers, params):
model = Sequential()
model.add(LSTM(1, input_shape=(layers[1], layers[0]), return_sequences=True)) # 15行1列作为输入
model.add(Dropout(params['dropout_keep_prob']))
model.add(LSTM(layers[2], return_sequences=False))
model.add(Dropout(params['dropout_keep_prob']))
model.add(Dense(units=layers[3], activation='tanh')) #输出为1维
model.compile(loss='mean_squared_error', optimizer=Adam(learning_rate=0.001))
return model
预测下一个时间戳,带入训练好的模型和数据,来对未来的温度数据做预测
def predict_next_timestamp(model, history):
prediction = model.predict(history)
prediction = np.reshape(prediction, (prediction.size,))
return prediction
读入json文件类型的参数,key:value,load_timeseries函数获取时间序列数据,rnn_lstm函数读入模型做训练,predict_next_timestamp函数做未来温度的预测
def train_predict():
params = None
# 读入参数
with open(parameter_file) as f:
params = json.load(f)
# 获取时间序列数据
x_train, y_train, x_test, y_test, x_test_raw, y_test_raw, last_window_raw, last_window \
= load_timeseries(train_file, params)
lstm_layer = [1, params['window_size'], params['hidden_unit'], 1] # 输入层shape
# 读入模型
model = rnn_lstm(lstm_layer, params)
# 训练模型
model.fit(x_train, y_train, batch_size=params['batch_size'], epochs=params['epochs'],
validation_split=params['validation_split'])
# model.summary()
predicted = predict_next_timestamp(model, x_test) # 根据测试集做温度的预测
# 获取预测的结果
predicted_raw = []
for i in range(len(x_test_raw)):
predicted_raw.append((predicted[i] + 1) * x_test_raw[i][0]) # 返回原始结果
plt.plot(predicted_raw[0:200], 'r+-', ms=3, lw=1, label='Test Actual')
plt.plot(y_test_raw[0:200], 'b+-', ms=3, lw=1, label='Test Predicted')
plt.legend()
plt.show()
# predict next time stamp
next_timestamp = predict_next_timestamp(model, last_window)
next_timestamp_raw = (next_timestamp[0] + 1) * last_window_raw[0][0]
print('The next time stamp forecasting is: {}'.format(next_timestamp_raw))
print('结果:', next_timestamp_raw)
实验结果
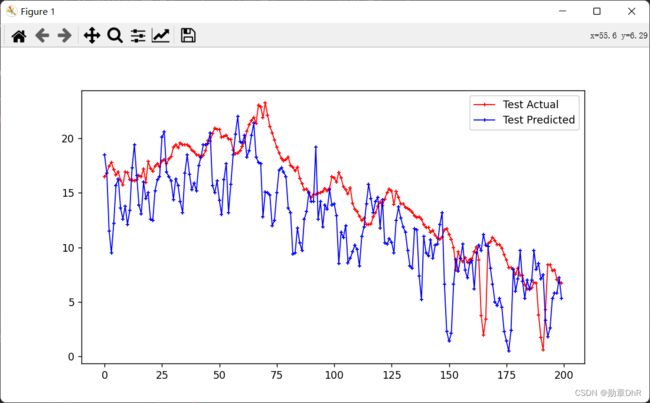
可视化结果可以看到预测值在真实值的上下浮动,浮动程度比较大,效果一般,但是还有一定的参考价值,我这里只训练了两个epoch,模型只有简单的输入输出,还有待优化和改进
262/262 [==============================] - 35s 120ms/step - loss: 4.2713 - val_loss: 1.0284
Epoch 2/2
262/262 [==============================] - 32s 121ms/step - loss: 4.2500 - val_loss: 1.0195
The next time stamp forecasting is: 15.915689048171044
结果: 15.915689048171044
给出数据集
链接:https://pan.baidu.com/s/1iwwUIvbh4vcR2bQ2iYtnAg
提取码:2ml5
给出全部代码
import numpy as np
import pandas as pd
from keras.layers.core import Dense, Activation, Dropout
from keras.layers.recurrent import LSTM
from keras.models import Sequential
from tensorflow.keras.optimizers import Adam, SGD, RMSprop
import json
import tensorflow._api.v2.compat.v1 as tf
import matplotlib.pyplot as plt
'''
"epochs": 2,
"batch_size": 10,
"window_size": 15, 窗口,每15个数据作为一组,依次滑动
"train_test_split": 0.8, 切分训练集
"validation_split": 0.1,
"dropout_keep_prob": 0.2,抑制参数传递,在全连接层,0.2的参数不做更新,更新速度变快,泛化能力更好,防止过拟合
"hidden_unit": 100
'''
# 处理时间序列数据集
def load_timeseries(filename, params):
# 加载时间序列数据集
series = pd.read_csv(filename, sep=',', header=0, index_col=0, squeeze=True)
data = series.values
adjusted_window = params['window_size'] + 1 # window_size+1,’+1‘作为预测值
# Split data into windows
raw = [] # 原始数据
for index in range(len(data) - adjusted_window):
raw.append(data[index:index + adjusted_window])
# Normalize data
result = normalize_window(raw)
raw = np.array(raw)
# 原始数据假设最开始有N行,通过窗口滑动形成[N-16,16]的二维数据
result = np.array(result)
# Split the input dataset into train and test
split_train_index = int(round(params['train_test_split'] * result.shape[0]))
train = result[:split_train_index, :]
np.random.shuffle(train) # 滑动窗口后的数据相关性太高,按行做重新排序,洗牌
x_train = train[:, :-1]
y_train = train[:, -1]
x_test = result[split_train_index:, :-1]
y_test = result[split_train_index:, -1]
# 对数据升维度,每一个X作为一个向量,作为一个输入
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
# 处理原始数据
# order = y_train.argsort(axis=0)
x_test_raw = raw[split_train_index:, :-1]
y_test_raw = raw[split_train_index:, -1]
# Last window, for next time stamp prediction
last_raw = [data[-params['window_size']:]] # 取出最后一组数据
last = normalize_window(last_raw)
last = np.array(last)
last = np.reshape(last, (last.shape[0], last.shape[1], 1))
return [x_train, y_train, x_test, y_test, x_test_raw, y_test_raw, last_raw, last]
# 规范化数据,正则化
def normalize_window(window_data):
normalize_data = []
for window in window_data:
normalize_window = [((float(p) / float(window[0])) - 1) for p in window]
normalize_data.append(normalize_window)
return normalize_data
# 建立模型
def rnn_lstm(layers, params):
model = Sequential()
model.add(LSTM(1, input_shape=(layers[1], layers[0]), return_sequences=True)) # 15行1列作为输入
model.add(Dropout(params['dropout_keep_prob']))
model.add(LSTM(layers[2], return_sequences=False))
model.add(Dropout(params['dropout_keep_prob']))
model.add(Dense(units=layers[3], activation='tanh')) #输出为1维
model.compile(loss='mean_squared_error', optimizer=Adam(learning_rate=0.001))
return model
# 预测下一个时间戳
def predict_next_timestamp(model, history):
prediction = model.predict(history)
prediction = np.reshape(prediction, (prediction.size,))
return prediction
# 数据预测
def train_predict():
params = None
# 读入参数
with open(parameter_file) as f:
params = json.load(f)
# 获取时间序列数据
x_train, y_train, x_test, y_test, x_test_raw, y_test_raw, last_window_raw, last_window \
= load_timeseries(train_file, params)
lstm_layer = [1, params['window_size'], params['hidden_unit'], 1] # 输入层shape
# 读入模型
model = rnn_lstm(lstm_layer, params)
# 训练模型
model.fit(x_train, y_train, batch_size=params['batch_size'], epochs=params['epochs'],
validation_split=params['validation_split'])
# model.summary()
predicted = predict_next_timestamp(model, x_test) # 根据测试集做温度的预测
# 获取预测的结果
predicted_raw = []
for i in range(len(x_test_raw)):
predicted_raw.append((predicted[i] + 1) * x_test_raw[i][0]) # 返回原始结果
plt.plot(predicted_raw[0:200], 'r+-', ms=3, lw=1, label='Test Actual')
plt.plot(y_test_raw[0:200], 'b+-', ms=3, lw=1, label='Test Predicted')
plt.legend()
plt.show()
# predict next time stamp
next_timestamp = predict_next_timestamp(model, last_window)
next_timestamp_raw = (next_timestamp[0] + 1) * last_window_raw[0][0]
print('The next time stamp forecasting is: {}'.format(next_timestamp_raw))
print('结果:', next_timestamp_raw)
if __name__ == '__main__':
train_file = './data/daily-minimum-temperatures.csv'
parameter_file = './training_config.json'
# 如果是空格分隔符,\s+.index_col=0,第0列数据作为index,日期作为index,温度作为value
data = pd.read_csv(train_file, sep=',', header=0, index_col=0, squeeze=True)
# 动态申请显存
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
train_predict()