Levenberg-Marquardt(LM算法)的理解
Levenberg-Marquardt LM算法 的理解
- 1. convex optimization
-
- 1.1 convex set
- 1.2 convex function
- 1.3 optimization problem
- 1.4 convex optimization
- 1.5 Duality
- 2. SLAM Bundle Adjustment
-
- 2.1 Gauss Newton's method
- 2.2 LM法
- 2.3 Regularizaion in optimization
- 2.4 μ \mu μ的选取
1. convex optimization
先简单介绍一下凸优化的内容
First quickly introduction the convex optimization concepts.
1.1 convex set
Definition:
for x 1 , x 2 ∈ A x_{1}, x_{2} \in A x1,x2∈A, we say A A A is a convex set if and only if the following holds for any θ ∈ [ 0 , 1 ] \theta \in [0,1] θ∈[0,1]:
θ x 1 + ( 1 − θ ) x 2 ∈ A \theta x_{1} + (1- \theta)x_{2} \in A θx1+(1−θ)x2∈A
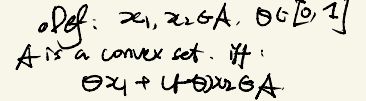
凸函数的定义如上,不过可以通过下面的图简单理解。可以直觉得说,如果两点集合内的点的“连线“上的点都在集合内,那么它就是一个凸集合。
We can quickly understand it by the following graph. If all the elements between x 1 x_{1} x1 and x 2 x_{2} x2 are in the set A A A, we could say it is a convex set.

1.2 convex function
Definition:
we say f ( x ) f(x) f(x) with domain d o m ( f ) dom(f) dom(f) is a convex function, if and only if , the following conditions holds for any θ ∈ [ 0 , 1 ] \theta \in [0,1] θ∈[0,1]:
f ( θ x 1 + ( 1 − θ ) x 2 ) ≤ θ f ( x 1 ) + ( 1 − θ ) f ( x 2 ) f(\theta x_{1} + (1-\theta)x_{2}) \le \theta f(x_{1}) + (1-\theta) f(x_{2}) f(θx1+(1−θ)x2)≤θf(x1)+(1−θ)f(x2)
θ x 1 + ( 1 − θ ) x 2 , x 1 , x 2 ∈ d o m ( f ) \theta x_{1} + (1-\theta)x_{2}, x_{1},x_{2} \in dom(f) θx1+(1−θ)x2,x1,x2∈dom(f)
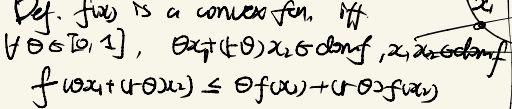

1.3 optimization problem
General form:
m i n i m i z e : f 0 ( x ) minimize : \quad f_{0}(x) minimize:f0(x)
s u b j e c t t o : f i ( x ) ≤ 0 , i ∈ 1 , 2 , . . . , n subject \ to : \quad f_{i}(x) \le 0, \ i \in {1,2,...,n} subject to:fi(x)≤0, i∈1,2,...,n
h j ( x ) = 0 , j ∈ 1 , 2 , . . . , m \quad \quad \quad \quad h_{j}(x) = 0, \ j \in {1,2,...,m} hj(x)=0, j∈1,2,...,m
f 0 ( x ) f_{0}(x) f0(x) is the objective function, and f i ( x ) f_{i}(x) fi(x) are inequality constraints, h j ( x ) h_{j}(x) hj(x) are equality constraints.
f 0 ( x ) f_{0}(x) f0(x)是优化的目标函数, f i ( x ) f_{i}(x) fi(x) 是不等式优化条件, h j ( x ) h_{j}(x) hj(x) 是等式优化条件。
for examples:
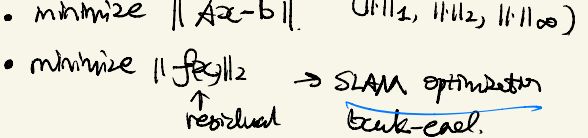
上面有几个简单的优化例子,可以发现SLAM问题(优化残差)也是其中之一。
1.4 convex optimization
f 0 ( x ) f_{0}(x) f0(x) , f i ( x ) f_{i}(x) fi(x) are all convex functions, and h j ( x ) h_{j}(x) hj(x) are affline equations, then the problem is a convex optimization problem.
如果 f 0 ( x ) f_{0}(x) f0(x) , f i ( x ) f_{i}(x) fi(x) 都是凸函数的话, h j ( x ) h_{j}(x) hj(x)是affline, 那么问题就变成了凸优化问题。

为什么要引入凸优化问题呢?问题我们可以证明在凸优化问题中,局部最小值就是全局最小值!而且凸优化是一个成熟的技术,有非常成熟快速高效和完善的解决算法。
也就是说,如果我们证明一个问题是凸优化问题,我们就可以保证它有快速高效的精确解!
1.5 Duality

2. SLAM Bundle Adjustment
SLAM的后端Bundle Adjustment其实是一个无约束的最小二乘范数下的优化问题(但是它不一定是凸的,或许是,我也不知道有没有人去证明过,这应该是一个很好的研究课题!)。

2.1 Gauss Newton’s method
我们常用的有牛顿法,是直接对目标函数 f 0 ( x ) f_{0}(x) f0(x) (下图中的 F ( x ) F(x) F(x))进行处理的。
![]()
另外有高斯牛顿法,是对残差函数进行处理,我们简单写出了它的求导过程:
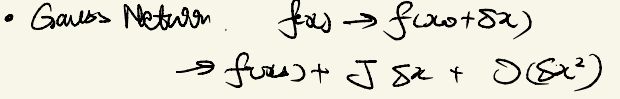

2.2 LM法

LM法则是在GN的基础上增加了一个阻尼因子。对于这个阻尼因子,不同的人有很多种解释方式(比如对x增加了一个阻尼,阻尼因子很大时接近最速下降法,阻尼因子比较小时,则更加接近高斯牛顿)。
但是我个人比较倾向于通过regularization来解读它。
2.3 Regularizaion in optimization
我们考虑这样一个问题:
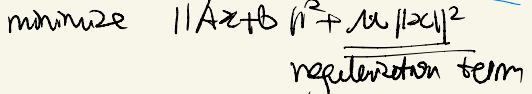
在优化原本的目标函数的同时,增加了一个对x的regularization限制。对于这一个增加的regularization项,同样有很多解读方式,在这里我介绍一下其中一种:
引入regularization是由于A的误差:
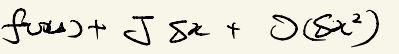
在我们的SLAM问题中,A其实是残差函数的雅各比,b则是在线性化位置的残差函数的值( f ( x 0 ) f(x_{0}) f(x0))。很明显,由于在 x 0 x_{0} x0附近进行了线性化,其实在这里是存在误差的。我们假设误差为 Δ \Delta Δ的话:
![]()
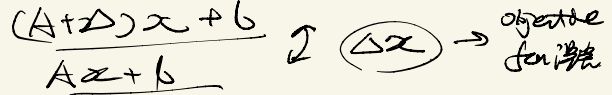
这样的话,如果我们限制 δ x \delta x δx的大小,则可以限制整个线性化中引入的误差。
- 其实从泰勒展开的角度看,我们是在 x 0 x_{0} x0附近做的泰勒展开,如果偏离 x 0 x_{0} x0过多,那么我们的线性化近似就失效了!所以必须保证 x 0 + δ x x_{0}+\delta x x0+δx在 x 0 x_{0} x0附近活动。
- 而且我们可以发现, μ \mu μ的选取是和 Δ \Delta Δ相关的!
2.4 μ \mu μ的选取
Δ \Delta Δ其实是和hessian矩阵相关的。

而在GN算法中,其实是使用 J T J J^{T}J JTJ来近似hessian矩阵的,所以我们会在LM算法中见到 μ \mu μ的初试化:
