【Kaggle项目实战记录】狗的品种识别
文章目录
-
- 1 查看原数据
- 2 数据预处理,建立Dataset
-
- 设定图像增广的方法
- 创建数据集Dataset类
- 预览训练集和验证集
- 3 定义和初始化模型
- 4 设置训练集和测试集
- 5 训练
- 6 模型存储
- 7 验证数据,上传
-
- 读取验证集
- 定义预测函数,预测
- 简单的技术点总结
这是一个动手学深度学习原课程的一个比赛项目(狗的品种识别)。课程的地址。
自己顺便记录一下这个项目自己的实现流程和思考,以巩固熟悉关于图片分类项目的整个流程。
用到的都是最基本的技术,初学者都会。
1 查看原数据
先浏览一下原数据长什么样子。
把数据集解压后发现下面有2个子文件夹,train中共10222张图片,为训练集;
test中共10357张图片,为测试集。


训练集的标签信息在label.csv中,id表示训练集中的图片文件名,Breed表示类别,有120个类别(狗的品种)。
sample_submission.csv中是届时提交的文件格式,代表测试集中各张图片中各自120个狗的品种的概率分布(softmax结果)。id代表test文件夹中各图片的文件名。

我们的目的是对test所有图片中的狗进行类别的预测,120个类别的预测概率都写到sample_submission.csv中。
我们发现本例的数据集图片对应的是id,(id, label)对应一组标签数据,而标签数据的信息存在了label.csv文件中。
所以我们首先需要自己写一个Dataset数据集对象,它最好可以直接传入一个含有标签数据信息的csv文件,从中构建一个数据集。
2 数据预处理,建立Dataset
先导包
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision.datasets import ImageFolder
from torchvision import transforms
import torchvision
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import os
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
我们第一个目的是准备建立自己的数据集Dataset类。
我们这次准备直接给Dataset传入数据文件csv,让它自己根据文件名(id)读取图片。
先读取label.csv查看
# 读取训练集和label
train_csv = pd.read_csv('../dog_breed_identification/labels.csv')
print(len(train_csv))
train_csv

把label中的类名转换为类别号class_to_num(根据字符串排序),查看一下结果。
# 读取训练集和label
print('训练集总数为',len(train_csv))
# 这个class_to_num即作为类别号到类别名称的映射
labels_info = train_csv.iloc[:,1] # 第2列的标签信息
class_to_num = labels_info.unique()
class_to_num = np.sort(class_to_num)
class_to_num

设定图像增广的方法
先把训练集和测试集需要的图像增广的方法设了,届时Dataset直接调用。
在训练集上:
先采用随机裁剪图像,所得图像为原始面积的0.08到1之间,高宽比在3/4和4/3之间,再缩放回224x224。
再使用随机水平翻转。
再随机更改亮度,对比度和饱和度。
在测试集上,使用放大到256×256后中心裁剪出224x224。
transform_train = transforms.Compose([
# 随机裁剪图像,所得图像为原始面积的0.08到1之间,高宽比在3/4和4/3之间。
# 然后,缩放图像以创建224x224的新图像
transforms.RandomResizedCrop(224, scale=(0.08, 1.0),
ratio=(3.0/4.0, 4.0/3.0)),
transforms.RandomHorizontalFlip(),
# 随机更改亮度,对比度和饱和度
transforms.ColorJitter(brightness=0.4,
contrast=0.4,
saturation=0.4),
# 添加随机噪声
transforms.ToTensor(),
# 标准化图像的每个通道
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
transform_test = transforms.Compose([
transforms.Resize(256),
# 从图像中心裁切224x224大小的图片
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
创建数据集Dataset类
我给Dataset设置了以下功能:
- 可读入csv文件,其含有指定格式的数据(文件名 id)+标签信息。
根据id,用PIL中的Image.open方法读入图片。
在__getitem__中,取到图片数据的方法是用PIL的Image.open方法来实现的。open后传入的id就读取自csv文件。- 可设定是否为训练集(train=True)
如设定为训练集,我又设定了一个 训练测试比(train_test_ratio),用于在训练集中,人工再分出一小部分测试集用于训练时实时测试准确率(这样的话会给出dataset中测试集的数据索引范围,并且前后使用的图像增广的方法也不一样)。
如果不设置train_test_ratio,则不用考虑这个问题。
如果不设为训练集(train=False),即读入测试集,用于测试模型,提交结果。这样返回则是img, fname(id)。- 训练集和测试集使用不同的图像增广方法,方法在上面已定义。
包括训练集中如使用了train_test_ratio分出一小部分的测试集,也使用测试集的图像增广法。
建立Dataset后,会预览数据集体验一下这个Dataset的功能。
class dog_dataset(Dataset):
def __init__(self, csv_path, file_path, train=True, train_test_ratio=None):
"""
Args:
csv_path (string): 格式 csv_path = '../dog_breed_identification/labels.csv'
如果train=True,csv文件为训练集文件名+标签信息,第一列为文件名,第二列为label
如果train=False,csv文件为验证集的文件名信息,第一列为文件名
file_path (string): 图片所在文件夹,格式 file_path = '../dog_breed_identification/train/'
train=True (boolean): 是否读为训练集
train_test_ratio=None (0~1小数): 仅当train=True时,可设置训练集占比,将训练集分成训练/测试两个部分
"""
self.train = train
if self.train==True: # 仅当train=True时可设train_test_ratio
if train_test_ratio is not None:
if train_test_ratio > 0 and train_test_ratio < 1:
self.train_test_ratio = train_test_ratio
else:
print('train_test_ratio设置不正确,未成功分配训练/测试集')
self.train_test_ratio = None
else:
self.train_test_ratio = None
else:
self.train_test_ratio = None
self.file_path = file_path
# 判断是否都为jpg文件
file_list = os.listdir(self.file_path)
jpg_tocheck = [i.split('.')[1] for i in file_list if i.split('.')[1] == 'jpg']
assert len(jpg_tocheck) == len(file_list)
if self.train==True:
# 读取训练集的信息文件
csv_file = pd.read_csv(csv_path)
if self.train_test_ratio is None:
# 建立imgs_filename
self.imgs_filename = csv_file['id'].tolist() # 第1列的文件名(id)信息
labels_info = csv_file.iloc[:,1] # 第2列的标签信息
origin_labels = labels_info.tolist() # 第2列的标签信息List
class_to_num = labels_info.unique()
class_to_num = np.sort(class_to_num) # 建立类别名到类别号的映射
print('读取csv文件成功,已建立类别名到类别号的映射,映射规则为类别名按字符串排列,即sorted(类名列.unique().tolist())')
csv_file['class_num'] = labels_info.apply(lambda x: np.where(class_to_num == x)[0][0]) # 建立新列,完成类别名到类别号的映射
# 建立labels
self.labels = csv_file['class_num'].tolist()
else: # 当设定了训练集/测试集比率时,训练集会随机分出一部分数据归为测试集。
self.num_train = int(len(csv_file) * train_test_ratio)
num_test = len(csv_file) - self.num_train
csv_file = csv_file.sample(frac=1).reset_index(drop=True) # 数据集重新打乱
print('设定了训练集占比,随机分出训练集',str(self.num_train),'个;分出测试集',str(num_test),'个。')
# 建立imgs_filename
self.imgs_filename = csv_file['id'].tolist() # 第1列的文件名(id)信息
labels_info = csv_file.iloc[:,1] # 第2列的标签信息
origin_labels = labels_info.tolist() # 第2列的标签信息List
class_to_num = labels_info.unique()
class_to_num = np.sort(class_to_num) # 建立类别名到类别号的映射
print('读取csv文件成功,已建立类别名到类别号的映射,映射规则为类别名按字符串排列,即sorted(类名列.unique().tolist())')
csv_file['class_num'] = labels_info.apply(lambda x: np.where(class_to_num == x)[0][0]) # 建立新列,完成类别名到类别号的映射
# 建立labels
self.labels = csv_file['class_num'].tolist()
print('前', str(self.num_train), '个数据为训练集,已使用训练集的数据增强;之后的视作测试集,已使用测试集的数据增强。')
else: # 验证集的情况
# 读取验证集的信息文件
csv_file = pd.read_csv(csv_path)
# 建立imgs_filename
self.imgs_filename = csv_file['id'].tolist() # 第1列的文件名(id)信息
print()
def __getitem__(self, index):
fname = self.imgs_filename[index] + '.jpg'
img = Image.open(self.file_path + fname)
if self.train_test_ratio is None:
if self.train==True:
label = self.labels[index]
return transform_train(img), label # 使用训练集的数据增强
else: # 验证集上增加返回一个文件名(id)的信息,方便后期识别。并使用测试集的数据增强
return transform_test(img), fname
else: # 设定了train_test_ratio的情形
label = self.labels[index]
if index < self.num_train: # 前num_train数为训练集,使用训练集的数据增强
return transform_train(img), label
else: # num_train之后为测试集,使用测试集的数据增强
return transform_test(img), label
def __len__(self):
return len(self.imgs_filename)
# 在__getitem__中,按index取到图片的方法就是用PIL中的Image.open来实现的。
预览训练集和验证集
我们预览一下通过新创建的dog_dataset类,建立各类训练集和测试集看看。
# 读取训练集看看
csv_path = '../dog_breed_identification/labels.csv'
file_path = '../dog_breed_identification/train/'
Dog_dataset = dog_dataset(csv_path, file_path, train=True)
print('第一张图的类别号、数据集的长度:', Dog_dataset[0][1], len(Dog_dataset))
train_iter = DataLoader(Dog_dataset, batch_size=128, shuffle=False)
X, y = next(iter(train_iter))
print('一个batch的数据形状、第一张图的类别:',X.shape, y[0])
print('第一张图:')
plt.imshow(torch.transpose(X[0], 0, 2))

# 把训练集分为训练+测试集看看
csv_path = '../dog_breed_identification/labels.csv'
file_path = '../dog_breed_identification/train/'
Dog_dataset = dog_dataset(csv_path, file_path, train=True, train_test_ratio=0.9)
print('第一张图片的类别号、数据集长度:', Dog_dataset[0][1], len(Dog_dataset))
print('第9200张图片(为测试集) :')
plt.imshow(torch.transpose(Dog_dataset[9199][0], 0, 2))

# 读取验证集看看
csv_path = '../dog_breed_identification/sample_submission.csv'
file_path = '../dog_breed_identification/test/'
Dog_dataset = dog_dataset(csv_path, file_path, train=False)
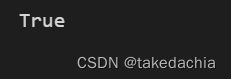
print('第1张图片的形状、第1张图片的类别号、数据集的长度:', (Dog_dataset[0][0]).shape, Dog_dataset[0][1], len(Dog_dataset))
valid_iter = DataLoader(Dog_dataset, batch_size=128)
X, y = next(iter(valid_iter))
print('第一批次最后一张图片:')
plt.imshow(torch.transpose(X[-1], 0, 2))

3 定义和初始化模型
直接使用预训练好的模型固定参数,最后加一个1000类到120的非线性激活函数+全连接层。
def get_net(devices):
finetune_net = torch.nn.Sequential()
# finetune_net.features = torchvision.models.resnet34(pretrained=True)
finetune_net.features = torchvision.models.resnet50(pretrained=True)
# 定义一个新的输出网络,共有120个输出类别
finetune_net.output_new = torch.nn.Sequential(torch.nn.Linear(1000, 256),
torch.nn.ReLU(),
torch.nn.Linear(256, 120))
# 将模型参数分配给用于计算的CPU或GPU
finetune_net = finetune_net.to(devices)
# 冻结参数
for param in finetune_net.features.parameters():
param.requires_grad = False
return finetune_net
pretrained_net = get_net(device)
# 优化器选取
lr, wd = 0.001, 0.001
optimizer = torch.optim.AdamW(pretrained_net.parameters(), lr=lr, weight_decay=wd)
4 设置训练集和测试集
因为原始数据中,提供的测试集其实是验证集,需要提交结果,在线验证准确率。
所以,自己需要对建立的训练集再随机分割一下,分成训练集和测试集。
传入参数train_test_ratio(训练集占比)即可。
测试集可以数量远小于训练集,只是观察本地训练的效果。我设成了0.96。
# 先建立训练数据集
csv_path = '../dog_breed_identification/labels.csv'
file_path = '../dog_breed_identification/train/'
Dog_dataset_train = dog_dataset(csv_path, file_path, train=True, train_test_ratio=0.96)

# 上面在训练集中分出一部分测试集,以便训练时第一时间查看训练的效果
indices1 = range(9813)
train_set = torch.utils.data.Subset(Dog_dataset_train, indices1)
indices2 = range(9813, len(Dog_dataset_train))
test_set = torch.utils.data.Subset(Dog_dataset_train, indices2)
print('在数据集中分出训练集和测试(验证)集各:', len(train_set), len(test_set))

5 训练
# 定义train函数,使用GPU训练并评价模型
import time
# 测试集上评估准确率
def evaluate_accuracy(data_iter, net, device=None):
"""评估模型预测正确率"""
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
# # 测试集上做数据增强(normalize)
# X = test_augs(X)
if isinstance(net, torch.nn.Module):
net.eval() # 将模型net调成 评估模式,这会关闭dropout
# 累加这一个batch数据中判断正确的个数
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 将模型net调回 训练模式
else: # 针对自定义的模型(几乎用不到)
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将 is_training 设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
def train(train_iter, test_iter, net, loss, optimizer, device, num_epochs):
net = net.to(device)
print('training on ', device)
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch+1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
def train_fine_tuning(net, optimizer, batch_size=128, num_epochs=15):
train_iter = DataLoader(train_set, batch_size)
test_iter = DataLoader(test_set, batch_size)
loss = torch.nn.CrossEntropyLoss()
train(train_iter, test_iter, net, loss, optimizer, device, num_epochs)
train_fine_tuning(pretrained_net, optimizer)
定义评估准确率和训练函数。
设置好训练集、测试集、损失函数、batch_size、训练轮数,以及模型,开始训练。
(我的设备:RTX3060)

6 模型存储
训练好后可以把模型储存到本地,方便重新读取和部署。
# pretrained_net 是 torchvision.models.resnet50() 类
path = 'net_pretrained.pt'
torch.save(pretrained_net.state_dict(), path)
7 验证数据,上传
我们现在需要在test.csv中预测类别。
test_csv = pd.read_csv('../dog_breed_identification/sample_submission.csv')
print(len(test_csv))
test_csv.head()

# 对比test_csv中的类顺序与class_to_num顺序是否一致,应当都是按字符串顺序排序的
temp = test_csv.columns.tolist()
temp.pop(0) # 去掉第一个'id'
print(temp == class_to_num.tolist())
读取验证集
# 读取验证集看看
csv_path = '../dog_breed_identification/sample_submission.csv'
file_path = '../dog_breed_identification/test/'
Dog_dataset = dog_dataset(csv_path, file_path, train=False)
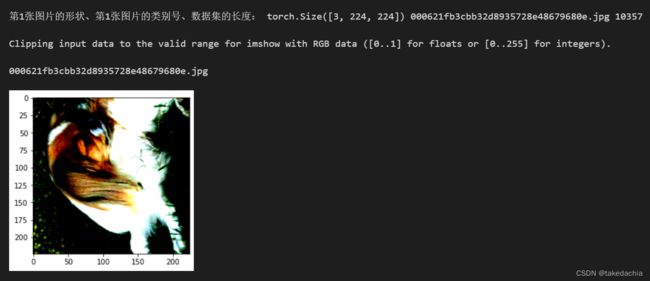
print('第1张图片的形状、第1张图片的类别号、数据集的长度:', (Dog_dataset[0][0]).shape, Dog_dataset[0][1], len(Dog_dataset))
valid_iter = DataLoader(Dog_dataset, batch_size=128)
# 查看一下验证集上的第1张图片
X, y = next(iter(valid_iter))
# 查看验证集第1个数据。valid_iter是按原顺序读取的。
plt.imshow(torch.transpose(X[0],0,2))
print(y[0])
定义预测函数,预测
定义一个预测函数,返回一个List,包含了10357个预测结果(120个类别的概率分布)。
# 定义预测函数
def valid_output(valid_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就用net的device
device = list(net.parameters())[0].device
with torch.no_grad():
y_output = []
id = []
for X, y in valid_iter:
# 验证集上做数据增强(normalize)
X = X.to(device)
net.eval() # 将模型net调成评估模式
y_hat = torch.softmax(net(X), dim=0)
y_hat = y_hat.cpu().tolist()
y_output += y_hat
id += list(y)
return id, y_output
# 测试模式
pretrained_net.eval()
id, output = valid_output(valid_iter, pretrained_net)
print(len(output))

写回sample_submission.csv
# 将结果写入sample_submission.csv
with open('../dog_breed_identification/sample_submission.csv', 'w') as f:
f.write('id,' + ','.join(class_to_num.tolist()) + '\n')
for id, output in zip(id, output):
f.write(id.split('.')[0] + ',' + ','.join(
[str(num) for num in output]) + '\n')
最后将这个sample_submission.csv按要求上传即可。
Kaggle上的这个Score应该是结果的Log Loss,排名不算靠前。如果想取得好成绩可以继续修改模型和超参数进行试验,并翻阅讨论区与别人的Code分享,本文仅记录自己的图片分类解决方案供学习、记录用。

简单的技术点总结
- 根据给的数据集特点定制Dataset数据集对象。
- 将本地的训练集再分成训练集和测试集(很小一部分)进行训练,这样可实时查看训练效果。
- 数据增强:训练集上采用随机裁剪图像,所得图像为原始面积的0.08到1之间,高宽比在3/4和4/3之间,再缩放回224x224。
再随机更改亮度,对比度和饱和度。
使用随机水平翻转。 - 模型:使用表现较好的预训练过的模型,使用Resnet50,冻结模型的参数,添加一个全连接层,指定120个输出。
- 优化器:使用AdamW,lr=0.001,weight_decay=0.001
(本文使用代码也可参考我的Github)