机器学习原来这么有趣!第三章:图像识别【鸟or飞机】?深度学习与卷积神经网络
作者:Adam Geitgey
原文:https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721#.3n9dohehj
译者:巡洋舰科技——赵95
校对:离线Offline——林沁
转载请联系译者。
你是不是看烦了各种各样有关深度学习的报道,却仍不知其所云?让我们一起来改变这个现状吧!
这一次,我们将应用深度学习技术,来写一个识别图像中物体的程序。换句话说,我们会解释 Google 相册搜索图片时所用到的「黑科技」: 

Google 现在可以让你在你自己的图片库里面,根据你的描述搜索图片,即使这些图片根本没有被标注任何标签!这是怎么做到的??
和第一、二章一样,这篇指南是为那些对机器学习感兴趣,但又不知从哪里开始的人而写的。这意味着文中有大量的概括。但是那又如何呢?只要能让读者对机器学习更感兴趣,这篇文章的任务也就完成了。
用深度学习识别物体 

xkcd#1425(出自http://xkcd.com,汉化来自http://xkcd.tw)
你可能曾经看过这个著名的 xkcd 的漫画。
一个 3 岁的小孩可以识别出鸟类的照片,然而最顶尖的计算机科学家们已经花了 50 年时间来研究如何让电脑识别出不同的物体。漫画里的灵感就是这么来的。
在最近的几年里,我们终于找到了一种通过深度卷积神经网络(deep convolutional neural networks)来进行物体识别的好方法。这些个词听起来就像是威廉·吉布森科幻小说里的生造词,但是如果你把这个想法逐步分解,你绝对可以理解它。
让我们开始吧——让我们一起来写一个识别鸟类的程序!
由浅入深
在我们在识别鸟类之前,让我们先做个更简单的任务——识别手写的数字「8」。
在第二章中,我们已经了解到神经网络是如何通过连接无数神经元来解决复杂问题的。我们创造了一个小型神经网络,然后根据各种因素(房屋面积、格局、地段等)来估计房屋的价格:

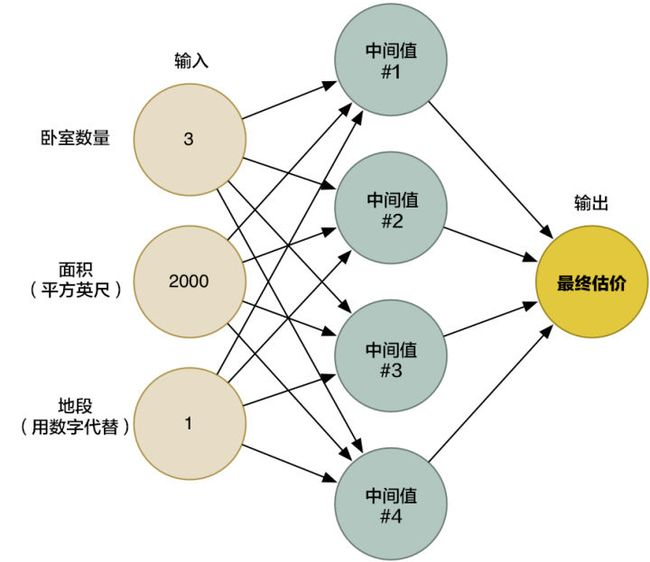
在第一章中我们提到了,机器学习,就是关于重复使用同样的泛型算法,来处理不同的数据,解决不同的问题的一种概念。所以这次,我们稍微修改一下同样的神经网络,试着用它来识别手写文字。但是为了更加简便,我们只会尝试去识别数字「8」。
机器学习只有在你拥有数据(最好是大量数据)的情况下,才能有效。所以,我们需要有大量的手写「8」来开始我们的尝试。幸运的是,恰好有研究人员建立了 MNIST 手写数字数据库,它能助我们一臂之力。MNIST提供了 60,000 张手写数字的图片,每张图片分辨率为 18×18。下列是数据库中的一些例子:

 MNIST 数据库中的数字 「 8 」
MNIST 数据库中的数字 「 8 」
万物皆「数」
在第二章中我们创造的那个神经网络,只能接受三个数字输入(卧室数、面积、地段)。但是现在,我们需要用神经网络来处理图像。所以到底怎样才能把图片,而不是数字,输入到神经网络里呢?
结论其实极其简单。神经网络会把数字当成输入,而对于电脑来说,图片其实恰好就是一连串代表着每个像素颜色的数字:


我们把一幅 18×18 像素的图片当成一串含有 324 个数字的数组,就可以把它输入到我们的神经网络里面了:


为了更好地操控我们的输入数据,我们把神经网络的输入节点扩大到 324 个:

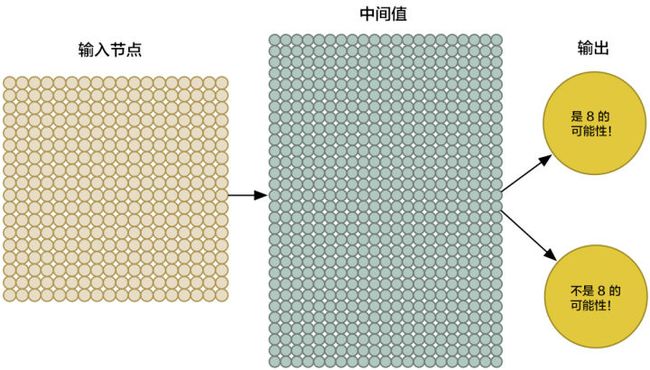 请注意,我们的神经网络现在有了两个输出(而不仅仅是一个房子的价格)。第一个输出会预测图片是「8」的概率,而第二个则输出不是「8」的概率。概括地说,我们就可以依靠多种不同的输出,利用神经网络把要识别的物品进行分组。
请注意,我们的神经网络现在有了两个输出(而不仅仅是一个房子的价格)。第一个输出会预测图片是「8」的概率,而第二个则输出不是「8」的概率。概括地说,我们就可以依靠多种不同的输出,利用神经网络把要识别的物品进行分组。
虽然我们的神经网络要比上次大得多(这次有 324 个输入,上次只有 3 个!),但是现在的计算机一眨眼的功夫就能够对这几百个节点进行运算。当然,你的手机也可以做到。
现在唯一要做的就是用各种「8」和非「8」的图片来训练我们的神经网络了。当我们喂给神经网络一个「8」的时候,我们会告诉它是「8」的概率是 100% ,而不是「8」的概率是 0%,反之亦然。
下面是一些训练数据:


嗯……训练数据好好吃
在现代的笔记本电脑上,训练这种神经网络几分钟就能完成。完成之后,我们就可以得到一个能比较准确识别字迹「8」的神经网络。欢迎来到(上世纪八十年代末的)图像识别的世界!
短浅的目光
仅仅把像素输入到神经网络里,就可以识别图像,这很棒!机器学习就像魔法一样!……对不对?
呵呵,当然,不会,这么,简单。
首先,好消息是,当我们的数字就在图片的正中间的时候,我们的识别器干得还不错。


坏消息是:
当数字并不是正好在图片中央的时候,我们的识别器就完全不工作了。一点点的位移我们的识别器就掀桌子不干了(╯‵□′)╯︵┻━┻。


这是因为我们的网络只学习到了正中央的「8」。它并不知道那些偏离中心的「8」长什么样子。它仅仅知道中间是「8」的图片规律。
在真实世界中,这种识别器好像并没什么卵用。真实世界的问题永远不会如此轻松简单。所以,我们需要知道,当「8」不在图片正中时,怎么才能让我们的神经网络识别它。
暴力方法 #1:滑框搜索
我们已经创造出了一个能够很好地识别图片正中间「8」的程序。如果我们干脆把整个图片分成一个个小部分,并挨个都识别一遍,直到我们找到「8」,这样能不能行呢?

 这个叫做滑动窗口算法(sliding window),是暴力算法之一。在有限的情况下,它能够识别得很好。但实际上它并不怎么有效率,你必须在同一张图片里面一遍一遍地识别不同大小的物体。实际上,我们可以做得更好!
这个叫做滑动窗口算法(sliding window),是暴力算法之一。在有限的情况下,它能够识别得很好。但实际上它并不怎么有效率,你必须在同一张图片里面一遍一遍地识别不同大小的物体。实际上,我们可以做得更好!
暴力方法 #2:更多的数据与一个深度神经网
刚刚我们提到,经过训练之后,我们只能找出在中间的「8」。如果我们用更多的数据来训练,数据中包括各种不同位置和大小的「8」,会怎样呢?
我们并不需要收集更多的训练数据。实际上,我们可以写一个小脚本来生成各种各样不同位置「8」的新图片:

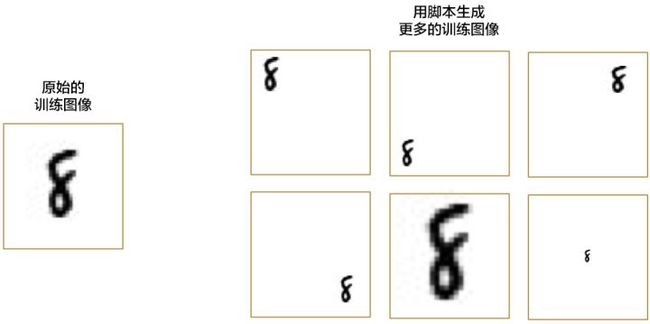 通过组合不同版本的训练图片,我们创造出了合成训练数据( Synthetic Training Data )。这是一种非常实用的技巧!
通过组合不同版本的训练图片,我们创造出了合成训练数据( Synthetic Training Data )。这是一种非常实用的技巧!
使用这种方法,我们能够轻易地创造出无限量的训练数据。
数据越多,这个问题对神经网络来说就越复杂。但是通过扩大神经网络,它就能寻找到更复杂的规律了。
要扩大我们的网络,我们首先要把把节点一层一层的堆积起来:

 因为它比传统的神经网络层数更多,所以我们把它称作「 深度神经网络」(deep neural network)。
因为它比传统的神经网络层数更多,所以我们把它称作「 深度神经网络」(deep neural network)。
这个想法在二十世纪六十年代末就出现了,但直至今日,训练这样一个大型神经网络也是一件缓慢到不切实际的事情。然而,一旦我们知道了如何使用 3D 显卡(最开始是用来进行快速矩阵乘法运算)来替代普通的电脑处理器,使用大型神经网络的想法就立刻变得可行了。实际上,你用来玩守望先锋的 NVIDIA GeForce GTX1080 这款显卡,就可以极快速的训练我们的神经网络。

 但是尽管我们能把我们的神经网络扩张得特别大,并使用 3D 显卡快速训练它,这依然不能让我们一次性得到结论。我们需要更智能地将图片处理后,放入到神经网络里。
但是尽管我们能把我们的神经网络扩张得特别大,并使用 3D 显卡快速训练它,这依然不能让我们一次性得到结论。我们需要更智能地将图片处理后,放入到神经网络里。
仔细想想,如果把图片最上方和最下方的「8」当成两个不同的对象来处理,并写两个不同的网络来识别它们,这件事实在是说不通。
应该有某种方法,使得我们的神经网络,在没有额外的训练数据的基础上,能够非常智能的识别出图片上任何位置的「8」,都是一样是「8」。幸运的是……这就是!
卷积性的解决办法
作为人类,你能够直观地感知到图片中存在某种层级(hierarchy)或者是概念结构(conceptual structure)。参考下面的这个图片:

 作为人类,你立刻就能识别出这个图片的层级:
作为人类,你立刻就能识别出这个图片的层级:
· 地面是由草和水泥组成的
· 图中有一个小孩
· 小孩在骑弹簧木马
· 弹簧木马在草地上
最重要的是,我们识别出了小孩儿,无论这个小孩所处的环境是怎样的。当每一次出现不同的环境时,我们人类不需要重新学习小孩儿这个概念。
但是现在,我们的神经网络做不到这些。它认为「8」出现在图片的不同位置,就是不一样的东西。它不能理解「物体出现在图片的不同位置还是同一个物体」这个概念。这意味着在每种可能出现的位置上,它必须重新学习识别各种物体。这弱爆了。
我们需要让我们的神经网络理解平移不变性(translation invariance)这个概念——也就是说,无论「8」出现在图片的哪里,它都是「8」。
我们会通过一个叫做卷积(Convolution)的方法来达成这个目标。卷积的灵感是由计算机科学和生物学共同激发的。(有一些疯狂的生物学家,它们用奇怪的针头去戳猫的大脑,来观察猫是怎样处理图像的 >_<)。
卷积是如何工作的
之前我们提到过,我们可以把一整张图片当做一串数字输入到神经网络里面。不同的是,这次我们会利用「位移物相同」[1]的概念来把这件事做得更智能。
下面就是,它怎样工作的分步解释——
第一步:把图片分解成部分重合的小图块
和上述的滑框搜索类似的,让我们把滑框滑过整个图片,并存储下每一个框里面的小图块:


这么做之后,我们把图片分解成了 77 块同样大小的小图块。
第二步:把每个小图块输入到小型神经网络中
之前,我们做的事是把单张图片输入到神经网络中,来判断它是否一为「8」。这一次我们还做同样的事情,只不过我们输入的是一个个小图块:
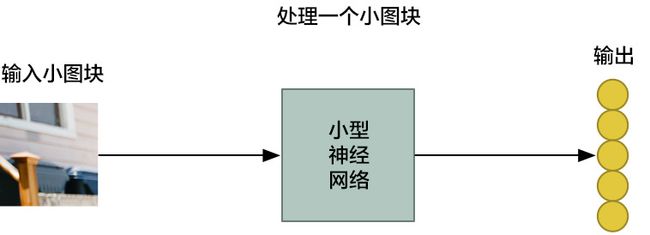
 重复这个步骤 77 次,每次判断一张小图块。
重复这个步骤 77 次,每次判断一张小图块。
然而,有一个非常重要的不同:对于每个小图块,我们会使用同样的神经网络权重。换一句话来说,我们平等对待每一个小图块。如果哪个小图块有任何异常出现,我们就认为这个图块是「异常」(interesting)的
第三步:把每一个小图块的结果都保存到一个新的数组当中
我们不想并不想打乱小图块的顺序。所以,我们把每个小图块按照图片上的顺序输入并保存结果,就像这样:

 换一句话来说,我们从一整张图片开始,最后得到一个稍小一点的数组,里面存储着我们图片中的哪一部分有异常。
换一句话来说,我们从一整张图片开始,最后得到一个稍小一点的数组,里面存储着我们图片中的哪一部分有异常。
第四步:缩减像素采样
第三步的结果是一个数组,这个数组对应着原始图片中最异常的部分。但是这个数组依然很大:

 为了减小这个数组的大小,我们利用一种叫做 最大池化(max pooling)的函数来 降采样(downsample)。它听起来很棒,但这仍旧不够!
为了减小这个数组的大小,我们利用一种叫做 最大池化(max pooling)的函数来 降采样(downsample)。它听起来很棒,但这仍旧不够!
让我们先来看每个 2×2 的方阵数组,并且留下最大的数:

 这里,一旦我们找到组成 2×2 方阵的 4 个输入中任何异常的部分,我们就只保留这一个数。这样一来我们的数组大小就缩减了,同时最重要的部分也保留住了。
这里,一旦我们找到组成 2×2 方阵的 4 个输入中任何异常的部分,我们就只保留这一个数。这样一来我们的数组大小就缩减了,同时最重要的部分也保留住了。
最后一步:作出预测
到现在为止,我们已经把一个很大的图片缩减到了一个相对较小的数组。
你猜怎么着?数组就是一串数字而已,所以我们我们可以把这个数组输入到另外一个神经网络里面去。最后的这个神经网络会决定这个图片是否匹配。为了区分它和卷积的不同,我们把它称作「全连接」网络(“Fully Connected” Network)。
所以从开始到结束,我们的五步就像管道一样被连接了起来:

 添加更多步骤
添加更多步骤
我们的图片处理管道是一系列的步骤:卷积、最大池化,还有最后的「全连接」网络。
你可以把这些步骤任意组合、堆叠多次,来解决真实世界中的问题!你可以有两层、三层甚至十层卷积层。当你想要缩小你的数据大小时,你也随时可以调用最大池化函数。
我们解决问题的基本方法,就是从一整个图片开始,一步一步逐渐地分解它,直到你找到了一个单一的结论。你的卷积层越多,你的网络就越能识别出复杂的特征。
比如说,第一个卷积的步骤可能就是尝试去识别尖锐的东西,而第二个卷积步骤则是通过找到的尖锐物体来找鸟类的喙,最后一步是通过鸟喙来识别整只鸟,以此类推。
下面是一个更实际的深层卷积网络的样子(就是你们能在研究报告里面找到的那种例子一样):

 这里,他们从一个 224×224 像素的图片开始,先使用了两次卷积和最大池化,再使用三次卷积,一次最大池化;最后再使用两个全连接层。最终的结果是这个图片能被分类到 1000 种不同类别当中的某一种!
这里,他们从一个 224×224 像素的图片开始,先使用了两次卷积和最大池化,再使用三次卷积,一次最大池化;最后再使用两个全连接层。最终的结果是这个图片能被分类到 1000 种不同类别当中的某一种!
建造正确的网络
所以,你是怎么知道我们需要结合哪些步骤来让我们的图片分类器工作呢?
说句良心话,你必须做许多的实验和检测才能回答这个问题。在为你要解决的问题找到完美的结构和参数之前,你可能需要训练 100 个网络。机器学习需要反复试验!
建立我们的鸟类分类器
现在我们已经做够了准备,我们已经可以写一个小程序来判定一个图中的物体是不是一只鸟了。
诚然,我们需要数据来开始。CIFAR10 数据库免费提供了 6000 张鸟类的图片和 52000 张非鸟类的图片。但是为了获取更多的数据,我们仍需添加 Caltech-UCSD Birds-200-2011 数据库,这里面包括了另外的 12000 张鸟类的图片。
这是我们整合后的数据库里面的一些鸟类的图片:


这是数据库里一些非鸟类图片:

 这些数据对于我们这篇文章解释说明的目的来说已经够了,但是对于真实世界的问题来说,72000 张低分辨率的图片还是太少了。如果你想要达到 Google 这种等级的表现的话,你需要上百万张高清无码大图。 在机器学习这个领域中,有更多的数据永远比一个更好的算法更重要!现在你知道为什么谷歌总是乐于给你提供无限量免费图片存储了吧? 他们,需要,你的,数据!
这些数据对于我们这篇文章解释说明的目的来说已经够了,但是对于真实世界的问题来说,72000 张低分辨率的图片还是太少了。如果你想要达到 Google 这种等级的表现的话,你需要上百万张高清无码大图。 在机器学习这个领域中,有更多的数据永远比一个更好的算法更重要!现在你知道为什么谷歌总是乐于给你提供无限量免费图片存储了吧? 他们,需要,你的,数据!
为了建立我们的分类器,我们将会使用 TFLearn。TFLearn 是 Google TensorFlow 的一个封装,Google TensorFlow 包含了一个拥有简单 API 的深度学习库。用它来建立卷积网络的过程,和写几行代码定义我们网络的层级一样简单。
下面是定义并训练我们网络的代码:
# -*- coding: utf-8 -*-




















40 条评论
电池的正负极就是Positive/Neg,在科学计算机领域没看到过阴阳一说,生物学里有
生物统计学,也就是基于的统计学使用的是阴性、阳性
正负通常指以0为界的数值状态,阴阳则指代某事物是否具备一个指标/特征。比如在战术用语里,positive就不会翻译成“正/大于零/正相关”,而是“是/有/存在”。电池的正负极应该是物理学描述与中性(0)相对的两种状态,而不是“有电”,“没电”,在概念上混淆了。
从这个意义来讲,猜测符合/不符合实际,显然是后者的含义。即使是二元假设,变量编码也通常是0和1而不是1/-1。
进一步去说,机器学习还有一个术语叫misclassification rate, 误分类率。这个术语通过文中的pos/neg的定义是解释不通的(误正率?)
可以的,但是只支持python 3.5
先mark一下,要开始搞图像识别了。。。
写得很好很清楚,不过我还是有一点不太明白,卷积解决了平移问题,那大小问题是怎么解决?
如果代码的格式能调整一下就更好了。
不错,直观理解卷积神经网络的两篇文章之一。
醍醐灌顶